🖇️ 데이터 확인
- '총계'에서 CCTV수가 가장 적은 순부터 차례대로 나열
CCTV_Seoul.sort_values(by="총계", ascending=True).head(5)⇊

- '총계'에서 CCTV수가 가장 많은 순부터 차례대로 나열
CCTV_Seoul.sort_values(by="총계", ascending=False).head(5)⇊

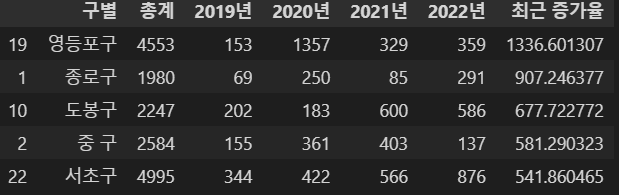
- 최근 3년간 그 전 보유한 갯수 대비 CCTV를 많이 설치한 구를 순서대로 나열
CCTV_Seoul["최근 증가율"] = ((CCTV_Seoul["2022년"] + CCTV_Seoul["2021년"] + CCTV_Seoul["2020년"]) / CCTV_Seoul["2019년"] * 100)
CCTV_Seoul.sort_values(by="최근 증가율", ascending=False).head(5)⇊
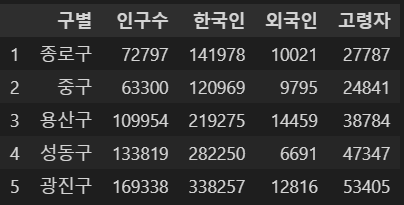
🖇️ 인구 현황 데이터 훑어보기
pop_Seoul.rename(columns={pop_Seoul.columns[0]: "구별",
pop_Seoul.columns[1]: "인구수",
pop_Seoul.columns[2]: "한국인",
pop_Seoul.columns[3]: "외국인",
pop_Seoul.columns[4]: "고령자"}, inplace=True)
pop_Seoul.head()⇊

─ drop()
행을 지우는 명령
- drop(axis =0) : 행 삭제 , 기본적으로 설정되어있는 값
- drop(axis = 1) : 열 삭제
pop_Seoul.drop([0], inplace=True)
pop_Seoul.head()⇊
─unique()
여러번 등장하는 걸 한번씩만 볼 수 있게 해줌
*데이터가 많아지면 unique를 이용하여 데이터를 초반 검증함
pop_Seoul["구별"].unique()⇊
array(['종로구', '중구', '용산구', '성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구',
'도봉구', '노원구', '은평구', '서대문구', '마포구', '양천구', '강서구', '구로구', '금천구',
'영등포구', '동작구', '관악구', '서초구', '강남구', '송파구', '강동구'], dtype=object)- 한 번이상 나오는 구의 갯수
len(pop_Seoul["구별"].unique())⇊
25- 외국인 비율과 고령자 비율 생성
- column 연산이 편하다는 것이 Python의 장점
pop_Seoul["외국인비율"] = pop_Seoul["외국인"] / pop_Seoul["인구수"] * 100
pop_Seoul["고령자비율"] = pop_Seoul["고령자"] / pop_Seoul["인구수"] * 100
pop_Seoul.head()⇊
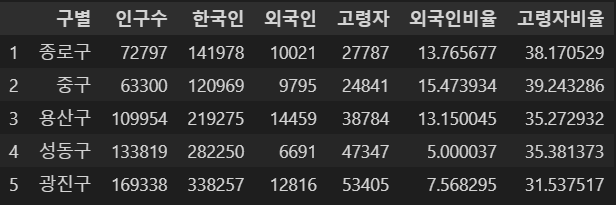
- 인구수가 많은 구부터 내림차순으로 나열
pop_Seoul.sort_values(by="인구수", ascending=False).head(5)⇊

- 외국인이 많은 구부터 내림차순으로 나열
pop_Seoul.sort_values(by="외국인", ascending=False).head(5)⇊
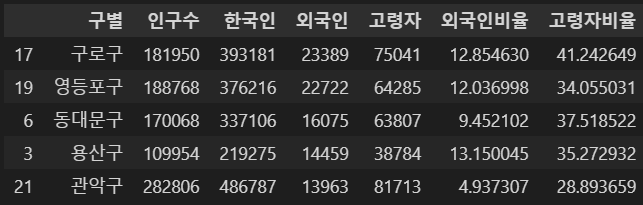
- 고령자가 많은 구부터 내림차순으로 나열
pop_Seoul.sort_values(by="고령자", ascending=False).head(5)⇊

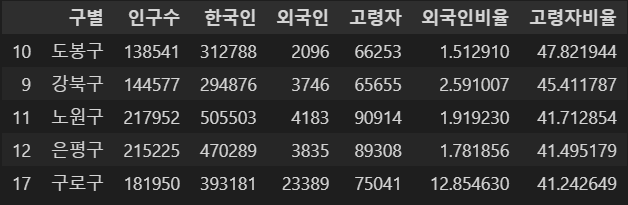
- 고령자 비율이 높은 순부터 내림차순으로 나열
pop_Seoul.sort_values(by="고령자비율", ascending=False).head(5)⇊
🖇️ Pandas 데이터 합치기
- pd.concat()
- pd.merge()
- pd.join()
─ merge
- merge를 이용한 데이터 병합
- Pands DataFrame 데이터끼리의 병합은 빈번히 발생
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키Key값이라고 함
- 기준이 되는 키값은 두 데이터 프레임 안에 모두 포함되어 있어야 함
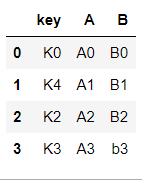
left = pd.DataFrame(
{
"key" : ["K0", "K4", "K2", "K3"],
"A" : ["A0", "A1", "A2", "A3"],
"B" : ["B0", "B1", "B2", "b3"]
}
)
right = pd.DataFrame(
{
"key" : ["K0", "K1", "K2", "K3"],
"C" : ["C0", "C1", "C2", "C3"],
"D" : ["D0", "D1", "D2", "D3"]
}
)left
⇊
right
⇊

- Key 컬럼 기준으로 공통으로 가지고있는 것들로만 병합
pd.merge(left, right, on="key")⇊
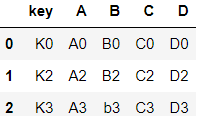
- left의 key를 기준으로(left의 key들 다 보존) right 병합
- right에는 K4자리가 없기때문에 NaN으로 출력
pd.merge(left, right, how="left", on="key")⇊
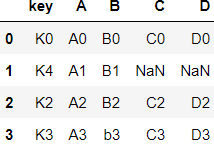
- 둘 다 손상되지않도록 Key를 기준으로 병합
- outer: 가장 확대. 두 데이터 프레임 값을 살림. 합집합
pd.merge(left, right, how="outer", on="key")⇊

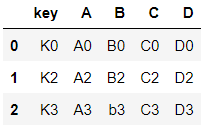
- key 칼럼에서 두 데이터의 공통분모만 병합
- inner: 교집합
pd.merge(left, right, how="inner", on="key")⇊
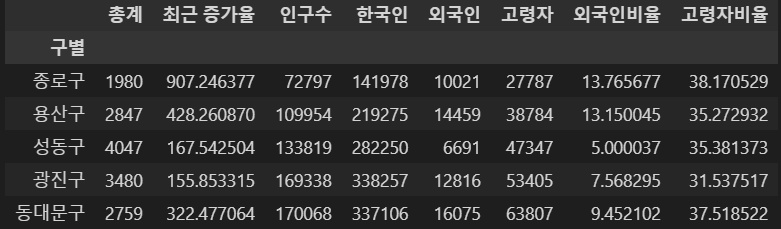
- CCTV 데이터에도 적용
data_result = pd.merge(CCTV_Seoul, pop_Seoul, on="구별")
data_result.head()⇊

- 필요없는 컬럼 삭제
del data_result['2019년']
del data_result['2020년']
del data_result['2021년']
del data_result['2022년']
data_result.head()⇊
─ set_index()
index를 재지정하는 명령
- Pandas index 지정
- Index를 잡을때는 중복되는게 없어야함 ex)강남구가 2개 있다던지..
data_result.set_index("구별", inplace=True) ##나중에 그래프 그릴때 편함
data_result.head()⇊
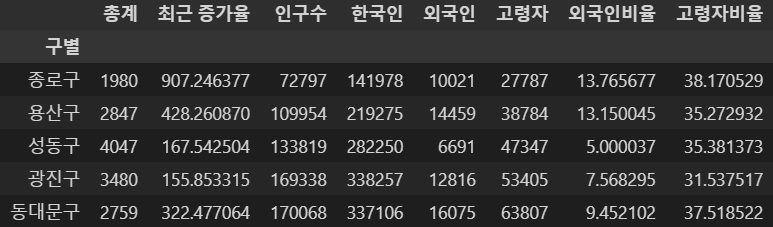
─ 상관관계(Correlation)
두 변량 사이에 한쪽이 증가하면 다른쪽도 증가(혹은 감소)하는 경향이 있을 때, 이 두 변량 사이에는 상관관계 가 있다고 함
- 단, 상관관계가 있다고 하여 두 변량이 인과관계인 것은 아님
- 데이터의 관계를 찾을 떄, 최소한의 근거가 있어야 해당 데이터를 비교하는 의미가 존재
- 상관계수를 조사해서 0.2이상의 데이터를 비교하는 건 의미가 있음

data_result.corr()
⇊
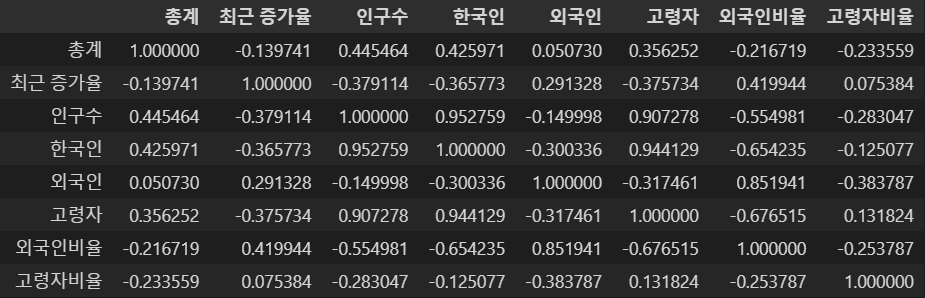
-CCTV전체 수 (총계)와 가장 상관관계가 있는 데이터는 인구수
∴구별 인구대비 CCTV현황을 분석해서 상대적으로 CCTV가 적거나 많은 구를 찾는 것은 의미가 있음
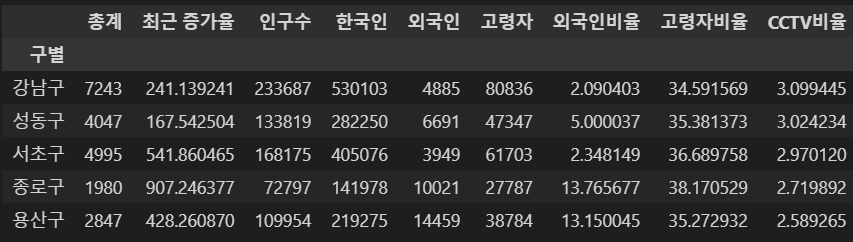
- CCTV비율이 높은 구 확인
data_result["CCTV비율"] = data_result["총계"] / data_result["인구수"]
data_result["CCTV비율"] = data_result["CCTV비율"] * 100
data_result.sort_values(by="CCTV비율", ascending=False).head(5)⇊
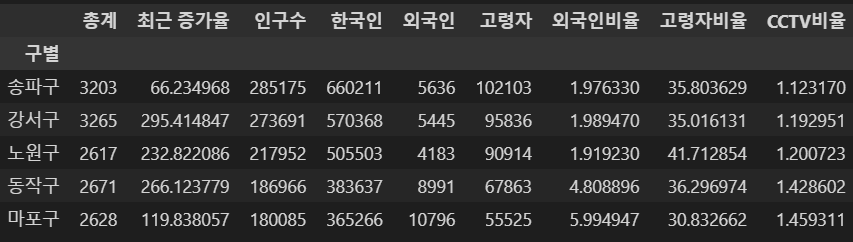
- CCTV비율이 낮은 구 확인
data_result.sort_values(by="CCTV비율", ascending=True).head(5)⇊
from.제로베이스 데이터 취업스쿨 강의
++사족
서울시 데이터 광장에 있던 csv파일을 그대로 쓰려니 utf-8로 인코딩도 안되고, 수많은 NaN 투성이에, 안의 값을 문자열로 받아들여서 결국 엑셀에서 확인해봤더니, 값에 해당하는 셀서식이 '통화'로 되어있는게 있어서 오류가 난것으로 판명.
'숫자'로 싹다 바꾸고 저장했더니 인코딩도 utf-8로 되고 NaN들도 없어지고 해결.