🧷 웹데이터 분석
🖇️ Beautiful Soup
태그로 되어있는 문서를 해석하는 기능을 가진 파이썬 모듈
from bs4 import BeautifulSouppage = open('../data/03. test_first.html', 'r').read()
soup = BeautifulSoup(page, 'html.parser')
print(soup.prettify())⇊
<!DOCTYPE html>
<html>
<head>
<title>
Very Simple HTML Code by PinkWink
</title>
</head>
<body>
<div>
<p class="inner-text first-item" id="first">
Happy PinkWink.
<a href="http://www.pinkwink.kr" id="pw-link">
PinkWink
</a>
</p>
<p class="inner-text second-item">
Happy Data Science.
<a href="https://www.python.org" id="py-link">
Python
</a>
</p>
</div>
<p class="outer-text first-item" id="second">
<b>
Data Science is funny.
</b>
</p>
<p class="outer-text">
<b>
All I need is Love.
</b>
</p>
</body>
</html>- html 파일을 읽을때
- open: 파일명과 함꼐 읽기(r), 쓰기(w) 속성 지정
- html.parser: Beautiful SOup의 html을 읽는 엔진 중 하나(lxml도 많이 사용)
-prettify(): html 출력을 이쁘게 만들어 주는 기능(들여쓰기가 들어간 상태)
soup.body⇊
<body>
<div>
<p class="inner-text first-item" id="first">
Happy PinkWink.
<a href="http://www.pinkwink.kr" id="pw-link">PinkWink</a>
</p>
<p class="inner-text second-item">
Happy Data Science.
<a href="https://www.python.org" id="py-link">Python</a>
</p>
</div>
<p class="outer-text first-item" id="second">
<b>
Data Science is funny.
</b>
</p>
<p class="outer-text">
<b>
All I need is Love.
</b>
</p>
</body>- body: body태그만 보고 싶은 경우
soup.find('p')⇊
<p class="inner-text first-item" id="first">
Happy PinkWink.
<a href="http://www.pinkwink.kr" id="pw-link">PinkWink</a>
</p>- find(): 특정 태그를 찾아줌(단, 맨 먼저 보여지는 하나만 찾을 수 있음)
soup.find_all('p')⇊
[<p class="inner-text first-item" id="first">
Happy PinkWink.
<a href="http://www.pinkwink.kr" id="pw-link">PinkWink</a>
</p>,
<p class="inner-text second-item">
Happy Data Science.
<a href="https://www.python.org" id="py-link">Python</a>
</p>,
<p class="outer-text first-item" id="second">
<b>
Data Science is funny.
</b>
</p>,
<p class="outer-text">
<b>
All I need is Love.
</b>
</p>]- find_all(): 지정된 태그를 전부 찾아줌 (리스트형 데이터로)
for each_tag in soup.find_all('p'):
print('------------------')
print(each_tag.get_text())⇊
------------------
Happy PinkWink.
PinkWink
------------------
Happy Data Science.
Python
------------------
Data Science is funny.
------------------
All I need is Love.- get_text(): 태그로 쌓여져 있는 글자를 가져오는 함수
links = soup.find_all('a')
links⇊
[<a href="http://www.pinkwink.kr" id="pw-link">PinkWink</a>,
<a href="https://www.python.org" id="py-link">Python</a>]for each in links:
href = each['href']
text = each.string
print(text + '->' + href)⇊
PinkWink->http://www.pinkwink.kr
Python->https://www.python.org- 외부로 연결되는 링크 주소 알아내는 법
🖇️ 크롬 개발자 도구 이용
from urllib.request import urlopen#url = 'https://finance.naver.com/marketindex/'
url = 'https://finance.naver.com/marketindex/'
page = urlopen(url)
soup = BeautifulSoup(page, 'html.parser')
print(soup.prettify())⇊
Output exceeds the size limit. Open the full output data in a text editor
<script language="javascript" src="/template/head_js.naver?referer=info.finance.naver.com&menu=marketindex&submenu=market">
</script>
<script src="https://ssl.pstatic.net/imgstock/static.pc/20230321170048/js/info/jindo.min.ns.1.5.3.euckr.js" type="text/javascript">
</script>
<script src="https://ssl.pstatic.net/imgstock/static.pc/20230321170048/js/jindo.1.5.3.element-text-patch.js" type="text/javascript">
</script>
<div id="container" style="padding-bottom:0px;">
<div class="market_include">
<div class="market_data">
<div class="market1">
<div class="title">
<h2 class="h_market1">
<span>
환전 고시 환율
</span>
</h2>
</div>
<!-- data -->
<div class="data">
<ul class="data_lst" id="exchangeList">
<li class="on">
<a class="head usd" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW" onclick="clickcr(this, 'fr1.usdt', '', '', event);">
<h3 class="h_lst">
<span class="blind">
미국 USD
...
window.addEventListener('mousedown', gnbLayerClose);
}
</script>- 웹주소(url)에 접근할 때는 urllib의 request모듈 필요
- response, res 도 많이 사용
url = 'https://finance.naver.com/marketindex/'
response = urlopen(url)
response.status⇊
200
- response: http 상태 코드,정상적으로 요청을 했고 정상적으로 응답을 받았다는 코드
- 결과값은 어떤 상태인지 표현
ㄴ http 상태코드
import requests
#from urllib.request.Request
from bs4 import BeautifulSoupurl = 'https://finance.naver.com/marketindex/'
response = requests.get(url)
# response.text
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())⇊
Output exceeds the size limit. Open the full output data in a text editor
<script language="javascript" src="/template/head_js.naver?referer=info.finance.naver.com&menu=marketindex&submenu=market">
</script>
<script src="https://ssl.pstatic.net/imgstock/static.pc/20230321170048/js/info/jindo.min.ns.1.5.3.euckr.js" type="text/javascript">
</script>
<script src="https://ssl.pstatic.net/imgstock/static.pc/20230321170048/js/jindo.1.5.3.element-text-patch.js" type="text/javascript">
</script>
<div id="container" style="padding-bottom:0px;">
<div class="market_include">
<div class="market_data">
<div class="market1">
<div class="title">
<h2 class="h_market1">
<span>
환전 고시 환율
</span>
</h2>
</div>
<!-- data -->
<div class="data">
<ul class="data_lst" id="exchangeList">
<li class="on">
<a class="head usd" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW" onclick="clickcr(this, 'fr1.usdt', '', '', event);">
<h3 class="h_lst">
<span class="blind">
미국 USD
...
window.addEventListener('mousedown', gnbLayerClose);
}
</script>- find, select_one :단일 선택
- find_all, select: 다중선택
exchangeList = soup.select('#exchangeList > li') #바로 밑 하위데이터들
len(exchangeList), exchangeList⇊
Output exceeds the size limit. Open the full output data in a text editor
(4,
[<li class="on">
<a class="head usd" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW" onclick="clickcr(this, 'fr1.usdt', '', '', event);">
<h3 class="h_lst"><span class="blind">미국 USD</span></h3>
<div class="head_info point_up">
<span class="value">1,315.00</span>
<span class="txt_krw"><span class="blind">원</span></span>
<span class="change">2.00</span>
<span class="blind">상승</span>
</div>
</a>
<a class="graph_img" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW" onclick="clickcr(this, 'fr1.usdc', '', '', event);">
<img alt="" height="153" src="https://ssl.pstatic.net/imgfinance/chart/marketindex/FX_USDKRW.png" width="295"/>
</a>
<div class="graph_info">
<span class="time">2023.04.04 16:13</span>
<span class="source">하나은행 기준</span>
<span class="count">고시회차<span class="num">579</span>회</span>
</div>
</li>,
<li class="">
<a class="head jpy" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_JPYKRW" onclick="clickcr(this, 'fr1.jpyt', '', '', event);">
<h3 class="h_lst"><span class="blind">일본 JPY(100엔)</span></h3>
<div class="head_info point_up">
<span class="value">991.37</span>
...
<span class="time">2023.04.04 16:13</span>
<span class="source">하나은행 기준</span>
<span class="count">고시회차<span class="num">579</span>회</span>
</div>
</li>])title = exchangeList[0].select_one('.h_lst').text #제목
exchange = exchangeList[0].select_one('.value').text # 현재 환율
change = exchangeList[0].select_one('.change'). text # 환율 변화값
updown = exchangeList[0].select_one('div.head_info.point_up > .blind').text #>를 주면 div.head_info.point_up의 바로 밑의 하위 데이터 반환
title, exchange, change, updown⇊
('미국 USD', '1,315.00', '2.00', '상승')- id => # , class => .
- id는 단 하나씩만 존재
- '>' 는 '>'표시 앞에 있는 클래스의 바로 밑 데이터 반환
baseUrl = 'https://finance.naver.com'
baseUrl +exchangeList[0].select_one('a').get('href')⇊
'https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW'#4개 데이터 수집
exchange_datas = []
baseUrl = 'https://finance.naver.com'
for item in exchangeList:
data = {
'title':item.select_one('.h_lst').text,
'exchange':item.select_one('.value').text,
'change':item.select_one('.change').text,
'updown':item.select_one('.head_info > .blind').text,
'link':baseUrl + item.select_one('a').get('href')
}
exchange_datas.append(data)
df = pd.DataFrame(exchange_datas)
df⇊

🖇️ 위키백과 문서 정보 가져오기
import urllib
from urllib.request import Request
html = 'https://ko.wikipedia.org/wiki/{search_words}' #중괄호가 들어가면 문자열(str)에서 변수가 됨
req = Request(html.format(search_words=urllib.parse.quote('여명의_눈동자')))
response = urlopen(req)
soup = BeautifulSoup(response, 'html.parser')
soup⇊
Output exceeds the size limit. Open the full output data in a text editor
<!DOCTYPE html>
<html class="client-nojs vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-language-alert-in-sidebar-enabled vector-feature-sticky-header-disabled vector-feature-page-tools-enabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-enabled vector-feature-main-menu-pinned-disabled vector-feature-limited-width-enabled vector-feature-limited-width-content-enabled" dir="ltr" lang="ko">
<head>
<meta charset="utf-8"/>
<title>여명의 눈동자 - 위키백과, 우리 모두의 백과사전</title>
<script>document.documentElement.className="client-js vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-language-alert-in-sidebar-enabled vector-feature-sticky-header-disabled vector-feature-page-tools-enabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-enabled vector-feature-main-menu-pinned-disabled vector-feature-limited-width-enabled vector-feature-limited-width-content-enabled";(function(){var cookie=document.cookie.match(/(?:^|; )kowikimwclientprefs=([^;]+)/);if(cookie){var featureName=cookie[1];document.documentElement.className=document.documentElement.className.replace(featureName+'-enabled',featureName+'-disabled');}}());RLCONF={"wgBreakFrames":false,"wgSeparatorTransformTable":["",""],"wgDigitTransformTable":["",""],"wgDefaultDateFormat":"ko","wgMonthNames":["","1월","2월","3월","4월","5월","6월","7월","8월","9월","10월","11월","12월"],"wgRequestId":"fa90b647-63d7-4ebc-ae46-bd412f65665a",
"wgCSPNonce":false,"wgCanonicalNamespace":"","wgCanonicalSpecialPageName":false,"wgNamespaceNumber":0,"wgPageName":"여명의_눈동자","wgTitle":"여명의 눈동자","wgCurRevisionId":34684388,"wgRevisionId":34684388,"wgArticleId":51472,"wgIsArticle":true,"wgIsRedirect":false,"wgAction":"view","wgUserName":null,"wgUserGroups":["*"],"wgCategories":["깨진 링크를 가지고 있는 문서","인용 오류 - 지원되지 않는 변수 무시됨","인용 오류 - URL 없이 확인날짜를 사용함","백상예술대상 TV부문 대상 수상자(작)","백상예술대상 TV부문 작품상","1991년 드라마","문화방송 수목 미니시리즈","문화방송의 역사 드라마","일제강점기 역사 드라마","한국 현대사 드라마","대한민국의 소설을 바탕으로 한 텔레비전 드라마","송지나 시나리오 작품","1991년에 시작한 대한민국 TV 프로그램","1992년에 종료한 대한민국 TV 프로그램","한국의 반일 감정",
"1990년대 대한민국의 텔레비전 프로그램"],"wgPageContentLanguage":"ko","wgPageContentModel":"wikitext","wgRelevantPageName":"여명의_눈동자","wgRelevantArticleId":51472,"wgIsProbablyEditable":true,"wgRelevantPageIsProbablyEditable":true,"wgRestrictionEdit":[],"wgRestrictionMove":[],"wgVisualEditor":{"pageLanguageCode":"ko","pageLanguageDir":"ltr","pageVariantFallbacks":"ko"},"wgMFDisplayWikibaseDescriptions":{"search":true,"watchlist":true,"tagline":true,"nearby":true},"wgWMESchemaEditAttemptStepOversample":false,"wgWMEPageLength":30000,"wgNoticeProject":"wikipedia","wgVector2022PreviewPages":[],"wgMediaViewerOnClick":true,"wgMediaViewerEnabledByDefault":true,"wgPopupsFlags":10,"wgULSCurrentAutonym":"한국어","wgEditSubmitButtonLabelPublish":true,"wgCentralAuthMobileDomain":false,"wgULSPosition":"interlanguage","wgULSisCompactLinksEnabled":true,"wgULSisLanguageSelectorEmpty":false,"wgWikibaseItemId":"Q624988","GEHomepageSuggestedEditsEnableTopics":true,
"wgGETopicsMatchModeEnabled":false,"wgGEStructuredTaskRejectionReasonTextInputEnabled":false,"wgGELevelingUpEnabledForUser":false};RLSTATE={"skins.vector.user.styles":"ready","ext.gadget.SectionFont":"ready","ext.globalCssJs.user.styles":"ready","site.styles":"ready","user.styles":"ready","skins.vector.user":"ready","ext.globalCssJs.user":"ready","user":"ready","user.options":"loading","ext.cite.styles":"ready","mediawiki.ui.button":"ready","skins.vector.styles":"ready","skins.vector.icons":"ready","mediawiki.ui.icon":"ready","jquery.makeCollapsible.styles":"ready","ext.visualEditor.desktopArticleTarget.noscript":"ready","ext.wikimediaBadges":"ready","ext.uls.interlanguage":"ready","wikibase.client.init":"ready"};RLPAGEMODULES=["ext.cite.ux-enhancements","site","mediawiki.page.ready","jquery.makeCollapsible","mediawiki.toc","skins.vector.js","skins.vector.es6","mmv.head","mmv.bootstrap.autostart","ext.visualEditor.desktopArticleTarget.init","ext.visualEditor.targetLoader",
"ext.eventLogging","ext.wikimediaEvents","ext.navigationTiming","ext.cx.eventlogging.campaigns","ext.centralNotice.geoIP","ext.centralNotice.startUp","ext.gadget.directcommons","ext.gadget.ReferenceTooltips","ext.gadget.edittools","ext.gadget.refToolbar","ext.gadget.siteNotice","ext.gadget.scrollUpButton","ext.gadget.strikethroughTOC","ext.gadget.switcher","ext.centralauth.centralautologin","ext.popups","ext.echo.centralauth","ext.uls.compactlinks","ext.uls.interface","ext.cx.uls.quick.actions","wikibase.client.vector-2022","ext.growthExperiments.SuggestedEditSession"];</script>
<script>(RLQ=window.RLQ||[]).push(function(){mw.loader.implement("user.options@12s5i",function($,jQuery,require,module){mw.user.tokens.set({"patrolToken":"+\\","watchToken":"+\\","csrfToken":"+\\"});});});</script>
<link href="/w/load.php?lang=ko&modules=ext.cite.styles%7Cext.uls.interlanguage%7Cext.visualEditor.desktopArticleTarget.noscript%7Cext.wikimediaBadges%7Cjquery.makeCollapsible.styles%7Cmediawiki.ui.button%2Cicon%7Cskins.vector.icons%2Cstyles%7Cwikibase.client.init&only=styles&skin=vector-2022" rel="stylesheet"/>
<script async="" src="/w/load.php?lang=ko&modules=startup&only=scripts&raw=1&skin=vector-2022"></script>
<meta content="" name="ResourceLoaderDynamicStyles"/>
<link href="/w/load.php?lang=ko&modules=ext.gadget.SectionFont&only=styles&skin=vector-2022" rel="stylesheet"/>
<link href="/w/load.php?lang=ko&modules=site.styles&only=styles&skin=vector-2022" rel="stylesheet"/>
<meta content="MediaWiki 1.41.0-wmf.2" name="generator"/>
<meta content="origin" name="referrer"/>
<meta content="origin-when-crossorigin" name="referrer"/>
<meta content="origin-when-cross-origin" name="referrer"/>
<meta content="max-image-preview:standard" name="robots"/>
<meta content="telephone=no" name="format-detection"/>
<meta content="width=1000" name="viewport"/>
<meta content="여명의 눈동자 - 위키백과, 우리 모두의 백과사전" property="og:title"/>
...
</div>
<script>(RLQ=window.RLQ||[]).push(function(){mw.config.set({"wgHostname":"mw2305","wgBackendResponseTime":120,"wgPageParseReport":{"limitreport":{"cputime":"0.428","walltime":"0.562","ppvisitednodes":{"value":6300,"limit":1000000},"postexpandincludesize":{"value":260787,"limit":2097152},"templateargumentsize":{"value":7671,"limit":2097152},"expansiondepth":{"value":15,"limit":100},"expensivefunctioncount":{"value":0,"limit":500},"unstrip-depth":{"value":0,"limit":20},"unstrip-size":{"value":19468,"limit":5000000},"entityaccesscount":{"value":1,"limit":400},"timingprofile":["100.00% 357.210 1 -total"," 28.84% 103.028 1 틀:각주"," 26.55% 94.845 1 틀:위키데이터_속성_추적"," 22.00% 78.579 11 틀:뉴스_인용"," 21.85% 78.049 15 틀:둘러보기_상자"," 20.49% 73.190 1 틀:텔레비전_방송_프로그램_정보"," 13.30% 47.502 348 틀:정보상자_칸"," 6.08% 21.704 1 틀:백상예술대상_TV부문_작품상"," 5.39% 19.267 1 틀:원작"," 5.16% 18.420 1 틀:문화방송_수목_미니시리즈"]},"scribunto":{"limitreport-timeusage":{"value":"0.105","limit":"10.000"},"limitreport-memusage":{"value":4833604,"limit":52428800}},"cachereport":{"origin":"mw2434","timestamp":"20230403041420","ttl":1814400,"transientcontent":false}}});});</script>
<script type="application/ld+json">{"@context":"https:\/\/schema.org","@type":"Article","name":"\uc5ec\uba85\uc758 \ub208\ub3d9\uc790","url":"https:\/\/ko.wikipedia.org\/wiki\/%EC%97%AC%EB%AA%85%EC%9D%98_%EB%88%88%EB%8F%99%EC%9E%90","sameAs":"http:\/\/www.wikidata.org\/entity\/Q624988","mainEntity":"http:\/\/www.wikidata.org\/entity\/Q624988","author":{"@type":"Organization","name":"\uc704\ud0a4\ubbf8\ub514\uc5b4 \ud504\ub85c\uc81d\ud2b8 \uae30\uc5ec\uc790"},"publisher":{"@type":"Organization","name":"Wikimedia Foundation, Inc.","logo":{"@type":"ImageObject","url":"https:\/\/www.wikimedia.org\/static\/images\/wmf-hor-googpub.png"}},"datePublished":"2006-02-04T13:29:19Z","dateModified":"2023-04-03T04:13:18Z","headline":"1991\ub144\uc791 \ubb38\ud654\ubc29\uc1a1\uc758 \ub4dc\ub77c\ub9c8"}</script><script type="application/ld+json">{"@context":"https:\/\/schema.org","@type":"Article","name":"\uc5ec\uba85\uc758 \ub208\ub3d9\uc790","url":"https:\/\/ko.wikipedia.org\/wiki\/%EC%97%AC%EB%AA%85%EC%9D%98_%EB%88%88%EB%8F%99%EC%9E%90","sameAs":"http:\/\/www.wikidata.org\/entity\/Q624988","mainEntity":"http:\/\/www.wikidata.org\/entity\/Q624988","author":{"@type":"Organization","name":"\uc704\ud0a4\ubbf8\ub514\uc5b4 \ud504\ub85c\uc81d\ud2b8 \uae30\uc5ec\uc790"},"publisher":{"@type":"Organization","name":"Wikimedia Foundation, Inc.","logo":{"@type":"ImageObject","url":"https:\/\/www.wikimedia.org\/static\/images\/wmf-hor-googpub.png"}},"datePublished":"2006-02-04T13:29:19Z","dateModified":"2023-04-03T04:13:18Z","headline":"1991\ub144\uc791 \ubb38\ud654\ubc29\uc1a1\uc758 \ub4dc\ub77c\ub9c8"}</script>
</body>
</html>n = 0
for each in soup.find_all('ul'):
print('=>'+str(n)+'=========================')
print(each.get_text())
n += 1⇊
Output exceeds the size limit. Open the full output data in a text editor
=>0=========================
대문최근 바뀜요즘 화제임의의 문서로기부
=>1=========================
사랑방사용자 모임관리 요청
=>2=========================
도움말정책과 지침질문방
=>3=========================
계정 만들기로그인
=>4=========================
계정 만들기 로그인
=>5=========================
기여토론
=>6=========================
처음 위치
1개요
...
- ul을 찾은 다음 구분기호를 집어넣음
soup.find_all('ul')[32].text.strip().replace('\xa0', '').replace('\n', '')⇊
'채시라: 윤여옥 역 (아역: 김민정)박상원: 장하림(하리모토 나츠오) 역 (아역: 김태진)최재성: 최대치(사카이) 역 (아역: 장덕수)'🖇️ 시카고 맛집 데이터 분석
from bs4 import BeautifulSoup
from urllib.request import Request, urlopen
url_base = 'https://www.chicagomag.com'
url_sub = '/chicago-magazine/november-2012/best-sandwiches-chicago/'
url = url_base + url_sub
#html = urlopen(url)
req = Request(url, headers = {'User-Agent':'Chrome'})
html = urlopen(req).read()
soup = BeautifulSoup(html, 'html.parser')
soup⇊
Output exceeds the size limit. Open the full output data in a text editor
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="utf-8"/>
<meta content="IE=edge" http-equiv="X-UA-Compatible">
<link href="https://gmpg.org/xfn/11" rel="profile"/>
<script src="https://cmp.osano.com/16A1AnRt2Fn8i1unj/f15ebf08-7008-40fe-9af3-db96dc3e8266/osano.js"></script>
<title>The 50 Best Sandwiches in Chicago – Chicago Magazine</title>
<style type="text/css">
.heateor_sss_button_instagram span.heateor_sss_svg,a.heateor_sss_instagram span.heateor_sss_svg{background:radial-gradient(circle at 30% 107%,#fdf497 0,#fdf497 5%,#fd5949 45%,#d6249f 60%,#285aeb 90%)}
div.heateor_sss_horizontal_sharing a.heateor_sss_button_instagram span{background:#000!important;}div.heateor_sss_standard_follow_icons_container a.heateor_sss_button_instagram span{background:#000;}
.heateor_sss_horizontal_sharing .heateor_sss_svg,.heateor_sss_standard_follow_icons_container .heateor_sss_svg{
background-color: #000!important;
background: #000!important;
color: #fff;
border-width: 0px;
border-style: solid;
border-color: transparent;
}
.heateor_sss_horizontal_sharing .heateorSssTCBackground{
color:#666;
}
.heateor_sss_horizontal_sharing span.heateor_sss_svg:hover,.heateor_sss_standard_follow_icons_container span.heateor_sss_svg:hover{
border-color: transparent;
...
}
}
</script>
</body>
</html>print(soup.find_all('div', 'sammy'))⇊
Output exceeds the size limit. Open the full output data in a text editor
[<div class="sammy" style="position: relative;">
<div class="sammyRank">1</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/"><b>BLT</b><br/>
Old Oak Tap<br/>
<em>Read more</em> </a></div>
</div>, <div class="sammy" style="position: relative;">
<div class="sammyRank">2</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Au-Cheval-Fried-Bologna/"><b>Fried Bologna</b><br/>
Au Cheval<br/>
<em>Read more</em> </a></div>
</div>, <div class="sammy" style="position: relative;">
<div class="sammyRank">3</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Xoco-Woodland-Mushroom/"><b>Woodland Mushroom</b><br/>
Xoco<br/>
<em>Read more</em> </a></div>
</div>, <div class="sammy" style="position: relative;">
<div class="sammyRank">4</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Als-Deli-Roast-Beef/"><b>Roast Beef</b><br/>
Al’s Deli<br/>
<em>Read more</em> </a></div>
</div>, <div class="sammy" style="position: relative;">
<div class="sammyRank">5</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Publican-Quality-Meats-PB-L/"><b>PB&L</b><br/>
Publican Quality Meats<br/>
<em>Read more</em> </a></div>
...
<div class="sammyListing"><a href="https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Phoebes-Bakery-The-Gatsby/"><b>The Gatsby</b><br/>
Phoebe’s Bakery<br/>
<em>Read more</em> </a></div>
</div>]tmp_one = soup.find_all('div', 'sammy')[0]
type(tmp_one)⇊
bs4.element.Tag- type이 bs4.element.Tag라는것은 find 명령을 사용할 수 있다는 뜻
tmp_one.find(class_='sammyListing').get_text()⇊
'BLT\nOld Oak Tap\nRead more '- 메뉴, 가게이름 데이터 한꺼번에 존재
tmp_one.find('a')['href']⇊
'/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'- 연결되는 홈페이지 주소가 '상대경로'
import re
tmp_string = tmp_one.find(class_='sammyListing').get_text()
re.split(('\n|\r\n'), tmp_string)⇊
['BLT', 'Old Oak Tap', 'Read more ']- 가게 이름과 메뉴는 re모듈의 split으로 쉽게 구분 가능
print(re.split(('\n|\r\n'), tmp_string)[0])
print(re.split(('\n|\r\n'), tmp_string)[1])⇊
BLT
Old Oak Tapㄴ 위 내용들을 전체 반복문으로 호출
from urllib.parse import urljoin
url_base = 'https://www.chicagomag.com'
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all('div', 'sammy')
for item in list_soup:
rank.append(item.find(class_='sammyRank').get_text())
tmp_string = item.find(class_='sammyListing').get_text()
main_menu.append(re.split(('\n|\r\n'), tmp_string)[0])
cafe_name.append(re.split(('\n|\r\n'), tmp_string)[1])
url_add.append(urljoin(url_base, item.find('a')['href'])) #urljoin=가져온 두번째 주소가 만약 절대주소라면 url_base 붙이지 않음. 상대주소일 경우만 붙임- urljoin : 가져온 두번째주소가 절대주소라면 url_base를 붙이지 않음.상대주소일 경우에만 붙임
rank[:5]⇊
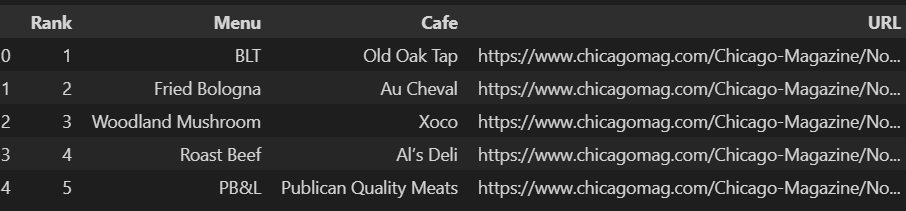
['1', '2', '3', '4', '5']
main_menu[:5]⇊
['BLT', 'Fried Bologna', 'Woodland Mushroom', 'Roast Beef', 'PB&L']cafe_name[:5]⇊
['Old Oak Tap', 'Au Cheval', 'Xoco', 'Al’s Deli', 'Publican Quality Meats']url_add[:5]⇊
['https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/',
'https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Au-Cheval-Fried-Bologna/',
'https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Xoco-Woodland-Mushroom/',
'https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Als-Deli-Roast-Beef/',
'https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Publican-Quality-Meats-PB-L/']ㄴ 데이터 프레임으로 정리
import pandas as pd
data = {'Rank': rank, 'Menu':main_menu, 'Cafe':cafe_name, 'URL':url_add}
df = pd.DataFrame(data)
df.head()⇊
🖇️ 시카고 맛집 데이터 하위 페이지 분석
req = Request(df['URL'][0], headers={"User-Agent":"Chrome"})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, 'html.parser')
print(soup_tmp.find('p', 'addy'))⇊
<p class="addy">
<em>$10. 2109 W. Chicago Ave., 773-772-0406, <a href="http://www.theoldoaktap.com/">theoldoaktap.com</a></em></p>ㄴ 정규식으로 정리
─ 정규식(Regular Expression)
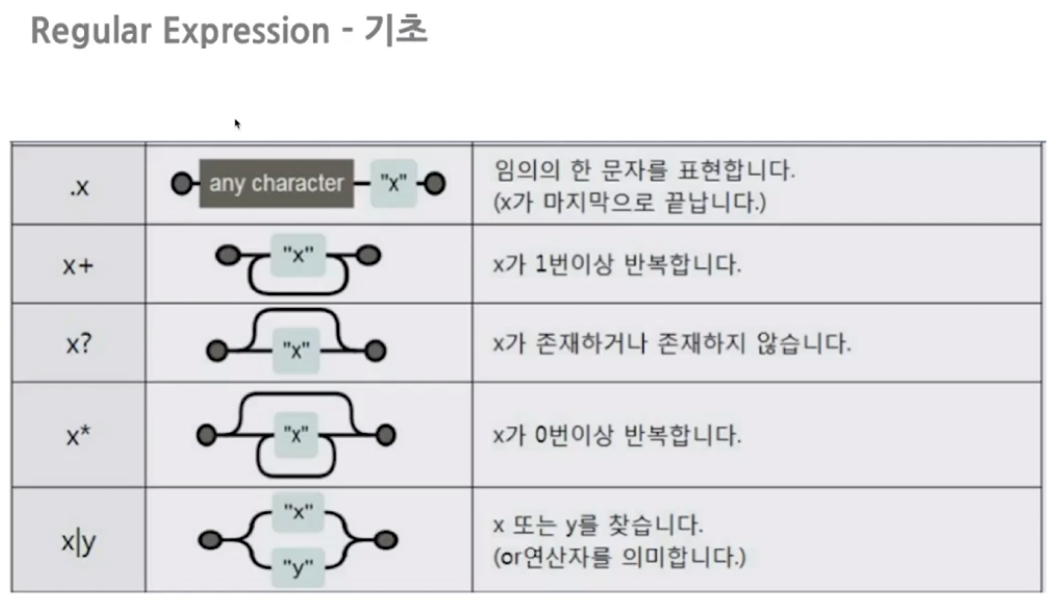
- 문장내에서의 패턴을 손쉽게 찾을 수 있음
price_tmp = soup_tmp.find('p', 'addy').get_text()
price_tmp⇊
'\n$10. 2109 W. Chicago Ave., 773-772-0406, theoldoaktap.com'- text로 먼저 변환
import re
re.split('.,', price_tmp)price_tmp = re.split('.,', price_tmp)[0]
price_tmp⇊
'\n$10. 2109 W. Chicago Ave'
- 가격과 주소만 가져오기 위해 .,로 분리
re.search('\$\d+\.(\d+)?', price_tmp).group()⇊
'$10.'
- '\$\d+.(\d+)?' : 달러 기호가 오고, 숫자 여러개가 오고, .이 와야하고, .뒤에는 숫자 여러개가 있을 수도 있고, 없을 수도 있음.
tmp = re.search('\$\d+\.(\d+)?', price_tmp).group()
price_tmp[len(tmp) + 2:]⇊
'2109 W. Chicago Ave'- 가격이 끝나는 지점의 위치를 이용. 그 뒤는 주소로 생각
price = []
address = []
for n in df.index[:3]:
# html = urlopen(df['URL'][n])
req = Request(df['URL'][n], headers={'User-Agent':'Mozilla/5.0'})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, 'lxml')
gettings = soup_tmp.find('p', 'addy').get_text()
price_tmp = re.split('.,', gettings)[0]
tmp = re.search('\$\d+\.(\d+)?', price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp) + 2 :])
print(n)for item in df[:3]['URL']:
print(item)ㄴ 리스트형 데이터 반복시킬떄는 위와같은 방법이 정석이지만, 여러 컬럼을 for문 내에서 사용할때는 어려움
from tqdm import tqdm
price = []
address = []
for idx, row in tqdm(df.iterrows()):
# html = urlopen(df['URL'][n])
req = Request(row['URL'][n], headers={'User-Agent':'Mozilla/5.0'})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, 'lxml')
gettings = soup_tmp.find('p', 'addy').get_text()
price_tmp = re.split('.,', gettings)[0]
tmp = re.search('\$\d+\.(\d+)?', price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp) + 2 :])
print(n)- tqdm: 프로그세스 바 생성
⇊
50it [01:09, 1.40s/it]🖇️ 시카고 맛집 데이터 지도 시각화
import folium
import pandas as pd
import googlemaps
import numpy as np
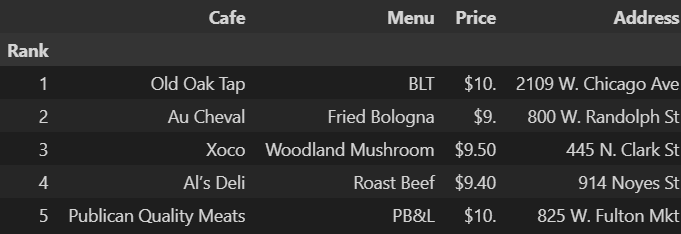
from tqdm import tqdmdf =pd.read_csv('../data/03.best_sandwiches_list_chicago2.csv', index_col=0)
df.head(5)⇊
gmaps_key = 'AI....'
gmaps = googlemaps.Client(key=gmaps_key)lat = []
lng = []
for idx, row in tqdm(df.iterrows()):
if not row['Address'] == 'Multiple location':
target_name = row['Address'] + ',' + 'Chicago'
gmaps_output = gmaps.geocode(target_name)
location_output = gmaps_output[0].get('geometry')
lat.append(location_output['location']['lat'])
lng.append(location_output['location']['lng'])
else:
lat.append(np.nan)
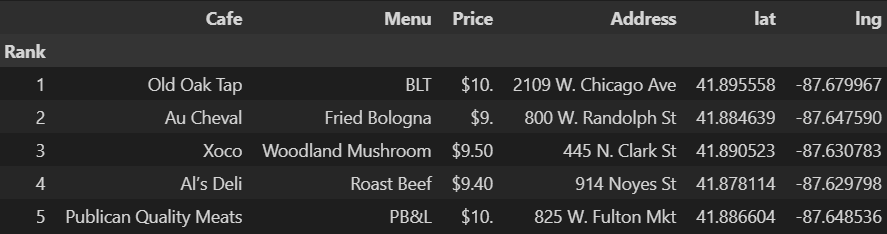
lng.append(np.nan)df['lat'] = lat
df['lng'] = lng
df.head()⇊
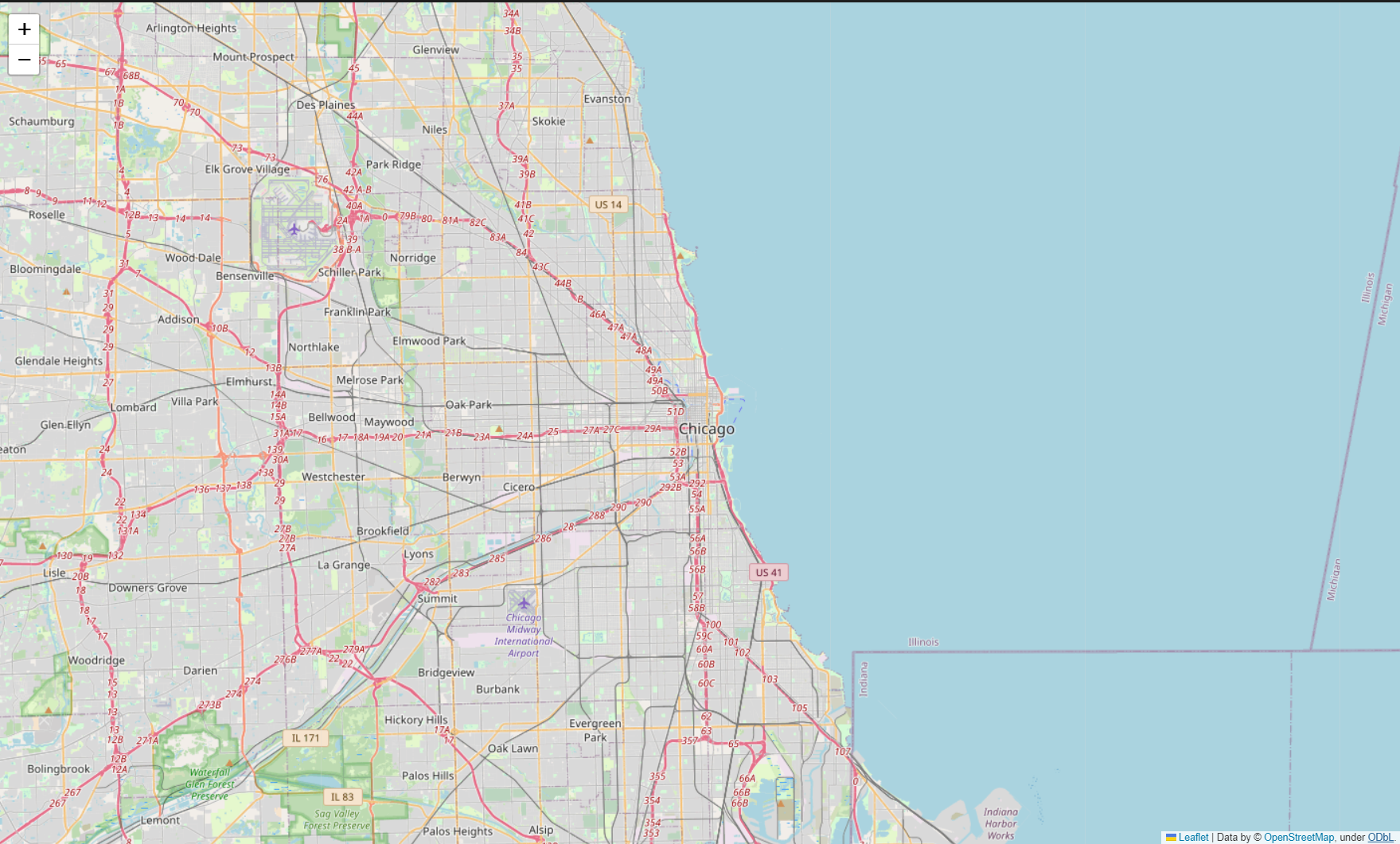
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
mapping⇊
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
for idx, row in df.iterrows():
if not row['Address'] == 'Multiple location':
folium.Marker([row['lat'], row['lng']], popup=row['Cafe']).add_to(mapping)
mapping⇊
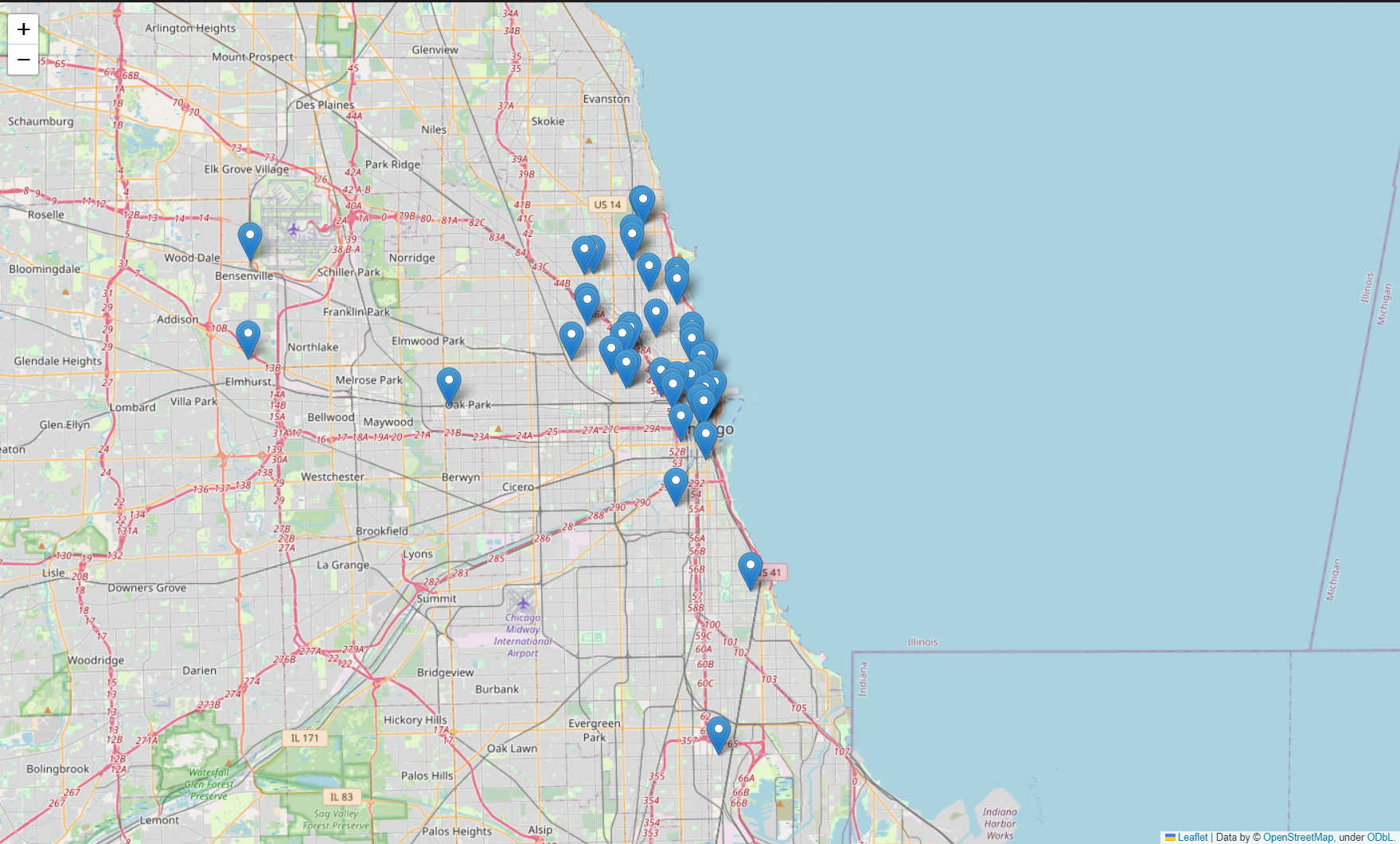
- 마커 추가
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
for idx, row in df.iterrows():
if not row['Address'] == 'Multiple location':
folium.Marker([row['lat'], row['lng']], popup=row['Cafe'],
tooltip=row['Menu'], icon= folium.Icon(icon='coffee', prefix='fa'),
).add_to(mapping)
mapping⇊
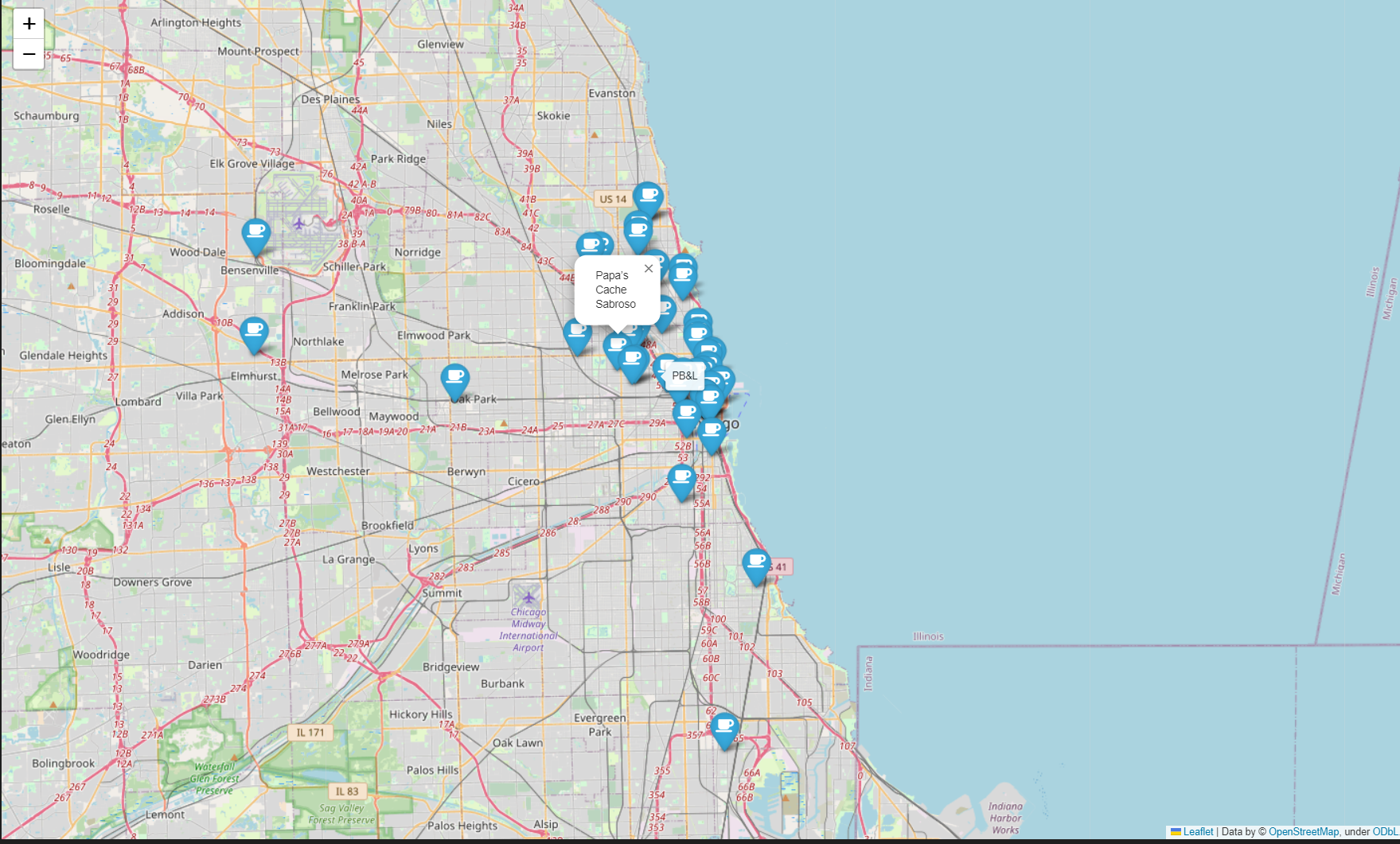
- 아이콘 꾸미기
