3주차 내용은 파이썬을 이용한 웹 스크래핑!
보통 크롤링이라고 많이 부르지만,
정확히 이야기하면 크롤링과 웹스크리핑에는 차이가 있다.
크롤링: 구글, 네이버 등에서 내 블로그 내용을 가져다가 보여주는거처럼 전체를 모두 긁어가는 것
스크래핑: 많은 웹페이지 내용 중, 내가 필요한 부분만 긁어 오는 것
내가 그동안 크롤링이라고 알고 배웠던 내용은 필요한 부분만 골라내서 가지고 오는 웹스크래핑 기술이었다!
웹스크래핑을 하기 위해서는 먼저 BeautifulSoup 라이브러리를 임포트했다.
아래 코드는 bs4를 이용해서 스크래핑 하기 위한 가장 기초 내용!
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')requests.get에 들어가는 url을 변경하면서
원하는 웹페이지의 내용에 접근할 수 있다.
처음 시도한 내용은 네이버 영화페이지에서 순위와 제목, 평점을 가지고 오는 일!
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
rank = tr.select_one('img')['alt']
title = a_tag.text
star = tr.select_one('td.point').text
print(rank, title, star)select 함수와 select_one 함수 그리고
copy_seletor을 이용해 쉽게 구현할 수 있었다.

하지만...
과제로 수행했던, 지니뮤직 웹 스크래핑에서는
똑같은 방법으로 시도했지만,
for tr in trs:
title = tr.selct_one('a.title.ellipsis').text.strip()
rank = tr.selct_one('td.number').text[0:2].strip()
artist = tr.selct_one('td.info > a.artist.ellipsis').text
print(title, rank, artist)아래와 같은 에러가 났다 ㅠㅠ
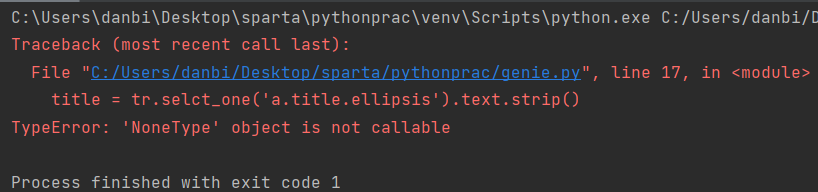
해답 찾아 삼만리를 했는데... 답은 너무 허무한 곳에서 발견됐다.
for문 안에 있는 오타...ㅎ 이런 오타..
오타를 다시 고치고..
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
title = tr.select_one('a.title.ellipsis').text.strip()
rank = tr.select_one('td.number').text[0:2].strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text.strip()
print(rank, title, artist)원하는 답을 얻을 수 있었다.
인터넷 서칭을 열심해 해본 결과, 내용을 모두 이해하지는 못했지만
none type 관련한 오류가 나면 for문부터 찾아봐야겠다는 교훈을 얻었다.
이렇게 웹 크롤링에 관한 3주차 수업도 끝!!
4주차는 정말 열심히 들어야 겠다 :)

왕초보 탈출기 입니다!! :)