작성일: 2022-12-26 (월)
오늘의 주제는 “파티션 테이블” 입니다.
하나의 테이블에서 반복적인 삭제 작업을 하게 된다면 해당 테이블에
SELECT하거나 INSERT 할 때 성능 저하가 발생한다는 내용을 다뤄보려고 합니다.
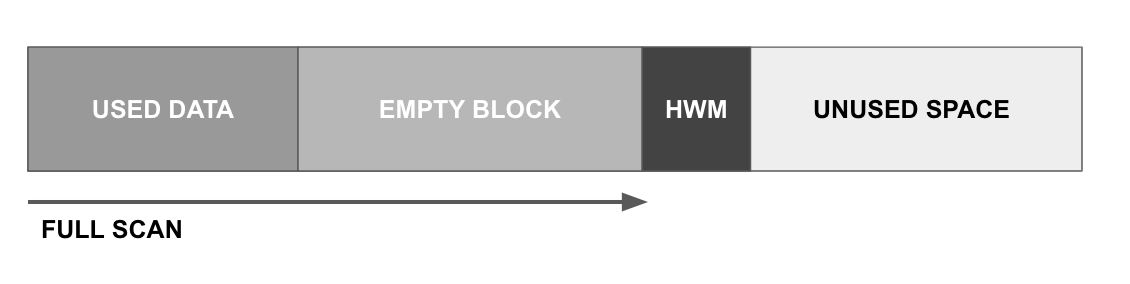
아래의 그림은 테이블에 존재하던 데이터를 삭제한 후의 모습입니다.

테이블의 데이터를 삭제하게 되면 더 이상 해당 데이터가 존재하지 않기 때문에 대부분의 사용자는 삭제 작업 과정에서 데이터가 완전히 지워지고 해당 공간마저도 반납된다고 생각하게 되지만,
실제 DBMS 내부에서는 데이터를 삭제하더라도 삭제된 데이터가 사용하던 공간은 반납하지 않습니다.
그렇기 때문에 반복적인 삭제 작업을 수행한 테이블을 조회하면 아래의 그림처럼 DBMS는 HWM 위치까지 스캔하고 결과집합을 리턴합니다.
이러한 반복적인 삭제 작업이 발생하는 테이블에서 성능 저하를 줄이기 위해서
이번에는 파티션에 대한 내용을 다뤄보겠습니다.
Partition(파티션) 이란?
- 파티션이란 하나의 테이블에서 모든 데이터를 관리하지 않고, 내부적으로 하나의 테이블을 여러개로 쪼개어 데이터를 관리하는 방식입니다.
- 사용자는 하나의 테이블에 읽기와 쓰기를 수행하지만 내부적으로는 쪼개진 여러 테이블에서 읽기/쓰기 작업을 수행하게 됩니다.

파티션에는 세 종류(List Partition, Range Partition, Hash Partition)가 존재합니다.
각각의 파티션별 장단점이 존재하지만
오늘은 Range Partition 에 대한 내용을 다뤄보려 합니다.
파티션을 사용하는 이유
- DML 작업의 성능 증가
- 인덱스를 이용한 테이블 액세스 비용은 데이터양이 늘고 추출 건수가 많아질수록 기하급수적으로 증가하게 됩니다.
- 파티션 테이블을 이용한다면 각각의 파티션 테이블에 생성된 독립적인 인덱스를 통해 빠른 작업이 가능해집니다.MySQL에서는 각각의 파티션에 로컬 인덱스가 생성되기 때문에
파티션의 키는 무조건 PK 혹은 UK로 설정되어 있어야 합니다. - 주기적인 삭제 작업이 존재하는 테이블의 경우 효율적인 관리가 가능
- 비즈니스 로직 혹은 제도화 된 법에 의해 필수 보관 주기가 지난 데이터의 경우 일반적인 DML(DELETE) 작업으로 처리할 시 많은 성능 저하 발생합니다.
- HMW (High Water Mark) 로 인한 불필요 Disk I/O 발생
- TABLE LOCK
- 이럴 경우, 파티션 단위로 데이터를 삭제하여 불필요한 리소스를 사용하지 않고 처리가 가능합니다.
- 비즈니스 로직 혹은 제도화 된 법에 의해 필수 보관 주기가 지난 데이터의 경우 일반적인 DML(DELETE) 작업으로 처리할 시 많은 성능 저하 발생합니다.
- 데이터의 물리적인 저장소 분리
- 파티션을 통해 파일 크기 조절, 저장 위치 등을 지정 / 저장할 수 있게 됩니다.
파티션 생성 쿼리
# MySQL
create table emp_log (
emp_no int not null auto_increment,
hire_date datetime not null default now(),
emp_name varchar(30) not null,
primary key (emp_no, hire_date),
key (hire_date)
) partition by range (columns(hire_date)) (
PARTITION p_202212 VALUES LESS THAN ('2023-01') ENGINE = InnoDB,
PARTITION p_202301 VALUES LESS THAN ('2023-02') ENGINE = InnoDB,
PARTITION p_202302 VALUES LESS THAN ('2023-03') ENGINE = InnoDB
);파티션 테이블에서의 쿼리 처리 방법
읽기
- where 조건으로 파티션 키 컬럼이 사용될 경우 레코드가 저장된 파티션에서 빠르게 대상 레코드 조회 가능
- where 조건으로 파티션 키 컬럼이 사용되지 않는다면 레코드를 찾기 위해 모든 파티션을 스캔하고 이에 따른 부하 발생
쓰기
- 파티션 키인 "hire_date" 컬럼 값을 이용해 레코드가 저장될 파티션 결정
- 데이터 삽입 시, 저장될 파티션 선택 이외에는 일반 테이블에서의 삽입 과정과 동일
- 파티션 선택 가능 + 인덱스 스캔
- 가장 효율적인 처리 가능
- 파티션 선택 불가 + 인덱스 스캔
- 특정 파티션을 선택할 수 없기 때문에 모든 파티션에 대한 스캔이 필수적이며 인덱스 Range Scan 사용 또는 파티션 테이블의 수가 많을수록 성능 저하
- 파티션 선택 가능 + 테이블 풀스캔
- 특정 파티션에 대한 풀스캔 진행, 대상 파티션 테이블의 데이터 수에 의해 성능과 연결
- 파티션 선택 불가 + 테이블 풀스캔
- 특정 파티션을 선택할 수 없기 때문에 모든 파티션에 대한 스캔이 필수적이며 각 파티션별 풀스캔 진행, 가장 성능이 느리며 많은 부하 발생
파티션 테이블을 생성하더라도 조회 과정에서 파티션 테이블의 키를 명시하지 않으면 결국 모든 파티션 테이블을 조회하며 FULL SCAN 작업이 진행되므로 주의해야 합니다.
특히, MySQL을 사용하는 사용자라면 더욱더 주의가 필요합니다.
MySQL 환경에서 Range Partition을 사용한다면 오라클과 같이 MAXVALUE 기능이 존재하지 않기 때문에 주기적인 관리가 중요합니다.
파티션 테이블을 사용하게 되면 그만큼 관리 포인트가 늘어나기 때문에 관리자의 입장에서는 장애 발생 가능성을 지닌 채 운영해야 합니다.
그렇기 때문에 파티션 테이블은 적절한 상황에서 적절한 테이블에 도입하여 관리하는 것이 중요합니다.
