🧷 서울 CCTV 분석
🖇️ 목표
- 서울시 구별 CCTC 현황데이터 확보──┐
- 인구 현황 데이터 확보 ───── ──┤
- CCTV데이터와 인구형황 데이터 합치기 ┤--- Pyhton, Pandas
- 데이터를 정리하고 정렬───────┘
- 그래프를 그릴 수 있는 능력 -Matplotlib
- 전체적인 경향을 파악가능한 능력 -Regression using Numpy
- 그 경향에서 벗어난 데이터를 강조하는 능력 - insight and Visualization
🖇️ Pandas로 csv,엑셀 파일 읽기
Pandas: powerful Python data analysis toolkit
- 파이썬에서 R만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용가능한 엑셀
import pandas as pd
CCTV_Seoul = pd.read_csv("data\\01.Seoul_CCTV.csv", encoding="euc-kr")
CCTV_Seoul.head()-통상csv는 띄어쓰기로 구분되니 read_csv명령으로 읽기만 해도 됨
-긴 파일명을 끝까지 입력하지말고 적당한 곳에서 Tab키
-한글은 encoding 필요 ※encoding에 'utf-8'또는'euc-kr'또는 'cp949' 입력필요
-head()는 파일이 긴 경우에 앞부분 5개만 보여달라는 뜻
─ column의 이름 조회 가능
CCTV_Seoul.columns⇊
ndex(['구분', '총계', '2013년 이전\n설치된 CCTV', '2013년', '2014년', '2015년', '2016년',
'2017년', '2018년', '2019년',
...
'Unnamed: 16374', 'Unnamed: 16375', 'Unnamed: 16376', 'Unnamed: 16377',
'Unnamed: 16378', 'Unnamed: 16379', 'Unnamed: 16380', 'Unnamed: 16381',
'Unnamed: 16382', 'Unnamed: 16383'],
dtype='object', length=16384)CCTV_Seoul.columns[0]⇊
'구분'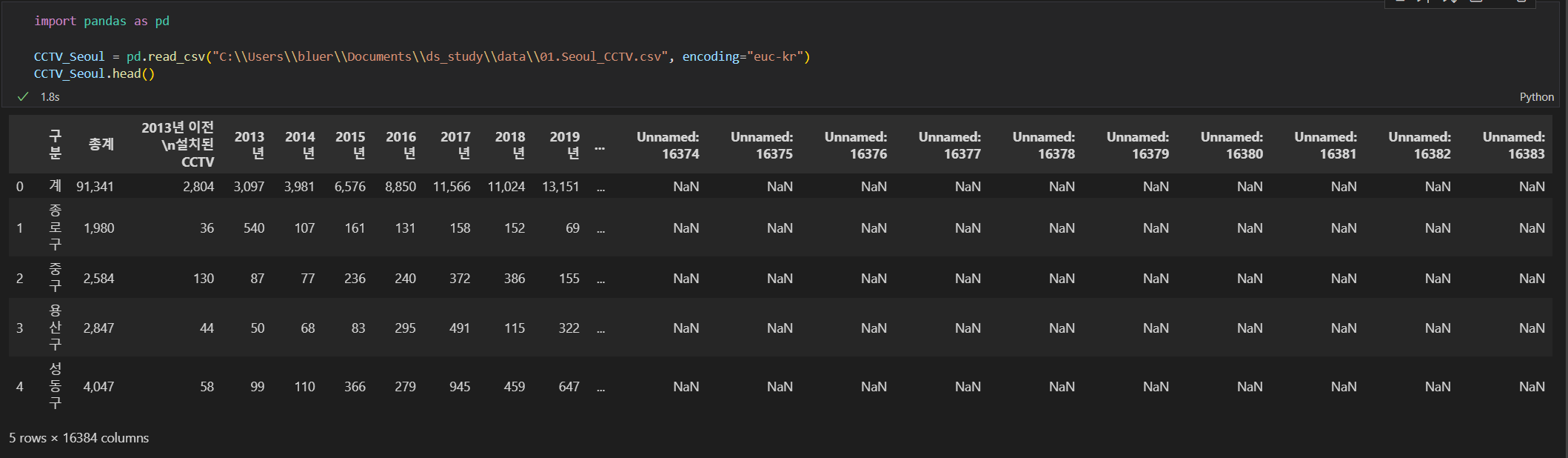
in visual studio code
- column 이름 변경시
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: '구별'}, inplace=True)
CCTV_Seoul.head()⇊
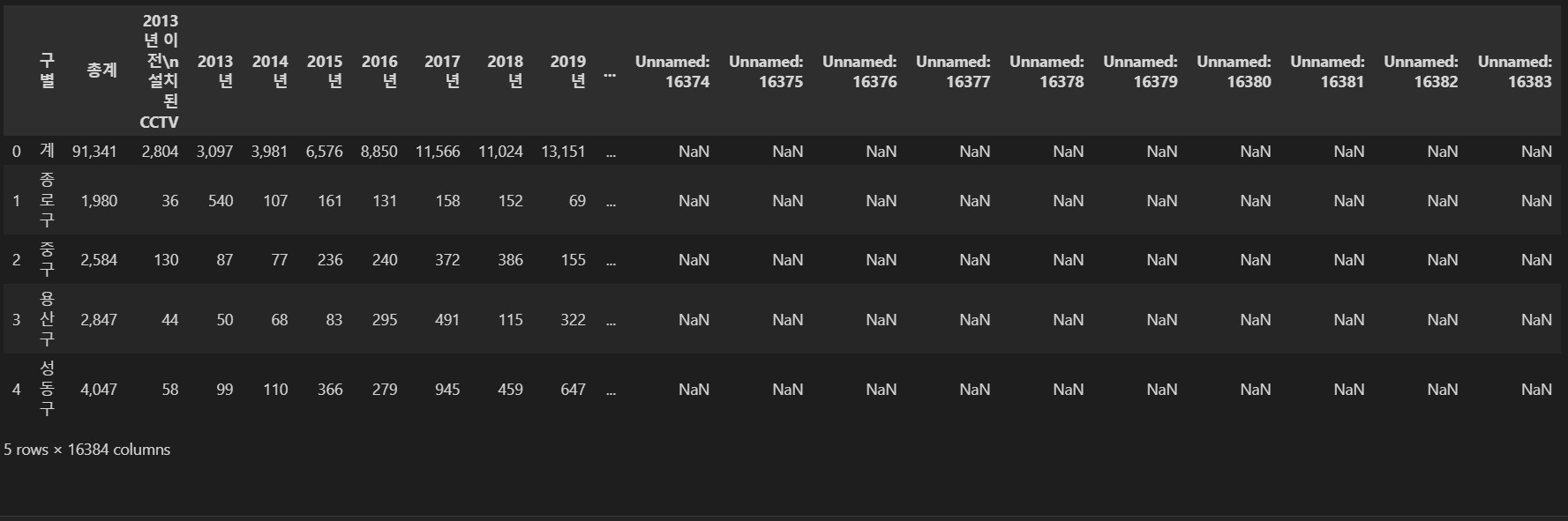
in visual studio code
─ 엑셀 파일 열기
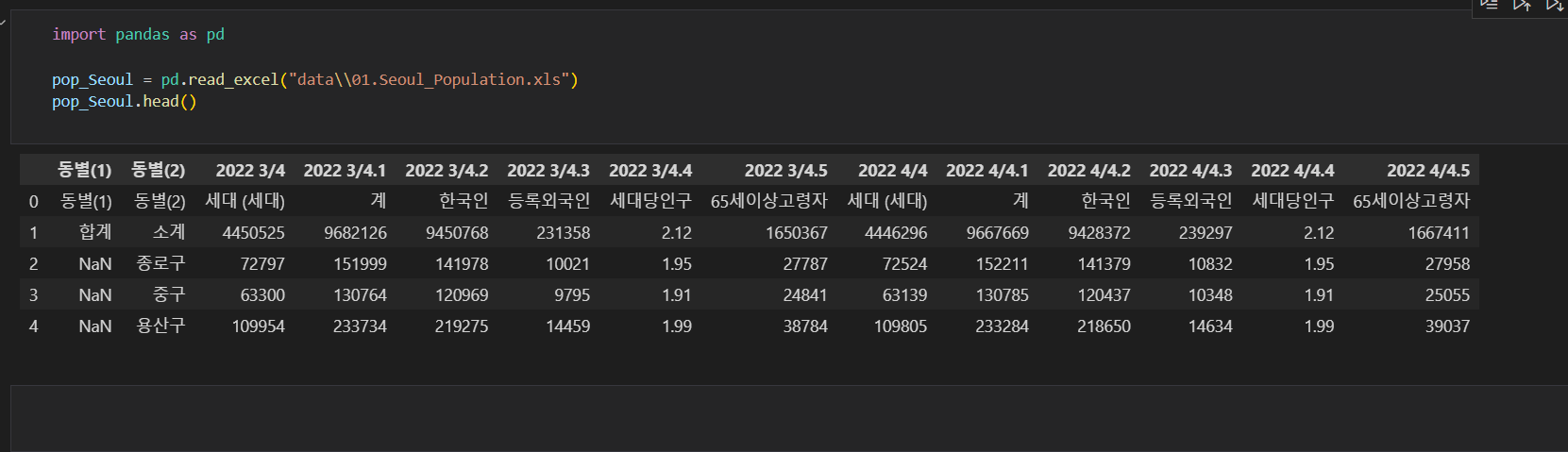
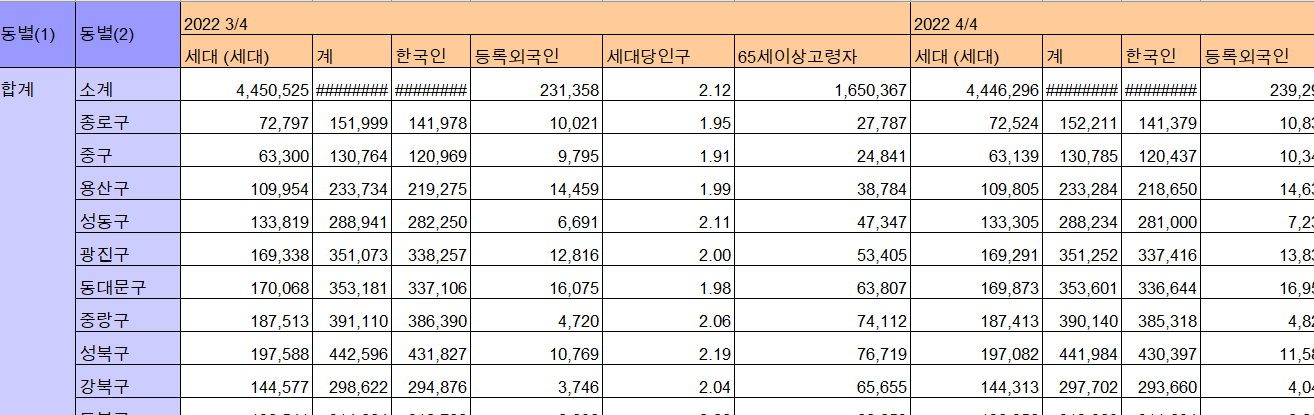
-판다스는 셀병합이 없기떄문에 엑셀에서 셀병합이 된 데이터는 판다스에서 다 풀어져서 나타남
import pandas as pd
pop_Seoul = pd.read_excel('data\\01.Seoul_Population.xls', header=1, usecols='B, C, E, F, G')
pop_Seoul.head()⇊
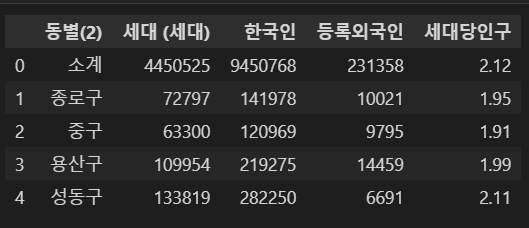
-자료를 읽기 시작할 행(header)를 지정
-읽어올 컬럼(usecols) 지정
─ 컬럼 이름 바꾸기
pop_Seoul.rename(columns={pop_Seoul.columns[0]: "구별",
pop_Seoul.columns[1]: "인구수",
pop_Seoul.columns[2]: "한국인",
pop_Seoul.columns[3]: "외국인",
pop_Seoul.columns[4]: "고령자"}, inplace=True)
pop_Seoul.head()⇊

🖇️ Pandas 기초
- pandas는 통상 pd로 import 함
- 수치해석적 함수가 많은 numpy는 통상 np로 import 함
import pandas as pd
import numpy as np
s= pd.Series([1, 3, 5, np.nan, 6, 8])
s⇊
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64-Pandas의 데이터형을 구성하는 기본은 Series
- 날짜(시간) 이용가능
dates = pd.date_range('20230329', periods=6)
dates⇊
DatetimeIndex(['2023-03-29', '2023-03-30', '2023-03-31', '2023-04-01',
'2023-04-02', '2023-04-03'],
dtype='datetime64[ns]', freq='D')─DataFrame
- pandas에서 가장 많이 사용되는 데이터형은 DataFrame
- index와 columns를 지정하면 됨
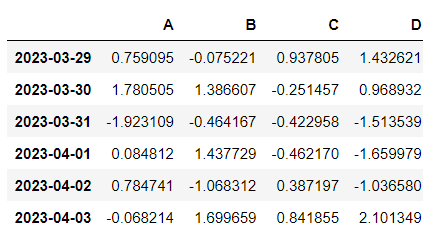
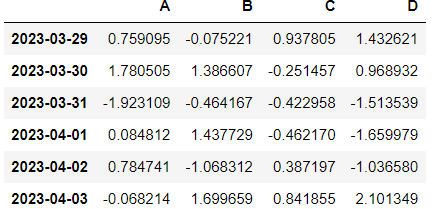
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=['A', 'B', 'C', 'D'])
df⇊
─info()
- DataFrame의 기본 정보 확인
- 각 컬럼의 크기와 데이터형태를 확인하는 경우가 많음
df.info()
⇊
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 6 entries, 2023-03-29 to 2023-04-03
Freq: D
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 6 non-null float64
1 B 6 non-null float64
2 C 6 non-null float64
3 D 6 non-null float64
dtypes: float64(4)
memory usage: 240.0 bytes─describe()
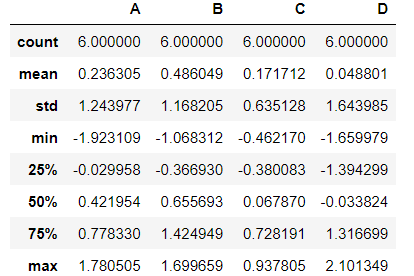
- DataFrame의 통계적 기본정보 확인
ex) 데이터가 컬럼별로 몇개씩 있는지, 평균은 얼마인지, 표준편차는 얼마인지, 최솟값, 4분의 1지점, 2분의 1지점, 4분의 3지점, 최대값 등
df.describe()
⇊
─sort_values()
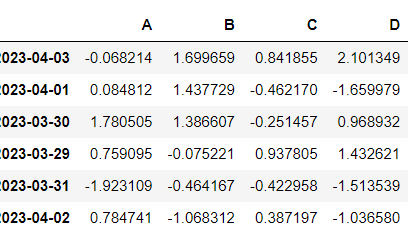
- 데이터를 정렬
df.sort_values(by='B', ascending=False)
⇊
─특정 컬럼만 읽기
df['A']
⇊
2023-03-29 0.759095
2023-03-30 1.780505
2023-03-31 -1.923109
2023-04-01 0.084812
2023-04-02 0.784741
2023-04-03 -0.068214
Freq: D, Name: A, dtype: float64─슬라이싱
- [n:m] : n부터 m-1까지
- 인덱스나 칼럼 이름으로 슬라이싱하는 경우는 m까지 포함
df[0:3]
⇊

─ loc[행,열]
- 이름으로도 사용 가능
-Pandas의 보편적인 슬라이싱 옵션
df.loc[:, ['A', 'B']]
⇊
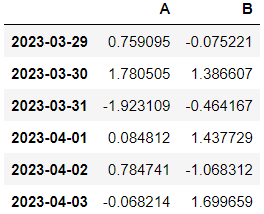
df.loc['20230329':'20230331',['A','B']]'
⇊
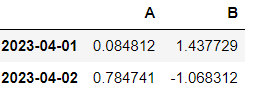
─iloc[행,열]
- 번호로만 접근
df.iloc[3]
⇊
A 0.084812
B 1.437729
C -0.462170
D -1.659979
Name: 2023-04-01 00:00:00, dtype: float64df.iloc[3:5, 0:2]
⇊
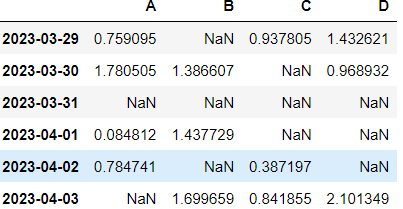
─df
- df[condition] 같이 사용하는 것이 일반적
- Pandas 버전에 따라 조금씩 허용되는 문법이 다름
df[df > 0]0보다 작은것은 NaN(Not a Number)처리 됨
⇊
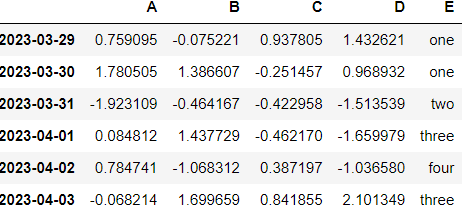
df['E'] = ['one', 'one', 'two', 'three', 'four', 'three']
df리스트안 데이터값을 가진 E 컬럼을 새로 생성
⇊
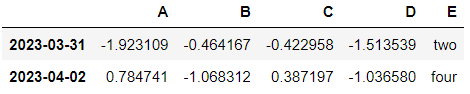
df['E'].isin(['two', 'four'])특정 요소가 있는지 확인
⇊
2023-03-29 False
2023-03-30 False
2023-03-31 True
2023-04-01 False
2023-04-02 True
2023-04-03 False
Freq: D, Name: E, dtype: booldf[df['E'].isin(['two', 'four'])]특정 요소가 있는 행만 선택
⇊
─del
특정 컬럼 제거
del df['E']
df⇊

─apply()
함수적용
- np.cumsum : 각 컬럼 누적합
df.apply(np.cumsum)⇊
df['A'].apply('sum')합계
⇊
1.417830998246393
df['A'].apply('mean')평균
⇊
0.23630516637439883
df['A'].apply('min'), df['A'].apply('max')최솟값, 최댓값
⇊
(-1.92310857808862, 1.7805054764336063)
