오늘은 EXISTS와 NOT EXISTS 연산자, 그리고 PIVOT과 UNPIVOT을 배웠다.
EXISTS 연산자 ★★★★★
: 상호관련 서브쿼리에서 사용하는 연산자로, 후보행 값이 "서브쿼리에 존재하는지 여부'를 찾는 연산자이다. 후보행 값이 서브쿼리에 존재하면 TRUE, 우리가 찾는 데이터가 나오면 검색을 종료하고 결과값을 별도의 메모리에 저장한다. 후보행 값이 서브쿼리에 존재하지 않으면 FALSE, 우리가 찾는 데이터가 아니다. EXISTS 연산자는 다음과 같이 사용한다.
SELECT *
FROM employees e
WHERE EXISTS (SELECT 'X'
FROM employees
WHERE manager_id = e.employee_id);위 쿼리문에서 'X'는 문자열도 되고 숫자도 된다. 그냥 문법 오류를 해결하기 위해 넣어주는 값이다.
예제를 풀어보자. 소속사원이 있는 부서정보를 출력하라는 뜻이다.
SELECT *
FROM departments d
WHERE EXISTS (SELECT 'x'
FROM employees
WHERE department_id = d.department_id);
EXISTS 문제를 풀 때 가장 먼저 생각해보아야 할 것은?
문제에서 추출해 달라고 한 정보를 보고 대략적인 메인쿼리의 구조를 정한다. 그리고 조건에 맞는 서브쿼리를 짠다. 메인쿼리 테이블만 한번 출력해본다. 거기서 첫번째 행을 후보행으로 잡고 후보행 값을(예제에선 department_id=10) 미지수 자리에 넣어본다. 서브쿼리 결과값이 후보행 값과 비교했을 때 참이면 결과를 별도에 메모리에 저장하고 쿼리문은 전체 데이터와 비교할 때 까지 그 과정을 계속 반복할 것이다.
NOT EXISTS 연산자
: 상호관련 서브쿼리에 사용하는 연산자로, 후보행 값이 서브쿼리에 존재하지 "않는" 데이터를 찾는 연산자이다. 후보행 값이 서브쿼리에 존재하지 않으면 TRUE, 우리가 찾는 데이터를 별도의 메모리에 저장한다. 후보행 값이 서브쿼리에 존재하면 FALSE, 우리가 찾는 데이터가 아니다.
NOT EXISTS는 NOT IN과 비슷해보이지만 가장 크게 차별화되는 장점이 있다. 예를 들면,
SELECT *
FROM employees
WHERE employee_id NOT IN (SELECT manager_id
FROM employees
WHERE manager_id IS NOT NULL);employees 테이블에서 관리자 id가 null이 아닌 관리자 id를 추출하는데 이 결과가 employees 테이블의 사원번호와 같지 않은, 즉 관리자가 아닌 사원들의 정보를 추출하라는 뜻이다. 예제처럼 NOT IN을 사용할 때, 여러행 서브쿼리에 NULL 값이 있으면 WHERE에 IS NOT NULL을 사용하여 NULL을 없애주어야 했다.
SELECT *
FROM employees
WHERE NOT EXISTS (SELECT 'x'
FROM employees
WHERE manager_id = e.employee_id);그런데 NOT EXISTS를 사용하면 NOT EXISTS 연산자 자체가 값이 FALSE일 때 버리는 로직을 하고 있기 때문에 굳이 IS NOT NULL을 쓰지 않아도 된다.
PIVOT
: 행(세로) 데이터를 열(가로)로 변경하는 함수이다. 기본적인 형태는 다음과 같다.
SELECT *
FROM (GROUP BY가 포함된 INLINE VIEW)
PIVOT(그룹함수 FOR 인라인뷰컬럼 IN (~~~~))여기서 INLINE VIEW로 들어갈 테이블은 행과 열의 방향을 변경하고자 하는 테이블이다. 그룹함수는 sum이나 max 같이 값에 영향을 주지 않는 함수들을 사용할 수 있다. 그리고 INLINE VIEW에서는 GROUP BY가 되어있어야 sum, max 등의 그룹함수를 사용할 수 있다. 단, PIVOT 안에서 갯수를 세거나 한다면 INLINE VIEW에서 GROUP BY를 빼야 한다. 그리고 PIVOT 함수를 쓸 때 들어가는 명칭들은 간결해야하므로 INLINE VIEW에서 꼭 별칭을 붙여주도록 한다. 예를 들어보자.
SELECT *
FROM (SELECT department_id, sum(salary) sumsal
FROM employees
GROUP BY department_id)
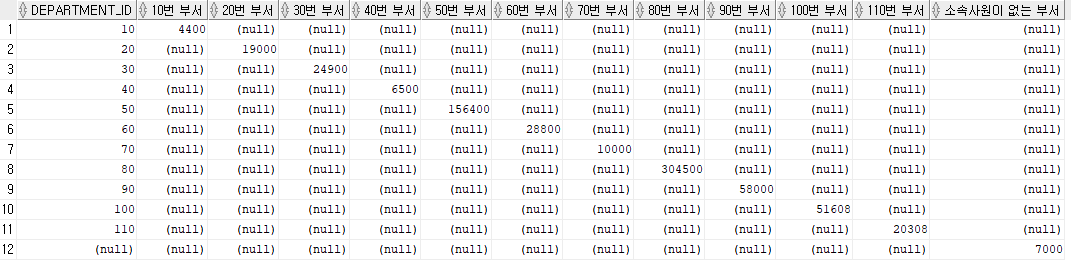
PIVOT(sum(sumsal) FOR department_id IN (10 as "10번 부서", 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, NULL as "소속사원이 없는 부서"));PIVOT 안의 sum(sumsal)은 INLINE VIEW에서 별칭해준 sumsal에다 값에 영향을 주지 않는 그룹함수인 sum을 붙인 것이다. 위의 결과는 다음과 같이 출력된다.

만약 IN 연산자 괄호 안에 들어가는 데이터 타입이 문자열이라면, 수행결과의 컬럼에 작은 따옴표가 함께 붙어나온다. 이럴 때에는 IN 연산자 괄호 안에 '문자열' as "문자열" 의 형태로 형변환을 시켜주는 것이 좋다. IN 연산자 괄호 안에서는 특수문자 사용에 유의하도록 한다.
※ 만약 PIVOT을 이용하지 않고 풀었을 때,
SELECT
department_id,
DECODE(department_id,10,salary) "10번 부서",
DECODE(department_id,20,salary) "20번 부서",
DECODE(department_id,30,salary) "30번 부서",
DECODE(department_id,40,salary) "40번 부서",
DECODE(department_id,50,salary) "50번 부서",
DECODE(department_id,60,salary) "60번 부서",
DECODE(department_id,70,salary) "70번 부서",
DECODE(department_id,80,salary) "80번 부서",
DECODE(department_id,90,salary) "90번 부서",
DECODE(department_id,100,salary) "100번 부서",
DECODE(department_id,110,salary) "110번 부서",
DECODE(department_id,NULL,salary) "소속사원이 없는 부서"
FROM employees;DECODE라는 함수를 이용하여 데이터를 열 방향으로 나열해줄 수는 있다. 그런데 이렇게 출력을 해보면 전체 사원에 대한 데이터가 전부 나열이 되기 때문에 이것을 함축적으로 표현할 필요가 있다. 즉 그룹함수를 만들고 GROUP BY를 이용해 그룹핑을 해주면 좀 더 간단하게 표현된다.
SELECT
department_id,
sum(DECODE(department_id,10,salary)) "10번 부서",
sum(DECODE(department_id,20,salary)) "20번 부서",
sum(DECODE(department_id,30,salary)) "30번 부서",
sum(DECODE(department_id,40,salary)) "40번 부서",
sum(DECODE(department_id,50,salary)) "50번 부서",
sum(DECODE(department_id,60,salary)) "60번 부서",
sum(DECODE(department_id,70,salary)) "70번 부서",
sum(DECODE(department_id,80,salary)) "80번 부서",
sum(DECODE(department_id,90,salary)) "90번 부서",
sum(DECODE(department_id,100,salary)) "100번 부서",
sum(DECODE(department_id,110,salary)) "110번 부서",
sum(DECODE(department_id,NULL,salary)) "소속사원이 없는 부서"
FROM employees
GROUP BY department_id
ORDER BY 1;위의 쿼리문은 다음과 같이 나타난다.
PIVOT을 사용하지 않고 DECODE나 그룹함수만 가지고도 행과 열의 방향을 바꿔줄 수는 있다. 하지만 너무 길고 복잡하기 때문에 PIVOT을 사용하는 것이 더 효과적인 방법이다.
UNPIVOT
: 열(가로) 데이터를 행(세로)으로 변경하는 함수이다. 기본적인 형태는 다음과 같다.
SELECT *
FROM (INLINE VIEW)
UNPIVOT(컬럼 FOR 컬럼 IN (~~~~)) -- 여기서 컬럼은 새로 생성하는 열을 말한다.예를 들어보자. 원래 아래와 같이 표현되는 테이블이 있다고 하자.

이 테이블에서 행과 열의 방향을 서로 바꿔주고 싶다면 UNPIVOT을 활용해야 한다. 대신 열을 새로 생성하기 때문에 컬럼 이름을 UNPIVOT 안에 넣어주어야 한다.
SELECT *
FROM (SELECT *
FROM (SELECT to_char(hire_date,'day') 요일
FROM employees)
PIVOT(count(*) FOR 요일 IN ('월요일' as "월",'화요일' as "화",'수요일' as "수",'목요일' as "목",'금요일' as "금",'토요일' as "토",'일요일' as "일")))
UNPIVOT(인원수 FOR 요일 IN (월,화,수,목,금,토,일))위 쿼리문의 결과는 다음과 같다.

UNPIVOT은 INCLUDE NULLS라는 옵션이 있다. 말 그대로 UNPIVOT에서 제외된 NULL 값을 포함해서 데이터를 출력하라는 뜻이다. INCLUDE NULLS를 사용하는 형태는 다음과 같다.
SELECT *
FROM (INLINE VIEW)
UNPIVOT INCLUDE NULLS(컬럼 FOR 컬럼 IN (~~~~))이렇게 PIVOT을 활용하면 행과 열에 각각 컬럼 이름을 지정해서 추이를 파악할 수 있는 교차표를 만들 수도 있다. 예를 들어보자.
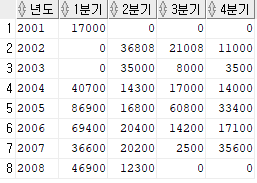
다음과 같은 교차표를 만들고 싶다면 어떻게 쿼리문을 짜야할까?
SELECT *
FROM (SELECT to_char(hire_date,'yyyy') 년도, to_char(hire_date,'q') 분기, sum(salary) 총액
FROM employees
GROUP BY to_char(hire_date,'yyyy'), to_char(hire_date,'q'))
PIVOT(max(총액) FOR 분기 IN ('1' as "1분기", '2' as "2분기", '3' as "3분기", '4' as "4분기"))
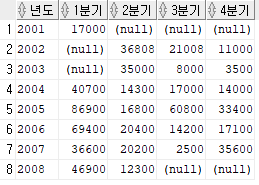
ORDER BY 1; 여기서 년도는 PIVOT 절에 쓰지 않고 INLINE VIEW에 기술한다. 년도를 첫번째 열이되고, 이것이 바로 기준이 되는 셈이다. 즉, 교차표는 기준이 되는 INLINE VIEW를 만들고 그 테이블에다가 행과 열의 방향을 바꾸고자 하는 테이블을 PIVOT하는 형식으로 붙이면 된다.
위 쿼리문의 결과에서 null 값을 다른 값으로 대체할 순 없을까? 우리는 null 값을 실제값으로 변환하는 함수인 nvl 함수를 배웠기 때문에 이것을 여기에 적용할 수 있다! 만약, null값을 0으로 변환한다면 SELECT문에 내가 입력하고 싶은 컬럼의 이름을 적어주되 nvl 함수가 적용된 형식으로 적어야 한다.
SELECT 년도, nvl("1분기",0) as "1분기", nvl("2분기",0) as "2분기", nvl("3분기",0) as "3분기", nvl("4분기",0) as "4분기"
FROM (SELECT to_char(hire_date,'yyyy') 년도, to_char(hire_date,'q') 분기, sum(salary) 총액
FROM employees
GROUP BY to_char(hire_date,'yyyy'), to_char(hire_date,'q'))
PIVOT(max(총액) FOR 분기 IN ('1' as "1분기", '2' as "2분기", '3' as "3분기", '4' as "4분기"))
ORDER BY 1;여기서 년도는 제일 왼 편에 위치하는 기준이 되기 때문에 SELECT문에는 그냥 년도라고 기술하고, 나머지 분기별로 컬럼을 나열해주면 된다.