DDL(CREATE, DROP), DML(INSERT, UPDATE, DELETE), TCL(COMMIT, ROLLBACK, SAVEPOINT), 트랜잭션, CTAS
빅데이터&머신러닝 - SQL
오늘은 어제에 이어 본격적으로 DDL, DML, TCL의 문법을 배웠다.
DDL의 가장 대표적인 구문이 바로 CREATE이다. CREATE는 일반적으로 테이블을 생성할 때 많이 사용하는데, 테이블을 생성하기 전에 해야할 것들이 몇 가지가 있다.
우선 테이블을 생성할 수 있는 권한이 있는지 확인해야 한다.
SELECT * FROM session_privs; 위의 문장을 실행했을 때 예시로서 나올 수 있는 결과는 아래와 같다.
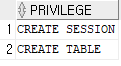
이 유저는 CREATE SESSION과 CREATE TABLE에 대한 권한이 있다는 뜻이다.
그리고 테이블을 저장할 수 있는 테이블스페이스 권한이 있는지 확인해야 한다.
SELECT * FROM user_ts_quotas;위의 문장을 실행했을 때 예시로서 나올 수 있는 결과는 아래와 같다.

테이블을 어느 테이블스페이스에 생성할 지 확인할 수 있다. 이 유저는 users라는 테이블스페이스에 테이블을 저장할 수 있다.
그리고 테이블을 어떻게 명명하는지, 그리고 그 안에 들어가는 컬럼의 이름은 어떻게 나타내는지 알아야한다.
TABLE
명명법
문자로 시작하며 길이는 1 ~ 30자여야한다. 문자, 숫자, 특수문자(_,#,$)가 가능하다.
대소문자는 구분하지 않는다. 예를 들어, 소문자 emp 이름의 테이블이 있는 경우 대문자 EMP 테이블은 생성할 수 없다.
동일한 유저가 소유한 객체의 이름은 중복되면 안된다. 이를 테면, 테이블에 employees라는 테이블이 있는데 뷰에 employees라는 객체이름이 있으면 안된다.
그리고 SELECT, FROM, GRANT, HAVING 등 오라클에서 이미 약속한 단어인 예약어는 사용할 수 없다.
컬럼 타입
- number(p,s) : 가변길이 숫자 타입(p : 전체 자리수, s : 소수점 자리수)
- varchar2(4000) : 가변길이 문자 타입. 영문자 기준 하나의 필드 안에 4000바이트가 맥시멈이다.
- char(2000) : 고정길이 문자 타입 영문자 기준 하나의 필드 안에 2000바이트가 맥시멈이다. 대부분 char보다 varchar2를 많이 사용한다.
- date : 날짜 타입(더 자세한 분류는 아래에 후술)
- clob : 가변길이 문자 타입. 하나의 필드 안에 맥시멈이 4gbyte
- blob : 가변길이 이진 데이터 타입. 하나의 필드 안에 맥시멈이 4gbyte
- bfile : 외부파일에 저장된 이진 데이터 타입. 하나의 필드 안에 맥시멈이 4gbyte
여기서 clob, blob, bfile은 대용량 데이터를 취급할 때 쓴다.
날짜 타입 컬럼
-
date 년월일 : sysdate, current_date
-
timestamp 년월일시분초.9자리 : localtimestamp
-
timestamp with time zone : 년월일시분초.9자리 TIMEZONE시간 : systimestamp, current_timestamp
-
timestamp with local time zone 년월일시분초.9자리 : 보는 지역에 따라 날짜 시간 정보가 자동 정규화하는 날짜 타입
-
interval year to month : 기간을 나타내는 날짜 타입. 년수, 개월수
interval year(3) to month -- year의 기본값은 2자리. 만약 3자리로 바꾸고 싶다면 위와 같이 나타냄 -
interval day to second : 기간을 나타내는 날짜 타입. 일수, 시분초.9자리
interval day(3) to second -- day의 기본값은 2자리. 만약 3자리로 바꾸고 싶다면 위와 같이 나타냄
DDL
: 데이터 정의 언어(Data Definition Language). CREATE, ALTER, DROP, RENAME, TRUNCATE, COMMENT 등이 있다.
CREATE
: 테이블을 생성하는 SQL문
CREATE TABLE emp(
id number(4),
name varchar2(30),
day date default sysdate)
TABLESPACE users;emp라는 테이블을 users라는 테이블스페이스에 생성하고, 그 테이블 안에 id, name, day라는 컬럼이 들어간다는 뜻. id는 전체자리수가 4인 숫자 타입, name은 30바이트까지 가능한 가변길이 문자 타입, day는 날짜 타입을 넣어주는데 테이블에 데이터를 입력할 때 날짜가 들어오지 않으면 null값 대신 default로 sysdate를 넣어준다는 의미이다.
DROP
: 테이블을 삭제하는 SQL문
DROP TABLE emp PURGE;emp라는 테이블을 영구히 삭제한다는 뜻이다. 여기서 PURGE는 영구히 삭제한다는 뜻으로 다시 복원이 되지 않으니 유의한다.
DML
: 데이터 조작 언어(Data Manipulation Language). INSERT, UPDATE, DELETE 등이 있다.
INSERT
: 테이블에 새로운 행을 입력하는 SQL문.
기본적인 구조는 다음과 같다.
INSERT INTO 소유자.테이블(컬럼, 컬럼, 컬럼, ...)
VALUES(데이터, 데이터, 데이터, ...);예를 들어보자.
INSERT INTO insa.emp(id,name,day)
VALUES(1,'홍길동','2006-05-27');insa라는 유저의 emp 테이블에 id가 1, name이 홍길동, day가 2006년 5월 27일인 데이터를 입력하라는 뜻이다. 내가 INSERT한 데이터가 제대로 입력되었는지 확인하기 위해서는 중간중간 수시로 SELECT 문을 이용해서 조회하면 좋다.
SELECT * FROM insa.emp;다음과 같이 출력된다.

INSERT 수행 시 default 값을 입력하는 방법에는 4가지가 있다.
1)
desc emp;
desc를 이용해 테이블의 구조를 먼저 파악한다. 위 테이블에는 컬럼이 총 세 개가 있다. 이 테이블에는 제약조건을 따로 설정하지 않았으므로 null 값이 허용된다.(제약조건에 대한 내용은 배운 다음 후술하도록 하겠다.)
INSERT INTO insa.emp(id,name)
VALUES(3,'김미영');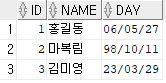
위의 예제처럼 만약 내가 emp라는 테이블에서 id와 name 두 개의 컬럼에 대한 데이터 밖에 모른다면 VALUES에 그에 해당하는 데이터를 써준다. 그리고 위에서 테이블을 생성할 때 day라는 컬럼은 날짜 타입으로 쓰되 default값은 sysdate라고 지정해주었기 때문에, 위 SQL문의 경우 디폴트 값인 sysdate로 필드값이 출력된다.
2)
INSERT INTO insa.emp(id,name,day)
VALUES(4,'이광수',default)
1번처럼 day 컬럼과 그 데이터 값을 비워두고 작성해도 되지만 'desc 테이블명'으로 컬럼 이름에 대한 정보를 파악한 뒤, 컬럼이름을 전부 밝히고 모르는 데이터에 대한 부분만 default라고 써줄 수도 있다. 1번 방식보다 2번 방식이 다른 사람이 보았을 때도 직관적으로 알아보기 쉬우니 이 방법을 쓰도록 하자.
3)
INSERT INTO insa.emp(id,name,day)
VALUES(5,default,default); 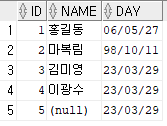
CREATE로 테이블을 생성할 때 name처럼 default 값이 선언되어 있지 않은 경우에는 null 값으로 입력된다.
4)
INSERT INTO insa.emp(id,name,day)
VALUES(6,'제임스',NULL);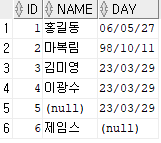
day 컬럼에 default 값이 sysdate로 선언되어 있더라도 default보다 null이 우선순위가 높기 때문에 null을 수행하면 null 값으로 입력된다.
UPDATE
: 특정한 필드값을 수정하는 SQL문
기본적인 구조는 다음과 같다.
UPDATE 소유자.테이블
SET 컬럼 = 새로운값, 컬럼 = 새로운값, ...
WHERE 조건; -- WHERE 절은 옵션예를 들어보자.
UPDATE insa.emp
SET id = 2;insa 유저의 emp 테이블에서 id 값을 전부 2로 수정하라는 뜻이다. SELECT 문으로 조회해보자.
SELECT * FROM insa.emp;다음과 같이 출력된다.
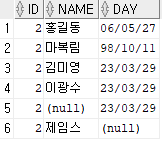
id 값이 전부 2로 변경된 것을 확인할 수 있다.
또 다른 예를 들어보자.
UPDATE insa.emp
SET id = 9, day = to_date('2023-03-29','yyyy-mm-dd')
WHERE id = 6;insa 유저의 emp 테이블에서 id가 6인 데이터를 id는 9로, day는 2023년 3월 29일로 수정하라는 뜻이다. SELECT 문으로 조회해보자.
SELECT * FROM insa.emp;다음과 같이 출력된다.
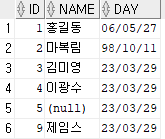
원래 제임스의 id는 2, day는 null이었다. UPDATE를 수행하고 난 뒤 id는 9, day는 2023년 3월 29일로 바뀐 모습을 확인할 수 있다.
DELETE
: 행을 삭제하는 SQL문
기본적인 구조는 다음과 같다.
DELETE FROM 소유자.테이블 WHERE 조건; -- WHERE 절은 옵션WHERE 절이 없으면 테이블의 전체 행을 삭제한다는 뜻이고, WHERE 절이 있으면 그 조건에 해당하는 행만 삭제한다는 뜻이다.
예를 들어보자.
DELETE FROM insa.emp WHERE id = 9insa 유저의 emp 테이블에서 id가 9인 행을 삭제한다는 뜻이다. SELECT 문으로 조회해보자.
SELECT * FROM insa.emp;다음과 같이 출력된다.
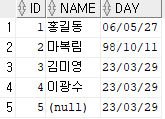
id가 9인 제임스 행이 사라진 것을 확인할 수 있다.
TCL
: 트랜잭션 제어 언어(Transaction Control Language). COMMIT, ROLLBACK, SAVEPOINT 등이 있다.
TCL에 대해서 알려면 우선 트랜잭션이 무엇인지에 대해 알아야 한다.
트랜잭션(Transaction) ★★★
: 논리적으로 DML을 하나로 묶어서 처리하는 작업 단위. DML 작업이 수행되는 순간 트랜잭션이 발생한다. 때문에 DML 수행 후 무조건 트랜잭션을 종료하는 TCL이 사용되어야 한다.
COMMIT
: DML 작업을 영구히 데이터베이스에 저장
예를 들어보자.
INSERT INTO hr.emp(id,name,day) -- transaction 시작
VALUES(1,'구교환','1982-12-14');hr이라는 유저의 emp 테이블에 id가 1, name이 구교환, day가 1982년 12월 14일인 데이터를 입력하라는 뜻이다. SELECT 문으로 조회해보자.
SELECT * FROM hr.emp;다음과 같이 출력된다.

이것을 RUN SQL Command Line에서 똑같이 실행해보자. 우선 conn hr/hr로 hr 계정에 연결을 한 뒤, 위에서 조회한 것처럼 똑같이 SELECT문으로 조회를 해본다면,
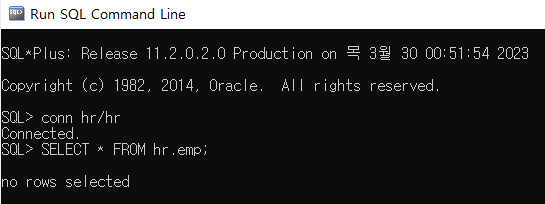 no rows selected 라고 나온다. 즉, 테이블을 조회했을 때 결과값이 하나도 없다는 소리이다. 왜 이렇게 나올까? 정답은 바로 읽기 일관성 때문이다.
no rows selected 라고 나온다. 즉, 테이블을 조회했을 때 결과값이 하나도 없다는 소리이다. 왜 이렇게 나올까? 정답은 바로 읽기 일관성 때문이다.
읽기 일관성이란, DML 작업을 수행하여 어떤 트랜잭션이 완료되기 전까지 데이터를 직접 조작하는 세션 외 다른 세션에서는 데이터 조작 전 상태의 내용이 일관적으로 조회, 출력, 검색되는 특성을 말한다.
우리는 hr 유저에서 INSERT문을 던져서 결과를 출력했지만 Run SQL Command Line에서는 그 결과가 나타나지 않는다. 왜냐하면 INSERT와 같은 DML 작업이 발생하면 반드시 TCL인 COMMIT이나 ROLLBACK을 해주어 완전히 트랜잭션을 종료해주어야 하기 때문이다. DML 수행 후 TCL도 수행해주어야 완벽히 다른 세션에도 결과가 적용되는 것을 볼 수 있다.
INSERT문 수행 후 COMMIT을 수행해보자.
COMMIT; -- transaction 시작 지점까지 영구히 저장, transaction 종료 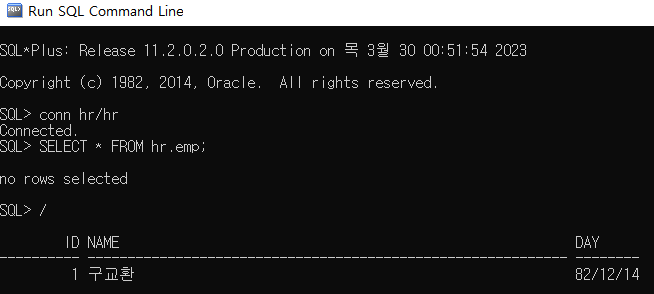 COMMIT을 수행한 뒤 Run SQL Command Line에서 데이터를 조회하면 트랜잭션 시작 시점까지 영구히 저장되어 종료되었기 때문에 결과값이 출력되어 나온다.
COMMIT을 수행한 뒤 Run SQL Command Line에서 데이터를 조회하면 트랜잭션 시작 시점까지 영구히 저장되어 종료되었기 때문에 결과값이 출력되어 나온다.
ROLLBACK
: DML 작업을 영구히 데이터베이스에서 취소
ROLLBACK도 COMMIT과 마찬가지 방식이다. 예를 들어보자.
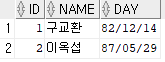
INSERT INTO hr.emp(id,name,day) -- transaction 시작
VALUES(2,'이옥섭','1987-05-29');hr이라는 유저의 emp 테이블에 id가 2, name이 이옥섭, day가 1987년 5월 29일인 데이터를 입력하라는 뜻이다. SELECT 문으로 조회하면 다음과 같이 출력된다.
 여기서 ROLLBACK을 수행해보자.
여기서 ROLLBACK을 수행해보자.
ROLLBACK; -- transaction 시작 지점까지 영구히 취소, transaction 종료 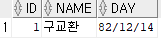 트랜잭션 시작 지점까지의 모든 DML 작업들이 취소되었기 때문에 INSERT문 시작 이전의 결과값으로 출력된다.
트랜잭션 시작 지점까지의 모든 DML 작업들이 취소되었기 때문에 INSERT문 시작 이전의 결과값으로 출력된다.
※ UNDO TABLESPACE의 역할
-
ROLLBACK
ROLLBACK을 하려면 이전의 데이터가 어딘가에는 저장이 되어있어야 한다는 뜻인데, 이 이전 데이터는 과연 어디에 있었던 걸까? 바로 UNDO TABLESPACE이다. UNDO TABLESPACE에는 DML 작업 이전 값이 저장된다.
SELECT * FROM dba_data_files;sys 계정에서 UNDO TABLESPACE를 조회하고 싶을 때 위의 SELECT문을 작성한다.

SELECT문으로 조회했을 때 나오는 UNDOTBS1가 바로 UNDO TABLESPACE이다. 이 테이블스페이스에 ROLLBACK하기 이전의 데이터가 저장된다.
-
읽기 일관성
읽기 일관성은 앞에서 언급했듯이 DML 작업을 수행하여 어떤 트랜잭션이 완료되기 전까지 데이터를 직접 조작하는 세션 외 다른 세션에서는 데이터 조작 전 상태의 내용이 일관적으로 조회, 출력, 검색되는 특성을 말한다. UNDO TABLESPACE는 아직 트랜잭션이 종료되지 않아서 오래 실행되는 쿼리의 읽기 일관성을 보장하기 위해 쓰인다.
읽기 일관성에 대한 예시를 들며 이해해보자.
INSERT INTO hr.emp(id,name,day) VALUES(1,'홍길동',to_date('2023-3-28','yyyy-mm-dd')); SELECT * FROM hr.emp;위 SQL문을 수행하면 우리 눈에는 저장된 것처럼 보이지만

실제로 Run SQL Command Line에서 실행해보면 결과가 출력되지 않는다.
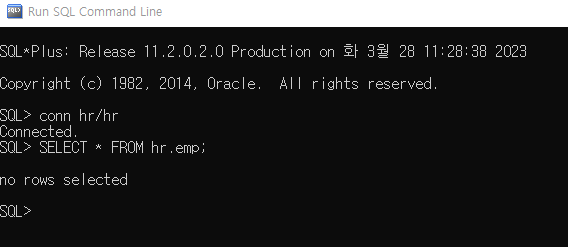
다른 세션에서도 동일한 결과를 출력하고자 한다면 DML을 통해 트랜잭션이 발생한 것을 TCL을 통해 영구히 저장(or 취소)할 필요가 있다.
INSERT INTO hr.emp(id,name,day) VALUES(1,'홍길동',to_date('2023-3-28','yyyy-mm-dd')); SELECT * FROM hr.emp; COMMIT;

SQL문에 이어서 COMMIT이라는 TCL 작업을 수행하였다. 실제로 Run SQL Command Line에서 실행해보면 우리가 INSERT한 데이터가 나타나는 것을 알 수 있다. 즉, INSERT를 통해 트랜잭션이 발생한 것을 COMMIT을 통해 영구히 저장해야 다른 세션에서도 결과가 출력된다.
SAVEPOINT
: DML 작업 시에 ROLLBACK 을 도와주는 표시자. 표시자는 고유한 이름으로 달아야 한다.
SAVEPOINT 표시자;
ROLLBACK TO 표시자; -- 표시자 밑에 있는 DML 전부 취소예를 들어보자. 아래와 같은 테이블이 있다고 하자.

INSERT INTO hr.emp_20(employee_id, last_name)
VALUES(400, '유재석');
SAVEPOINT A;hr 유저의 emp라는 테이블에 employee_id는 400, last_name은 유재석인 데이터를 추가하였고 그 시점까지 A라는 표시자로 SAVEPOINT를 만들었다. 아래에 추가로 내용을 업데이트 해보자.
UPDATE hr.emp_20
SET last_name = '나얼'
WHERE employee_id = 201;
SAVEPOINT B;
DELETE FROM hr.emp_20 WHERE employee_id = 300;
SELECT * FROM hr.emp_20;hr 유저의 emp라는 테이블에 employee_id는 201, last_name은 나얼인 데이터를 추가하였고 그 시점까지 B라는 표시자로 SAVEPOINT를 만들었다. 그리고 employee_id가 300인 데이터를 삭제한 뒤 SELECT문으로 테이블을 조회하였다. 결과는 다음과 같이 나타난다.
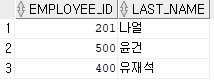
여기서 SAVEPOINT를 이용한 ROLLBACK을 하면 어떻게 될까?
ROLLBACK TO B;SAVEPOINT B 밑에 있는 DML은 전부 취소, 즉 SAVEPOINT B 밑에 있는 DELETE 문 이하는 전부 취소하라는 뜻이다. 결과는 다음과 같이 나타난다.

SAVEPOINT B 이하 DELETE문의 내용은 hr 유저의 emp_20 테이블에서 employee_id가 300인 데이터를 삭제하라는 뜻이었다. 그런데 ROLLBACK TO B를 하면 B 시점까지의 결과로 돌아가라는 뜻이므로 삭제했던 데이터가 다시 나타난다. ROLLBACK TO A는 어떨까?
ROLLBACK TO A;
SAVEPOINT A 밑에 있는 DML은 전부 취소, 즉 SAVEPOINT A 밑에 있는 UPDATE 문 이하는 전부 취소하라는 뜻이다. A 시점 이하에서는 employee_id가 201번인 사원의 last_name을 나얼로 바꾸고(UPDATE), hr 유저의 emp_20 테이블에서 employee_id가 300인 데이터를 삭제(DELETE)하라고 했다. 그런데 ROLLBACK TO A를 하면 A 시점까지의 결과로 돌아가라는 뜻이므로 나얼로 변경했던 이름도 원래 이름인 Hartstein으로 돌아갔고, 삭제했던 500번 사원에 대한 데이터도 다시 나타난다.
자동 COMMIT과 자동 ROLLBACK
DML 작업을 하고 나면 반드시 트랜잭션을 종료하는 것을 습관화 해야한다. 왜냐하면 어떤 경우에는 자동 COMMIT이나 자동 ROLLBACK이 발생할 수 있기 때문이다.
자동 COMMIT이 발생할 때,
-
DDL, DCL이 DML과 함께 사용될 때
: DDL(CREATE, ALTER, DROP, RENAME, TRUNCATE, COMMENT)은 내부적으로 INSERT, UPDATE 같은 트랜잭션이 발생하고, 트랜잭션이 발생하면 반드시 TCL(COMMIT)이 수행되기 때문에 안된다. DCL(GRANT, REVOKE)도 마찬가지.
-
sqlplus(Run SQL Command Line)에서 exit(정상적인 종료)를 수행해서 종료할 때
-
sqlplus에서 conn를 수행할 때
자동 ROLLBACK이 발생할 때,
- 창닫기 같이 sqlplus가 비정상적으로 종료될 때
- DML 작업을 수행하고 있는 컴퓨터가 비정상적으로 종료될 때
- CLIENT - SERVER 환경에서 NETWORK가 장애가 발생할 때
CTAS
: 테이블을 복제하는 하나의 구문. 테이블의 구조와 행(데이터), 그리고 제약조건 중에서는 NOT NULL 제약조건만 복제된다.
CREATE TABLE 소유자.테이블
AS
SELECT문;SELECT문으로 서브쿼리 문장을 먼저 만들고 제대로 출력이 되면 그 SELECT문을 소유자.테이블이라는 이름의 CREATE TABLE로 복제한다.
예를 들어보자.
CREATE TABLE hr.emp
AS
SELECT employee_id as id, lower(last_name||' '||first_name) as name, salary*12 as sal, department_id as dept_id
FROM hr.employees;hr 유저의 employees라는 테이블에서 id, name, sal, dept_id 데이터를 추출하는데 이 데이터는 hr 유저의 emp라는 테이블로 복제한다는 뜻이다. 이때 lower(last_name||' '||first_name) 같이 긴 표현식은 별칭을 써줘야 한다.
만약 hr 유저의 employees라는 테이블의 뼈대(구조)만 복제하고 싶을 땐 어떻게 해야할까?
CREATE TABLE hr.emp
AS
SELECT *
FROM hr.employees
WHERE 1 = 2;hr 유저의 employees 테이블에서 전체 데이터를 추출하는데 이 데이터는 hr 유저의 emp라는 테이블로 복제한다는 뜻이다. 그런데 테이블의 뼈대만 복제하고 싶을 땐 WHERE 절을 아무 조건이나 FALSE로 만들면 된다. (1과 2는 같지 않기 때문에 WHERE 절은 FALSE가 된다.)
DML의 서브쿼리
간단한 로직으로 DML을 활용하면 좋겠지만, 일반적으로 데이터를 변형하고 조작할 땐 여러 조건이 걸리는 경우가 많다. 그럴 때 상호관련 서브쿼리처럼 DML에도 서브쿼리가 활용되는 경우가 매우 빈번하기 때문에 여러 예제를 통해 살펴보도록 하자.
INSERT SUBQUERY
: INSERT 구문에 SUBQUERY가 결합된 형태이다. '데이터를 이행한다', '데이터를 로드한다' 라고도 표현된다. 기본적인 형태는 다음과 같다.
INSERT INTO 소유자.테이블
(서브쿼리)서브쿼리 자리에는 간단한 SELECT문이 올 수도 있고 INLINE VIEW를 활용하여 상호관련 서브쿼리를 공부했던 것처럼 여러 조건이 결합된 형태로도 나타날 수 있다.
만약 분석해야 하는 데이터를 다른 테이블에서 끌고와야 할 때 테이블이 만들어져 있지 않으면 CTAS로 복제하고, 테이블이 만들어져 있으면 INSERT SUBQUERY를 사용한다.
예를 들어보자.
INSERT INTO hr.emp(emp_id,name,sal,dept_id)
SELECT employee_id, last_name, salary, department_id
FROM hr.employees
WHERE department_id = 30;hr 유저의 employees라는 테이블에서 department_id가 30인 데이터의 employee_id, last_name, salary, department_id를 hr 유저의 emp 테이블로 끌고 와서 insert 하라는 뜻이다. 우리가 이전에 hr.emp라는 테이블을 만들어준 적이 있기 때문에 이미 만들어져 있는 테이블에 서브쿼리를 인서트 하는 식으로 INSERT SUBQUERY를 만들수 있고, 여기서 SELECT 절은 서브쿼리에 해당된다.
UPDATE SUBQUERY ★★★
: UPDATE 구문에 SUBQUERY가 결합된 형태이다. 기본적인 형태는 다음과 같다.
UPDATE 소유자.테이블
SET (서브쿼리)예제를 풀면서 UPDATE SUBQUERY를 이해해보자.
hr.emp 테이블의 dept_name 컬럼의 값을 hr.departments 테이블의 department_name의 값을 이용해서 수정해야 한다면 어떻게 SQL문을 작성하면 될까?
UPDATE hr.emp e
SET dept_name = (SELECT department_name
FROM hr.departments
WHERE department_id = e.dept_id)현장에서 UPDATE SUBQUERY를 많이 사용하기 때문에 잘 알아두도록 하자.
DELETE SUBQUERY
: DELETE 구문에 SUBQUERY가 결합된 형태이다. 기본적인 형태는 다음과 같다.
DELETE FROM 소유자.테이블
(서브쿼리)
예제를 풀면서 DELETE SUBQUERY를 이해해보자.
DELETE FROM hr.emp
WHERE id IN (SELECT employee_id
FROM hr.employees
WHERE hire_date < to_date('2003-01-01','yyyy-mm-dd'));hr 유저의 emp라는 테이블에서 hr 유저의 employees라는 테이블의 hire_date가 2003년 이전인 사원의 employee_id가 있으면 그 데이터를 삭제하라는 뜻이다. 그런데 IN 연산자를 사용하는 것은 전체 데이터를 스캔해야 하기 때문에 성능 면에서 효율이 떨어진다. 따라서 EXISTS 연산자를 활용하는 것이 좀 더 좋다. EXISTS를 이용한 DELETE SUBQUERY로 풀어보자.
DELETE FROM hr.emp e
WHERE EXISTS (SELECT 'X'
FROM hr.employees
WHERE hire_date < to_date('2003-01-01','yyyy-mm-dd')
AND employee_id = e.id);
※ PASSWORD 만료
웹사이트를 이용하다 보면 비밀번호를 변경한지 6개월이 지났기 때문에 비밀번호를 변경하라는 식의 팝업창이 뜰 때가 있다. SQL Developer를 이용해서 비밀번호 변경에 관한 로직이 어떤 식으로 흘러가는지 간단하게 살펴볼 수 있다.
우선, SQL Developer 세션에서
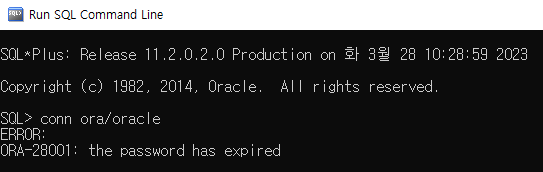
ALTER USER ora PASSWORD EXPIRE;를 실행한다. ora 유저의 비밀번호를 만료시키라는 뜻이다. Run SQL Command Line에서 conn ora/oracle을 입력하여 ora 유저로 접속하면 위의 SQL문이 수행되었기 때문에 비밀번호가 만료되었다고 나온다.
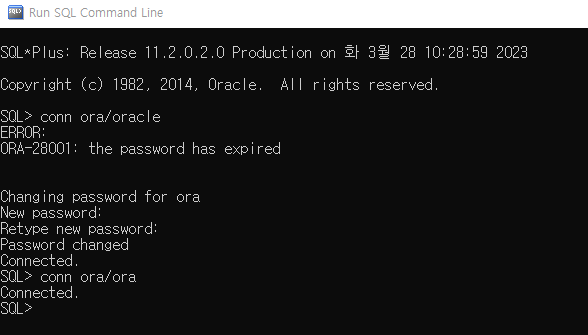
패스워드를 변경하고자 하면 새로운 패스워드를 입력(New password), 다시 입력(Retype new password)하면 비밀번호가 변경된다. 나는 패스워드를 ora라고 변경하였으므로 다시 sql에 연결하고자 했을 때는 conn ora/ora(유저이름: ora/패스워드: ora)라고 입력해야 연결이 된다.
※ ROW LEVEL LOCK
내가 작업하고 있는 행을 다른 세션에서 작업하려면 아직 트랜잭션이 종료되지 않았기 때문에 Lock이 걸린다. 즉, 같은 ROW에 대해서 DML 작업을 동시에 할 수 없게 만들어 놓은 것을 row level lock이라고 한다.(a.k.a. 이미 선택된 좌석입니다...) 내가 작업하고 있는 세션에서 트랜잭션이 종료되면 그 때 lock이 풀리게 된다.
