오늘은 ROLLUP, CUBE, GROUPING SETS라는 그룹함수와 SQL에서 계층검색 하는 법을 배웠다. 그리고 DDL과 DCL의 용법도 배웠다.
그룹연산자
만약, 하나의 테이블에서 컬럼의 갯수가 모두 다른 쿼리문장들을 하나로 합친다고 했을 때 생길 수 있는 문제점은 뭘까? 예를 들어보자.
SELECT department_id, job_id, manager_id, sum(salary) sumsal
FROM employees
GROUP BY department_id, job_id, manager_id
UNION ALL
SELECT department_id, job_id, NULL, sum(salary) sumsal
FROM employees
GROUP BY department_id, job_id
UNION ALL
SELECT department_id, NULL, NULL, sum(salary) sumsal
FROM employees
GROUP BY department_id
UNION ALL
SELECT NULL, NULL, NULL, sum(salary) sumsal
FROM employees;employees라는 테이블에서 각 컬럼을 기준으로 총액 급여를 출력하라는 뜻의 쿼리문인데, group by 하는 컬럼의 기준이 모두 다르기 때문에 중복이 발생하지 않아서 UNION ALL 이라는 합집합 연산자를 써줬다. 이렇게 쿼리문을 작성해도 문제는 없지만 employees라는 테이블을 4번이나 액세스 해야한다는 점에서 부하가 발생한다. 이런 문제점을 해결할 수 있는 그룹연산자로 ROLLUP, CUBE, GROUPING SETS가 있다. 하나씩 살펴보도록 하자.
ROLLUP
: GROUP BY 절에 지정된 열 리스트를 오른쪽에서 왼쪽 방향으로 이동하면서 그룹화를 만드는 연산자이다.(오라클 8i 버전)
1) ROLLUP을 사용하지 않았을 때
SELECT a,b,c,sum(salary)
FROM test
GROUP BY a,b,c;
sum(salary) = {a, b, c}2) ROLLUP을 사용했을 때
SELECT a,b,c,sum(salary)
FROM test
GROUP BY ROLLUP(a,b,c);
sum(salary) = {a, b, c}
sum(salary) = {a, b}
sum(salary) = {a}
sum(salary) = {}대용량 메모리를 포함하는 테이블을 여러 번 액세스 해야하는 문제점을 개선하기 위해 오라클 8i 버전부터는 ROLLUP이라는 기능이 생겼다. ROLLUP은 열 리스트의 오른쪽을 기준으로 왼쪽으로 컬럼을 하나씩 없애면서 군집을 만들어 여러 개의 부분집합을 합한 형태로 출력된다.
위의 예제는 test라는 테이블에서 a, b, c라는 컬럼을 기준으로 GROUP BY 하였고 그 기준에 따른 연봉의 합계를 출력하라는 뜻인데, 여기서 열 리스트의 오른쪽을 기준으로 컬럼을 하나씩 없애면 나올 수 있는 경우의 수는 총 4가지가 나온다. 이렇게 풀면 위에서 UNION ALL로 풀었던 예제를 더욱 손쉽게 풀 수 있다.
CUBE
: ROLLUP 연산자를 포함하고 모든 그룹화(조합 가능한 모든 경우의 수)를 할 수 있도록 만드는 연산자이다.(오라클 9i 버전)
SELECT a,b,c,sum(salary)
FROM test
GROUP BY CUBE(a,b,c);
sum(salary) = {a, b, c}
sum(salary) = {a, b}
sum(salary) = {a, c}
sum(salary) = {b, c}
sum(salary) = {a}
sum(salary) = {b}
sum(salary) = {c}
sum(salary) = {};ROLLUP 연산자는 컬럼을 오른쪽부터 하나씩 없애면서 군집을 만들었지만, 오라클 9i 버전부터는 CUBE라는 연산자가 등장했다. CUBE는 조합할 수 있는 모든 경우의 수를 가지고 출력을 한다.
단, 여기서 {a, b}, {a, c} 라는 부분집합의 일부만 추출하고 싶다면 두 쿼리문을 합집합 연산자로 풀어야 한다.
sum(salary) = {a, b}
sum(salary) = {a, c}
SELECT a,b,NULL,sum(sal)
FROM test
GROUP BY a,b
UNION ALL
SELECT a,NULL,c,sum(sal)
FROM test
GROUP BY a,c;GROUPING SETS
: 내가 원하는 그룹을 만드는 연산자이다.(오라클 9iR2 버전)
SELECT a,b,c,sum(sal)
FROM test
GROUP BY GROUPING SETS((a,b),(a,c),());
sum(salary) = {a, b}
sum(salary) = {a, c}
sum(salary) = {}CUBE 연산자처럼 내가 원하는 부분집합들만 골라서 그룹화할 수 없을까? 해서 나온 것이 바로 GROUPING SETS 연산자이다. 위의 예제는 {a, b}, {a, c} 라는 부분집합의 일부만 추출하고 싶다는 뜻이다.
이러한 그룹 연산자들을 적절히 활용하면 교차표에 행과 열의 합(또는 평균)을 구하는 식의 예제를 쉽게 풀어낼 수 있다. 아래의 교차표는 년도별, 분기별 연봉의 총액을 구하고 행과 열의 합 또한 나타내라는 뜻의 예제이다.
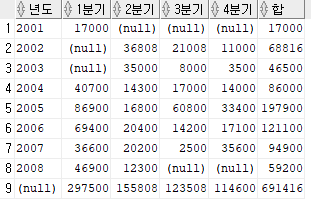
이 교차표는 다음과 같이 풀이할 수 있다.
SELECT *
FROM (SELECT 년도, nvl(분기,0) 분기, 총액
FROM (SELECT to_char(hire_date,'yyyy') 년도, to_char(hire_date,'q') 분기, sum(salary) 총액
FROM employees
GROUP BY CUBE(to_char(hire_date,'yyyy'), to_char(hire_date,'q'))))
PIVOT(sum(총액) FOR 분기 IN ('1' as "1분기",'2' as "2분기",'3' as "3분기",'4' as "4분기", '0' as "합"))
ORDER BY 1;계층검색(Hierarchical query)
: 말 그대로 계층의 구조를 가진 쿼리문을 말한다. 회사의 조직도나 트리 구조가 이런 계층 검색에 해당된다.
계층검색은 키 값이 있어야만 가능하다. 만약, 계층검색에서 SORT를 할 땐 ORDER BY 사용법에 유의하도록 한다. 왜냐하면 ORDER BY만 쓰게 되면 계층으로 정렬한 방식이 망가질 수 있기 때문이다. 계층 구조를 망가뜨리지 않고 ORDER BY로 정렬하고 싶다면, ORDER BY 사이에 SIBLINGS라는 키워드를 꼭 써줘야 한다. 그리고 ORDER SIBLINGS BY는 컬럼의 위치표기법이나 열 별칭 사용이 불가하다. 계층검색의 기본적인 구조는 다음과 같다.
SELECT (level)
FROM
(START WITH) -- 시작점
CONNECT BY (PRIOR) -- 연결고리 조건
(ORDER SIBLINGS BY)여기서 SELECT문의 level은 가상의 컬럼으로서 계층구조에서의 뿌리와 같은 역할을 한다. 그리고 START WITH 절은 시작점을 나타내는 절로, 계층검색을 할 때 필요충분조건은 아니다. 다만, 필요하다면 CONNECT BY 절 이전에 써준다. 계층검색에서 꼭 필요한 절은 바로 CONNECT BY 절이다. 데이터 출력 조건에 따라 PRIOR를 쓸 때도 있고 아닐 때도 있다.
PRIOR를 어느 위치에 써주느냐에 따라 계층검색도 두 가지 방식으로 나뉜다. 예시를 들면서 설명하도록 하겠다.
Top-down
SELECT *
FROM employees
START WITH employee_id = 101
CONNECT BY PRIOR employee_id = manager_id;employees 테이블에서 employee_id가 101번부터 시작하고(START WITH), 그 다음은 전 단계(PRIOR)의 employee_id를 manager_id로 가지고 있는 것을 출력하라는 뜻이다. 출력이 위에서 아래 방향으로 진행되는 것을 top-down 방식이라고 한다. 위의 예제는 다음과 같이 출력된다.
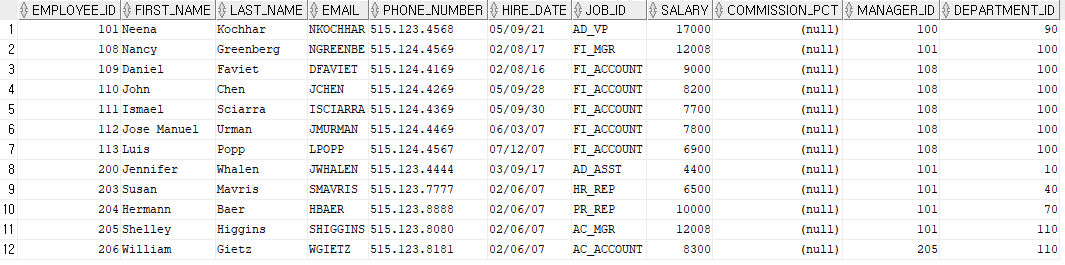
Bottom-up
SELECT *
FROM employees
START WITH employee_id = 101
CONNECT BY employee_id = PRIOR manager_id;employees 테이블에서 employee_id가 101번부터 시작하고(START WITH), 그 다음은 전 단계(PRIOR)의 manager_id를 employee_id로 가지고 있는 것을 출력하라는 뜻이다. 출력이 아래에서 위 방향으로 진행되는 것을 bottom-up 방식이라고 한다. 위의 예제는 다음과 같이 출력된다.
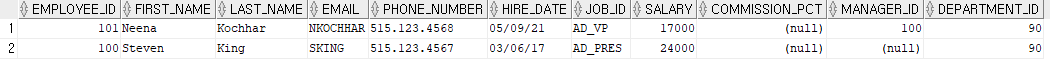
이 예제는 null을 employee_id로 가지고 있는 사원이 없기 때문에 2개의 데이터만 추출하고 검색이 종료되었다.
이런 계층검색에서 들여쓰기를 활용하는 예제를 살펴보자.
SELECT level, lpad(' ',level*2-2,' ')||last_name NAME
FROM employees
START WITH employee_id = 100
CONNECT BY PRIOR employee_id = manager_id;위 예제는 employees 테이블에서 employee_id가 100번부터 시작하고, 그 다음은 전 단계의 employee_id를 manager_id로 가지고 있는 것을 출력하되 level이라는 가상의 컬럼으로 그 뿌리를 나타내고 NAME이라는 컬럼에는 lpad를 이용하여 last_name 컬럼을 트리구조처럼 들여쓰기로 나타내라는 뜻의 쿼리문이다.
예를 들어 2행의 Kochhar을 가지고 lpad를 풀이해보자. Kochhar의 level은 2. lpad의 두번째 인수값으로 2*2-2=2, 즉 자릿수를 2로 고정한다. 그리고 오른쪽 기준으로 채워지는 문자를 ' '로 받고 모자라는 자릿수만큼 ' '이 채워지는 형태이다. 이러한 형식으로 나머지 들여쓰기도 level 값에 따라 다르게 표현된다. 위 예제는 아래와 같은 결과로 출력된다.
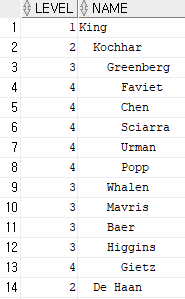
이러한 계층검색은 위의 예제처럼 들여쓰기나 구구단을 출력하는 등 여러가지 문제에 활용될 수 있으니 여러 유형들을 잘 이해하고 숙지하도록 하자.
DQL(Data Query Language)
- SELECT
데이터베이스에 있는 데이터를 조회하는 것이 바로 SELECT문이다. 우리가 그동안 배웠던 SELECT문은 DQL에 해당된다.
DDL(Data Definition Language)
- CREATE
- ALTER
- DROP
- RENAME
- TRUNCATE
- COMMENT
데이터베이스에 데이터를 생성하고, 변경하고, 삭제하고, 이름을 바꾸고, 제거하고, 주석을 다는 행위는 DDL에 해당된다. 이러한 DDL을 하기 전에는 우선 유저관리를 먼저 해줘야 하고 시스템권한도 필요하다. 유저관리와 시스템권한에 대한 내용은 아래에 후술하도록 하겠다.
DCL(Data Control Language)
- GRANT
- REVOKE
특정 데이터베이스 사용자에게 특정 작업에 대한 권한을 부여하거나 회수하는 것은 DCL에 해당된다.
우리는 그동안 무수히 많은 SELECT문, 즉 DQL에 대해 공부하였다. 이제 DDL과 DCL에 대해서도 알아보도록 하자. 우선, DDL과 DCL에 대해 이야기 하기 전에 권한과 롤에 대한 내용을 알아야 할 필요가 있다.
권한(Privilege)
: 특정한 SQL문을 수행할 수 있는 권리를 말한다. 권한에는 시스템권한과 객체권한 두 가지가 있다.
- 시스템권한
: 데이터베이스에 영향을 줄 수 있는 권한 - 객체권한
: 객체(테이블)를 사용할 수 있는 권한
롤(Role)
: 유저에게 부여할 수 있는 권한을 모아 놓은 객체. 관리에 대한 편리성이 있다.
객체 소유자
: 객체를 생성한 사용자. 생성한 객체에 대한 권한의 부여나 회수가 가능하다. 단, sys 계정에서 수행되어야 하는 시스템권한의 부여나 회수는 불가능하다. 우리 SQL Developer에서는 hr 데이터베이스를 가지고 실습하였다. (여기서 객체는 테이블이다. tab_privs라는 약어가 직관적으로 와닿지 않을 때 객체는 테이블이라는 것을 떠올리면 좋다.)
유저관리
SELECT * FROM user_sys_privs; -- 내가 sys로부터 직접 받은 시스템권한을 확인
SELECT * FROM user_tab_privs; -- 내가 직접 받은 객체권한을 확인
SELECT * FROM session_roles; -- 내가 받은 롤에 대한 정보 확인
SELECT * FROM role_sys_privs; -- 내가 받은 롤 안에 시스템권한 확인
SELECT * FROM role_tab_privs; -- 내가 받은 롤 안에 객체권한 확인유저생성
SELECT * FROM user_tables; -- 유저생성
SELECT * FROM user_ts_quotas; -- 사용할 수 있는 테이블스페이스에 대한 정보 확인SELECT * FROM user_ts_quotas. 만약 이 문장의 MAX_BYTES가 -1이라면 사용할 수 있는 용량은 무한(UNLIMITED)이라는 뜻이다.
객체권한 부여
GRANT SELECT ON hr.employees TO insa;
-- insa 유저에게 hr이라는 객체의 employees 테이블을 조회할 수 있는 권한을 부여
SELECT * FROM user_tab_privs;
-- 내가 받은 객체권한과 내가 부여한 객체권한을 같이 확인객체에 권한을 부여하는 것은 GRANT를 이용하면 되지만 그 권한이 제대로 부여되었는지 확인하기 위해서는 아래의 SELECT문을 이용하여 확인해주는 것이 좋다.
객체권한 회수
REVOKE SELECT ON hr.employees FROM insa;
-- insa 유저에게 hr이라는 객체의 employees 테이블을 조회할 수 있는 권한을 회수
SELECT * FROM user_tab_privs;
-- 내가 받은 객체권한과 내가 부여한 객체권한을 같이 확인객체권한 부여와 마찬가지로, 객체에 권한을 회수하는 것은 REVOKE를 이용하면 되지만 그 권한이 제대로 회수되었는지 확인하기 위해서는 아래의 SELECT문을 이용하여 확인해주는 것이 좋다.
SYS 계정
: 데이터베이스 관리자. 데이터베이스 내의 모든 객체에 대해 모든 권한의 부여와 회수가 가능하다. sys 계정에서 수행되어야 하는 시스템권한의 부여나 회수는 물론 객체에 대한 권한의 부여와 회수 또한 가능하다. 우리 SQL Developer에서는 dba 데이터베이스를 가지고 실습하였다.
유저생성
SYS 계정에서 유저를 생성할 때 다음과 같은 형태로 만들 수 있다.
CREATE USER insa -- 유저 이름 insa
IDENTIFIED BY oracle -- 패스워드 oracle
DEFAULT TABLESPACE USERS -- 유저가 사용할 디폴트 테이블스페이스 USERS
TEMPORARY TABLESPACE TEMP -- 유저가 사용할 임시 테이블스페이스 TEMP
QUOTA 10M ON USERS; -- quota는 USERS라는 테이블에서 10M로 사용량을 제한주요 용법
SELECT * FROM dba_users; -- 유저정보를 확인할 때
SELECT * FROM dba_data_files; -- 유저가 사용할 테이블스페이스
SELECT * FROM dba_temp_files; -- 임시 파일의 테이블스페이스시스템권한 부여
GRANT CREATE SESSION TO insa;
-- insa 유저에게 CREATE SESSION이라는 권한을 부여
SELECT * FROM dba_sys_privs WHERE GRANTEE = 'insa';
-- 권한을 부여받는 유저가 insa일 때 dba에서 시스템권한을 조회, 권한을 부여했으므로 조회가 가능시스템권한 회수
REVOKE CREATE SESSION FROM insa;
-- insa 유저에게 CREATE SESSION이라는 권한을 회수
SELECT * FROM dba_sys_privs WHERE GRANTEE = 'insa';
-- 권한을 부여받는 유저가 insa일 때 dba에서 시스템권한을 조회, 권한을 회수했으므로 조회 불가객체권한 부여
GRANT SELECT ON hr.employees TO insa;
-- insa 유저에게 hr이라는 객체의 employees 테이블을 조회할 수 있는 권한을 부여객체권한 회수
REVOKE SELECT ON hr.employees FROM insa;
-- insa 유저에게 hr이라는 객체의 employees 테이블을 조회할 수 있는 권한을 회수유저 정보 수정
ALTER USER insa
--IDENTIFIED BY oracle -- 패스워드 수정
--DEFAULT TABLESPACE users -- 디폴트 테이블스페이스 수정
--TEMPORARY TABLESPACE temp -- 임시 테이블스페이스 수정
--QUOTA UNLIMITED ON users -- 테이블스페이스 사용량을 수정(unlimited 대신 1MB면 1M)
--ACCOUNT LOCK -- 계정 잠금
--ACCOUNT UNLOCK -- 계정 잠금 해지