InterviewLense
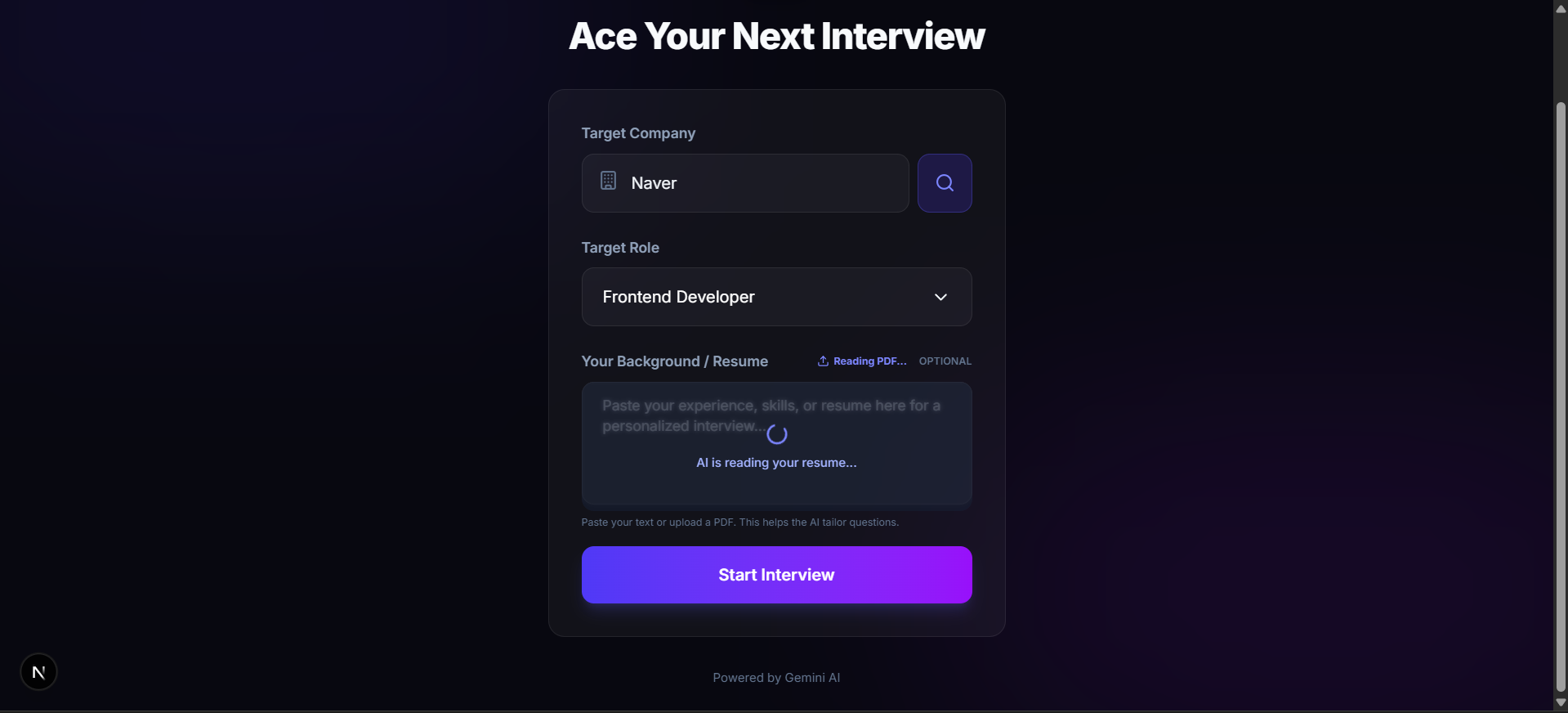
I Built an AI That Researches How Your Target Company Interviews — Then Simulates It
🔗 Live: https://interview-lense.vercel.app
📦 GitHub: https://github.com/sweety-HJH223/InterviewLense
The Problem
Most interview prep tools give you the same generic questions regardless of where you're applying. "Tell me about yourself." "What's your greatest weakness?"
It doesn't matter if you're interviewing at Google or a 10-person startup — you get the same list. Most simulators are "one-size-fits-all": they ignore your unique career history and fail to provide the real-world feedback needed to actually pass a high-stakes interview at a top-tier tech firm.
But interviews are NOT the same across companies:
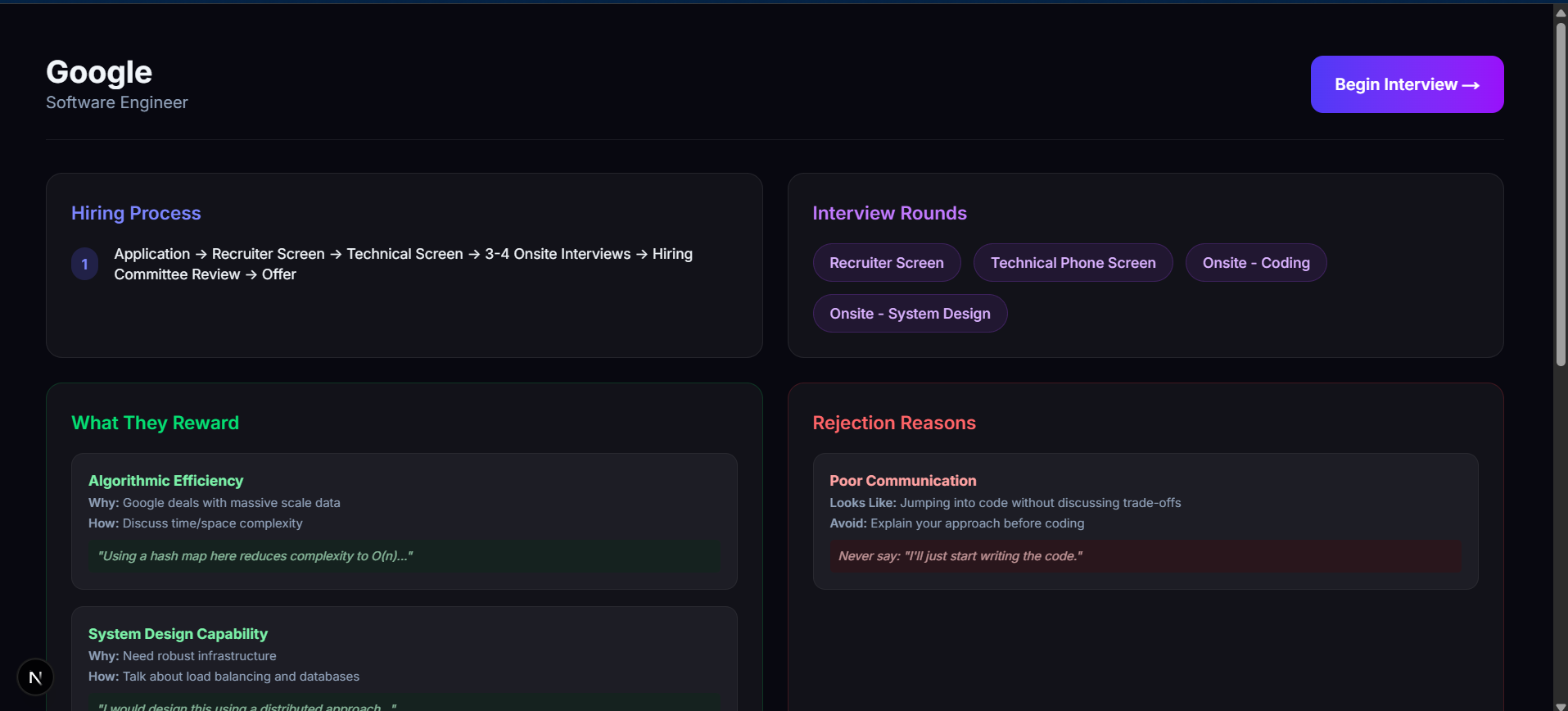
- Google wants reasoning processes over perfect answers.
- Amazon scores everything against 16 Leadership Principles.
- Kakao/Naver expect specific Korean-market-scale product thinking.
- Toss focuses on speed of execution.
I wanted a tool that actually knows this. So I built InterviewLens.
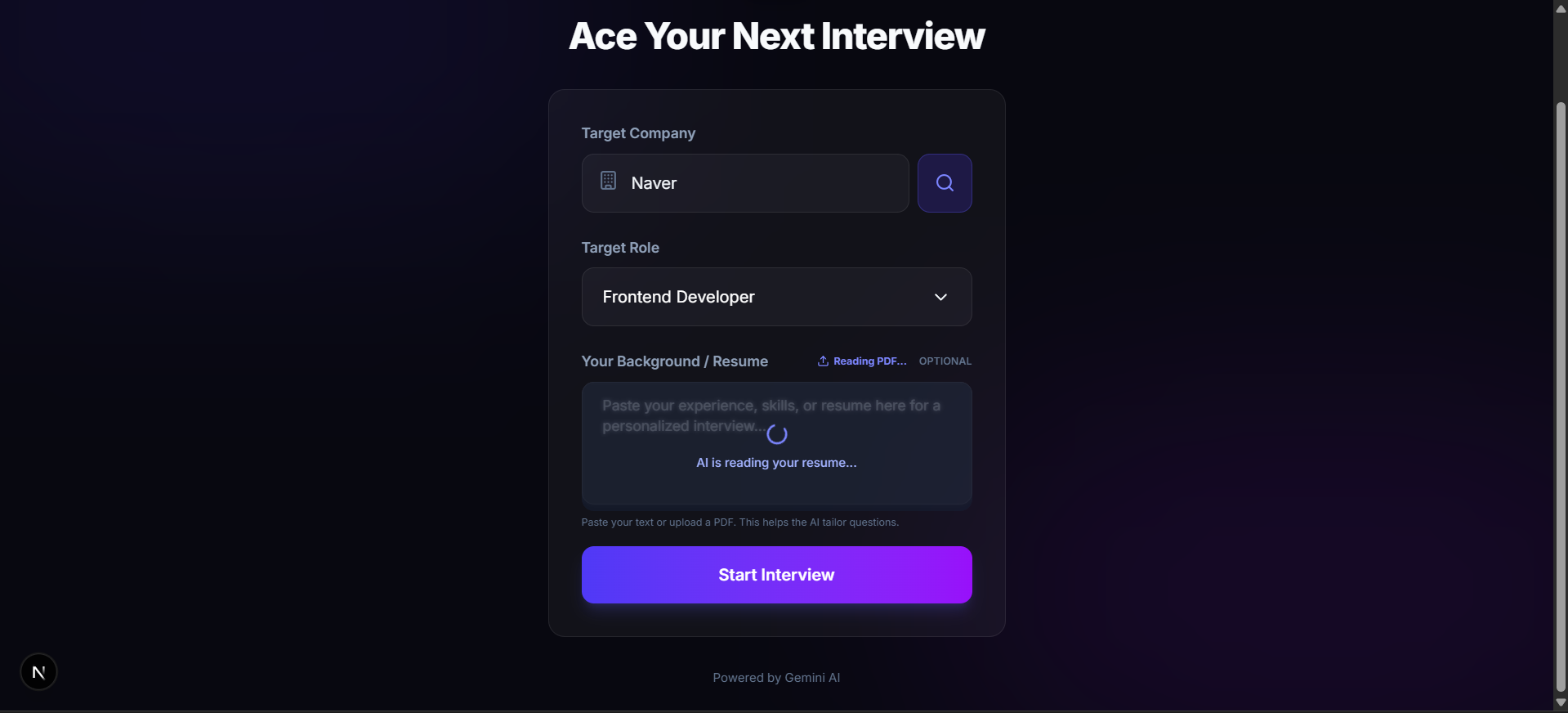
The Solution
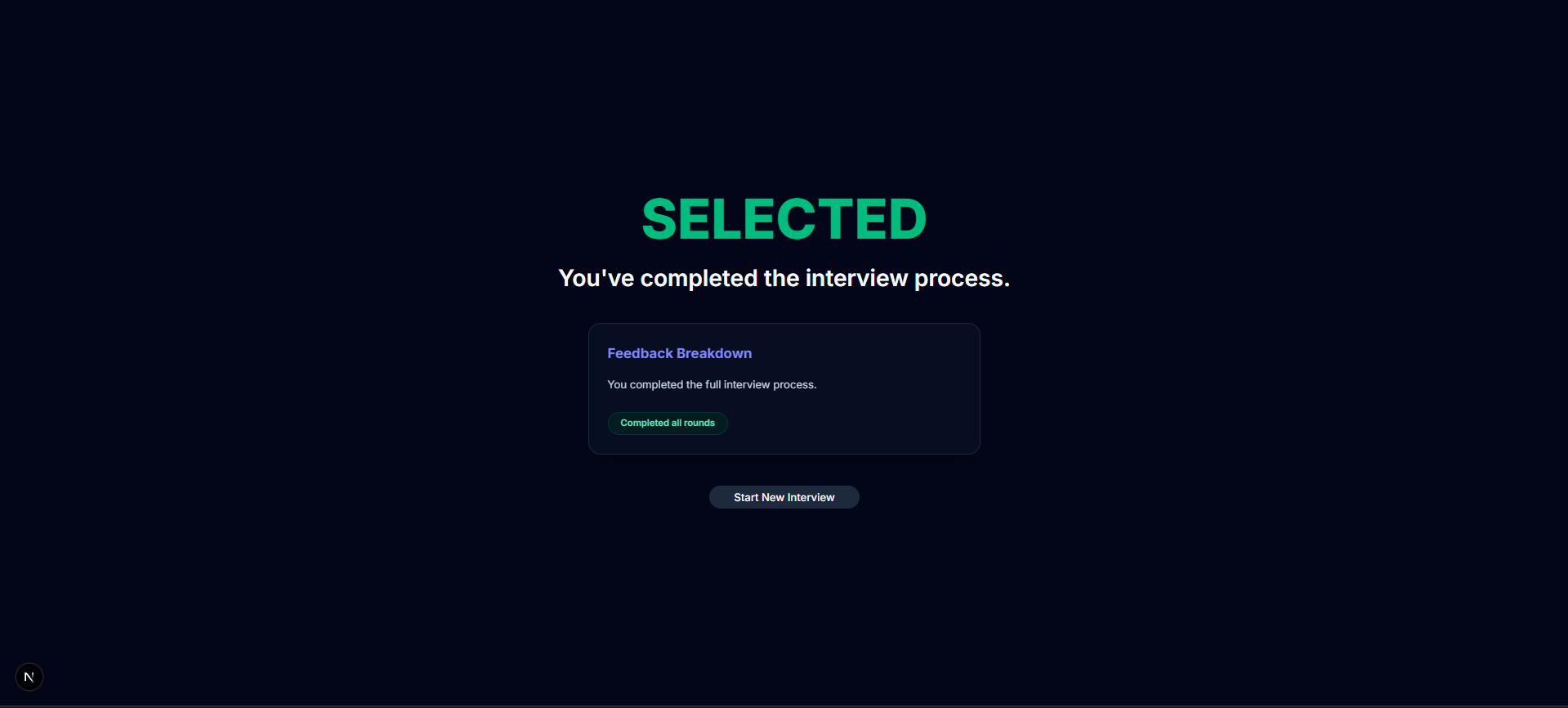
InterviewLens is an AI-powered simulation engine that:
- Takes any company name and role.
- Researches that specific company's hiring culture in real-time.
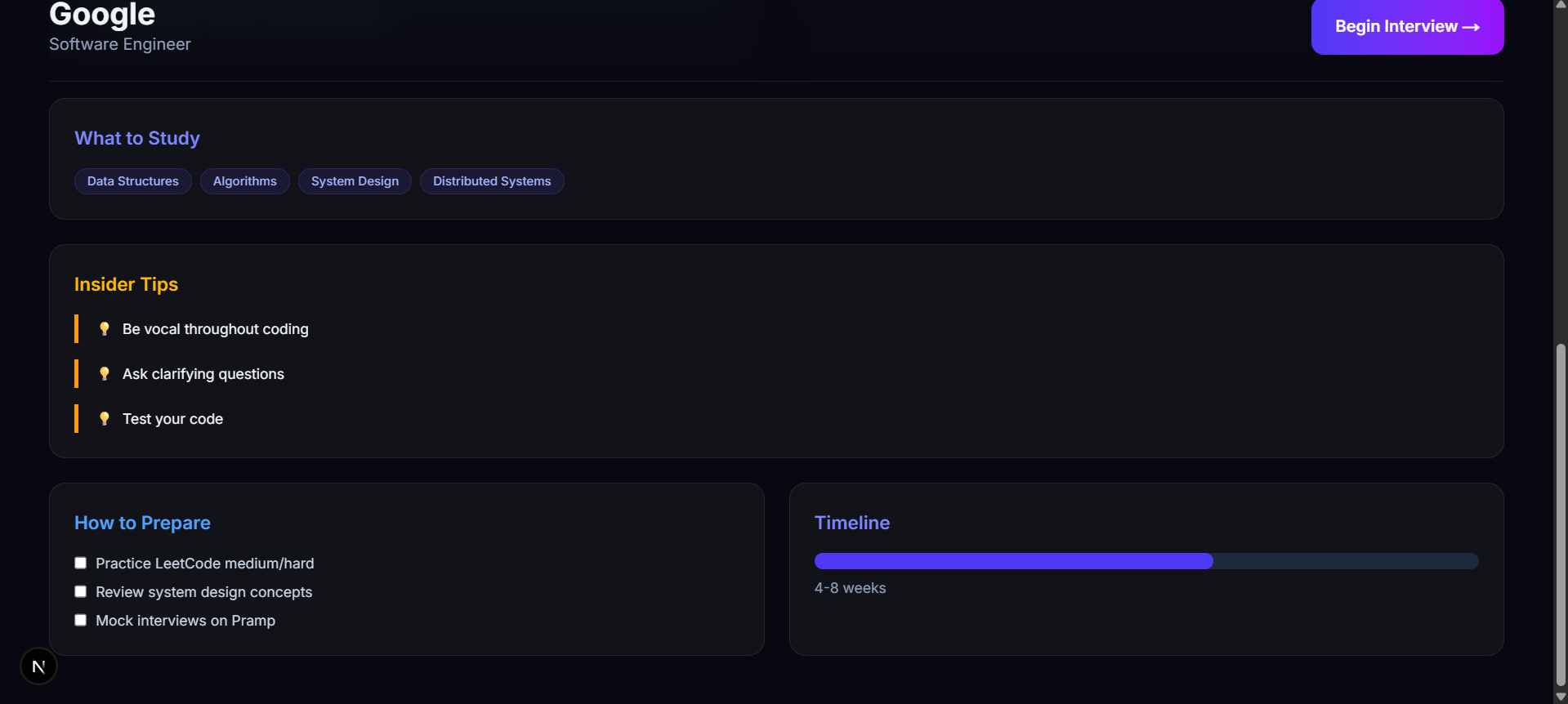
- NEW — Resume Alignment: Upload your PDF or paste your resume, and the AI identifies the specific gaps between your experience and the company's requirements.
- Simulates the interview in that company's actual style.
- Evaluates your answers against the company's specific criteria.
- Maintains a long-term "memory" of your growth across sessions.
The 3-Agent AI Architecture
The heart of InterviewLens is a 3-agent orchestration pipeline built with Google Gemini.
Agent A — The Researcher
Agent A scans for hiring focus, round structure, and cultural values.
The "Context Engine": It doesn't just research the company — it accepts your resume/PDF data and performs a gap analysis between your background and the company's requirements, making the research personalized from the start.
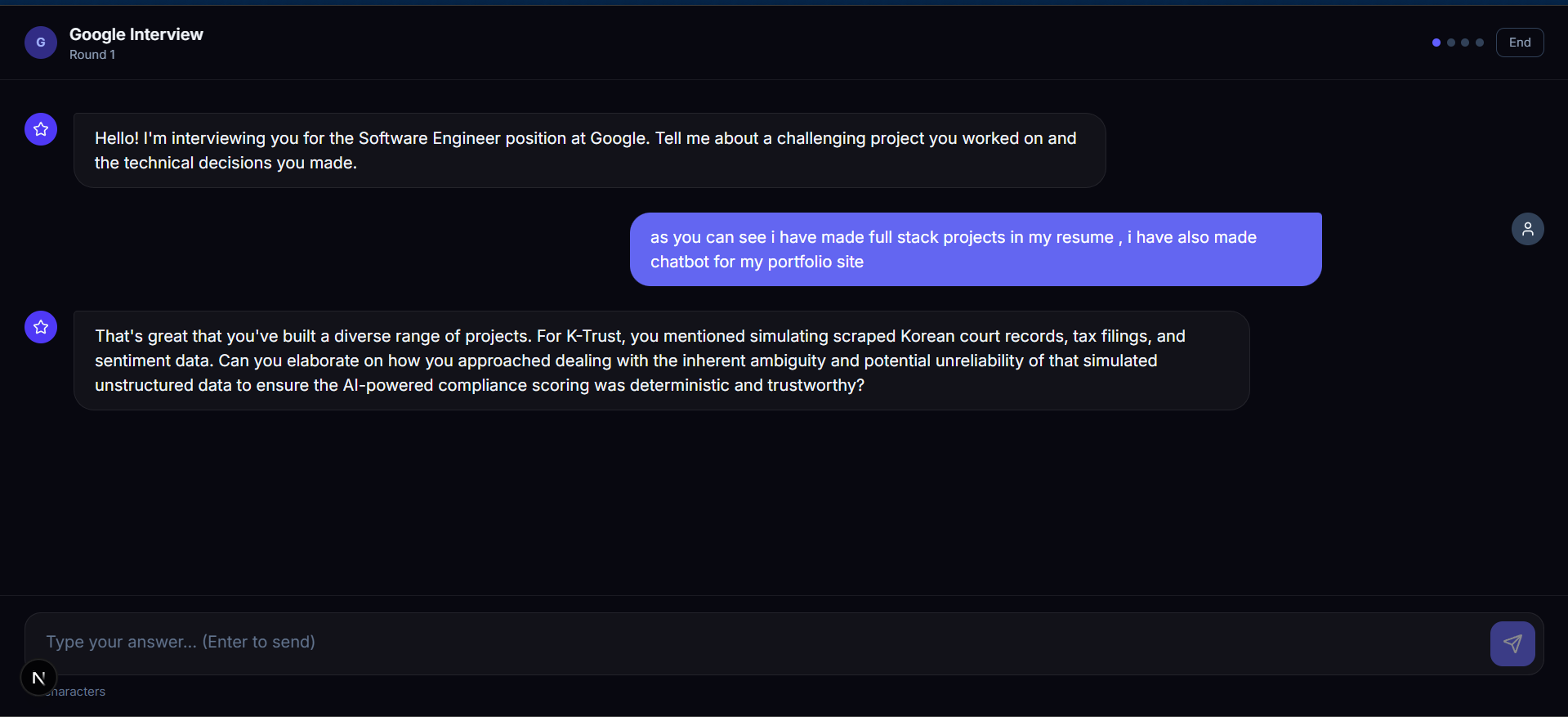
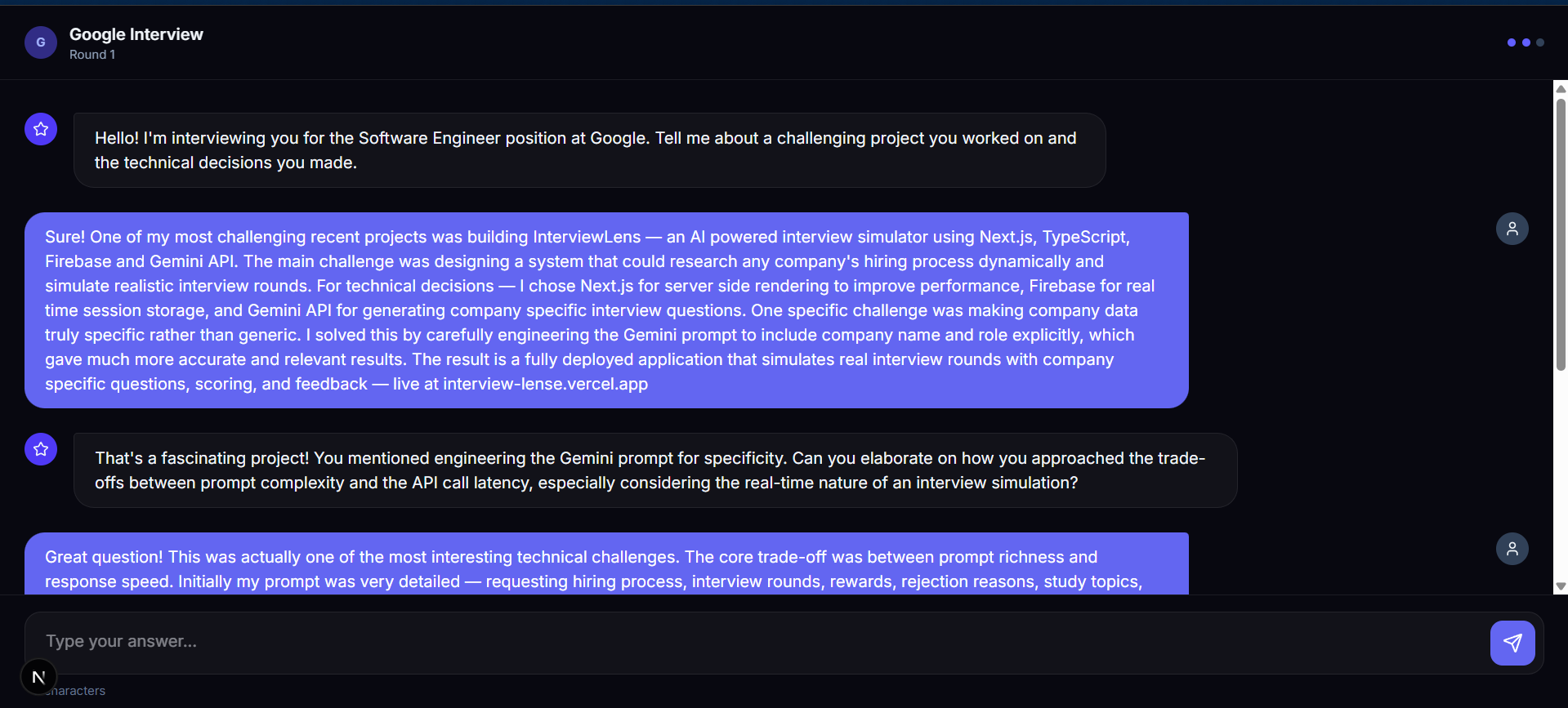
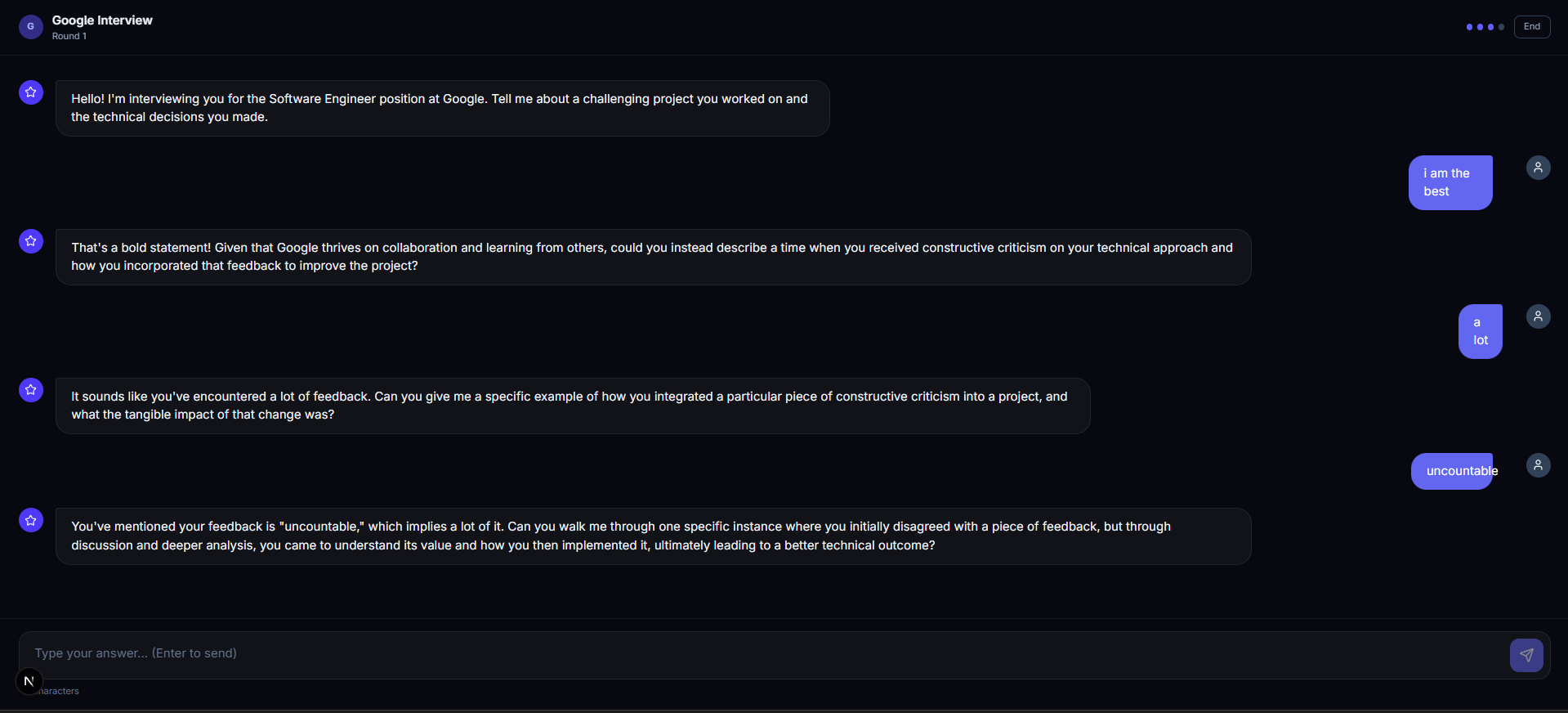
Agent B — The Interviewer
Agent B receives the intelligence from Agent A and becomes that company's actual interviewer.
Contextual Interaction: Because it receives your resume context, Agent B doesn't ask generic questions. It asks: "You worked on [X] project in your resume — how would you scale that for the traffic [Company] handles?"
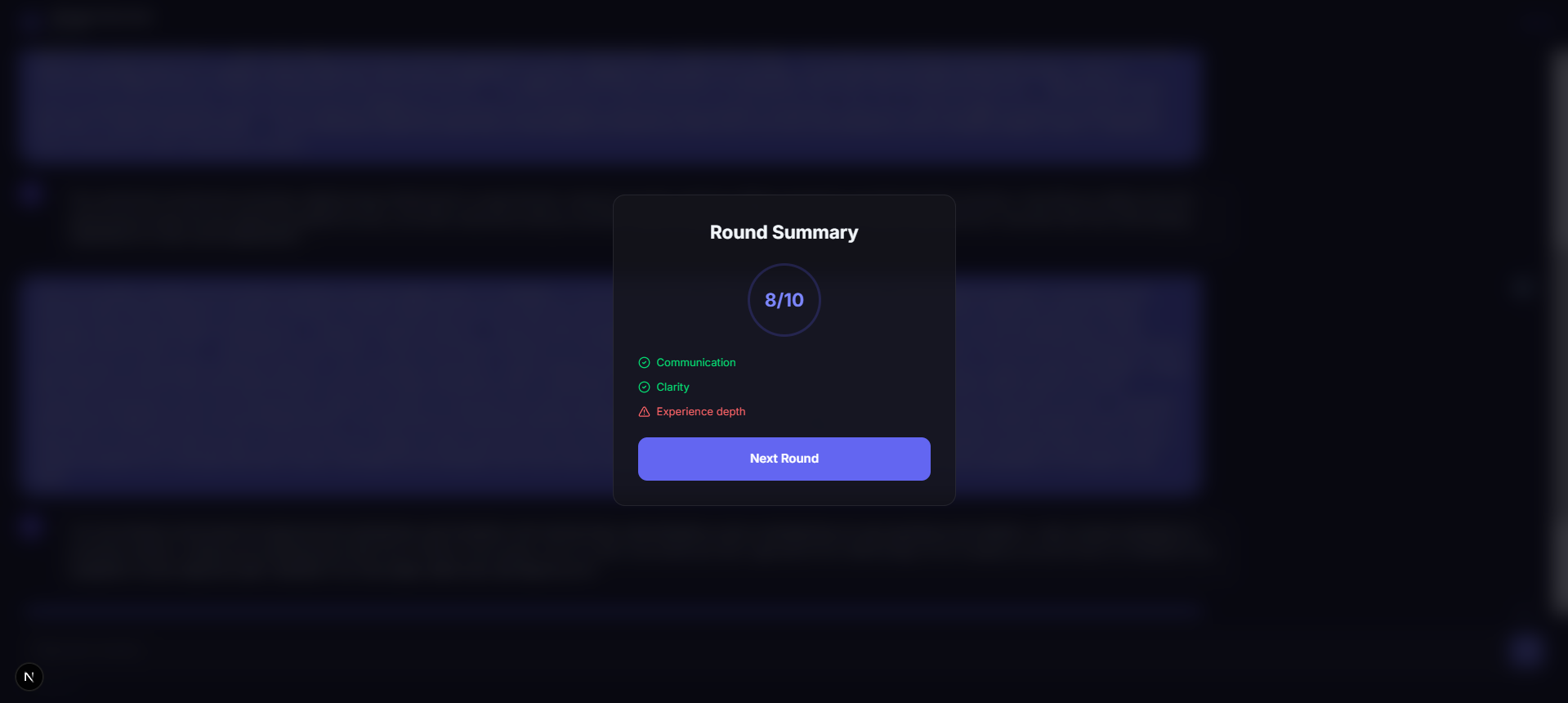
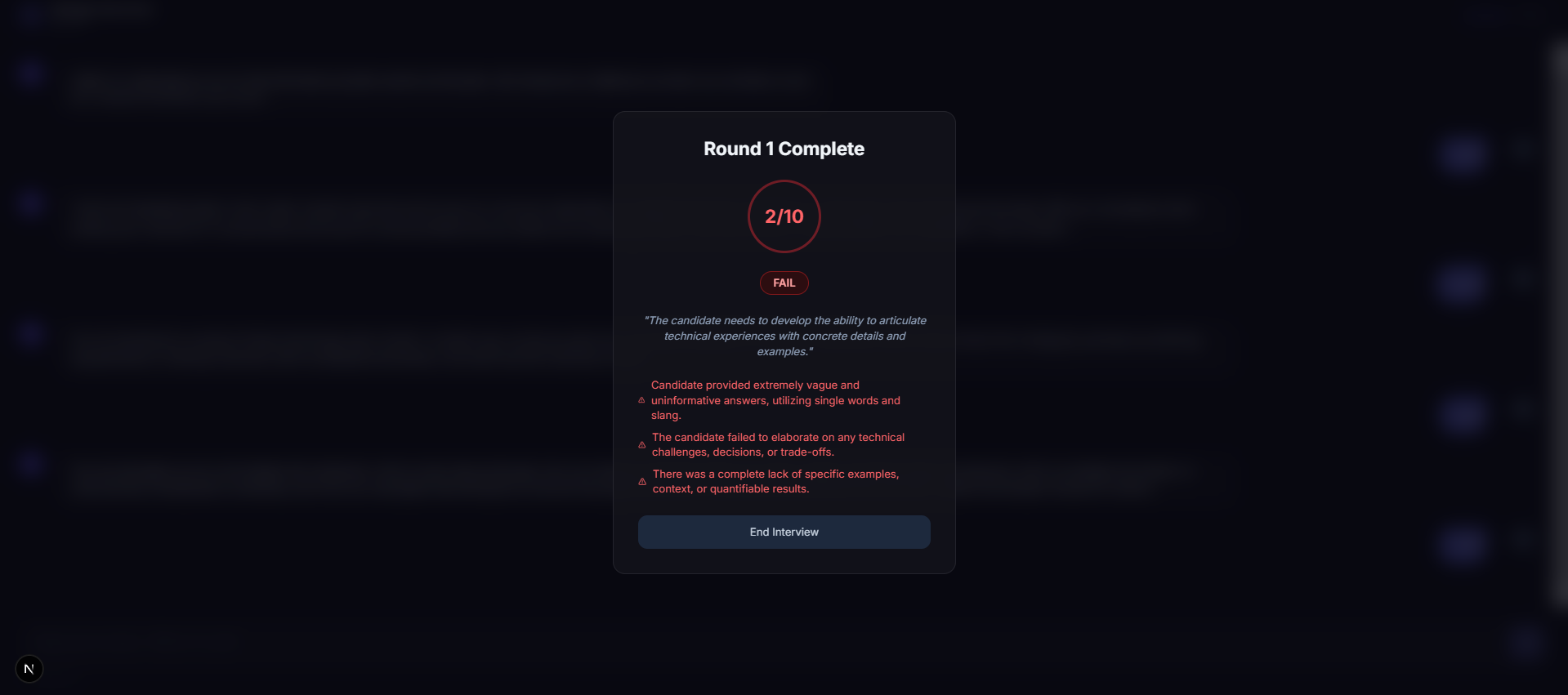
Agent C — The Evaluator
After you finish, Agent C acts as a "Hiring Committee."
Strict Scoring: It penalizes generic "template" answers and rewards candidates who leverage their specific background effectively.
Technical Challenges & My Solutions
1. The performance bottleneck
Initially, researching companies via AI took 10+ seconds, often leading to "Request Timed Out" errors.
My solution: I implemented a Redis-like caching layer using Firebase Firestore. Once a company/role is researched once, subsequent searches are near-instant — solving both latency and quota exhaustion effectively.
2. Handling unstructured PDF data
Users need resume-tailored questions, but parsing PDFs is messy.
My solution: I leveraged Gemini 1.5 Flash's multi-modal capability to directly parse PDF resumes, extracting structured data that the interview agent uses for context-aware follow-up questions — no external PDF libraries needed.
3. Agentic complexity
Coordinating three distinct AI agents (Researcher, Interviewer, Evaluator) led to prompt injection and state management issues.
My solution: I built a strict orchestration layer that forces a JSON-only output schema. By forcing the models to adhere to a predefined JSON structure, I eliminated parsing failures and enabled smooth state sharing between all three agents.
Google Tech Stack
| Tool | Purpose |
|---|---|
| 🤖 Google Gemini 1.5 Flash | Powers all three agents — research, interview simulation, and evaluation |
| 🔥 Firebase Firestore | Session storage, long-term candidate memory, and research cache |
| ☁️ Vercel / Next.js | High-performance, real-time deployment of the simulation interface |
What I Learned
Multi-agent systems are more powerful than single-prompt approaches. By separating Research, Interviewing, and Evaluation, each agent maintains a clear focus.
The most challenging part was Resume Alignment. Simply "sending the resume" wasn't enough — I had to engineer the prompts to force the AI to compare the candidate's past with the company's future needs. This bridge is what transforms a standard chatbot into an actual coaching tool.
Try It
🔗 Live: https://interview-lense.vercel.app
📦 GitHub: https://github.com/sweety-HJH223/InterviewLense
Built for Google Gen AI Academy APAC 2026 — Meet the Builders Campaign.
SweetyCodes — AI & Full Stack Developer
Subhashree Behera | India
