📌데이터베이스 저장영역 구조
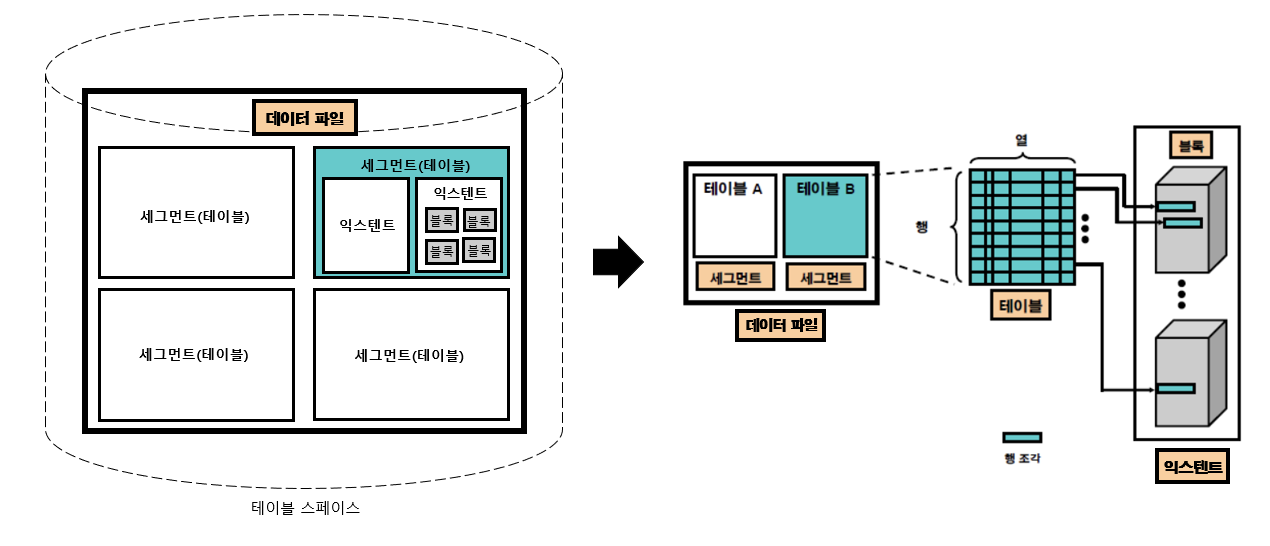
- 테이블 스페이스 | 세그먼트를 담는 콘테이너, 여러개의 데이터파일로 구성
- 데이터 파일 | 디스크 상의 물리적인 OS파일
- 세그먼트(테이블) | 테이블이 생성될 때 해당 테이블의 데이터를 보관.(테이블, index 등)
- 여러개의 익스텐트로 구성
- 테이블,인덱스를 생성할 때 데이터를 어떤 테이블 스페이스에 저장할지를 지정한다.
- 테이블은 각 열의 값이 들어있는 행으로 구성, 각 행은 행 조각으로 구성. → 레코드들의 집합
- 익스텐트 | 공간을 확장하는 단위, 연속된 블록들의 집합
- 테이블이나 인덱스에 데이터를 입력하다가 공간이 부족해지면 해당 오브젝트가 속한 테이블스페이스로 부터 익스텐트를 추가로 할당 받는다,
- 블록(페이지) | 데이터를 읽고 쓰는 단위 → 입출력단위
- 사용자가 입력한 레코드를 실제로 저장하는 공간
- 하나 이상의 레코드들이 저장된 단위
- 페이지 라고도 부름 ( DB2, SQL Server )
- 물리적 디스크 공간 크기에 따라 블록 크기도 결정됨
- 한 블록은 한 테이블이 독점한다 → 한 블록에 저장된 레코드는 모두 같은 테이블 레코드다.
- 테이블, 인덱스에서 특정 레코드 하나를 읽고 싶어도 해당 블록을 통째로 읽음
- 레코드
- 블록을 구성하는 요소
- 더이상 분리될 수 없는 최소 데이터 저장 단위
📌블록 내 레코드 저장 방식
테이블의 정의에 따라 고정길이 또는 가변길이의 레코드들을 저장한다. 저장하는 블록 방식에 따라 차지하는 용량이 달라진다.
📖고정 길이 레코드
고정적인 바이트 수를 갖는 레코드를 저장하는 기법. 모든속성의 길이가 항상 일정하다. 고정 길이일 경우 레코드의 컬럼 데이터타입 크기만큼 할당해서 블록에 저장하면 된다.
- 레코드의 길이가 블록 길이에 딱 맞춰 떨어지지 않는 단점이 존재한다. 블록내의 남는 공간 낭비로 이어진다.
- 블록의 길이가 레코드 길이로 정확히 나눠지지 않아 한 레코드를 두 블럭에 나누어 저장하는 방법
=> 레코드 접근 시 두 블록을 접근 (시스템에서는 두 블럭에 접근해야 하므로 부하가 늘어난다.)
📖가변 길이 레코드
블록에 저장되는 레코드의 길이가 서로 다른(가변적) 레코드를 할당하는 방법. 어디가 끝인지를 항상 기억하고 있어야된다는게 고정길이와의 차이점이다.
- 가변 길이 레코드가 사용되는 상황
- 한 블록 내에 저장되는 레코드 유형이 둘 이상일 경우
- 길이가 고정되지 않은 컬럼의 개수가 하나 이상일 경우
- 레코드가 멀티셋(멀티셋레코드의 컬럼값이 여러 개인 컬럼)을 허용한 컬럼을 가지는 경우
📖고정길이와 가변길이 레코드 저장 방식을 혼용하여 저장하는 방법
- 처음 블록의 0~4바이트까지는 어디서부터 얼마만큼이 가변길이인지 정보를 저장(길이 지시자)해놓는 용도로 사용한다.
- 4바이트부터 고정길이 데이터를 채우기 시작
- 레코드의 컬럼에 고정길이 데이터가 저장이 끝나면 한 바이트에 NULL 을 입력(구분자)하여 가변바이트의 시작을 구분.
- 가변길이 데이터 채우기 시작
📚인덱스 방식
별도의 인덱스 파일을 만들어서 레코드 파일에 대한 시작주소(address)를 저장하는 방식
📚헤더 영역에 메타데이터를 저장하는 방식
파일의 맨 첫 부분에 레코드를 구성하는 필드의 수, 수정 날짜, 삭제된 레코드 정보 등을 저장해놓아 레코드를 구분할 수 있는 방식.
📌파일구조화
파일 구조화란 파일 수준(데이터 파일?🤔)에서 레코드를 관리하는 기법이다. 각각의 레코드가 하나의 파일 내부에 몇번째 블록에 들어가야하는지를 결정한다.
📖힙파일구조
| 저장순서 고려 없이 파일 내 임의의 위치에 배치
- 저장할 크기가 있는 아무 블록에다가 저장하므로 저장의 속도는 가장 빠르다.
- 어떤 특정 레코드를 검색해야 하는 경우 임의의 블록으로 저장되어 있어 하나씩 블록을 탐색해서 찾아야 하므로 검색 속도는 느리다.
📖순차파일구조
| 레코드들이 탐색키 기준으로 순서대로 정렬되어 블록에 저장하는 것을 말한다
- 레코드를 저장해야 할 경우 레코드의 탐색키를 비교하고 어떤 블록에 넣을지 판단해야 하는 절차가 있으므로 바로바로 저장할 수 있는 힙 파일 구조의 저장 속도보다는 느리다.
- 레코드가 파일에 삽입되는 시점에 키 값 부여
- 이진 탐색을 사용하여 검색을 할 수 있으므로 힙 파일 구조처럼 하나씩 블록을 탐색해야 할 필요가 없다. 힙보다 검색 속도 빠르다.
📖해시파일구조
| 해시 함수를 이용하는 방식으로, 해시 함수는 레코드 탐색키를 입력받아 레코드가 저장될 블록 주소를 반환하고 해당 주소에 레코드를 저장하는 방식이다.
- 블록 주소들을 저장해야하는 공간이 필요하므로 다른 파일 구조들에 비해 공간의 낭비가 있을 수가 있다.
- 특정 레코드를 검색해야 하는 경우 대부분의 경우 한번의 블록 접근으로 원하는 레코드를 찾을 수 있어 가장 빠르다(해시 함수의 구조에 따라 다름)

배우는 것이 즐겁다!