SELECT, NULL, 열 별칭, 리터럴 문자열, 중복행 제거, WHERE, 연산자(산술, 연결, 비교, 논리, IN, NULL값 체크, LIKE), ESCAPE, ORDER BY
빅데이터&머신러닝 - SQL
어제까지 배운 내용을 정리하면,
SQL
데이터베이스에 있는 테이블의 데이터를 액세스 할 수 있는 언어. DQL, DML, TCL, DDL, DCL 등이 있다.
- DQL(데이터 쿼리 언어) : SELECT
- DML(데이터 조작 언어) : INSERT, UPDATE, DELETE, MERGE
- TCL(트랜잭션 통제 언어) : COMMIT, ROLLBACK, SAVEPOINT
- DDL(데이터 정의 언어) : CREATE, ALTER, DROP, RENAME, TRUNCATE, COMMENT
- DCL(데이터 통제 언어) : GRANT, REVOKE
테이블(TABLE)
행(ROW)과 열(COLUMN)으로 이루어진 데이터의 저장 구조
SQL에서는 이런 테이블 안에 있는 데이터를 여러 가지 조건을 통해 추출하는 방법들을 배우고 있다.
SELECT문의 기능
- PROJECTION(열 추출)
- SELECTION(행 추출)
- JOIN : 서로 다른 테이블의 데이터를 추출(나중에 INNER JOIN, OUTER JOIN 배움)
SQL 작성할 때 주의사항
-
SELECT, FROM, WHERE과 같은 것들은 대문자로 작성, 나머지 컬럼 이름은 소문자로 작성하는 것이 좋다.
-
공백과 Tab key, Enter key를 주의하자. 중구난방이면 선술한 데이터와 다른 데이터로 인식하여 결과적으로 SQL의 성능을 떨어뜨린다.
-
HINT(F10) : 작성한 코드 안에 커서를 두고 F10을 누르면 그 코드에 대한 실행계획이 나오고, 문장을 확인할 때 유용하게 쓰인다.
-
주석 처리를 잘하자. 회사에서 협업하다보면 주석이 매우 유용하다.
/
여러 행 주석 처리
/-- 단일 행 주석 처리
-
절은 서로 다른 줄에 작성하자. 그래야 가독성이 좋다.
-
SQL문 제일 뒤에 ;으로 종료하자. Ctrl+Enter만 해도 실행은 되지만 ;을 써줘야 중간에 오류가 안 난다.
여러가지 연산자도 배웠다. 첫 날엔 산술연산자, 연결연산자를 배웠다.
연산자
1. 산술연산자
그냥 사칙연산이다. 원래 계산하던 것 처럼 곱셈, 나눗셈을 먼저 수행하고 덧셈, 뺄셈이 더 후순위이다. 사칙연산의 순서를 제어할 땐 원래 연산하던 것 처럼 괄호를 붙이면 된다. 숫자(NUMBER) 타입의 데이터는 사칙연산이 전부 가능하고, 문자(VARCHAR2, CHAR) 타입의 데이터는 사칙연산이 불가능하고, 날짜(DATE) 타입의 데이터는 덧셈, 뺄셈만 가능하다. (각 컬럼의 데이터가 무슨 타입인지 확인할 때는 desc 컬럼이름)
SELECT 1 * (2 / 3) + 4 + 5
FROM dual; -- dual은 dummy table, 가상의 테이블을 말한다.2. 연결연산자
컬럼이나 문자열을 다른 컬럼에 연결할 때 사용한다. 두 개의 세로선(||)으로 표현한다.(세로선은 shift+\ 누르면 된다.) 결과는 무조건 문자열로 생성된다.
SELECT last_name ||' '|| fisrt_name
FROM employees;last_name과 first_name 컬럼을 연결연산자로 이어주었고 두 데이터 사이에 공백문자를 넣어주기 위해 작은 따옴표를 사용했다. 이 또한 문자열이므로 연결연산자를 이중으로 사용했다.
NULL
결측치, 결측값이라고 한다. 사용할 수 없고, 알 수 없고, 할당할 수 없고... 0도 아니고 그렇다고 공백도 아니다. NULL은 SQL 뿐만 아니라 R, Python 모두 사용되는 개념이니 참고하도록 한다.
조건제어문
약간 파이썬 기초 배울 때 if elif else하는 느낌이었다. 다른 회차 때 더 자세히 언급된다고 한다.
IF commission_pct IS NULL THEN
0
ELSE
commission_pct
END IF;만약 commission_pct가 NULL이면 THEN을 만나서 0으로 return, 아니면 그냥 commission_pct 값을 return한다는 뜻이다.
그러나 SQL에서는 조건제어문(PL/SQL)을 사용할 수 없어서 nvl이라는 함수를 이용해줘야 한다.
nvl 함수는 null 값을 실제값으로 대체하는 함수라고 한다. 아래와 같이 쓴다고 한다.
nvl(컬럼이름, 실제값)예시를 들어보자!
SELECT
employee_id,
salary,
commission_pct,
(salary*12) + (salary*12*nvl(commission_pct, 0)
FROM employees;위의 조건제어문에서 "만약 commission_pct가 NULL이면 THEN을 만나서 0으로 return" 이 부분에 주목해야할 것 같다. NULL이면 0을 return 한다고 했다. 근데 SQL에서는 그걸 못한다. 그러니까 null 값을 실제값인 0으로 대체할 수 있는 nvl 함수를 쓰는거다.
열 별칭
alias. 너~무 긴 컬럼(열) 이름에 닉네임을 붙여주는거다. 방식은 여러가지가 있다.
~~~너~무 긴 컬럼~~~ 별칭 -- 바로 뒤에 한 칸 띄어쓰기
~~~너~무 긴 컬럼~~~ as 별칭 -- 선택사항. 문장이 너무 복잡하거나 길 때, 센스있게 as를 붙이면 구분이 쉽다.
~~~너~무 긴 컬럼~~~ "별칭" -- 공백, 특수문자 있거나, 숫자가 맨 앞이거나, 대소문자 구분하려면 큰 따옴표리터럴 문자열
작은 따옴표로 묶여 있는 문자를 말한다. 어퍼스트로피에스('s) 같은 축약형은 어떻게 하지? 두 가지 방법이 있다.
-
작은 따옴표를 하나 더 붙인다.
SELECT 'My name''s ' || last_name ||' ' || first_name -
q'[리터럴문자열]' (대괄호 말고 꺽쇠나 느낌표도 가능)
SELECT q'[My name's]' || last_name ||' ' || first_name
여기까지가 어제 배운 내용. 오늘 배운 내용도 정리해보자.
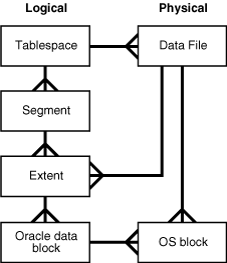
우선 개념적인 내용부터 배웠다. DB와 Block등의 용어를 정의할 때 이것을 책으로 비유한다고 해보자. 이를 테면, 집에 책장이 있다고 했을 때 집은 DB, 책장은 Tablespace, 책은 Segment(Table), 장(chapter)은 Extent, 페이지는 Block, 문장은 row를 의미한다. 특히 Block은 oracled에서 I/O의 최소 단위를 말한다. 이것은 모두 논리적인 관점에서 DB를 보았을 때이고, 물리적인 관점에서 본다면 OS>Datafile>OS Block으로 나뉜다고 한다.
중복행 제거
동일한 데이터의 여러 행들이 있을 때 distinct 키워드를 이용하여 중복을 제거할 수 있다.
SELECT distinct employee_idWHERE 절!!! ★★★
원하는 데이터만 뽑아서 보고 싶을 때 조건을 걸어주는 절이다. 영문자는 대소문자를 구별하고, 문자열이나 날짜열은 작은 따옴표로 묶어줘야한다. 그리고 중요한 것은 날짜 타입의 경우 SQL Developer를 실행하고 있는 지역에 따라 표시 형식을 다르게 해주어야한다. 한국의 경우 (RR/MM/DD)로 쓰고, 미국은 (DD-MON-RR)로 표기한다.
그리고 오늘은 비교연산자, 논리연산자, IN연산자, NULL 연산자, LIKE 연산자를 배웠다.
연산자
3. 비교연산자
컬럼이름과 비교값들을 가지고 비교하는 경우가 많다. 주로 범위를 비교하지만 문자열 또한 비교 가능하다.
=(같다), >(크다), >=(크거나 같다), <(작다), <=(작거나 같다), !=, ^=, <>(같지 않다)기간, 날짜 등을 표시할 때 쓰기도 한다.
SELECT *
FROM employees
WHERE hire_date >= '01/01/01'
AND hire_date <= '02/12/31';2001~2002년에 입사한 사원을 출력하라는 뜻이다.
4. 논리연산자
AND, OR, NOT이 있다. AND는 두 조건이 모두 참일 경우 True, OR는 두 조건 중 하나가 참일 경우 True, NOT은 FALSE일 경우 True, True일 경우 False를 출력한다. 논리연산자의 우선순위는 NOT > AND > OR 이다.
SELECT *
FROM employees
WHERE hire_date BETWEEN '01/01/01' AND '02/12/31'; 위와 같은 예제. BETWEEN A AND B를 쓸 수도 있다. 대신 hire_date라는 기준컬럼이 동일해야한다.
SELECT
last_name,
salary
FROM employees
WHERE salary NOT BETWEEN 2500 AND 3500;salary가 2500~3500이 아닌 사원들의 last_name과 salary를 출력하라는 뜻이다. BETWEEN 앞에 NOT을 붙일 수도 있다.
5. IN 연산자
각 목록의 값과 일치하는 값을 추출할 때 사용한다. IN 연산자에도 NOT을 사용할 수 있다.
-
SELECT * FROM employees WHERE employee_id = 100 OR employee_id = 101 OR employee_id = 102; -
SELECT * FROM employees WHERE employee_id IN (100,101,102);
1번과 2번 쿼리문은 동일한 결과를 나타낸다.
컬럼 이름이 동일하다는 전제 하에 OR로 여러 번 연결하는 것 보다 IN 연산자를 사용하면 훨씬 간단하게 출력이 가능하다.
6. NULL 값을 체크하는 연산자
IS NULL, IS NOT NULL이 있다. NULL인 것, NULL이 아닌 것만 추출한다.
7. LIKE 연산자
모르는 문자 패턴을 찾는 연산자. 활용은 %와 _로 다음과 같이 할 수 있다.
WHERE last_name LIKE 'K%' -- 대문자 K로 시작하는 데이터
WHERE last_name LIKE 'K___' -- 대문자 K로 시작하면서 뒤에 세 글자만 붙는 데이터
WHERE last_name LIKE '_i%' -- 첫 글자 아무거나, 두번째 글자는 i로 된 데이터여러 가지 예제를 풀다 보니 LIKE 연산자로 활용할 수 있는 부분이 엄청 많았다. 하지만 절대절대절대 하면 안 되는 것이 숫자, 날짜!!! 찾을 때는 사용하면 안된다. 특히 날짜!!! 이를 테면,
SELECT *
FROM employees
WHERE hire_date LIKE '02%';이렇게 작성해도 실행은 된다. 하지만 hire_date는 날짜 타입의 컬럼이고 LIKE 연산자는 문자열 데이터를 추출하는 연산자이다. F10(실행계획)을 눌러보면 알 수 있는데 SQL Developer의 inner fuction을 통해 형 변환이 일어나기 때문에 실행이 되기는 하지만, 결과적으로 보면 방대한 양의 데이터를 처리할 때 이런 방식이 오히려 성능을 저해하는 요소가 된다.
위 예제의 경우, 문제의 의도는 2002년도에 입사한 사원의 정보를 추출하라는 의미이므로 다음과 같이 작성하는 것이 오히려 바람직하다.
SELECT *
FROM employees
WHERE hire_date BETWEEN '02/01/01' AND '02/12/31';ESCAPE '\'
LIKE 연산자를 쓸 때 언더스코어나 퍼센트를 순수한 문자로 인식할 수 있게 하는 방법이다. 예를 들면, LIKE 연산자를 이용해서 HR_REP, HR_PROG 라는 데이터를 추출하고 싶을 때,
SELECT *
FROM employees
WHERE job_id LIKE 'HR_%'이렇게 작성하면 HR 뒤에 붙은 언더스코어 때문에 오류가 난다. 이런 문제를 막기 위해 ESCAPE라는 키워드를 사용해서 LIKE 연산자에 쓰이는 언더스코어나 퍼센트를 순수한 문자로 변환하는 과정을 거쳐야한다.
SELECT *
FROM employees
WHERE job_id LIKE 'HR\_%' ESCAPE '\'예제에 ESCAPE '\'를 적용한 결과다. WHERE 절 맨 뒤에 ESCAPE 키워드로 '\'를 선언해주고, 이제부터 역슬래시 "바로" 뒤에 나온 글자는 순수한 문자로 취급하겠다 는 의미이다. 다른 예제에도 적용해보자.
SELECT *
FROM employees
WHERE job_id LIKE 'HR\_\%%' ESCAPE '\'위 예제는 HR_%로 시작하는 데이터를 추출하겠다는 의미이다. 원본 데이터에 언더스코어나 퍼센트가 이미 있어서 이것을 역슬래시로 각각 문자 취급하도록 만들어주었다.
ESCAPE '\'는 한번 이해하면 쉬운데 기억이 잘 안나는게 문제다. 너무너무너무 중요한 개념이니까 잊지 않도록하자.
ORDER BY
FROM 절의 테이블에서 SELECT 절로 데이터를 추출하고나면, 이것을 SORT(정렬)하는 과정이 필요하다. 이 때 ORDER BY 절을 이용하는데 오름차순은 asc(근데 오름차순은 디폴트라 asc라고 안 써줘도 된다.), 내림차순은 desc라고 절의 가장 마지막에 써준다.
SELECT
employee_id,
(salary*12) + (salary*12*nvl(commission_pct,0)) annual_salary
FROM employees
ORDER BY annual_salary desc;(salary12) + (salary12*nvl(commission_pct,0))라고 하는 긴 표현식이 있다. 이 경우엔 annual_salary라는 별칭을 붙여주었는데, ORDER BY 절에도 마찬가지로 별칭을 쓸 수 있다. 별칭을 큰 따옴표로 붙였다면 ORDER BY 절에도 큰 따옴표로 표시해야한다.
그리고 ORDER BY에는 위치표기법이라고 해서 컬럼의 이름을 숫자로 표현할 수도 있다. 이를 테면,
SELECT
employee_id,
department_id,
(salary*12) + (salary*12*nvl(commission_pct,0)) "annual_salary"
FROM employees
ORDER BY 2, 3 desc위 예제는 총 세 개의 컬럼이 있고, 2번째 컬럼은 오름차순(뒤에 따로 desc라고 기술하지 않았기 때문), 3번째 컬럼은 내림차순 하겠다는 의미이다. 즉, 굳이 department_id나 (salary12) + (salary12*nvl(commission_pct,0)) 혹은 "annual_salary" 같은 긴 컬럼 이름을 ORDER BY에 쓰지 않아도 된다는 말이다. 컬럼의 순서를 번호로 부여한다.
