
- 위코드 실습 중 하나로 진행한 내용을 이용해 크롤링을 해보려고 합니다.
- 미국 영화 사이트 RottenTomatoes의 기생충 평론가 리뷰를 크롤링 해보겠습니다.
- 크롤링을 하기 위해서는
Requests와BeautifulSoup라이브러리가 필요합니다. - 크롤링용 가상환경을 세팅하고 필요한 라이브러리를 설치해 사용하면 좋습니다.
1. requests로 가져와 beautifulsoup으로 파싱하기
>>> pip install requests # 라이브러리를 설치합니다.
>>> pip install BeautifulSoup # 현재 BeautifulSoup은 버젼 4를 사용합니다.
>>> import requests
>>> from bs4 import BeautifulSoup
>>> url = "https://www.rottentomatoes.com/m/parasite_2019/reviews"
>>> req = requests.get(url)
>>> print(req) # get은 단순히 응답코드만 가져옵니다.
<Response [200]>
>>> html = req.text # html내용을 가져오기 위해 text를 가져옵니다. 인코딩이 안 맞을 경우에는 인코딩 방식을 바꾸거나 .content를 쓸 수 있습니다.
>>> print(html)
<!DOCTYPE html>
<html lang="en"
dir="ltr"
xmlns:fb="http://www.facebook.com/2008/fbml"
xmlns:og="http://opengraphprotocol.org/schema/">
<head prefix="og: http://ogp.me/ns# flixstertomatoes: http://ogp.me/ns/apps/flixstertomatoes#">
...
>>> soup = BeautifulSoup(html, 'html.parser')
<!DOCTYPE html>
<html dir="ltr" lang="en" xmlns:fb="http://www.facebook.com/2008/fbml" xmlns:og="http://opengraphprotocol.org/schema/">
<head prefix="og: http://ogp.me/ns# flixstertomatoes: http://ogp.me/ns/apps/flixstertomatoes#">
<!-- salt=lay-def-02-juRm -->
<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>
<meta content="ie=edge" http-equiv="x-ua-compatible"/>
<meta content="width=device-width, initial-scale=1" name="viewport"/>
<title>Parasite (Gisaengchung) - Movie Reviews</title>
...
2. 구별 요소(selector) 정해서 한 개 항목 가져오기
리뷰를 보면 여러 개가 같은 형식으로 되어 있습니다. 이럴 때는 보통 html 리스트 형식을 사용합니다. 이럴 경우 이름, 소속, 평가, 날짜끼리는 같은 CSS 클래스를 사용했을 가능성이 큽니다.
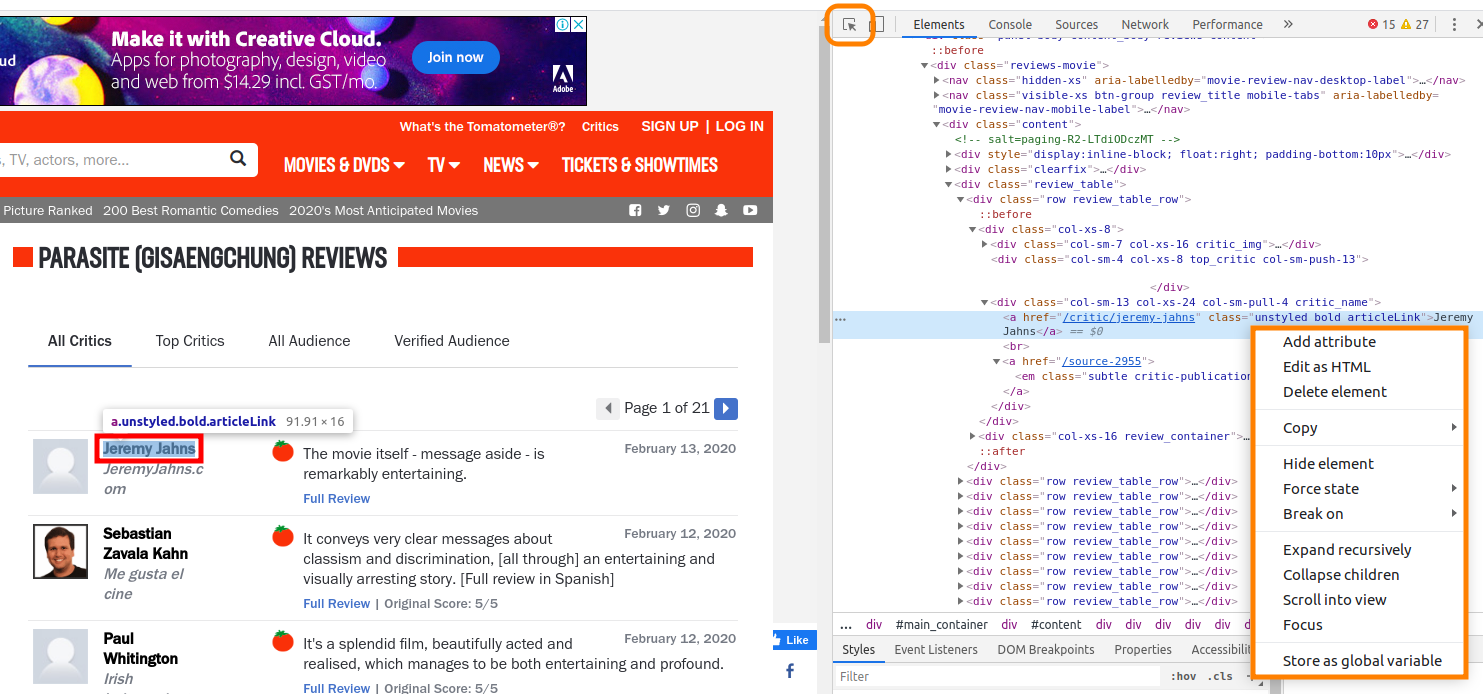
사진과 같이 크롬 개발자 도구를 열고(F12) 커서 표시를 클릭(Ctrl+Shift+C)한 후 원하는 부분(이름, 소속, 평가, 날짜)를 클릭합니다. 그럼 오른쪽에 파란색 영역표시 되는 부분에서 우클릭 후 Copy - Copy selector 를 눌러 값을 복사합니다.
selector의 전체 부분이 다 필요한 것은 아닙니다. 클래스명이 겹치지 않는다는 가정 하에 div.review_table부터 가져오고 리스트의 첫번째 항목에 해당하는 :nth-child(1)를 지워 전체 값을 다 가져오도록 코드에 넣습니다.
원래 selector 값
#content > div > div > div > div.review_table > div:nth-child(1) > div.col-xs-8 > div.col-sm-13.col-xs-24.col-sm-pull-4.critic_name > a.unstyled.bold.articleLink
>>> name = soup.select(
'div.review_table > div > div.col-xs-8 > div.col-sm-13.col-xs-24.col-sm-pull-4.critic_name > a.unstyled.bold.articleLink'
)
>>> print(name)
[<a class="unstyled bold articleLink" href="/critic/jeremy-jahns">Jeremy Jahns</a>, <a class="unstyled bold articleLink" href="/critic/sebastian-zavala-kahn">Sebastian Zavala Kahn</a>, <a class="unstyled bold articleLink" href="/critic/paul-whitington-15988">Paul Whitington</a>, <a class="unstyled
...
>>> print(name[0])
<a class="unstyled bold articleLink" href="/critic/jeremy-jahns">Jeremy Jahns</a>
>>> print(name[0].text)
Jeremy Jahns가져온 값(name)은 리스트로 되어 있으며 원하는 텍스트를 가져오는 방법은 마지막 줄과 같습니다.
이와 같이 소속, 평가, 날짜도 가져옵니다. 그런 다음 zip함수로 리스트로 묶고, replace함수로 불필요한 텍스트를 제거하는 과정을 거치면 원하는 값만 가져올 수 있습니다.
3. 나머지 항목까지 모두 크롤링하기
>>> name = soup.select(
'div.review_table > div > div.col-xs-8 > div.col-sm-13.col-xs-24.col-sm-pull-4.critic_name > a.unstyled.bold.articleLink'
)
>>> belongto = soup.select(
'div.review_table > div > div.col-xs-8 > div.col-sm-13.col-xs-24.col-sm-pull-4.critic_name > a > em'
)
>>> review = soup.select(
'div.review_table > div > div.col-xs-16.review_container > div.review_area > div.review_desc > div.the_review'
)
>>> created_at = soup.select(
'div.review_table > div > div.col-xs-16.review_container > div.review_area > div.review-date.subtle.small'
)
>>> movie_review = []
>>> for item in zip(name, belongto, review, created_at):
movie_review.append(
{
'name' : item[0].text.replace('\n', '').replace('\t', '').replace(' ', ''),
'belongto' : item[1].text.replace('\n', '').replace('\t', '').replace(' ', ''),
'review' : item[2].text.replace('\n', '').replace('\t', '').replace(' ', ''),
'created_at': item[3].text.replace('\n', '').replace('\t', '').replace(' ', ''),
}
)
>>> print(movie_review)
[{'name': 'Jeremy Jahns', 'belongto': 'Me gusta el cine', 'review': 'The movie itself - message aside - is remarkably entertaining.', 'created_at': 'February 13, 2020'}, {'name': 'Sebastian Zavala Kahn', 'belongto': 'Irish Independent', 'review': 'It conveys very clear messages about classism and discrimination, [all through] an entertaining and visually arresting story. [Full review in Spanish]', 'created_at': 'February 12, 2020'}, {'name': 'Paul Whitington', 'belongto': 'entertainment.ie', 'review': "It's a splendid film, beautifully acted and realised, which manages to be both entertaining and profound.", 'created_at': 'February 12, 2020'}, {'name': 'Deirdre Molumby', 'belongto': 'Independent (UK)', 'review': 'A breath-taking cinematic accomplishment that will have you talking for days', 'created_at': 'February 12, 2020'}, {'name': 'Clarisse Loughrey', 'belongto': 'The Jewish Chronicle', 'review': "[Bong Joon-ho]'s work is as playful as it is sincere and revelatory.
4. 20페이지까지 크롤링 후 파일로 저장하기
1페이지 크롤링을 완성했습니다. 20페이지까지 하기 위해 url list를 만들고 for문으로 코드를 수정합니다. 아래는 최종코드입니다. csv 저장을 위해 pandas 라이브러리도 설치해 가져옵니다. 리스트 형식으로만 결과를 뽑으면 판다스를 이용해 손쉽게 파일로 저장할 수 있습니다.
import requests
import pandas as pd
from bs4 import BeautifulSoup
ran = range(1,21)
url = "https://www.rottentomatoes.com/m/parasite_2019/reviews?type=&sort=&page="
url_list = []
for r in ran:
url_list.append(url+str(r))
print(url_list)
movie_review = []
for url in url_list:
req = requests.get(url)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
name = soup.select(
'div.review_table > div > div.col-xs-8 > div.col-sm-13.col-xs-24.col-sm-pull-4.critic_name > a.unstyled.bold.articleLink'
)
belongto = soup.select(
'div.review_table > div > div.col-xs-8 > div.col-sm-13.col-xs-24.col-sm-pull-4.critic_name > a > em'
)
review = soup.select(
'div.review_table > div > div.col-xs-16.review_container > div.review_area > div.review_desc > div.the_review'
)
created_at = soup.select(
'div.review_table > div > div.col-xs-16.review_container > div.review_area > div.review-date.subtle.small'
)
for item in zip(name, belongto, review, created_at):
movie_review.append(
{
'name' : item[0].text.replace('\n', '').replace('\t', '').replace(' ', ''),
'belongto' : item[1].text.replace('\n', '').replace('\t', '').replace(' ', ''),
'review' : item[2].text.replace('\n', '').replace('\t', '').replace(' ', ''),
'created_at': item[3].text.replace('\n', '').replace('\t', '').replace(' ', ''),
}
)
data = pd.DataFrame(movie_review)
data.to_csv('movie_review.csv')