🖇️ seaborn
import matplotlib.pyplot as plt
import seaborn as sns
# %matplotlib inline
get_ipython().run_line_magic('matplotlib', 'inline')- seaborn은 matplotlib과 함께 실행
x = np.linspace(0, 14, 100)
y1 = np.sin(x)
y2 = 2 * np.sin(x + 0.5)
y3 = 3 * np.sin(x + 1.0)
y4 = 4 * np.sin(x + 1.5)plt.figure(figsize=(10, 6))
plt.plot(x, y1, x, y2, x, y3, x, y4)
plt.show()⇊
- seaborn은 import하는 것만으로도 뭔가 효가를 줌
sns.set_style('white') #그리드가 없어지고 배경 흰색으로
plt.figure(figsize=(10, 6))
plt.plot(x, y1, x, y2, x, y3, x, y4)
sns.despine() #라인이 왼쪽과 아랫쪽만 남음
plt.show()⇊
- sns.set_style() : 'white', 'whitegrid', 'dark', 'darkgrid'
plt.figure(figsize=(10, 6))
plt.plot(x, y1, x, y2, x, y3, x, y4)
sns.despine(offset=10)
plt.show()⇊
-왼쪽 하단 선 간격을 띄움
tips = sns.load_dataset('tips')
tips.head(5)⇊
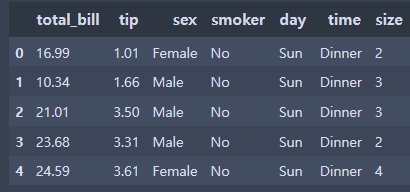
- seaborn내에 실습용 데이터 내장
plt.figure(figsize=(8, 6))
sns.boxplot(x=tips['total_bill'])
plt.show()⇊
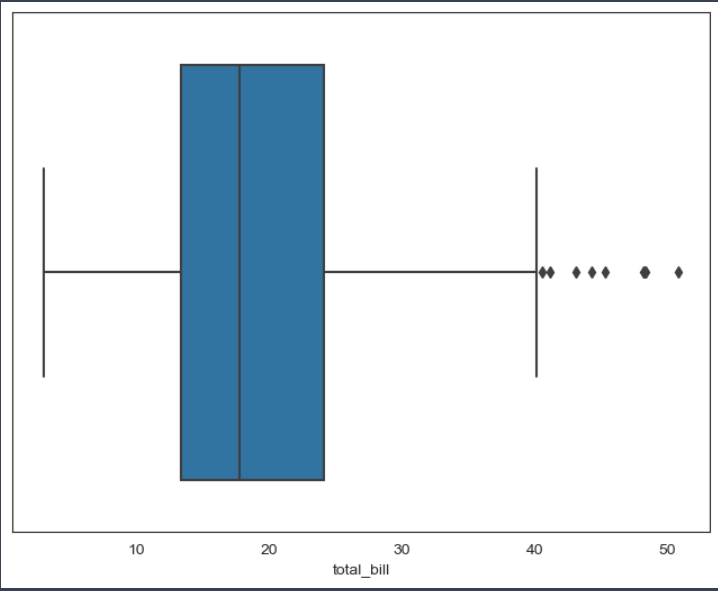
- boxplot()
plt.figure(figsize=(8, 6))
sns.boxplot(x='day', y='total_bill', data=tips)
plt.show()⇊
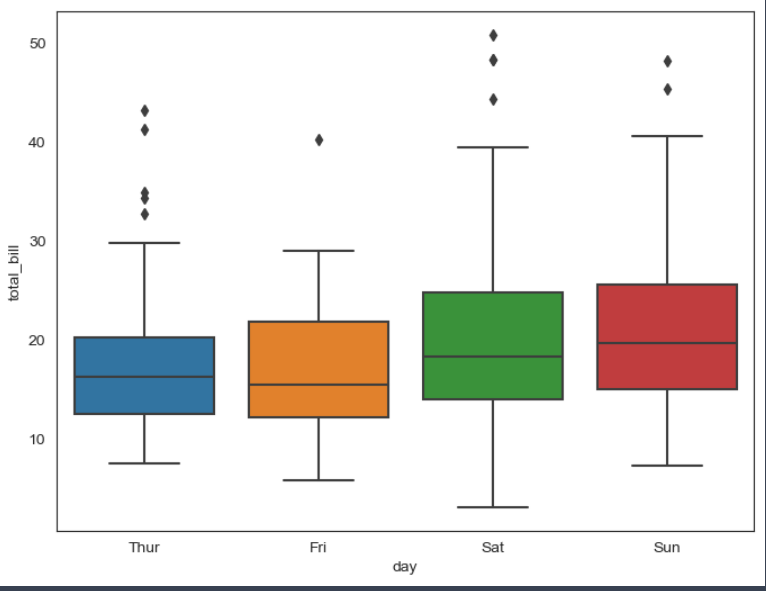
-boxplot에 컬럼 지정
plt.figure(figsize=(8, 6))
sns.boxplot(x='day', y='total_bill', hue='smoker', data=tips, palette='Set3')
plt.show()⇊
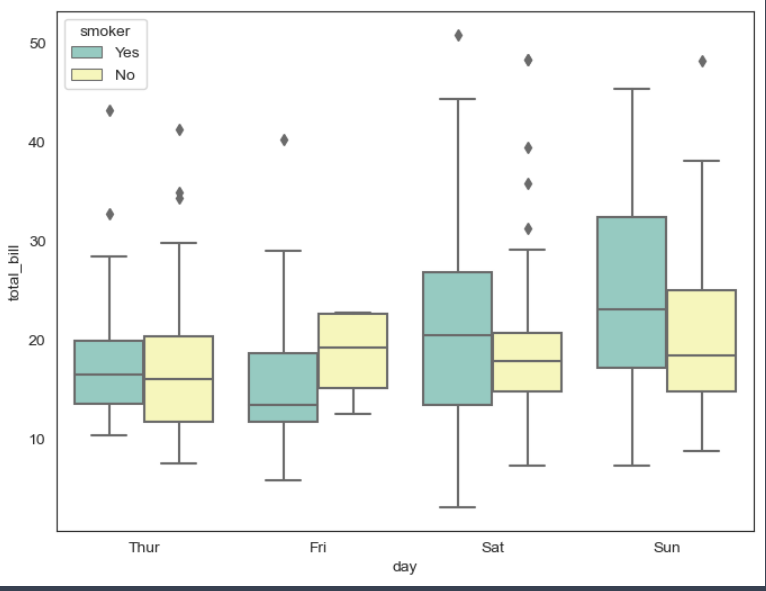
- 컬럼을 지정하고 구분짓기(hue) 가능
- hue: 카테고리 데이터 표시
plt.figure(figsize=(8, 6))
sns.swarmplot(x='day', y='total_bill', data=tips, color='.5')
plt.show()⇊
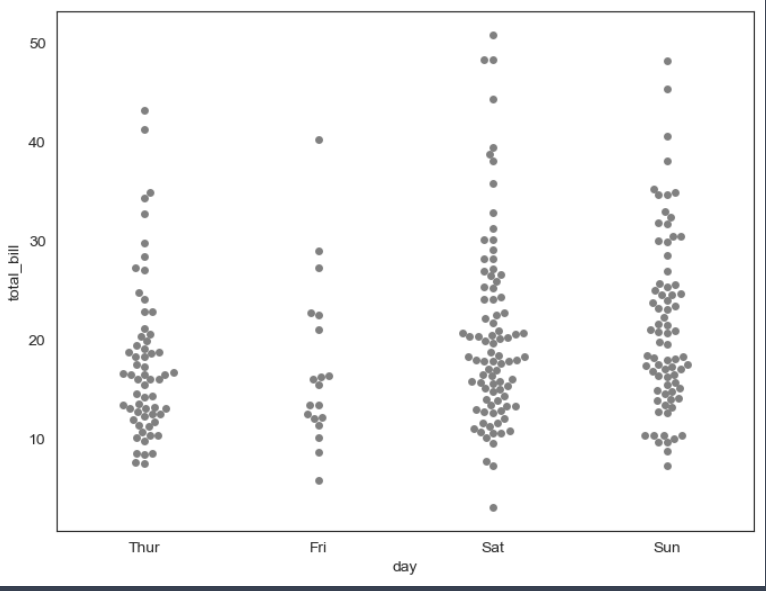
- swarmplot() : 데이터의 분포를 보여줌
- color 값은 0~1 사이 (검은색~흰색)
plt.figure(figsize=(8, 6))
sns.boxplot(x='day', y='total_bill', data=tips)
sns.swarmplot(x='day', y='total_bill', data=tips, color='.25')
plt.show()⇊
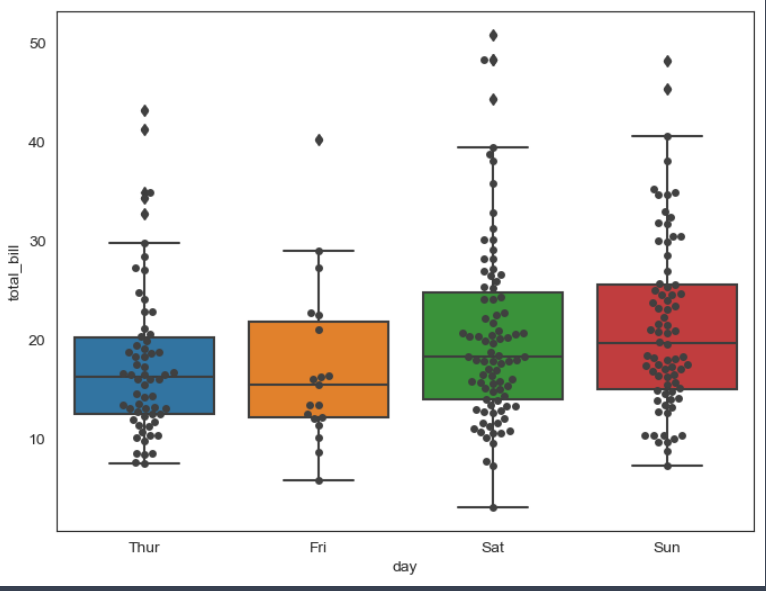
- boxplot() + swarmplot()
sns.set_style('darkgrid')
sns.lmplot(x='total_bill', y='tip', data=tips, height=7)
plt.show()⇊
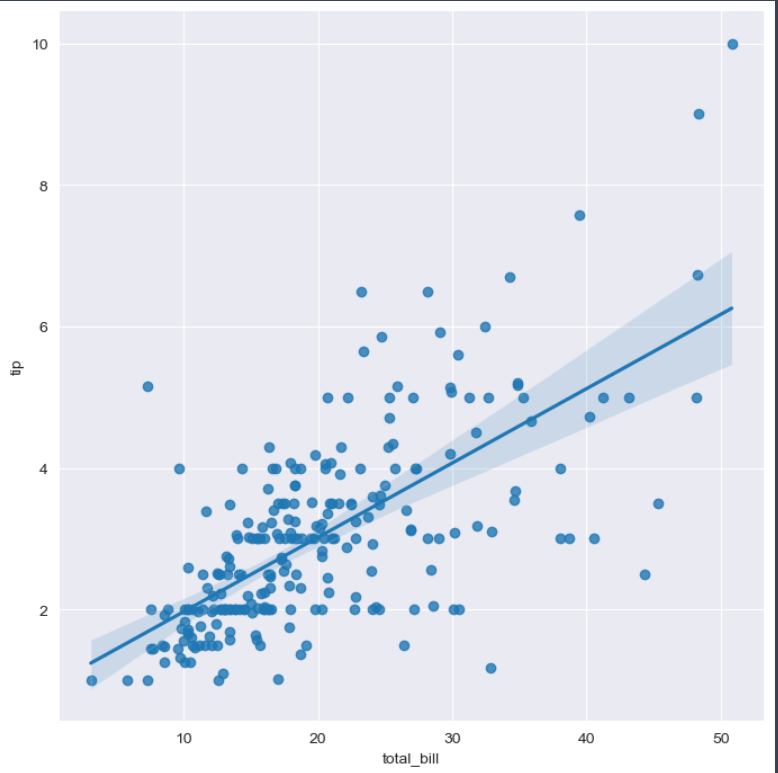
- total bill과 tip사이의 관계 파악
sns.lmplot(x='total_bill', y='tip', hue='smoker', data=tips, height=7)
plt.show()⇊
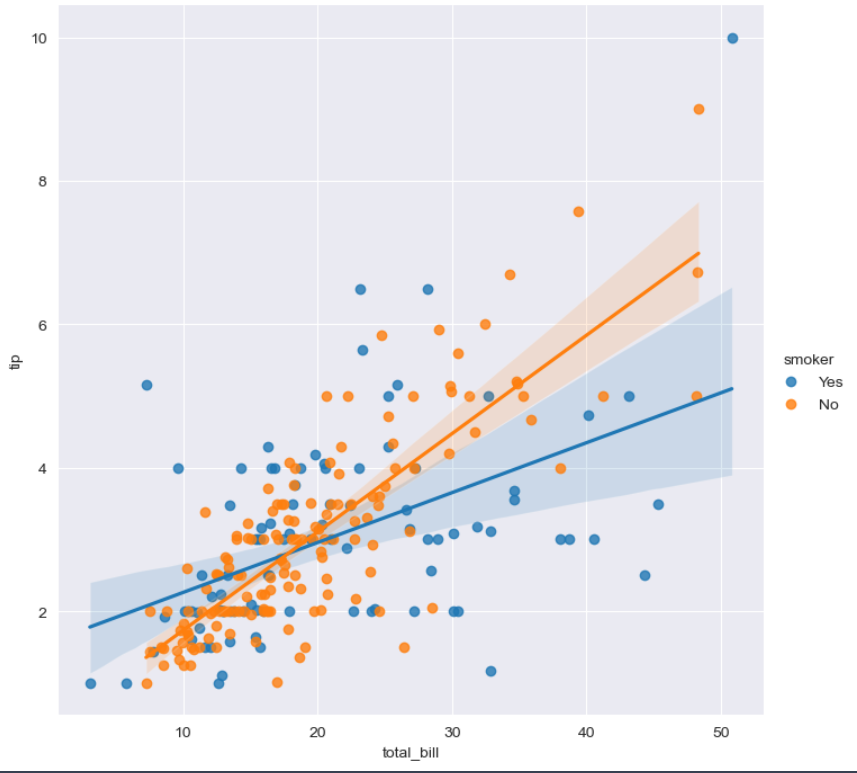
- smoker를 기준으로 나눔.
flights = sns.load_dataset('flights')
flights.head(5)⇊
- 또다른 실습용 데이터 flights (어떤 항공사의 년도,월, 승객수)
flights = flights.pivot('month', 'year', 'passengers')
flights.head(5)⇊
- pivot()=(index, columns, values)
plt.figure(figsize=(10, 8))
sns.heatmap(flights, annot=True, fmt='d')
plt.show()⇊
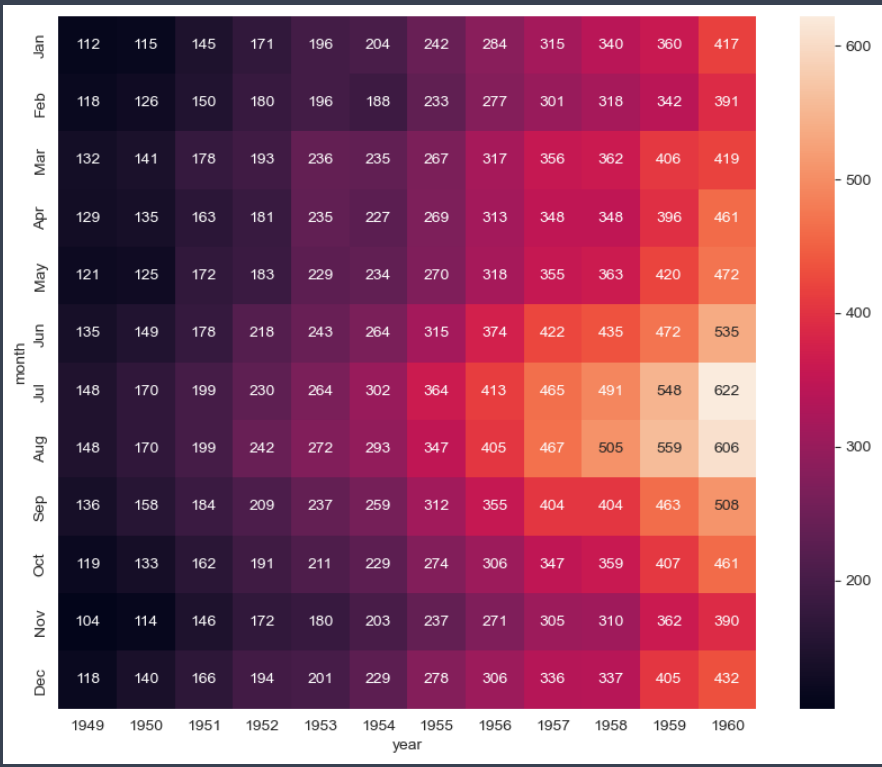
- heatmap을 이용하면 전체 경향 알 수 있음
- annot: 각 칸들안에 숫자를 넣을지 말지 결정
- fmt: d=정수형, f=실수형
plt.figure(figsize=(10, 8))
sns.heatmap(flights, annot=True, fmt='d', cmap='YlGnBu')
plt.show()⇊
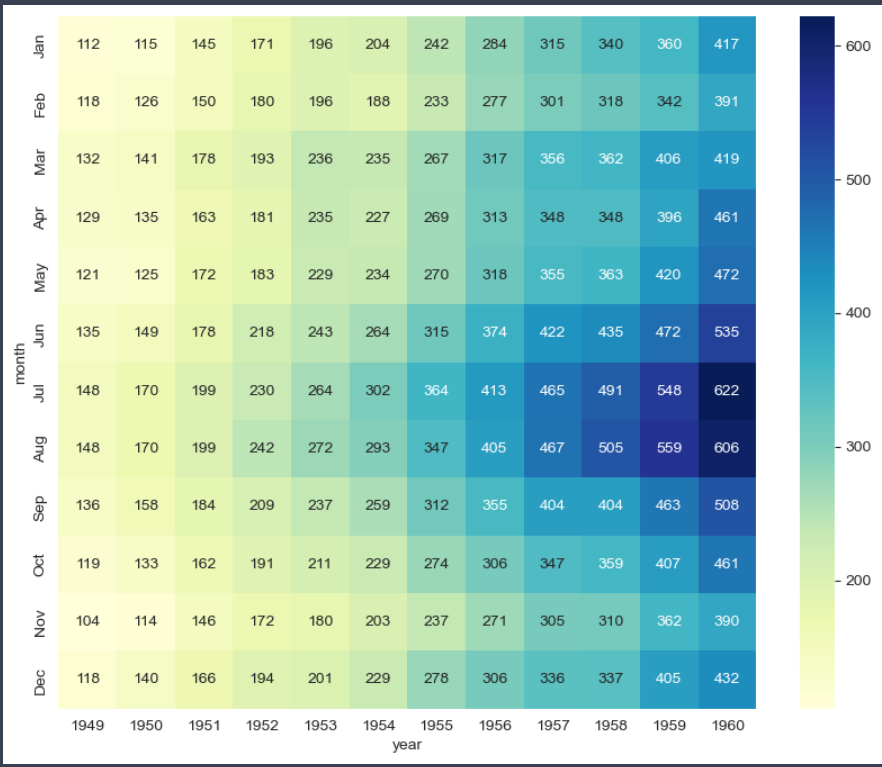
- 색깔 다르게
sns.set(style='ticks')
iris = sns.load_dataset('iris')
iris.head(10)⇊
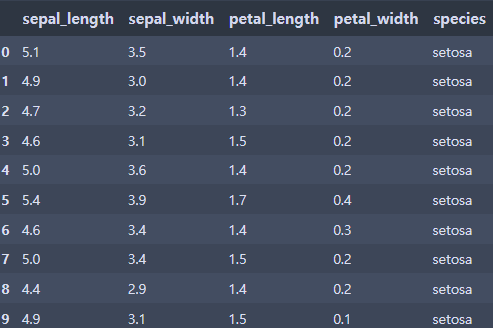
- iris 데이터(붓꽃의 3가지 품종을 꽃잎과 꽃받침의 가로세로 길이로 분류하려는 데이터)
sns.pairplot(iris)
plt.show()⇊
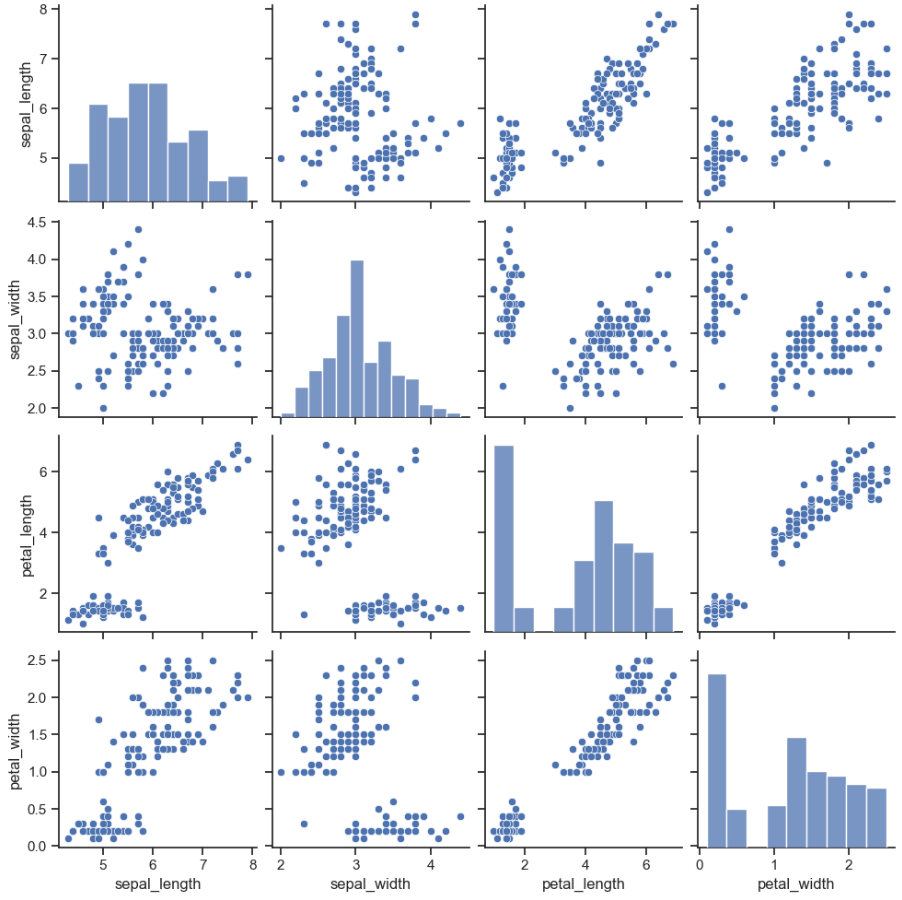
- pairplot() : 다수의 컬럼 비교하는 모든 경우의 수 표시
sns.pairplot(iris, hue='species')
plt.show()⇊
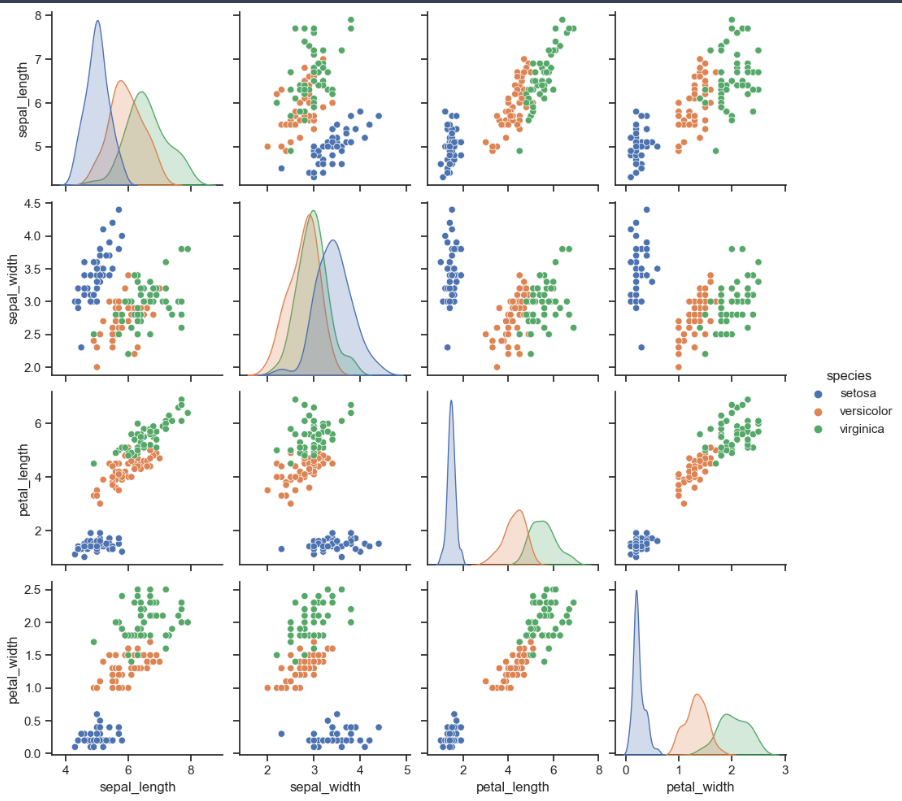
- 품종에 따라 색상다르게
sns.pairplot(iris, x_vars=['sepal_width', 'sepal_length'], y_vars=['petal_width', 'petal_length'])
plt.show()⇊
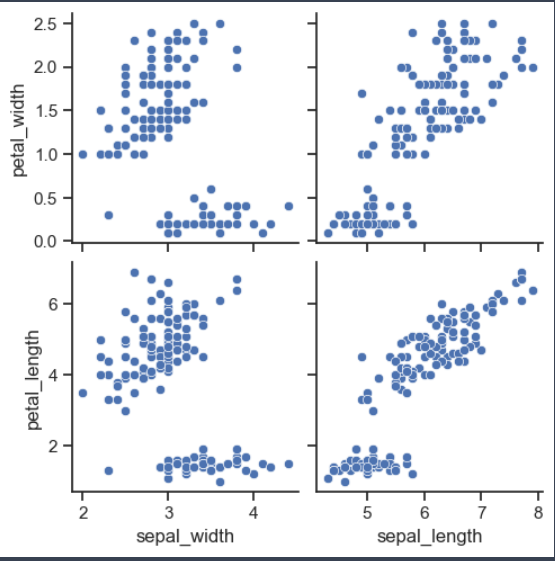
- 원하는 컬럼만 pairplot
anscombe = sns.load_dataset('anscombe')
anscombe.head(5)⇊
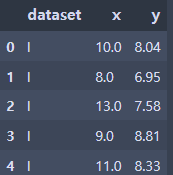
sns.set_style('darkgrid')
sns.lmplot(x='x', y='y', data=anscombe.query("dataset == 'I'"), ci=None, height=7)
plt.show()⇊
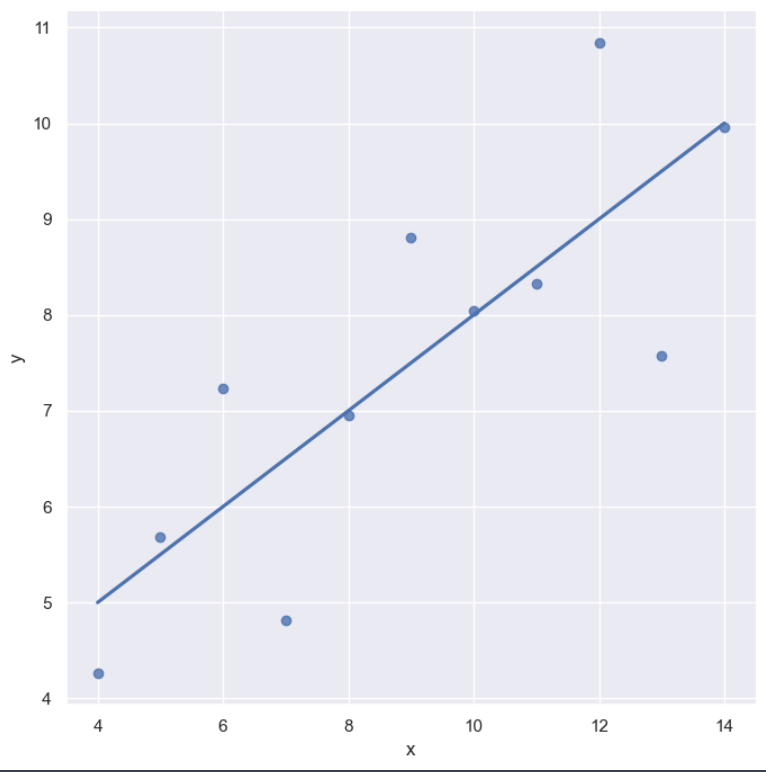
- ci: 신뢰구간 선택
sns.set_style('darkgrid')
sns.lmplot(x='x', y='y', data=anscombe.query("dataset == 'I'"), ci=None, height=7, scatter_kws={'s':50})
plt.show()⇊
- scatter_kws{'s':숫자} : 점의 크기 변경
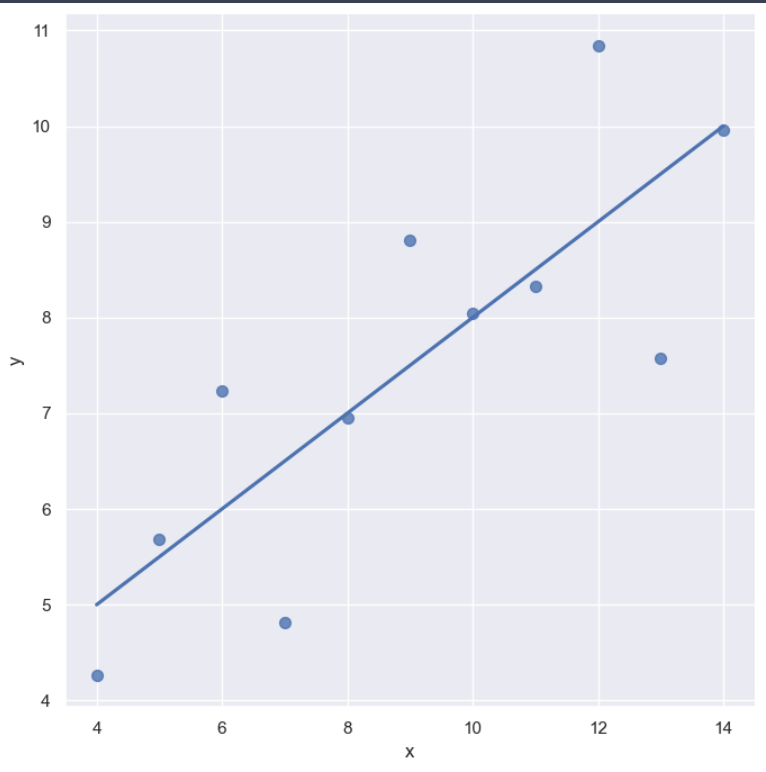
sns.set_style('darkgrid')
sns.lmplot(x='x', y='y', data=anscombe.query("dataset == 'II'"),
order=1, ci=None, height=7, scatter_kws={'s':50})
plt.show()⇊
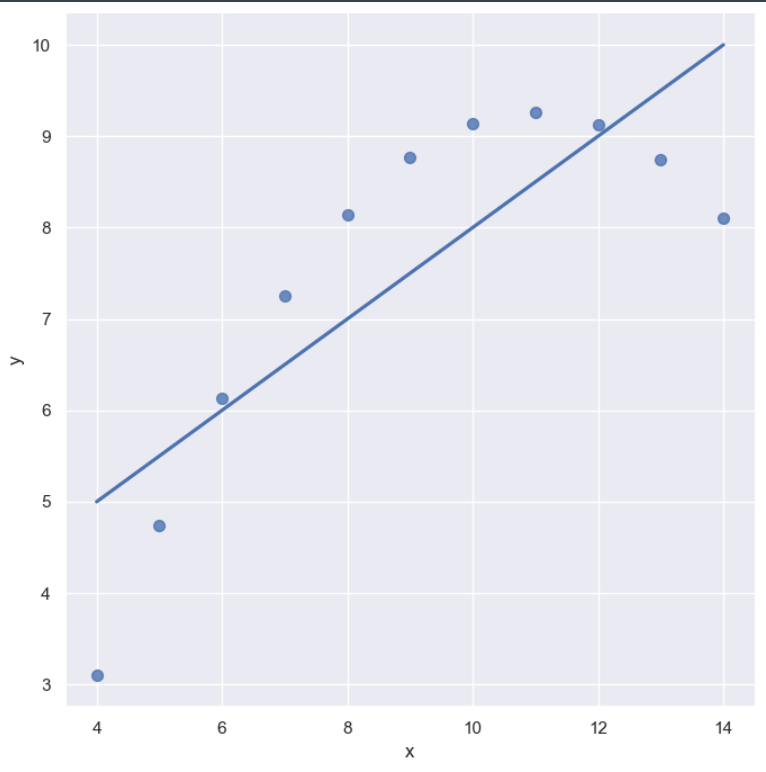
sns.set_style('darkgrid')
sns.lmplot(x='x', y='y', data=anscombe.query("dataset == 'II'"),
order=1, ci=None, height=7, scatter_kws={'s':50})
plt.show()⇊
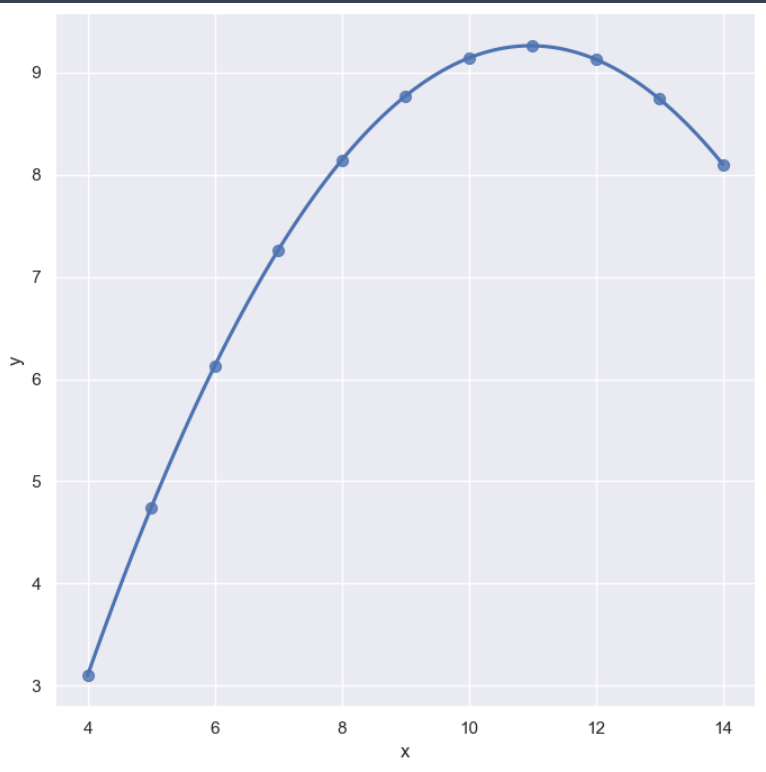
sns.set_style('darkgrid')
sns.lmplot(x='x', y='y', data=anscombe.query("dataset == 'III'"),
ci=None, height=7, scatter_kws={'s':50})
plt.show()⇊
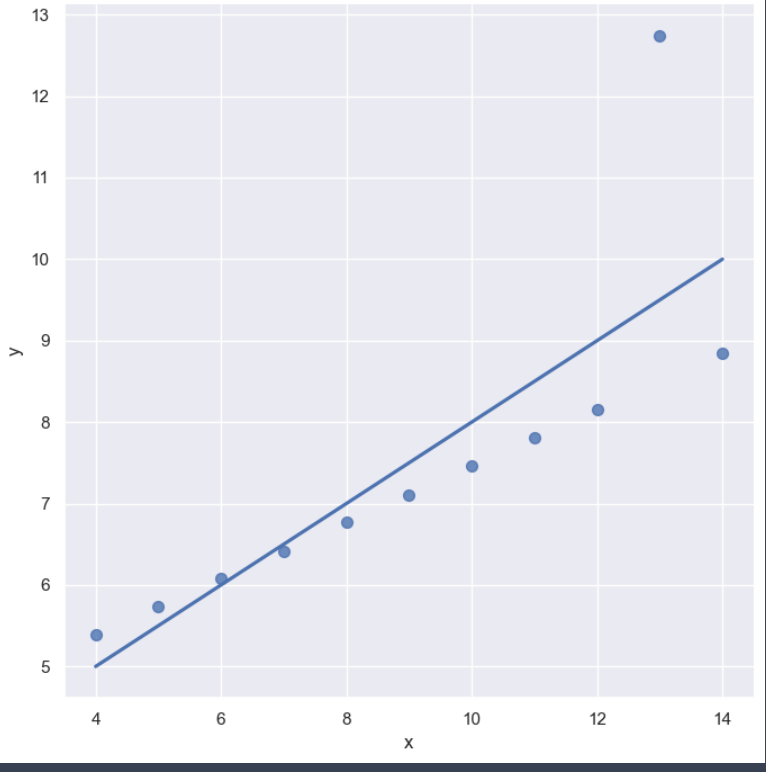
- outlier : 하나 동떨어져있는 데이터를 설정
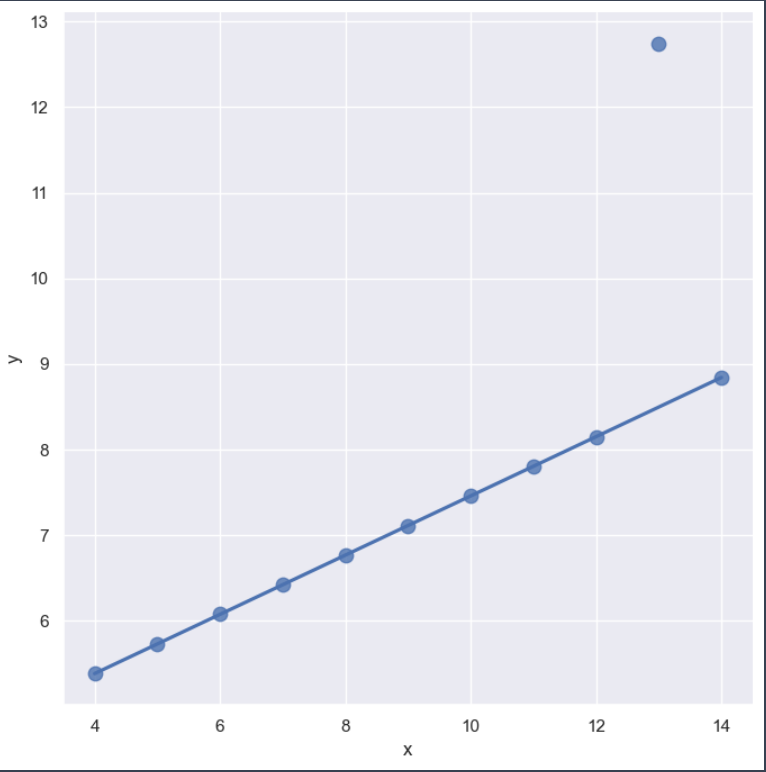
sns.set_style('darkgrid')
sns.lmplot(x='x', y='y', data=anscombe.query("dataset == 'III'"),
robust=True, ci=None, height=7, scatter_kws={'s':80})
plt.show()⇊
🖇️ 서울시 범죄현황 데이터 시각화
import matplotlib.pyplot as plt
import seaborn as sns
#%matplotlib inline
get_ipython().run_line_magic('matplotlib', 'inline')
from matplotlib import rc
##한글 폰트 잡기
plt.rcParams['axes.unicode_minus'] = False
rc('font', family='Malgun Gothic')crime_anal_norm.head()sns.pairplot(crime_anal_norm, vars=['강도', '살인', '폭력'], kind='reg', height=3);⇊
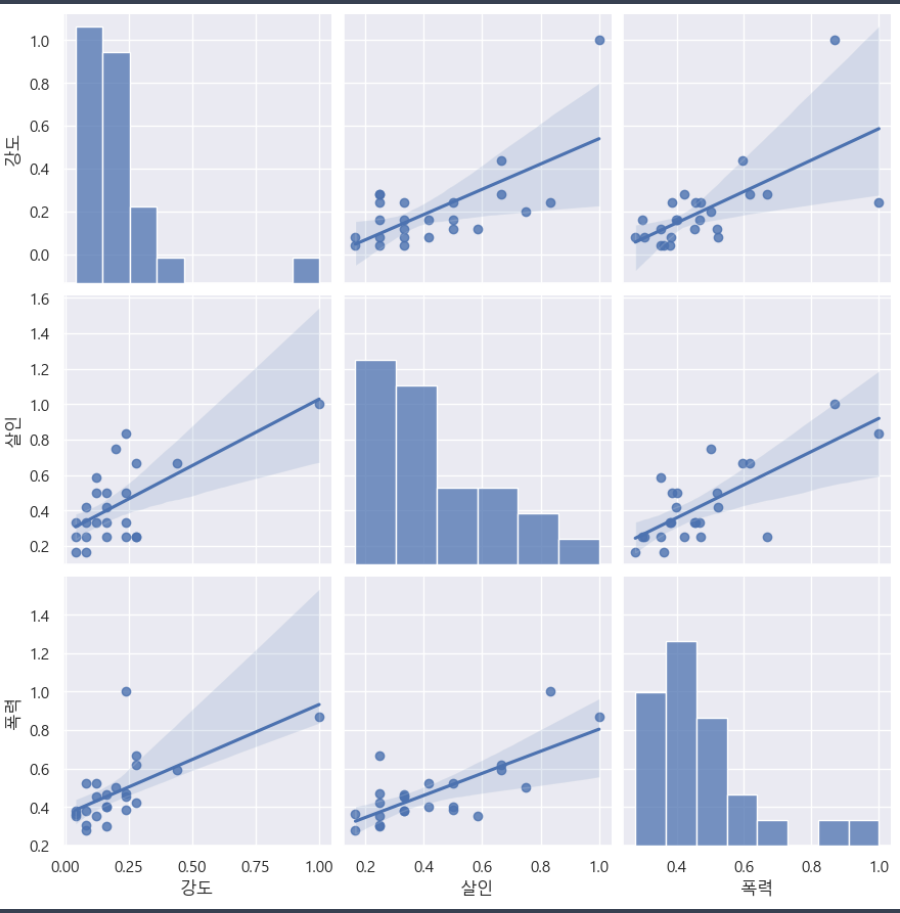
- pairplot으로 강도,살인,폭력에 대한 상관관계 그래프
def drawPlot():
sns.pairplot(
crime_anal_norm, x_vars=['인구수', 'CCTV'], y_vars=['살인', '강도'], kind='reg', height=4
)
plt.show()drawPlot()⇊
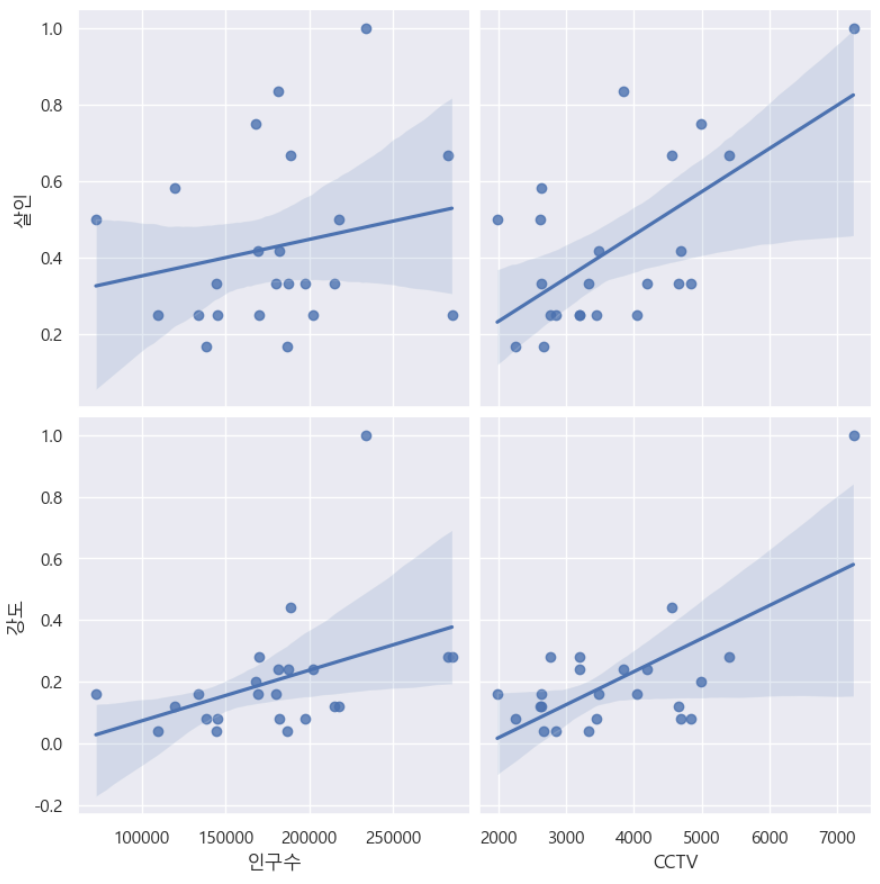
- 인구수,CCTV와 살인,강도의 상관관계
CCTV가 많을 수록 강도/살인사건이 늘어났다는게 아닌, 강도/살인 사건이 많이 발생하기때문에 CCTV를 늘렸다고 볼 수 있음
def drawPlot():
sns.pairplot(
crime_anal_norm,
x_vars=['인구수', 'CCTV'],
y_vars=['살인검거율', '폭력검거율'],
kind='reg',
height=4
)
plt.show()drawPlot()⇊
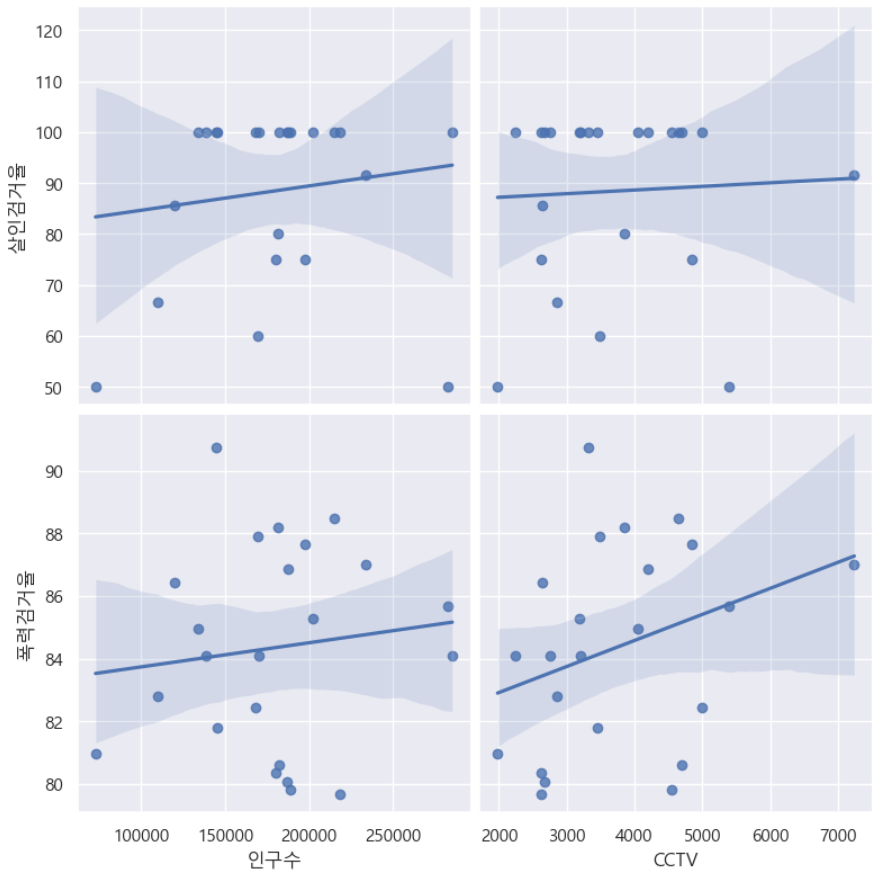
- 인구수,CCTV와 살인,폭력 검거율의 상관관계
def drawPlot():
sns.pairplot(
crime_anal_norm,
x_vars=['인구수', 'CCTV'],
y_vars=['절도검거율', '강도검거율'],
kind='reg',
height=4
)
plt.show()drawPlot()⇊
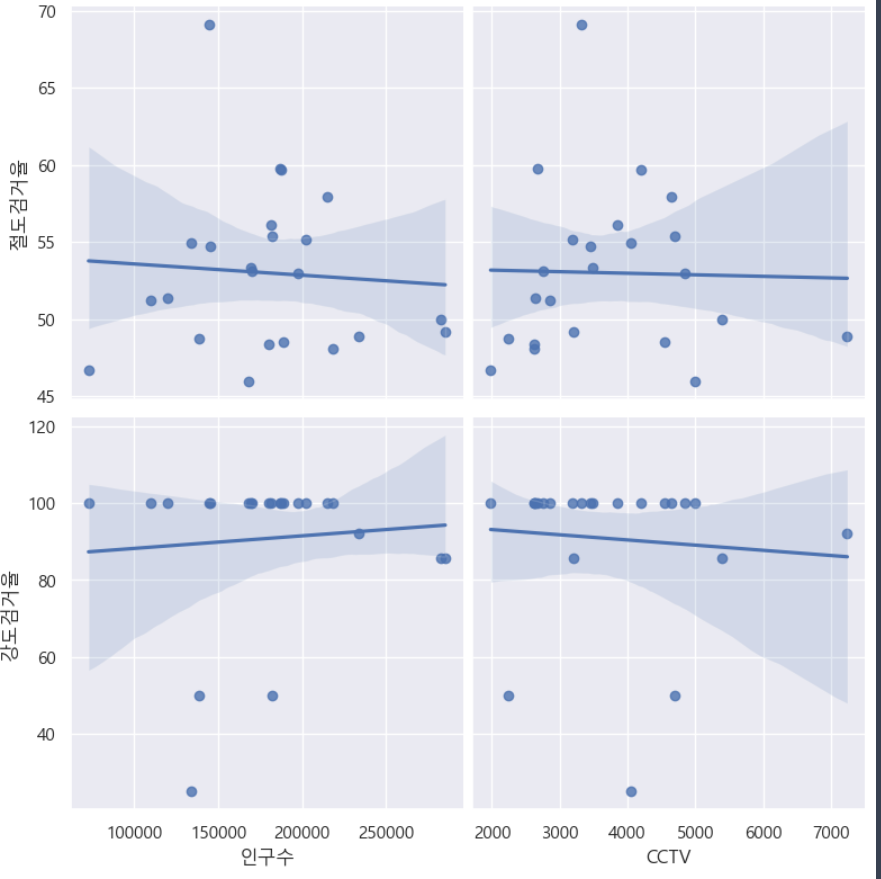
- 인구수,CCTV와 절도,강도 검거율의 상관관계
def drawGraph():
target_col = ['강간,추행검거율', '강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율', '검거']
crime_anal_norm_sort = crime_anal_norm.sort_values(by='검거', ascending=False)
plt.figure(figsize=(10, 10))
sns.heatmap(
crime_anal_norm_sort[target_col],
annot=True,
fmt='f',
linewidths=0.5, #간격설정
cmap='RdPu'
)
plt.title('범죄 검거 비율(정규화된 검거의 합으로 정렬)')
plt.show()drawGraph()⇊
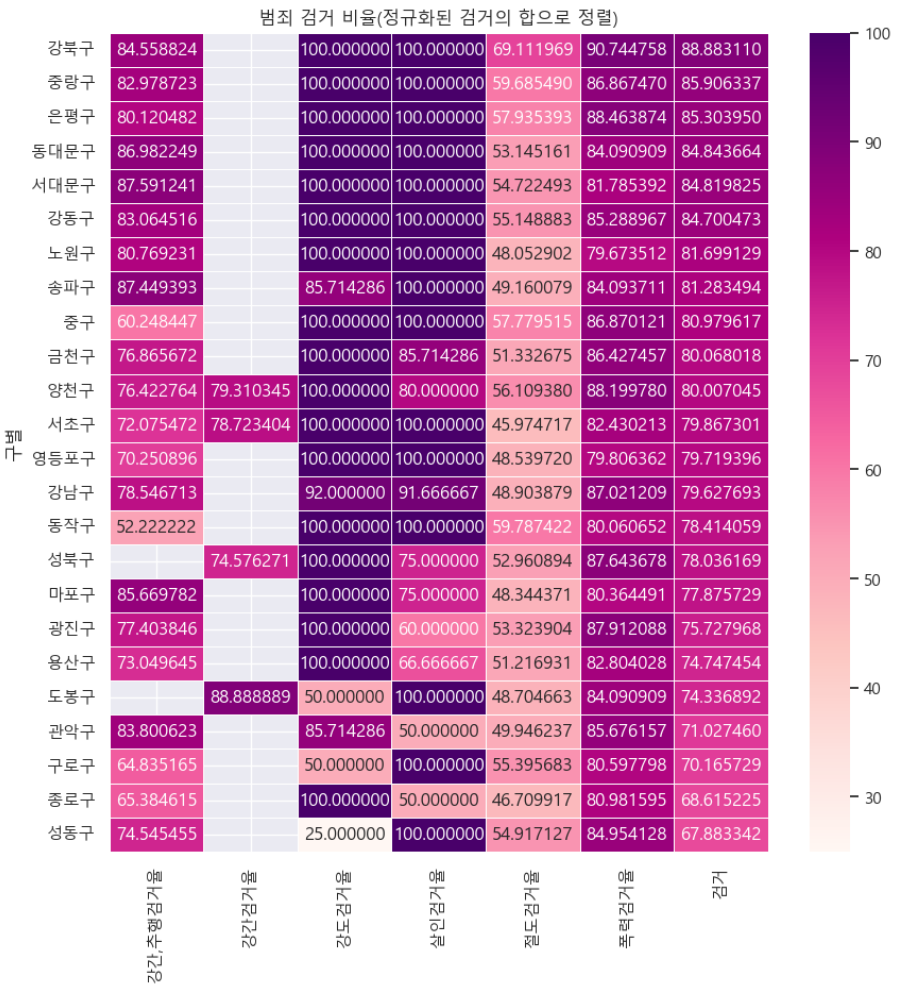
- 검거율만 가지고 heatmap 생성
- 단, 전체 검거율의 대표값인 검거를 기준으로 정렬
def drawGraph():
target_col = ['강간,추행', '강간', '강도', '살인', '절도', '폭력', '범죄']
crime_anal_norm_sort = crime_anal_norm.sort_values(by='범죄', ascending=False)
plt.figure(figsize=(10, 10))
sns.heatmap(
crime_anal_norm_sort[target_col],
annot=True,
fmt='f',
linewidths=0.5,
cmap='RdPu'
)
plt.title('범죄비율(정규화된 발생 건수로 정렬)')
plt.show()drawGraph()⇊
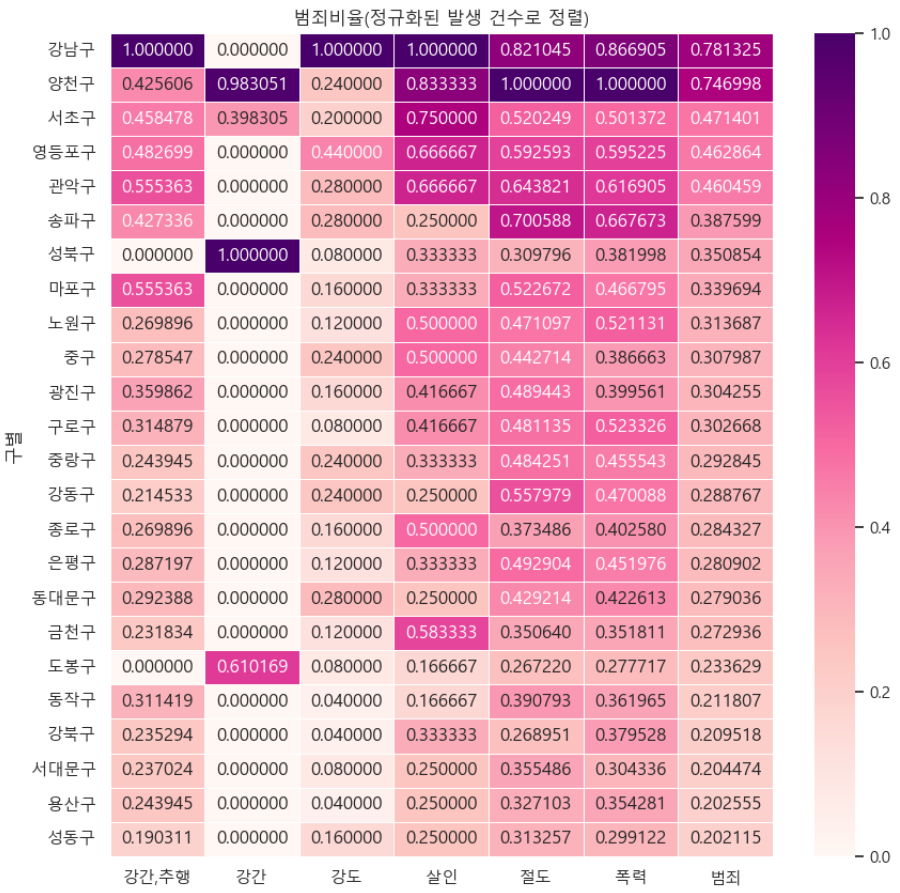
- 범죄발생 건수로 heatmap
- 대표값은 범죄 기준
🖇️ 지도 시각화- Folium
Folium은 기본적으로 크롬에서 동작이 가장 좋음
m = folium.Map(location=[45.5236, -122.6750])
m⇊
- 위도,경도 입력하면 지도상으로 표시
m.save('../data/index.html')
- 지도를 html로 저장가능
folium.Map(location=[45.5236, -122.6750], tiles='Stamen Toner', zoom_start=13)⇊
- tiles: 지도 스타일
- zoom_start: 몇 배 줌으로 확대할 건지 (0~18)
my_map = folium.Map(location=[45.32978807363888, -121.66311154513842], tiles='Stamen Terrain', zoom_start=12)
folium.Marker([45.32913940282635, -121.66409859805704], popup='<i>Mt Hood Meadows</i>').add_to(my_map)
folium.Marker([45.32972018983369, -121.66126618534908], popup='<b>Umbrella Falls Trail #667 Trailhead</b>').add_to(my_map)⇊
<folium.map.Marker at 0x21a9beffc40>
- 마커 추가 가능
my_map
⇊
m = folium.Map(location=[45.32978807363888, -121.66311154513842], tiles='Stamen Terrain', zoom_start=17)
folium.Marker(
location=[45.32913940282635, -121.66409859805704],
popup='Mt Hood Meadows',
icon=folium.Icon(icon='cloud')
).add_to(m)
folium.Marker(
location=[45.32972018983369, -121.66126618534908],
popup='Umbrella Falls Trail #667 Trailhead',
icon=folium.Icon(color='green')
).add_to(m)
folium.Marker(
location=[45.32877036879794, -121.66193935586483],
popup='한글테스트',
icon=folium.Icon(color='red', icon='info-sign')
).add_to(m)m
⇊
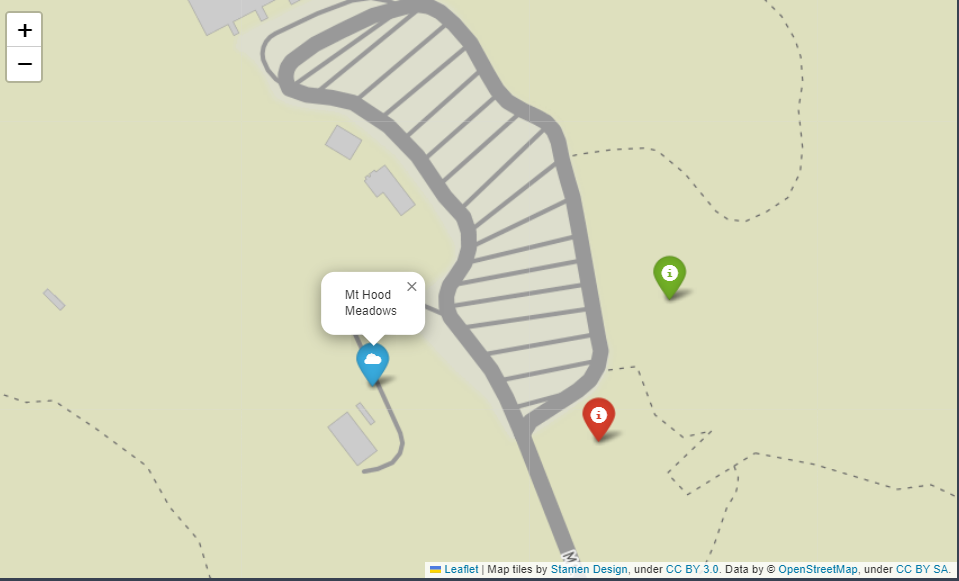
- 다양한 모양의 아이콘 지원
m = folium.Map(location=[45.536225209218316, -121.58733455455987], tiles='Stamen Toner', zoom_start=14)
folium.Circle(
radius=100,
location=[45.53898442544114, -121.56701243124628],
popup='Mount Hood',
color='crimson',
fill=False
).add_to(m)
folium.CircleMarker(
location=[45.5340957368361, -121.56559889981757],
popup='Hood River Ranger Station',
color='#3186cc',
fill=True,
fill_color='#3186cc'
).add_to(m)m
⇊
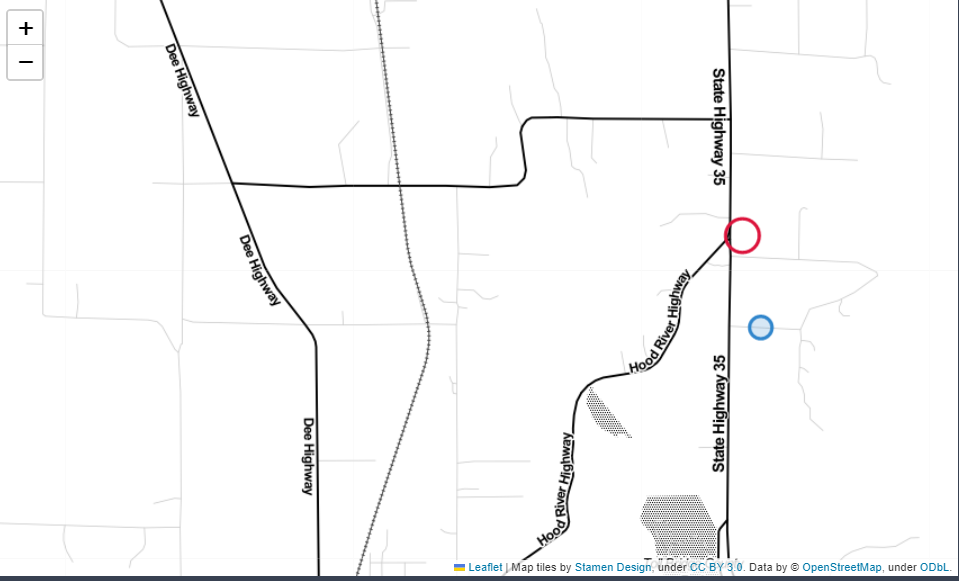
- Circle 마커 :반경 지정
m = folium.Map(location=[45.42571237115935, -121.59068688941238], tiles='Stamen Terrain', zoom_start=15)
m.add_child(folium.ClickForMarker())
m⇊
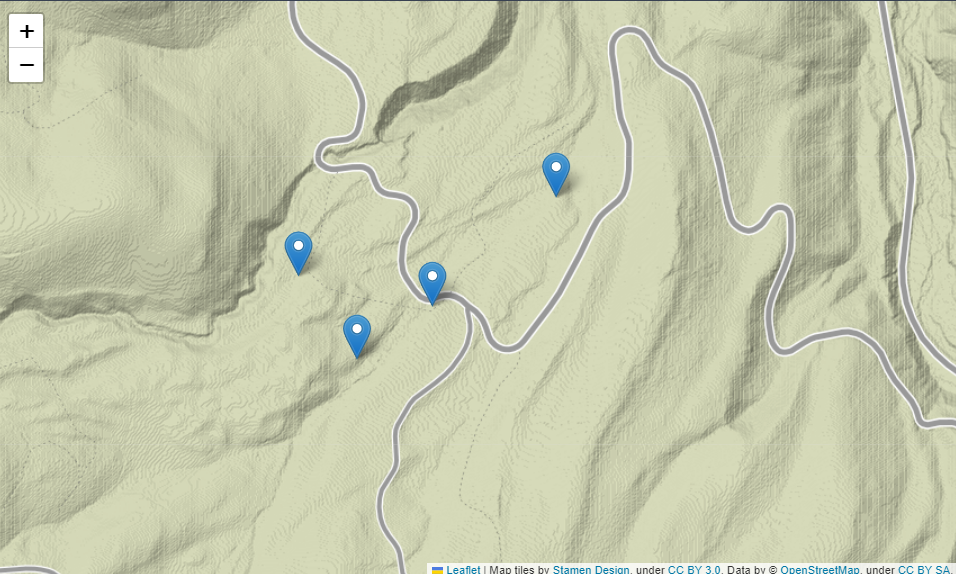
- folium.ClickForMarker(): 클릭할 때 마다 새로운 마커 생성
m = folium.Map(location=[45.42571237115935, -121.59068688941238], tiles='Stamen Terrain', zoom_start=15)
m.add_child(folium.LatLngPopup())
m⇊
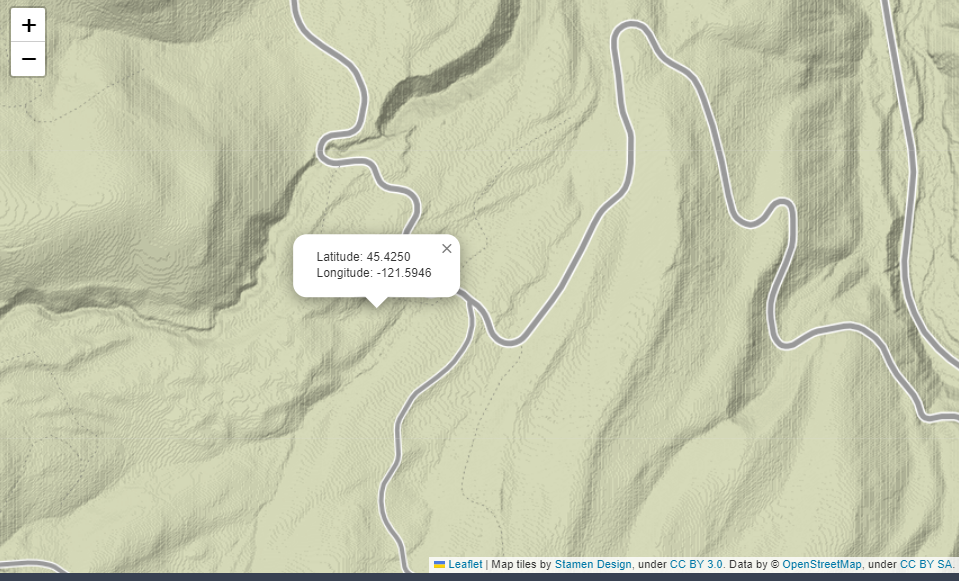
- 지도를 클릭시 그 위치의 위도,경도를 반환
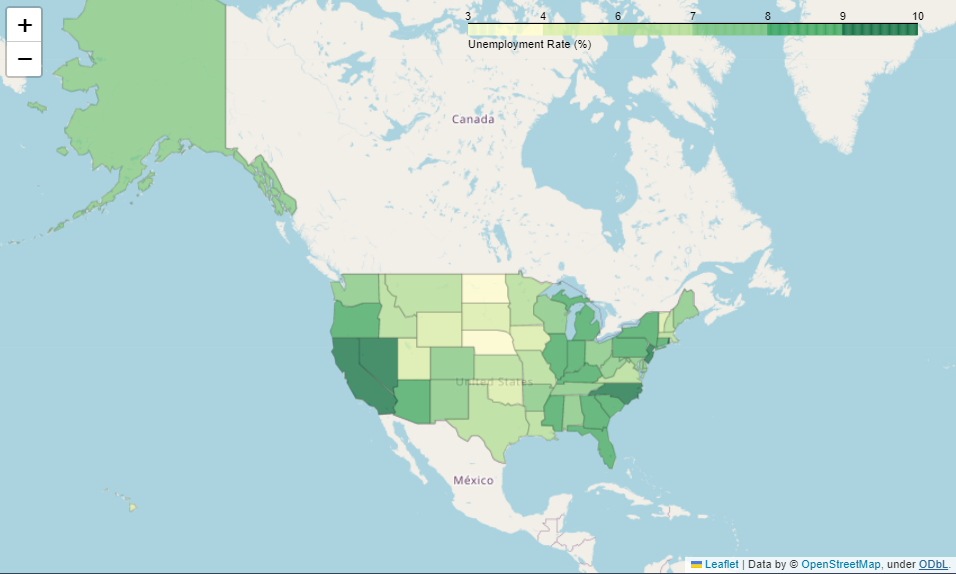
- 지도에 colormap 표현
- json 파일을 이용하여 경계선과 id를 각 지역에 구현
- csv파일에 이에 매칭되는 id와 값을 가지도록 함
import json
state_data = pd.read_csv('../data/02. US_Unemployment_Oct2012.csv')
m = folium.Map(location=[48, -102], zoom_start=3)
m.choropleth(
geo_data='../data/02. us-states.json',
data=state_data,
columns=['State', 'Unemployment'],
key_on='feature.id',
fill_color='YlGn',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='Unemployment Rate (%)'
)m
⇊
🖇️ 서울시 범죄현황 지도 시각화
import json
crime_anal_norm = pd.read_csv('../data/02. crime_in_Seoul_final.csv', index_col=0, encoding='utf-8')
geo_path='../data/02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner')
my_map.choropleth(
geo_data=geo_str,
data=crime_anal_norm['살인'],
columns=[crime_anal_norm.index, crime_anal_norm['살인']],
fill_color='PuRd',
key_on='feature.id',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='정규화된 살인 발생 건수'
)my_map⇊
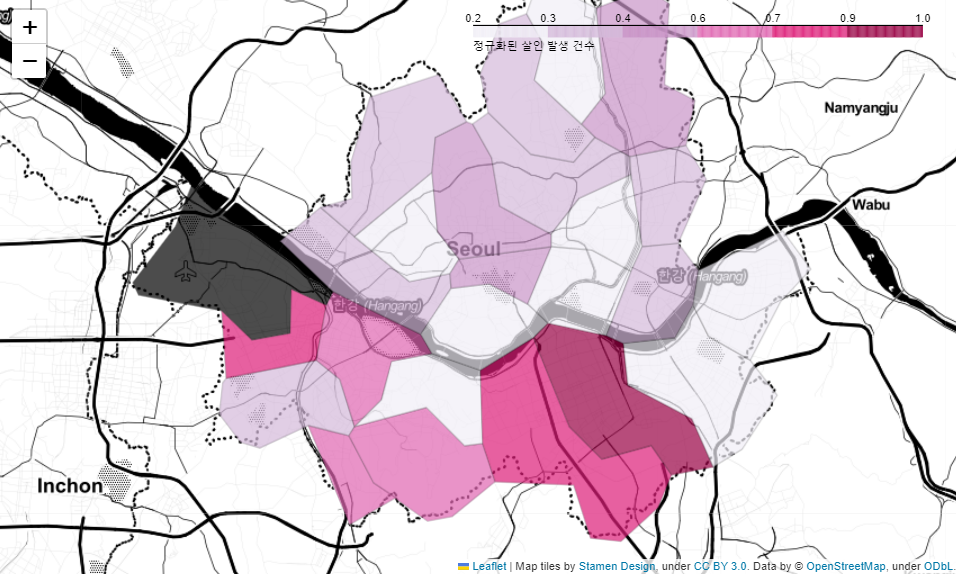
- 살인 발생 건수에대한 지도 시각화
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner')
my_map.choropleth(
geo_data=geo_str,
data=crime_anal_norm['강간,추행'],
columns=[crime_anal_norm.index, crime_anal_norm['강간,추행']],
fill_color='PuRd',
key_on='feature.id',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='정규화된 성범죄 발생 건수'
)my_map
⇊
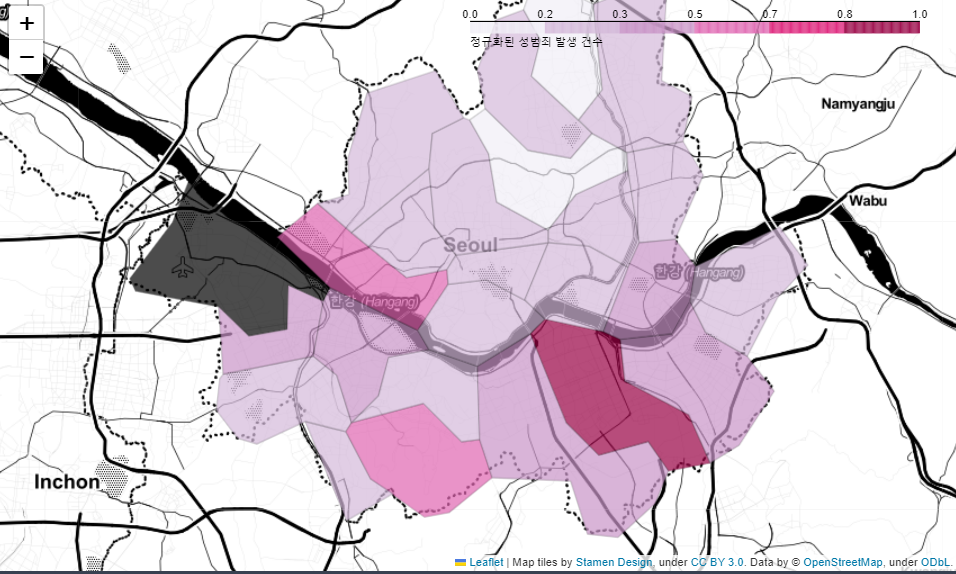
- 성범죄 발생건수에대한 지도 시각화
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner')
my_map.choropleth(
geo_data=geo_str,
data=crime_anal_norm['범죄'],
columns=[crime_anal_norm.index, crime_anal_norm['범죄']],
fill_color='PuRd',
key_on='feature.id',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='정규화된 범죄 발생 건수'
)
my_map⇊
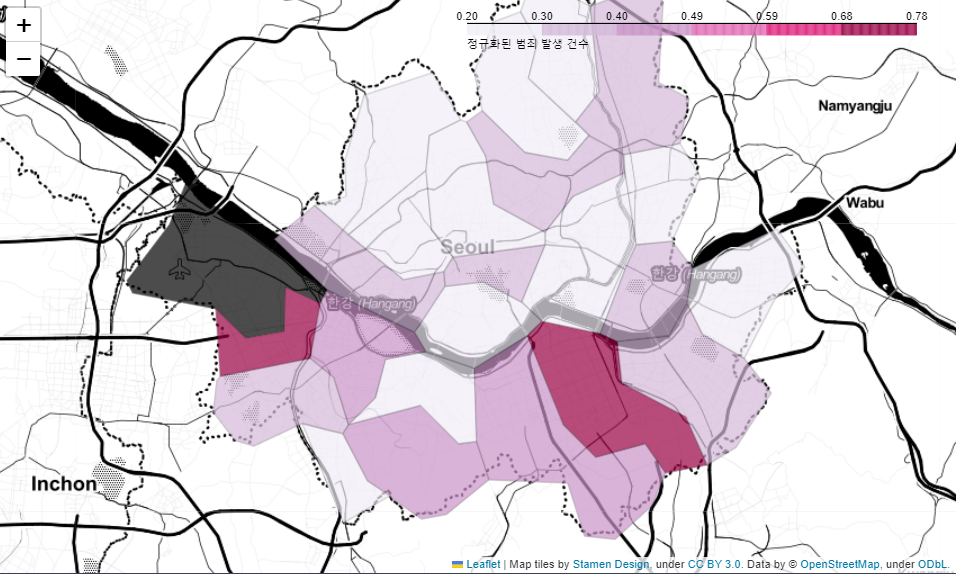
- 종합 범죄 발생 건수에 대한 지도 시각화
tmp_criminal = crime_anal_norm['범죄']/crime_anal_norm['인구수']
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner')
my_map.choropleth(
geo_data=geo_str,
data=tmp_criminal,
columns=[crime_anal_norm.index, tmp_criminal],
fill_color='PuRd',
key_on='feature.id',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='정규화된 인구 대비 범죄발생 건수'
)
my_map⇊
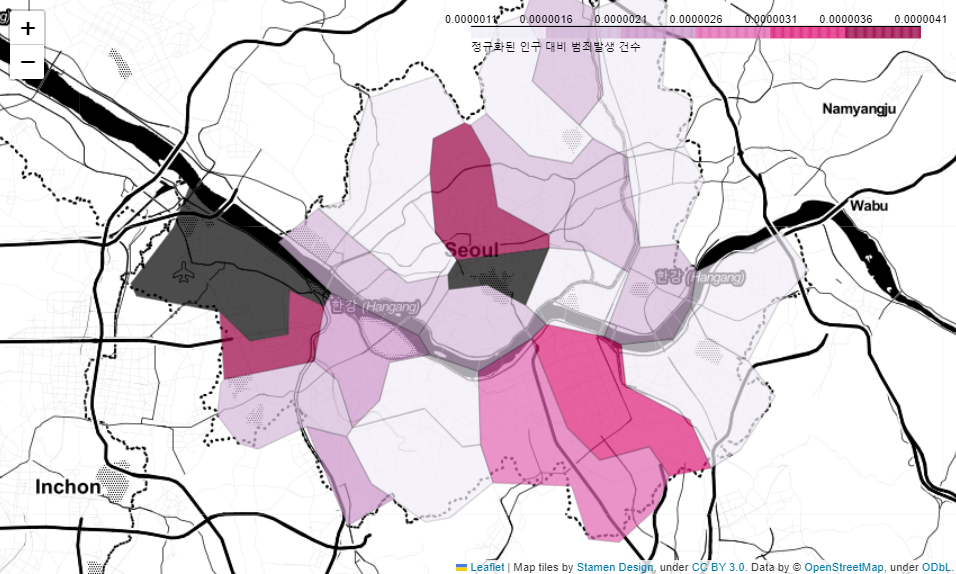
- 인구 대비 범죄 발생건수에 대한 지도 시각화
crime_anal_station = pd.read_csv(
'../data/02.crime_in_Seoul_raw.csv', index_col=0, encoding='utf-8'
)
col = ['살인검거', '강도검거', '강간검거', '절도검거', '폭력검거']
tmp = crime_anal_station[col] / crime_anal_station[col].max()
crime_anal_station['검거'] = np.mean(tmp, axis=1)
crime_anal_station.head()ㄴ경찰서별 정보를 가지고 범죄발생과 함께 정리
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11)
for idx, rows in crime_anal_station.iterrows():
folium.Marker([rows['lat'], rows['lng']]).add_to(my_map)ㄴ 경찰서 위치를 지도에 표시
my_map
⇊
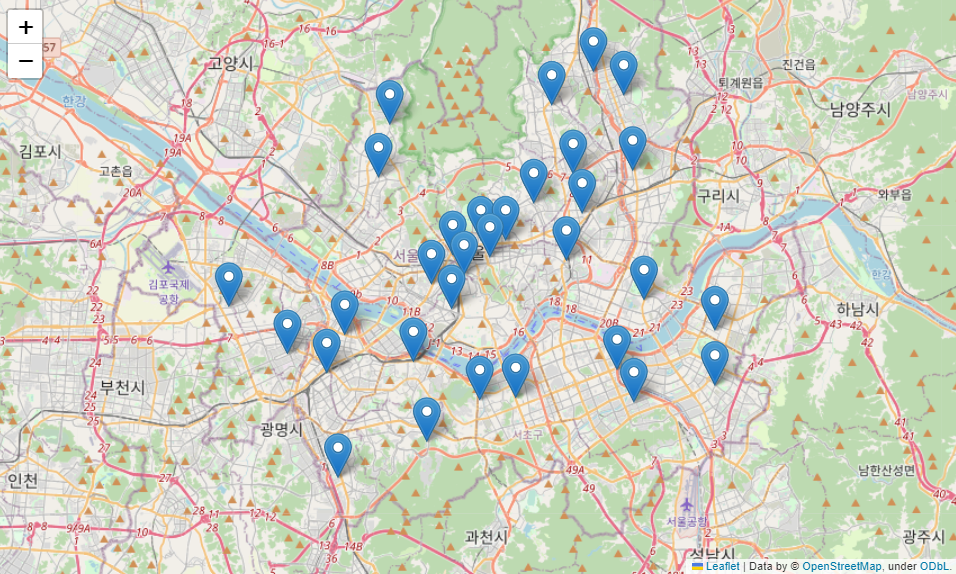
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11)
for idx, rows in crime_anal_station.iterrows():
folium.CircleMarker(
[rows['lat'], rows['lng']],
radius=rows['검거'] * 50,
popup=rows['구별'] + ':' + '%.2f' % rows['검거'],
fill=True,
fill_color='#3186cc'
).add_to(my_map)
my_map⇊
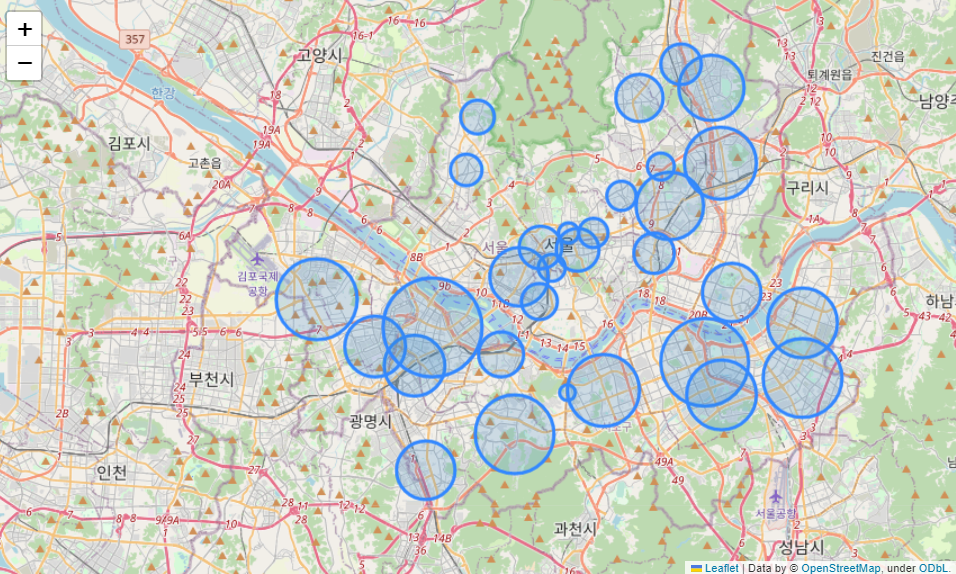
- 검거에 적절한 값을 곱해서 원의 넓이로 사용
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner')
my_map.choropleth(
geo_data=geo_str,
data=crime_anal_norm['범죄'],
columns=[crime_anal_norm.index, crime_anal_norm['범죄']],
fill_color='PuRd',
key_on='feature.id',
fill_opacity=0.7,
line_opacity=0.2,
)
for idx, rows in crime_anal_station.iterrows():
folium.CircleMarker(
[rows['lat'], rows['lng']],
radius=rows['검거'] * 50,
popup=rows['구별'] + ':' + '%.2f' % rows['검거'],
color='#3186cc',
fill=True,
fill_color='#3186cc'
).add_to(my_map)
my_map⇊

- 구별 범죄 현황과 경찰서별 검거율을 함께 표시
🖇️ 서울시 범죄현황 장소별 분석
crime_loc_raw = pd.read_csv(
'../data/02. crime_in_Seoul_location.csv', thousands=',', encoding='euc-kr'
)
crime_loc_raw.head()⇊

- 강남의 높은 범죄 발생은 유흥업소 밀집과 관련이 있지않은지
crime_loc_raw['범죄명'].unique()
⇊
array(['살인', '강도', '강간.추행', '절도', '폭력'], dtype=object)
crime_loc_raw['장소'].unique()
⇊
array(['아파트, 연립 다세대', '단독주택', '노상', '상점', '숙박업소, 목욕탕', '유흥 접객업소', '사무실',
'역, 대합실', '교통수단', '유원지 ', '학교', '금융기관', '기타'], dtype=object)crime_loc = crime_loc_raw.pivot_table(
crime_loc_raw, index=['장소'], columns=['범죄명'], aggfunc=[np.sum]
)
crime_loc.columns = crime_loc.columns.droplevel([0,1])
crime_loc.head()⇊
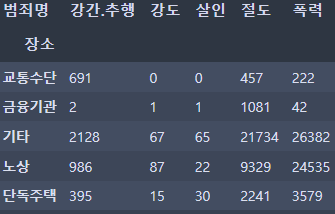
col = ['살인', '강도', '강간', '절도', '폭력']
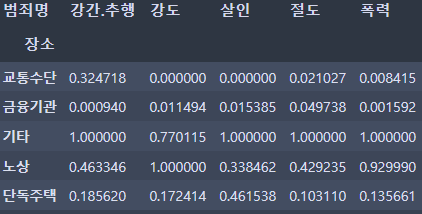
crime_loc_norm = crime_loc / crime_loc.max()
crime_loc_norm.head()⇊
crime_loc_norm['종합'] = np.mean(crime_loc_norm, axis=1)
crime_loc_norm.head()⇊
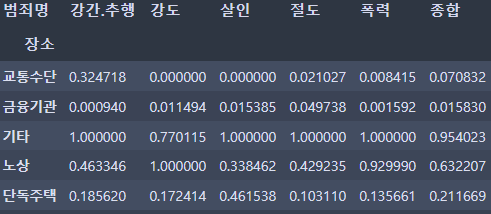
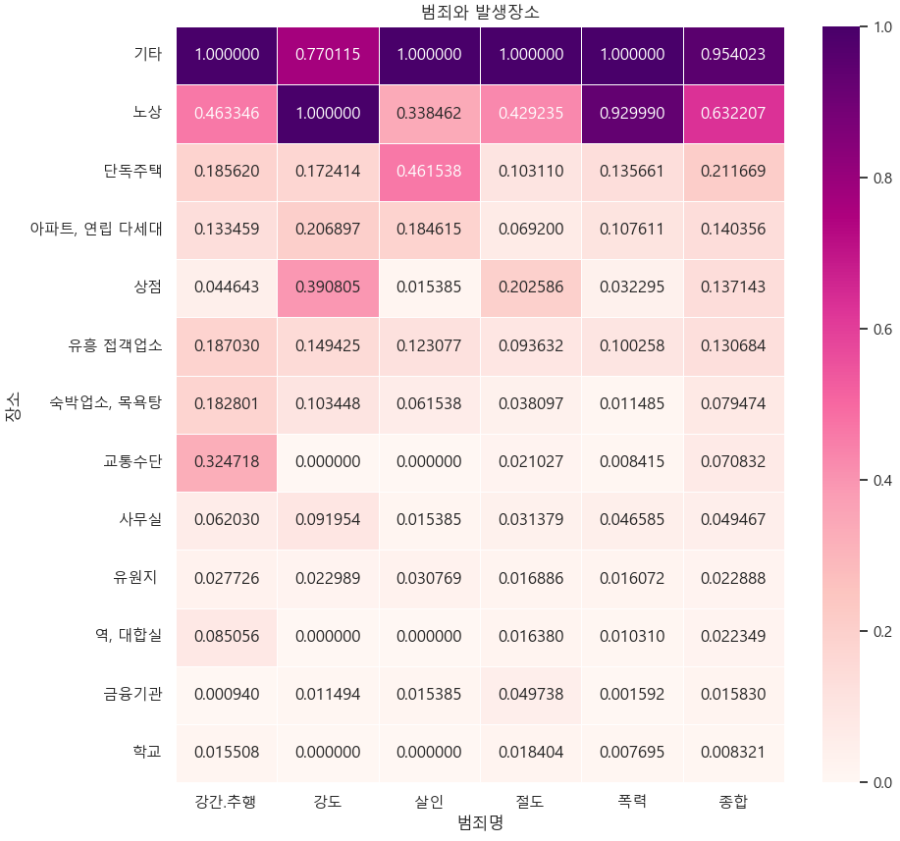
crime_loc_norm_sort = crime_loc_norm.sort_values(by='종합', ascending=False)
def drawGraph():
plt.figure(figsize=(10, 10))
sns.heatmap(crime_loc_norm_sort, annot=True, fmt='f', linewidths=0.5, cmap='RdPu')
plt.title('범죄와 발생장소')
plt.show()
drawGraph()⇊