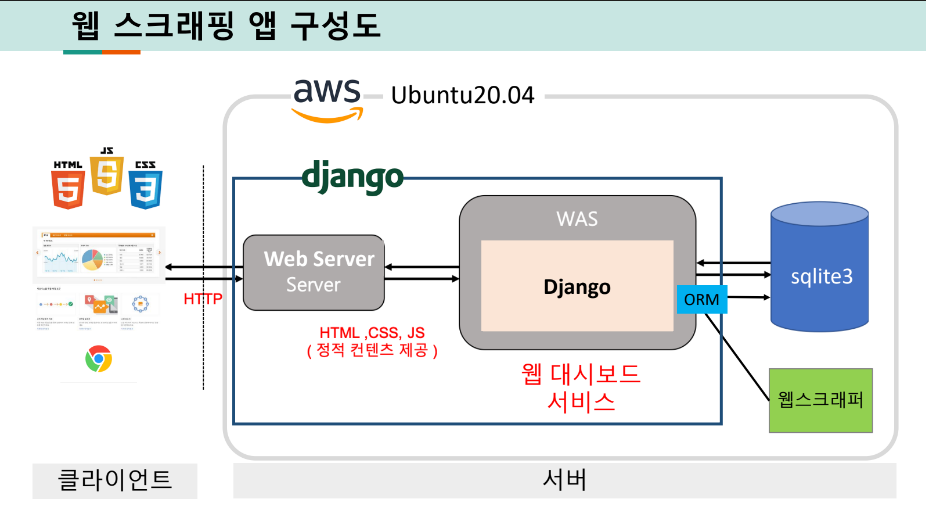
구성
Scraper_v1 -> 웹 스크래핑 코드구현
-web_scraper/scripts/scraper_test1.py
# 웹 스크래핑 코드
# library import
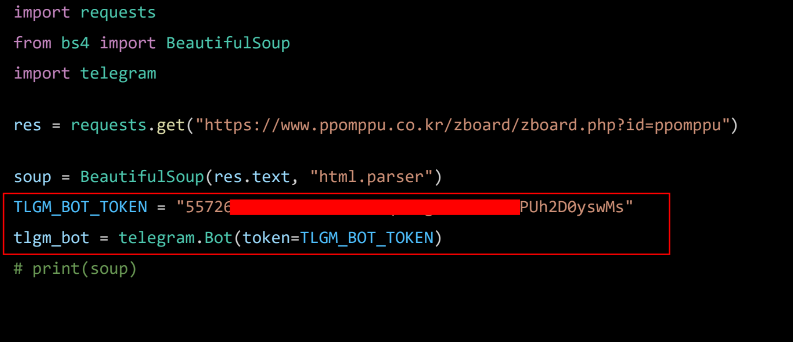
import requests
from bs4 import BeautifulSoup
url = "https://www.ppomppu.co.kr/zboard/zboard.php?id=ppomppu"
res = requests.get(url)
#print(res) #<Response [200]>
#print(res.text) # html 코드 출력
soup = BeautifulSoup(res.text, "html.parser") # text로 받은 결과를 html로 파싱하라.
# print(soup) # 출력은 똑같지만 Bs객체로 하나하나씩 요소 지정 가능
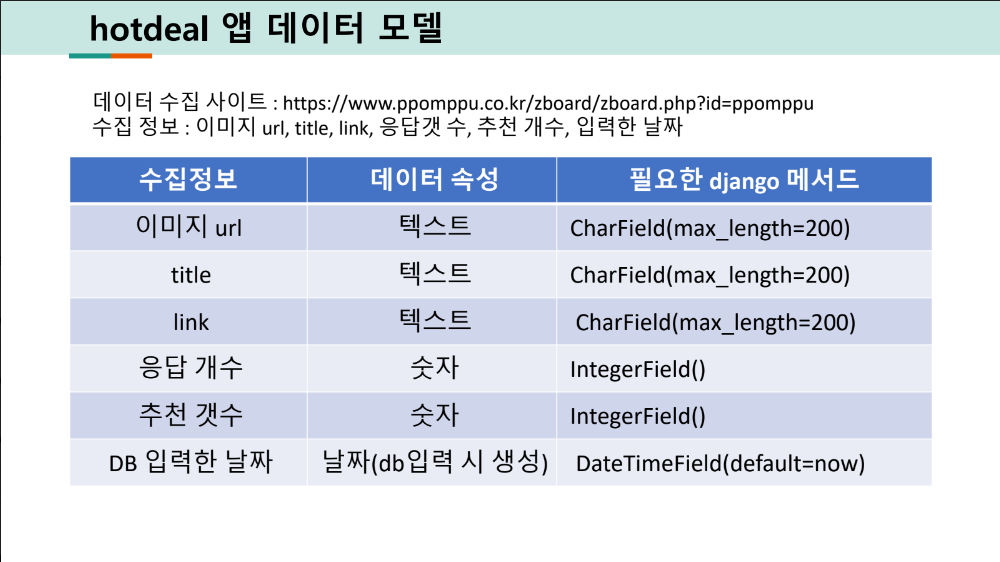
# 이미지url | title | link | 응답개수 | 추천개수 | DB입력한 날짜
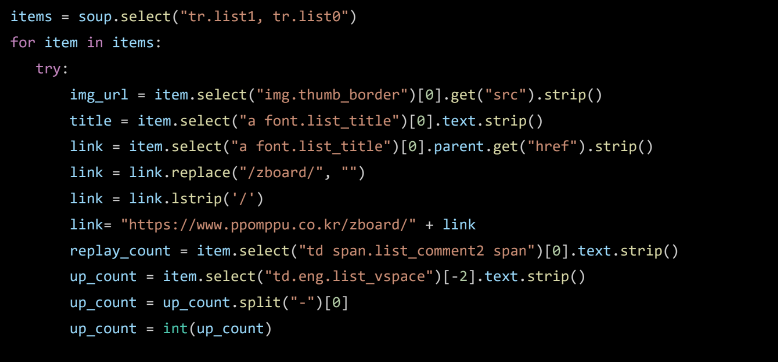
items = soup.select("tr.list, tr.list0")
for item in items:
try:
img_url = item.select("img.thumb_border")[0].get('src').strip()
# [0]:대괄호를 벗김 | get('src'):이미지속성태그 | strip():공백제거
title = item.select("a font.list_title")[0].text.strip()
# text : 태그안 텍스트만 select해주는 메소드
link = item.select("a font.list_title")[0].parent.get('href').strip()
# a태그 안 font를 감싸고있는 부모태그인 href여서 parent메소드 사용
link = link.replace('/zboard', "").lstrip('/')
# /zboard 가 있는 링크도 있고 없는 링크도 있으니,
# 있는 링크는 제거를 한 뒤 기존 url에 다시 붙이는 순서
link = "http://www.ppomppu.co.kr/zboard/" + link
reply_cnt = item.select("span.list_comment2 span")[0].text.strip()#응답개수
#추천개수
up_cnt = item.select("td.eng.list_vspace")[-2].text.strip()#추천개수
up_cnt = up_cnt.split('-')[0]
up_cnt = int(up_cnt)
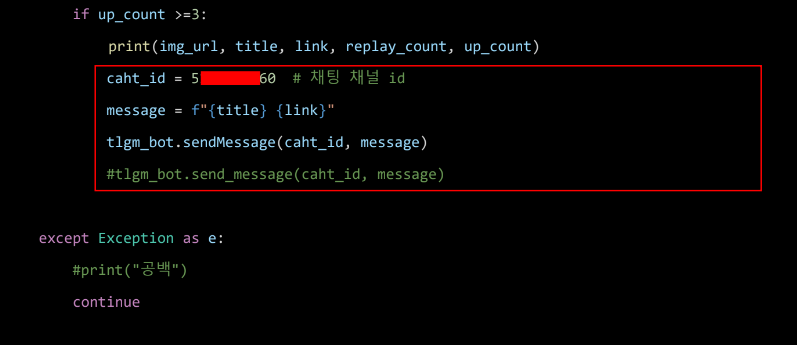
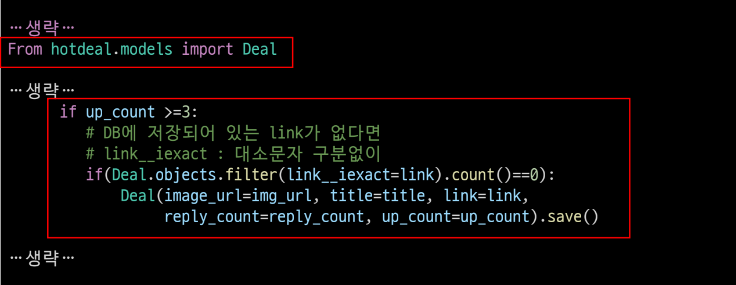
if up_cnt >=3:
# 터미널 프린트
print(img_url, title, link, reply_cnt, up_cnt)
print(up_cnt)
except Exception as e:
continue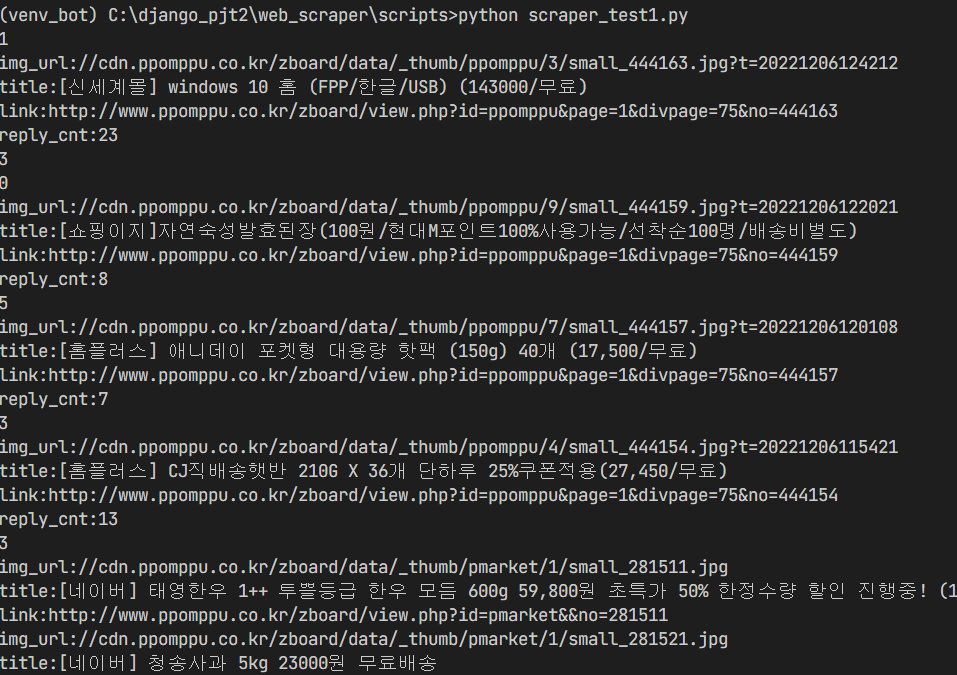
텔레그램 봇 만들기
텔레그램 다운 : https://desktop.telegram.org/
텔레그램 봇 만들기 참고 : https://chancoding.tistory.com/149
- 채팅방 id값
https://api.telegram.org/bot[my_channel_토큰]/getUpdates
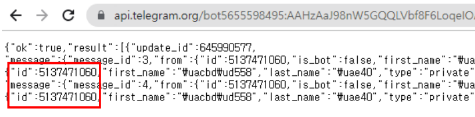
텔레그램 봇 TOKEN값과 채널 방 ID값 따로 메모!
Scraper_v2 -> 텔레그램 push구현
- web_scraper/scripts/scraper_test2.py
Scraper -> 스크래퍼와 장고 연결
-
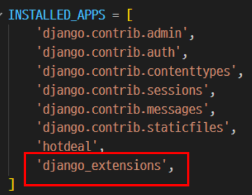
pip install django_extensions모듈 설치- settings.py, app 추가
- settings.py, app 추가
-
web_scraper/scripts/scraper.py 구현
-
python manage.py runscript scraper'

-
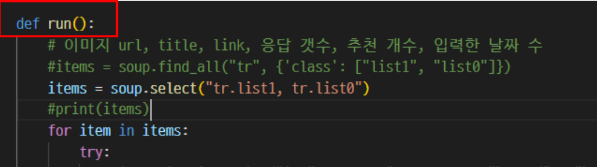
오류 해결 방법은 scraper.py 파일의 실행 부분을 run() 함수로 정의하면 됨
-
django_extensions를 설치하면 py범위있는 파일도 django범위가된다. 즉, 한 파일안에서 여러 파일로 import가 가능해졌다.
-
env_info.py

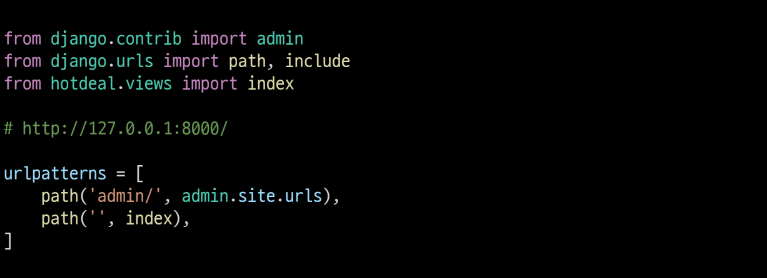
URLconf와 Views, Settings 설정
-
urls.py
-
views.py
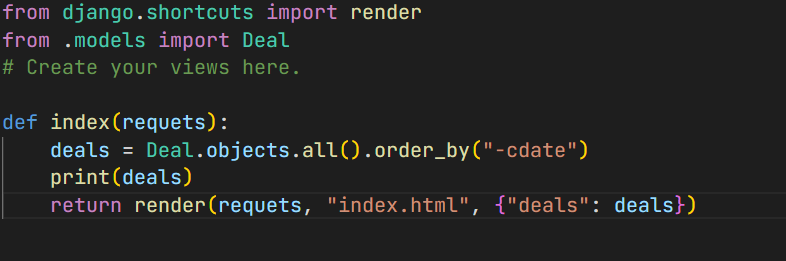
-
settings.py
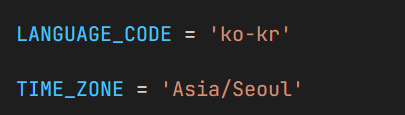
언어와 시간대
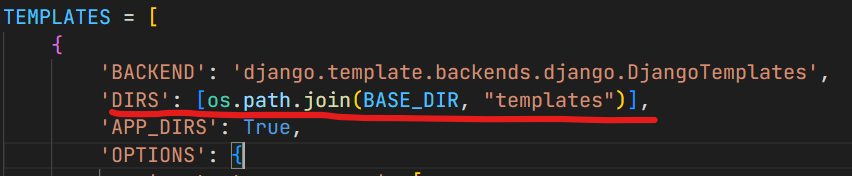
절대경로설정
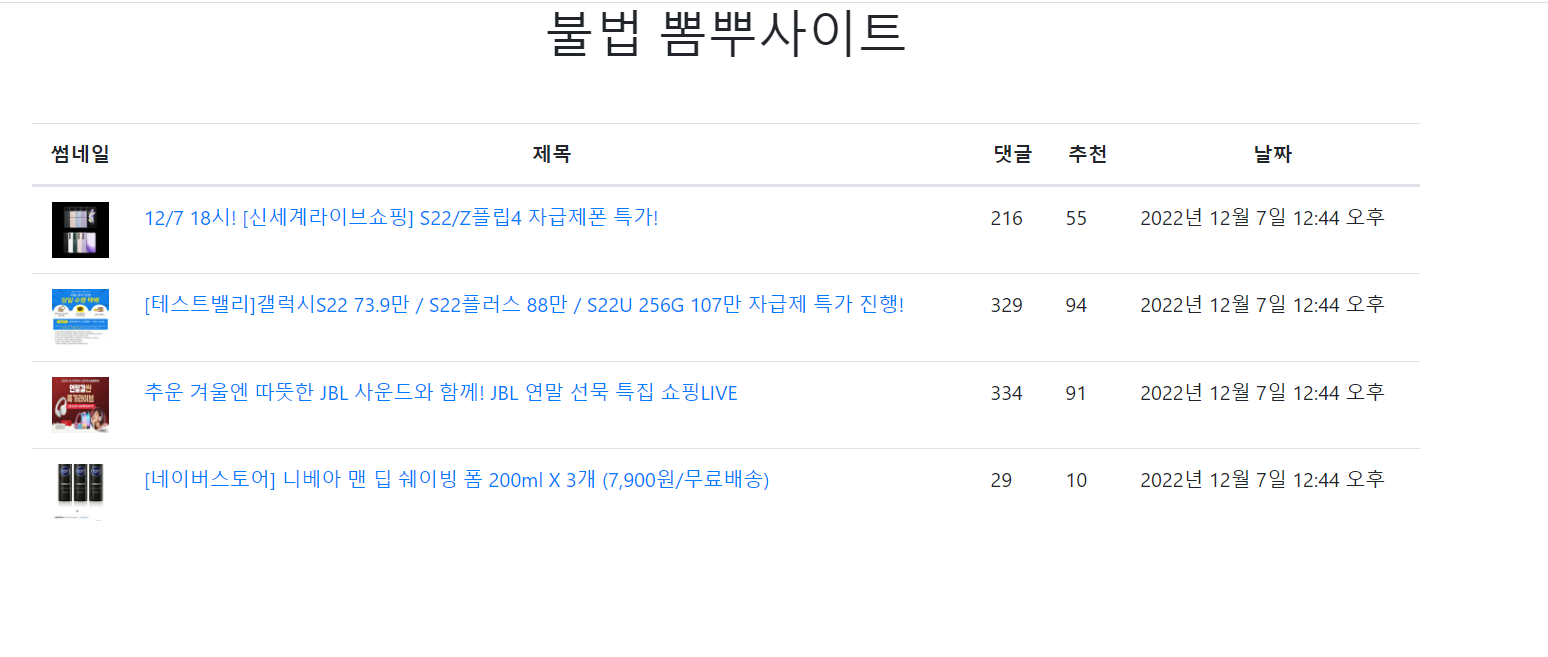
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/css/bootstrap.min.css" integrity="sha384-Vkoo8x4CGsO3+Hhxv8T/Q5PaXtkKtu6ug5TOeNV6gBiFeWPGFN9MuhOf23Q9Ifjh" crossorigin="anonymous">
<style>
img {
width: 45px;
}
th {
text-align: center;
white-space: nowrap;
}
td.center {
text-align: center;
}
</style>
</head>
<body>
<div style="text-align: center;">
<h1>불법 뽐뿌사이트</h1>
</div>
<div class="container mt-5">
<table class="table table-hover">
<thead>
<tr>
<th scope="col">썸네일</th>
<th scope="col">제목</th>
<th scope="col">댓글</th>
<th scope="col">추천</th>
<th scope="col">날짜</th>
</tr>
</thead>
<tbody>
{% for deal in deals %}
<tr>
<td class="center"><img src="{{deal.img_url}}"></td><!-- style="width:40px; heigh:40px"></td> -->
<td><a href="{{deal.link}}">{{deal.title}}</a></td>
<td>{{ deal.reply_cnt }}</td>
<td>{{ deal.up_cnt }}</td>
<td>{{ deal.cdate }}</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
</body>
</html>
👨Education Computer Engineering 🎓Expected Graduation: February 2023 📞Contact info thstjddn77@gmail.com