오늘은 다중열 서브쿼리와 스칼라 서브쿼리, 그리고 집합연산자를 배웠다.
다중열 서브쿼리
: 컬럼이 여러 개인 서브쿼리. 기본적으로 지금까지 배웠던 서브쿼리들은 단일한 열(컬럼)에 대한 서브쿼리였다. 그런데 다중열 서브쿼리는 비교해야 하는 컬럼이 여러 개일 때를 말한다. 다중열 서브쿼리에는 쌍 비교와 비쌍 비교가 있다.
쌍 비교
SELECT *
FROM employees
WHERE (manager_id, department_id) IN (SELECT manager_id, department_id
FROM employees
WHERE first_name = 'John');말 그대로 여러 개의 컬럼을 쌍으로 묶어서 비교하는 것이다. 즉, 기준 컬럼들은 괄호로 묶고 그에 대응되는 컬럼들은 기준 컬럼과 갯수가 동일해야 한다. 대신 대응되는 컬럼들의 이름은 같지 않아도 된다.
비쌍 비교
SELECT *
FROM employees
WHERE manager_id IN (SELECT manager_id
FROM employees
WHERE first_name = 'John')
AND department_id IN (SELECT department_id
FROM employees
WHERE first_name = 'John');비(非)쌍 비교. 쌍 비교와 다르게 기준 컬럼들을 여러 개의 단일 열로 만들어서 AND로 연결하는 방식이다. 단, AND로 연결되어 있다고 해서 두 조건을 모두 만족하는 쌍 비교처럼 생각하면 안된다. 기준 컬럼과 대응되는 컬럼의 데이터가 일치하는 경우를 비쌍 비교로 풀었을 때는 쌍 비교했을 때의 값과 동일하게 나오겠지만, 대부분의 경우 쌍 비교와 비쌍 비교의 데이터 건 수는 다르게 나온다. 비쌍 비교를 쉽게 이해하자면 아래의 그림과 같다.
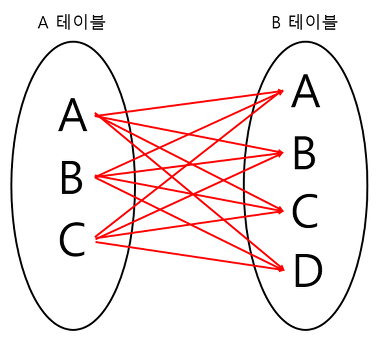
A 테이블의 A(또는 B,C)라는 컬럼이 B 테이블의 모든 값(여러 행 서브쿼리의 결과값)과 대응되는지 일일히 확인한다고 보면 된다.
스칼라 서브쿼리(Scalar subquery)
: 한 행에서 정확히 하나의 열 값만 반환하는 서브쿼리. 동일한 입력값이 들어오면 수행 횟수를 최소화 할 수 있는 로직을 구현한다. 스칼라 서브쿼리의 가장 큰 장점은 query execution cache 기능이 수행된다는 것이다. 키 값이 없는 데이터가 입력되면 null값으로 리턴하는데, 결과는 outer join과 같이 나타난다. 예를 들어보자.
SELECT employee_id, department_id, (SELECT department_name
FROM departments
WHERE department_id = e.department_id)
--------------------------------------
FROM employees e query execution cache
ORDER BY 2;employees 테이블에서 employee_id, department_id, department_name을 출력한다는 뜻이다. 미지수인 e.department_id에 입력값을 대입했을 때 그 값이 departments 테이블에 있으면 그 결과를 캐시의 형태로 저장하고 동일한 입력값이 들어오면 캐시에 저장된 결과로 출력되어서 I/O를 최소화한다.
미지수에는 중복성이 있는 값이 들어와야 성능 면에서 더 좋다.(만약 중복이 없으면 계속 캐시를 돌리면서 데이터를 뽑아내는 작업을 해야함)
SELECT문의 활용
그동안 배웠던 문법들을 살펴보면 SELECT문이 굉장히 다양한 절에 쓰이는 것을 알 수 있다. 하나씩 차근차근 살펴보도록 하자.
SELECT 스칼라 서브쿼리
FROM 인라인 뷰
WHERE 서브쿼리
GROUP BY X
HAVING 서브쿼리
ORDER BY 스칼라 서브쿼리SELECT 절에도 SELECT 문으로 서브쿼리를 넣을 수 있다. 그런데 SELECT 절에서는 단일값으로 나타내야 하기 때문에 하나의 컬럼 값만을 반환하는 스칼라 서브쿼리를 이용해 주어야 한다.
FROM 절에서는 SELECT문이 인라인 뷰라는 가상의 테이블로 만들어진다.
그리고 조건을 제한하는 WHERE 절과 그룹함수의 조건을 제한하는 HAVING 절 역시 SELECT문이 서브쿼리로 들어갈 수 있다.
ORDER BY 절에서도 스칼라 서브쿼리가 활용된다. SELECT 절에 컬럼의 정보를 출력하지 않으면서 SELECT 절에 나타나지 않은 다른 컬럼을 기준으로 정렬을 한다고 해보자. 만약 JOIN을 쓰지 않고 이 과정을 수행하려면, ORDER BY 절에 그 다른 컬럼에 대한 조건을 걸어주는 스칼라 서브쿼리를 넣어주면 된다. 예를 들어보자.
SELECT e.employee_id, e.last_name
FROM employees e
ORDER BY (SELECT department_name
FROM departments
WHERE department_id = e.department_id); employee_id와 last_name을 부서 이름을 기준으로 정렬한다고 했을 때, 부서 이름 컬럼은 employees 테이블에 없으므로 보통은 테이블끼리 JOIN을 해서 정렬을 해준다. 그런데 ORDER BY 절에 departments 테이블에 대한 스칼라 서브쿼리를 넣어서 정렬을 하면 JOIN을 하지 않아도 다른 테이블의 컬럼으로 정렬이 가능하다.
단, GROUP BY 절은 군집을 만드는 형태이기 때문에 다른 절과 달리 서브쿼리를 넣을 수 없다.
집합연산자
: 두 개 이상의 테이블에서 JOIN을 사용하지 않고 연관된 데이터를 조회할 수 있는 연산자. 집합연산자에는 UNION, UNION ALL, INTERSECT, MINUS가 있다.
집합연산자를 사용할 땐, 각 테이블의 SELECT 절의 컬럼의 갯수가 일치해야 한다. 그리고 첫번째 SELECT 절의 컬럼의 대응되는 두번째 SELECT 절의 컬럼은 데이터 타입이 일치해야 한다. 만약 대응되는 컬럼이 없다면 NULL 등으로 대체할 수 있다. UNION, INTERSECT, MINUS 연산자는 중복을 제거하지만 정렬(SORT)이 발생하기 때문에 주의해야한다. 그리고 집합연산자에서 ORDER BY 절은 제일 마지막에 기술해야하고, 첫번째 SELECT 절의 컬럼 이름, 별칭, 위치표기법을 사용할 수 있다.
합집합
UNION
: 합집합 연산자. 중복을 제거한다.
SELECT employee_id, job_id, to_char(salary)
FROM employees
UNION
SELECT employee_id, job_id, '무급'
FROM job_history
ORDER BY 3;employees 테이블에서 employee_id와 job_id, 그리고 salary(연봉)을 문자열로 변환한 데이터와 job_history 테이블에서 employee_id와 job_id를 합쳤을 때의 데이터를 출력하라는 뜻이다. 이 때, job_history 테이블에는 salary에 대한 컬럼이 없기 때문에, 컬럼의 갯수를 대응시키기 위해 '무급'이라는 가상의 컬럼을 만들어주었다. 단, 첫번째 SELECT문에서 salary를 문자열로 변환했기 때문에 '무급'이라는 컬럼도 문자열 데이터 타입이어야 한다. 그리고 ORDER BY 절에서는 컬럼 이름이나 열 별칭도 사용 가능하지만 예제처럼 위치표기법으로 나타내는 것이 좀 더 직관적이고 편하다.
UNION ALL
: 합집합 연산자. 중복을 포함한다.
SELECT employee_id, job_id, to_char(salary)
FROM employees
UNION ALL
SELECT employee_id, job_id, '무급'
FROM job_history
ORDER BY 3;UNION ALL은 중복을 포함하는 연산자이지만 첫번째 쿼리문장과 두번째 쿼리문장의 데이터 갯수가 완전히 일치하기 때문에 그냥 UNION 한 것과 데이터 갯수가 동일하게 나온다. UNION ALL은 중복을 포함하는 합집합 연산자이기 때문에 중복성이 없는 데이터를 합칠 땐 UNION ALL을 활용하는 것이 UNION보다 나을 수 있다.
교집합
INTERSECT
: 교집합 연산자.
SELECT employee_id
FROM employees
INTERSECT
SELECT employee_id
FROM job_history;employees 테이블에서의 employee_id 데이터와 job_history 테이블에서의 employee_id 데이터가 동일한 데이터만 출력하라는 뜻이다. job_history 테이블에 사원번호가 있다는 것은 한 번이라도 job을 변경한 이력이 있다는 것이고, 이것은 즉 두 쿼리문장의 교집합은 job을 변경한 이력이 있는 사원의 번호를 출력하라는 것이다. 또 다른 예시를 들어보자.
SELECT employee_id, job_id
FROM employees
INTERSECT
SELECT employee_id, job_id
FROM job_history;employees 테이블에서의 employee_id, job_id 데이터와 job_history 테이블에서의 employee_id, job_id 데이터가 동일한 데이터만 출력하라는 뜻이다. 현재 employees 테이블과 이전 job id 이력이 남은 job history 테이블의 교집합이라고 하면 현재 그 사원의 정보와 이전 이력이 동일하다는 뜻이다. 이를 테면, A 부서로 입사를 해서 다른 부서로 변경했다가 현재 다시 A부서로 돌아왔다는 것이다.
차집합
MINUS
: 차집합 연산자.
SELECT employee_id
FROM employees
MINUS
SELECT employee_id
FROM job_history;employees 테이블의 employee_id 데이터에서 job_history 테이블의 employee_id 데이터를 뺐을 때의 데이터를 출력하라는 뜻이다. 현재 employees 테이블에서 부서 변경 이력이 있는 사원번호를 뺀다는 뜻으로 즉, 한번도 job_id를 바꾸지 않은 사원 정보를 출력하라는 것이다. 또 다른 예시를 들어보자.
SELECT employee_id, job_id
FROM job_history
MINUS
SELECT employee_id, job_id
FROM employees;우리는 중학교 수학 시간에 집합을 배우면서, A-B라는 차집합이 있으면 그 결과는 A에서 A와 B의 교집합을 빼는 것이라는 것이라는걸 배웠다. SQL에서의 차집합 연산자도 이와 동일한 원리가 적용된다. 두 쿼리문장의 차집합은 테이블의 순서만 변경되었을 뿐, 위의 교집합 예시와 동일하다.
위 쿼리문은 job_history 테이블에서의 employee_id, job_id 데이터에서 employees 테이블에서의 employee_id, job_id 데이터를 뺐을 때의 데이터를 출력하라는 뜻으로, 두 쿼리문장의 교집합은 부서를 변경했다가 다시 원래 부서로 돌아온 사원들에 대한 데이터이다. 따라서 job_history 테이블에서 원래 부서로 돌아온 사원들을 뺀 나머지가 결과값으로 출력된다.
집합연산자와 EXISTS의 활용
어떤 쿼리문을 출력할 때는 집합연산자를 사용할 수도 있지만 그보다 EXISTS를 활용하는 것이 훨씬 효율적이다. 왜냐하면 UNION, INTERSECT, MINUS 연산자는 중복을 제거하지만 정렬(SORT)이 발생하기 때문에 주의해야한다.
결론부터 말하자면 INTERSECT 대신 EXISTS, MINUS 대신 NOT EXISTS 쓰는 것이 성능 면에서 좋다. 예를 들어보자.
SELECT *
FROM employees
WHERE employee_id IN (SELECT employee_id
FROM job_history); job_id를 한 번이라도 바꿨던 적이 있는 사원들의 정보를 출력하라는 뜻이다. 이 쿼리문을 INTERSECT를 이용해서 풀 수도 있다.
SELECT *
FROM employees
WHERE employee_id IN (SELECT employee_id
FROM employees
INTERSECT
SELECT employee_id
FROM job_history);위의 쿼리문장처럼 간단하게 표현할 수 있지만 굳이 예시를 들기 위해 INTERSECT를 사용해보았다. 위의 쿼리문을 EXISTS로 표현해보자.
SELECT *
FROM employees e
WHERE EXISTS (SELECT 'X'
FROM job_history
WHERE employee_id = e.employee_id);employees 테이블의 employee_id와 동일한 employee_id가 job_history 테이블에 존재하는지 확인한다는 뜻으로 위의 쿼리문들과 똑같은 뜻을 가지고 있다. 이렇듯 굳이 INTERSECT라는 교집합 연산자를 사용하지 않아도 EXISTS를 이용하면 훨씬 효율적으로 쿼리문을 작성할 수 있다. 그럼 반대로 job_id를 한번도 바꾼 적이 없는 사원들의 정보를 출력한다면 어떻게 해야할까?
SELECT *
FROM employees
WHERE employee_id NOT IN (SELECT employee_id
FROM job_history);위의 쿼리문을 INTERSECT를 이용해서 풀 수도 있다.
SELECT *
FROM employees
WHERE employee_id NOT IN (SELECT employee_id
FROM employees
INTERSECT
SELECT employee_id
FROM job_history);
위의 쿼리문을 MINUS를 이용해서 풀 수도 있다.
SELECT *
FROM employees
WHERE employee_id IN (SELECT employee_id
FROM employees
MINUS
SELECT employee_id
FROM job_history);위의 쿼리문을 NOT EXISTS로 표현해보면 어떨까?
SELECT *
FROM employees e
WHERE NOT EXISTS (SELECT 'X'
FROM job_history
WHERE employee_id = e.employee_id); employees 테이블의 employee_id와 동일한 employee_id가 job_history 테이블에 존재하지 않는지 확인한다는 뜻으로 위의 쿼리문들과 똑같은 뜻을 가지고 있다. 이렇듯 굳이 MINUS라는 차집합 연산자를 사용하지 않아도 NOT EXISTS를 이용하면 훨씬 효율적으로 쿼리문을 작성할 수 있다.
