📌 인덱스
어떤 데이터가 하드디스크의 어디에 있는지 위치 정보를 가진 주소록과 같은 개념이다. (데이터 - 위치주소(ROWID)) 쌍으로 저장하고 관리된다. 빠른 검색을 위한 목적으로 쓰이며, 데이터가 순서대로 정렬되어 저장된다.
📌인덱스 리빌드
기존의 인덱스를 삭제하고 재생성하는 방법이다.
📌인덱스 리빌드가 필요한 이유
데이터 변경(INSERT,DELETE,UPDATE)시 가져오는 인덱스의 성능 저하를 막기 위해 인덱스 관리를 해주어야 한다. 인덱스는 트리구조로 이루어져 있는데, 데이터 변경이 많아질 수록 트리 구조가 불균형되어 검색 속도를 늦어지게 한다.
📖INSERT
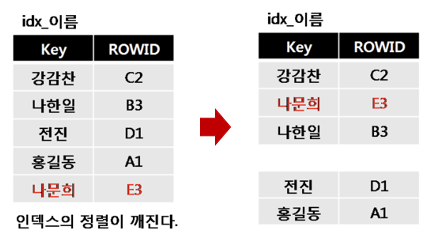
출처) https://multifrontgarden.tistory.com/11
인덱스는 데이터가 순서대로 정렬되어 저장되도록 한다. 하지만 기존 블럭에 여유 공간이 없는 상황에서 그 블럭에 새로운 데이터가 입력되어야 하는 경우, 기존 블럭의 내용 중 일부를 새 블럭에다가 기록한 다음 기존 블럭에 빈 공간을 만들어서 새로운 데이터를 추가하게 된다.
이러한 중간 INSERT 과정으로 인해 전체적인 인덱스 변경이 필요하다.
📚이유 1) 테이블이 변경될 때 인덱스도 같이 수정되지 않는다.
INSERT를 하고 난 후, 인덱스 갱신을 하지 않으면 인덱스의 최하위 계층 노드 위치는 대부분 잘못된 상태로 남겨진다. 인덱스 리빌드를 통해 , 변경된 데이터의 인덱스를 최신의 것으로 유지 할 수 있게 된다.
📚이유 2 ) INSERT 작업이 거듭될 수록, 인덱스의 데이터가 조각화(Insert split) 현상이 심해진다.
조각화된 데이터가 DB내에 흩어진다. 즉, 조각화 될수록 검색 시간도 늘어나고 차지하는 공간도 늘어난다. 이는 인덱스 성능 저하를 일으킨다. 인덱스 리빌드를 통해 방지할 수 있다.
📖DELETE
테이블의 데이터를 DELETE 할 때 인덱스는 지워지지 않는다. 인덱스는 그 데이터를 안쓴다고 체크만 된다. 즉, 쓰지는 않는데 용량은 그대로 가지고 있는 것이다.
삭제된 데이터의 인덱스는 아직 남아있어,
1) 해당 테이블 공간은 데이터가 삭제되어 있음에도 불구하고 사용하지 못하고,
2) INDEX RANGE SCAN등에 퍼올려야 하는 블록의 수가 늘어나 인덱스 기능으로서의 역할을 기대하기 힘들어진다.
3) 이처럼 기존의 용량이 그대로 유지 된 상태에서 새로운 데이터의 삽입이 발생할 경우, insert split 현상이 발생하게 된다.
따라서, 쓰지 않는 인덱스를 정리하기 위해 인덱스 리빌드가 필요하다.
📖UPDATE
인덱스는 UPDATE 개념이 없고, INSERT와 DELETE의 작업 2개가 발생한다.
📌인덱스 리빌드의 단점
- 재구축되는 동안 이전 인덱스와 새 인덱스 모두를 각각의 테이블스페이스에 수용할 충분한 공간이 필요하다.(추가 디스크 공간 필요)
→ 이전 인덱스는 새 인덱스가 구축된 후 삭제됨.
- 리빌드하는 동안 테이블에 LOCK이 발생하기 때문에 서비스를 막아놓고 작업을 해야 한다.
- 기존에 사용하던 INDEX를 사용하는 것이 아니라 새로운 INDEX를 생성한다.
