오늘은 함수에 대해서 배웠다. 함수는 여러가지 기능을 하게 만들어주는 프로그램이다. 함수는 중첩이 가능하며 문자함수, 숫자함수, 날짜함수, 형변환함수, 일반함수가 있다. 오늘은 이 중에서 문자, 숫자, 날짜함수에 대한 내용을 배웠다.
문자함수
lower
: 소문자로 변환하는 함수
upper
: 대문자로 변환하는 함수
initcap
: 첫글자는 대문자, 나머지 글자는 소문자로 변환하는 함수
이 3가지는 인수값이 꼭 한 개여야 한다. 예제를 들어보자.
SELECT *
FROM employees
WHERE upper(last_name) = 'KING';last_name 컬럼의 모든 데이터를 대문자로 형변환하고 이것을 'KING'과 비교한다는 의미이다. R과 Python에서도 동일한 함수를 사용하지만, SQL에서는 이런 함수들을 사용하면 편리하긴하나 성능 면에서는 좀 떨어질 수도 있다. 왜냐하면 R, Python은 내 PC에서 돌아가지만 SQL은 DB 서버(우리가 사용하는 SQL의 경우 DB서버가 Oracle)에서 돌아가기 때문에, lower 같이 텍스트 전체를 변환한 뒤 비교하는 방법인 full table scan을 하면 너무 오래 걸리고 성능이 떨어지는 문제가 있기 때문이다. 무엇이 더 좋은 데이터 처리 방식인지 고민하는 것이 필요하다.
concat
: 연결연산자와 동일. 인수값은 반드시 두 개여야 한다.
SELECT
last_name||', '|| first_name,
concat(last_name||', ', first_name),
upper(last_name || first_name || job_id),
lower(concat(concat(last_name, first_name), job_id))
FROM employees;인수값이 반드시 두 개여야하므로 리터럴 문자열이 들어가야할 때는 하나의 인수값 안에서 연결연산자(||)로 이어줘야 한다. 그리고 위와 같이 중복도 가능하다.
length
: 문자의 길이를 리턴하는 함수
lengthb
: 문자의 바이트 값을 리턴하는 함수
SELECT
length('bigdata'), -- 결과는 7
lengthb('bigdata'), -- 결과는 7
length('빅데이터'), -- 결과는 4
lengthb('빅데이터') -- 결과는 3*4=12
FROM dual;
여기서 length는 말그대로 문자의 길이(글자수)이다. 그리고 영문자는 한 글자당 1바이트이지만 한글은 한 글자당 3바이트이기 때문에 3바이트*4글자=총 12바이트 이다.
instr
: 문자의 위치를 리턴하는 함수. 위치이기 때문에 숫자로 나온다.
instr(컬럼, '찾는 문자열', 시작위치(1), n번째로 등장하는 위치(1))
instr 함수. 컬럼과 찾는 문자열 까지는 알겠다. 시작위치는 몇 번째 글자부터 확인하겠냐는 것이고, n번째로 등장하는 위치는 말 그대로 시작위치로부터 n번째에 등장하는 위치를 말한다. 시작위치와 n번째로 등장하는 위치의 디폴트 값은 1,1 이다.
SELECT
last_name,
instr(last_name, 'a', 1, 2)
FROM employees;last_name이라는 컬럼에서 'a' 문자열을 추출하는데 첫번째 글자부터 확인하고 2번째에 등장하는 글자의 위치를 리턴한다.
SELECT last_name,
instr(last_name,'a'),
instr(last_name,'a',1,2)
FROM employees
WHERE instr(last_name, 'a' 1, 2) > 0;WHERE 절에서 instr에 조건을 걸어줄 수도 있다. 예를 들어, last_name에 'a'가 들어있을 수 있지만 한 번만 들어있을 수도 있기 때문에 WHERE 절에서 걸어준 조건을 살펴보면 'a' 문자열이 2번째로 등장하는(원래 글자에서 a가 여러개 있다는 뜻이다.) 글자의 위치, 즉 숫자가 반드시 리턴이 되어야 하고 그 값이 0보다 큰 값들만 추출될 수 있도록했다.(꼭 0일 필요는 없다.) 어쨌든 그렇게 하면 'a' 문자열이 2번째에도 등장하는 데이터들만 추출된다.
substr
: 문자를 추출하는 함수
substr(컬럼(문자열), 시작점, 추출갯수)substr은 시작점만 쓰고 추출갯수는 안 써도 된다.(안 쓰면 문자 끝까지 추출되어 나옴)
substrb
: 문자를 바이트 값만큼 추출하는 함수
substrb('문자열', 시작점, 바이트 값)substrb에서 바이트가 모자라면 더 하위의 바이트 값 만큼 추출된다.
SELECT
last_name,
substr(last_name, 1, 2),
substr(last_name, 2), -- 두번째 글자부터 끝까지 출력
substr(last_name, length(last_name)), -- length는 글자수. 글자수=마지막 글자
substr(last_name, -1, 1), -- -1은 역수. 맨 뒤에서 한 글자를 추출
substr(last_name, -2, 1) -- -2는 맨 뒤에서 두번째 글자를 시작으로 한 글자를 추출
FROM employees;각종 예제를 풀 때, LIKE 연산자를 활용하게 될 경우가 많은데 대용량 데이터를 처리할 땐 LIKE 보다 함수를 이용해 푸는 것이 훨~씬 효과적이다. instr과 substr을 생활화하도록 하자!!!
trim
: 왼쪽, 오른쪽 부분에 연속되는 문자를 제거하는 함수
ltrim
: 왼쪽 부분에 연속되는 문자를 제거하는 함수
rtrim
: 오른쪽 부분에 연속되는 문자를 제거하는 함수
SELECT
trim('a' from 'aaabbcaa'), -- trim 기본 형태
trim(' ' from ' bbc '), -- 공백 제거
trim(' bbc ') -- from 없이도 공백 제거 가능
FROM dual;그냥 말 그대로 연속되는 글자 제거한다고 보면 된다.
replace
: 문자를 다른 문자로 치환하는 함수
replace(컬럼(문자열), 이전 문자, 새로운 문자)
trim은 공백 제거가 가능하지만 내부 공백은 제거하지 못한다는 단점이 있다. 대신 replace 함수를 이용하여 ''(빈 문자열)을 활용하면 내부공백을 제거할 수 있다. 공백 두 개도 한 개로 replace 해서 걸러줄 수도 있다.
lpad
: 문자의 자리를 고정시킨 후 문자값을 오른쪽 기준으로 채우고 빈 왼쪽 공백을 다른 값으로 채우는 함수
rpad
: 문자의 자리를 고정시킨 후 문자값을 왼쪽 기준으로 채우고 빈 오른쪽 공백을 다른 값으로 채우는 함수
lpad, rpad. 이것도 처음에만 어렵지 이해하면 쉽다. lpad, rpad는 세가지만 기억하면 된다.
자릿수 고정 / 왼쪽(or 오른쪽) 기준으로 문자 채우기 / 나머지 자릿수만큼 '*'
SELECT 5000, lpad('*',5000/1000,'*')
-- 5000/1000으로 자릿수를 고정
어차피 1000당 *로 채워야하니까 오른쪽 기준으로 채워지는 문자를 *로 받고 자릿수만큼 *이 채워짐
SELECT 5000, lpad('',5000/1000,'*')
-- lpad는 어떤 값이든 인수를 채워야되니까 빈 문자열을 넣으면 null값이 뜸
SELECT 5000, lpad(' ',5000/1000+1,'*')
-- 인수값이 공백문자이기 때문에 자릿수 하나가 모자라서 +1을 해줌예제에서 5000 대신 컬럼 이름을 넣어주면 된다. lpad, rpad에서 가장 많이 활용되는 분야가 바로 주민등록번호다. 제일 많이 활용되니까 손코딩 문제로 많이 출제될 것 같다. 매우 중요!
SELECT
'210101-1234567' 주민번호_1,
rpad(substr('210101-1234567',1,8), 14, '*') 주민번호_2
FROM dual;결과는 이렇다.

숫자함수
round
: 지정된 소수점 자릿수 값을 반올림하는 함수
SELECT
round(45.926, 2) -- 소수 둘째자리까지 반올림해서 나타내라
round(45.926, 0) -- 소수점을 반올림해서 버린다
round(45.926) -- 소수점을 반올림해서 버린다
round(45.926, -1) -- 10의 자리까지 반올림해서 나타내라
round(45.926, -2) -- 100의 자리까지 반올림. 그런데 45.926은 100이 넘지 않으니까 값이 0으로 나옴
FROM dual;
trunc
: 지정된 소수점 자릿수 값을 버리는 함수. round랑 거의 똑같다.
ceil
: 숫자값을 가장 큰 정수로 반환하는 함수(올림)
floor
: 숫자값을 가장 작은 정수로 반환하는 함수(내림)
round와 ceil, trunc와 floor가 서로 비슷한 개념이라고 보면 된다.
mod
: 어떤 값을 나눈 나머지를 반환하는 함수. 짝수, 홀수 계산할 때 많이 활용된다.
SELECT mod(12, 5) -- 12를 5로 나눈 나머지
FROM dual;power
: 거듭제곱
SELECT power(2, 3) -- 2를 세제곱
FROM dual;abs
: 절대값
SELECT abs(-100) -- 결과는 100
FROM dual;sqrt
: 루트
SELECT sqrt(9) -- 결과는 3
FROM dual;
날짜함수
sysdate
: 현재 서버 날짜를 리턴하는 함수. DATE 타입 형식
systimestamp
: 현재 서버 날짜, 시간(초 이하 9자리(ns)까지), 타임존을 리턴하는 함수
current_date
: 현재 클라이언트의 날짜를 리턴하는 함수. DATE 타입 형식
current_timestamp
: 현재 클라이언트의 날짜, 시간(초 이하 9자리(ns)까지), 타임존을 리턴하는 함수
localtimestamp
: 현재 클라이언트의 날짜, 시간(초 이하 9자리(ns)까지)을 리턴하는 함수. 타임존은 나타내지 않는다.
예를 들면, 내가 한국 기업에 다니는데 싱가폴로 출장을 가게 됐다고 치자. 그럼 서버 시간은 한국 시간이지만 클라이언트 시간은 싱가폴 시간으로 나타난다는 소리. 현업에 나가게 되면 점점 기업들이 글로벌해지기 때문에 이런 서버 시간과 클라이언트 시간을 점검하는 것은 굉장히 중요하다고 한다.
months_between
: 두 날짜간의 달(개월) 수를 리턴하는 함수.
months_between(DATE1, DATE2) -- 인수값은 날짜 타입이면 된다.예를 들어보자.
SELECT
employee_id,
trunc(sysdate - hire_date) "근무일수",
trunc(months_between(sysdate, hire_date)) "근무달수"
trunc(months_between(sysdate, hire_date)/12) "근무연수"
FROM employees; 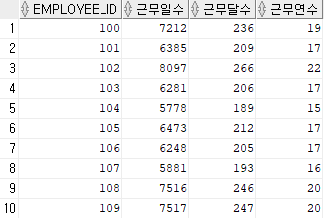
trunc는 소수점을 버리기 위해 붙였다. months_between을 활용하면 내가 여기서 얼마나 일했는지 등의 기간을 알아보기 편하다.
add_months
: 달(개월) 수를 더하거나 빼는 함수
add_months(DATE, 달 수) -- 여기서 숫자는 일 수 아니고 개월 수예를 들어보자.
SELECT
sysdate,
add_months(sysdate, 10), -- 10개월을 더하거나
add_months(sysdate, -10) -- 10개월을 뺌
FROM dual; next_day
: 입력한 날짜를 기준으로 찾고자 하는 요일의 첫번째 날짜를 반환하는 함수
next_day(DATE,'N요일')예를 들어보자.
SELECT next_day(sysdate,'월요일') -- sysdate라는 날짜를 기준으로 그 이후에 돌아오는 월요일(미래시점)
FROM dual;
여기서 요일은 왜 한글로 쓰는가? 왜냐하면 요일은 세션의 언어에 종속되기 때문이다.
last_day
: 기준 날짜 달의 마지막 날짜를 리턴하는 함수
last_day(DATE)
마지막 날짜니까 2월을 제외하고선 30 아니면 31일로 리턴될 것이다. 그리고 저 DATE에 일 수를 추가하여 연산한 다음 마지막 날짜를 알아보는 것도 가능하다.
to_timestamp
: 문자를 날짜형(timestamp)으로 변환하는 함수. 시간 정보를 나타낼 때 유용하다.
to_timestamp(날짜 시간, '날짜모델요소')예를 들어보자.
SELECT
to_timestamp('2023-04-03 10:17:00.123456789','yyyy-mm-dd hh24:mi:ss.ff')
FROM dual;날짜모델요소에서 초 이하 9자리는 ff라고 표현한다.
to_timestamp_tz
: 문자를 날짜형(timestamp with time zone)으로 변환하는 함수.
to_timestamp(날짜 시간 타임존, '날짜모델요소')예를 들어보자.
SELECT
to_timestamp_tz('2023-04-03 10:17:00.123456789 +09:00','yyyy-mm-dd hh24:mi:ss.ff tzh:tzm')
FROM dual;날짜모델요소에서 타임존을 나타내는 형식은 tzh:tzm 이라고 표현한다.
to_yminterval
: 문자를 날짜형(interval year to month)으로 변환하는 함수
to_yminterval('년수-개월수')예를 들어보자.
SELECT
sysdate + to_yminterval('00-11')
FROM dual;현재 날짜에 11개월을 더하라는 뜻이다. 단, 개월수에 들어갈 수 있는 숫자는 0~11까지이다. 12개월은 1년이기 때문에 개월수에 12라고 적는 것보다 년수에 1이라고 적는 것이 더 적합하다.
to_dsinterval
: 문자를 날짜형(interval day to second)으로 변환하는 함수
to_dsinterval('일수 시분초')예를 들어보자.
SELECT
sysdate + to_dsinterval('100 10:00:00') result
FROM dual;
현재 날짜에 100일 하고도 10시간을 더하라는 뜻이다. 일수와 시분초의 구분자는 공백으로 나타낸다. 단, sysdate는 날짜이기 때문에 to_dsinterval으로 시분초를 추가해주어도 시간에 대한 정보가 출력되지않는다.
SELECT
localtimestamp + to_dsinterval('100 10:00:00') result
FROM dual;
시분초에 대한 정보를 추가하려면 sysdate가 아니라 localtimestamp와 같이 시간 정보가 나오는 인수값을 넣어주어야 한다.
extract
: 날짜형을 숫자형으로 추출하는 날짜 함수
extract(추출할요소 from 날짜)
extract(추출할요소 from 시간)예를 들어보자.
SELECT extract(year from sysdate) FROM dual;
-- 현재 날짜의 년도를 출력
SELECT extract(hour from localtimestamp) FROM dual;
-- 현재 클라이언트의 날짜,시간에서 시간을 출력
SELECT extract(timezone_hour from current_timestamp) FROM dual;
-- 현재 클라이언트의 날짜,시간에서 타임존의 시간을 출력
SELECT extract(timezone_region from current_timestamp) FROM dual;
-- 현재 클라이언트의 날짜,시간에서 타임존의 지역을 출력
SELECT extract(timezone_abbr from current_timestamp) FROM dual;
-- 현재 클라이언트의 날짜,시간에서 타임존의 약어를 출력(ex.한국이면 KST)날짜 계산
날짜 + 숫자(일 수) = 날짜
날짜 - 숫자(일 수) = 날짜
날짜 + 시간 = 날짜 시간
날짜 - 시간 = 날짜 시간
날짜 - 날짜 = 숫자(일 수)
날짜 + 날짜 = 오류 -- 절대 안 됨!
날짜 + interval year to month = 날짜
날짜 - interval year to month = 날짜
날짜 + interval day to second = 날짜
날짜 - interval day to second = 날짜날짜에 숫자(일 수) 더하고 빼는건 당연히 날짜로 나올거고, 시간을 더하고 빼는 것 또한 논리에 맞게 날짜 시간으로 떨어진다. 날짜 - 날짜는 디데이 같은 개념으로 생각하면 쉽다.(ex. 현재 날짜 - 퇴사 날짜 = D-nn!!) 날짜 + 날짜는 논리적으로 생각해봐도 말이 안된다.
그리고 날짜에 interval year to month, 즉 년수와 개월수를 더하거나 빼는 것은 날짜로 출력된다. 또한 날짜에 interval day to second, 즉 일수와 시분초를 더하거나 빼는 것은 날짜로 출력된다. 만약 시간의 정보를 나타내는 timestamp 타입의 데이터에 interval day to second를 더하거나 빼면 날짜 시간으로 출력된다.
여기서 숫자는 무조건 일 수를 뜻한다. 만약 분이나 초로 써야한다면 그에 맞게 60을 곱하는 등 연산을 더해주면 된다.
