🌟 목표
이디야가 스타벅스 근처에 매장을 만든다는 소문이 있다.
웹크롤링을 통해 매장위치정보를 불러오고 가설을 검증해보자.
1. 서울시 스타벅스 데이터 가져오기
📌 미션
서울시의 스타벅스 매장 이름과 주소, 구 이름을 pandas data frame으로 정리
- 스타벅스 map 페이지에 selenium으로 접근한다.
from selenium import webdriver
url = "https://www.starbucks.co.kr/store/store_map.do"
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get(url)- 페이지 내 지역검색을 클릭 (css selector를 복사한 후 find_element로 가져오기)
from selenium.webdriver.common.by import By
driver.find_element(By.CSS_SELECTOR,"#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search > h3 > a").click()- 서울클릭 후 전체 클릭
driver.find_element(By.CSS_SELECTOR,"#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a").click()
driver.find_element(By.CSS_SELECTOR,"#mCSB_2_container > ul > li:nth-child(1) > a").click()- 서울 전체 [스타벅스 매장명, 주소, 위도, 경도]정보가 담긴 페이지 코드 가져온 후 매장 정보만 raw에 담기
페이지 내 위도 경보 정보가 있어서 google maps로 가져오지 않아도 된다. 😊
from bs4 import BeautifulSoup
soup = BeautifulSoup(driver.page_source,"html.parser")
# 전체매장 정보
raw = soup.select("#mCSB_3_container > .quickSearchResultBoxSidoGugun > .quickResultLstCon")- 매장명, 주소, 위도, 경도 각각 리스트에 담기
store_list = []
address_list = []
lat_list = []
long_list = []
from tqdm import tqdm_notebook
for i in tqdm_notebook(raw) :
store = i.get("data-name")
lat = i.get("data-lat")
long = i.get("data-long")
address = i.find(class_ = "result_details").contents[0]
store_list.append(store)
lat_list.append(lat)
long_list.append(long)
address_list.append(address)- pandas로 DataFrame화 시키기
gu_list = [gu.split()[1] for gu in address_list]
import pandas as pd
starbucks = pd.DataFrame(
{"매장명" : store_list,
"주소" : address_list,
"위도" : lat_list,
"경도" : long_list,
"구" : gu_list }
)결과

2. 서울시 이디야 커피 정보 가져오기
- 이디야 store 사이트 접근
from selenium import webdriver
url = "https://ediya.com/contents/find_store.html"
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get(url)- 주소란 클릭
이디야 페이지의 경우 주소에 각 구이름을 입력한 뒤 페이지코드를 가져와야함.
driver.find_element(By.CSS_SELECTOR,"#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a").click()
- 스타벅스 구 리스트 중 유니크 값만 뽑아서 for문으로 주소란에 입력해준 뒤 주소와 매장명 데이터를 리스트에 담아주기
for문으로 입력 중 팝업창이 뜨는 이슈가 있어 try ~ except 구문으로 오류가 뜰 시 검색창을 지워주는 clear()를 사용하였다.
gu_name = starbucks["구"].unique()
store = []
address = []
from tqdm import tqdm_notebook
import time
for data in tqdm_notebook(gu_name) :
try:
driver.find_element(By.CSS_SELECTOR,"#keyword").send_keys(data)
driver.find_element(By.CSS_SELECTOR,"#keyword_div > form > button").click()
time.sleep(1)
soup = BeautifulSoup(driver.page_source,"html.parser")
data = soup.select("#placesList > li")
time.sleep(1)
for i in data :
temp = i.text.split("점 ")
if temp[0] + "점" != "" and temp[1] != "" :
store.append(temp[0] + "점")
address.append(temp[1])
driver.find_element(By.CSS_SELECTOR,"#keyword").clear()
except:
driver.find_element(By.CSS_SELECTOR,"#keyword").clear()
pass- 스타벅스와 마찬가지로 주소에서 구 이름만 빼서 리스트에 담아준 뒤 Data Frame처리
gu_name = [i.split()[1] for i in address ]
ediya = pd.DataFrame({
"매장명" : store,
"주소" : address,
"구 이름" : gu_name
})- 이디야 위도 경도는 googlemaps를 이용해 가져온다.
import googlemaps
gmaps_key = "개인코드"
gmaps = googlemaps.Client(key = gmaps_key)
lat_list = []
lng_list = []
for i in tqdm_notebook(ediya["주소"]) :
if len(gmaps.geocode(i, language="ko")) != 0 :
lat = gmaps.geocode(i, language="ko")[0].get("geometry")["location"]["lat"]
lng = gmaps.geocode(i, language="ko")[0].get("geometry")["location"]["lng"]
else :
lat = ""
lng = ""
lat_list.append(lat)
lng_list.append(lng)- Data Frame에 위도 경도 추가
ediya["위도"] = lat_list
ediya["경도"] = lng_list결과

3. 데이터시각화 및 분석
- 한글 깨짐 세팅
from matplotlib import font_manager as fm
from matplotlib import pyplot as plt
#한글폰트 깨짐 해결
get_ipython().run_line_magic("matplotlib", "inline")
plt.rc('font', family = "Malgun Gothic")
#마이너스부호 깨짐 해결
import matplotlib as mpl
mpl.rcParams['axes.unicode_minus'] = FalseA. folium 지도확인
import folium
my_map = folium.Map(
location = [37.5337307,126.9638275],
zoom_start = 11
)
for idx, row in starbucks.iterrows() :
folium.Marker(
location = [row.위도, row.경도],
icon = folium.Icon(
icon = "star",
color = "darkgreen"
)
).add_to(my_map)
for idx, row in ediya.iterrows() :
try :
folium.Marker(
location = [row.위도, row.경도],
icon = folium.Icon(
icon = "coffee",
color = "blue",
prefix = "fa"
)
).add_to(my_map)
except :
pass
my_map
🌟 인사이트
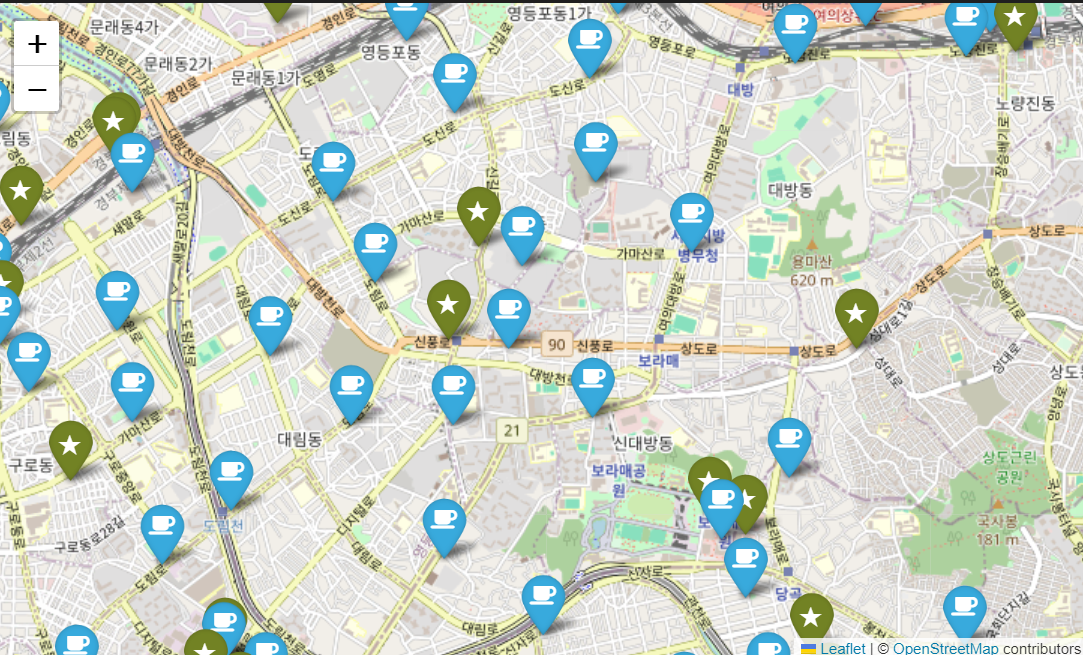
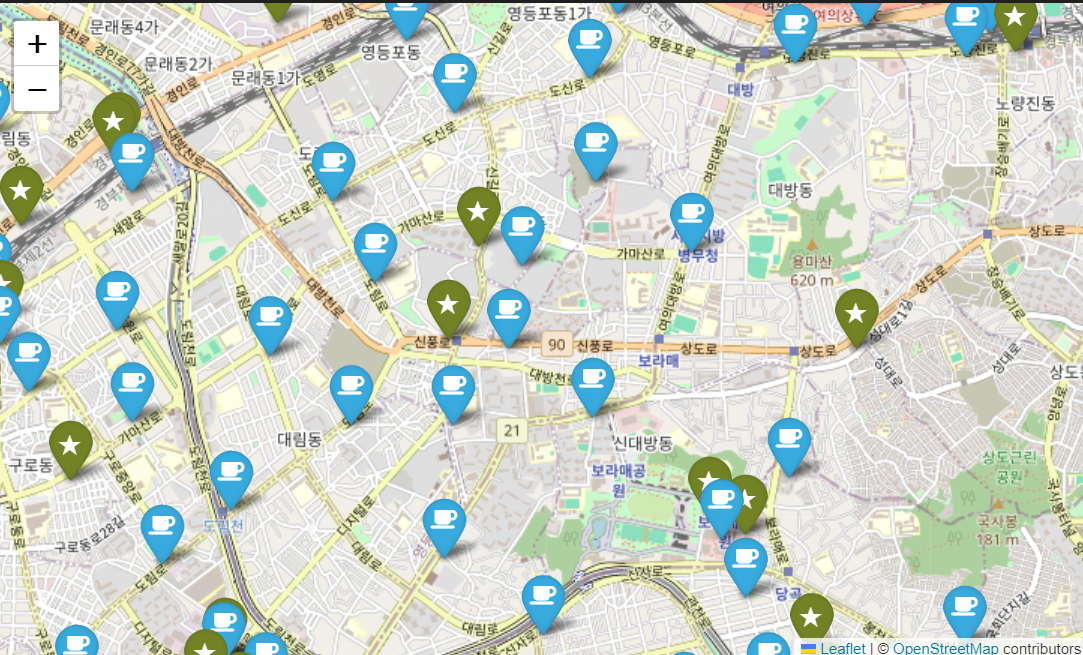
단순 위도 경도를 마커로 찍어서 확대하여 보았을 때,
이디야 매장만 밀집한 공간(대림동 부근 | 하단사진참고)도 보이므로
무조건 이디야 매장이 스타벅스 근처에 위치한다고 볼 수 없다.
다만 지역하나하나 확대하여 정성적 기준으로 판단하였으므로 정확한 답이라고 보기 어렵다
-> pivot : 구별로 정리하여 수 비교해보자
B. pivot table + matplotlib
- 스타벅스 구별 매장 수 pivot
star = starbucks.pivot_table(
index = "구",
aggfunc= "count",
values = "매장명"
)- 이디야 구별 매장 수 pivot
ediya.rename(columns = {"구 이름":"구"}, inplace=True)
edi = ediya.pivot_table(
index = "구",
aggfunc="count",
values = "매장명"
)- 두 브랜드 pivot table merge로 join
result = pd.merge(star, edi, how="inner",on = "구")
result.rename(columns = {
"매장명_x" : "스타벅스 매장 수",
"매장명_y" : "이디야 매장 수"
}, inplace = True)- plot으로 시각화
result.plot(
figsize = (10,10), kind = "barh", grid = True, title = "구별 매장 수"
)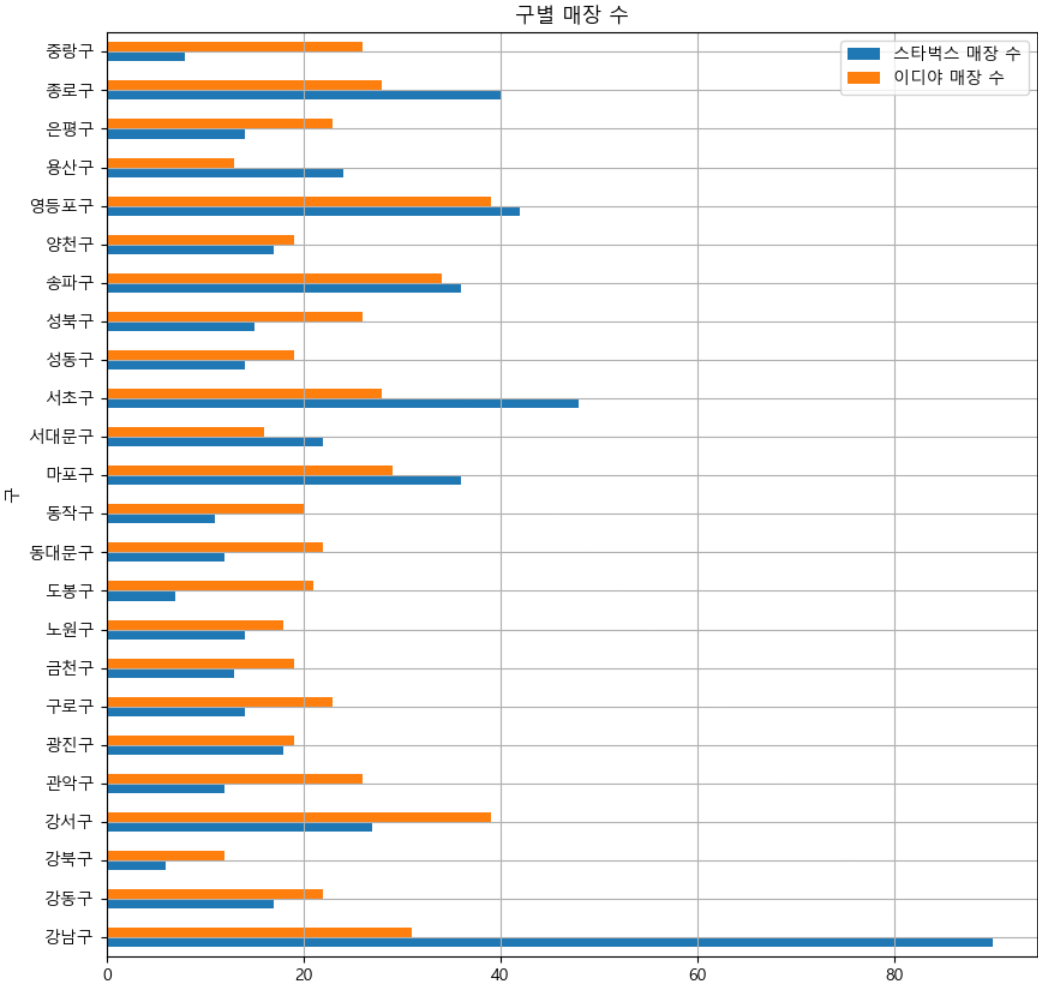
🌟 인사이트
- 서울 스타벅스 매장의 수 : 610
- 서울 이디야 매장의 수 : 571
두 브랜드 매장 수의 차이가 크지 않기 때문에,
이디야 매장이 스타벅스 근처에 있다면,
구별 그래프의 차이가 비슷해야한다.
(다른 구에 비해 강남구의 스타벅스 매장 수 그래프가 크다면 이디야 매장의 그래프도 다른 구에 비해 강남구가 높아야함)
하지만 스타벅스는 강남구가 많고 중랑구가 적은데 반해
이디야는 중랑구가 높으므로
이디야 매장이 스타벅스 근처에 있다고 볼 수 없다.
C. folium circle
- 컬럼명 정리
star.rename(columns = {"매장명":"매장수"},inplace = True)
star.head()
edi.rename(columns = {"매장명":"매장수"},inplace = True)
edi.head()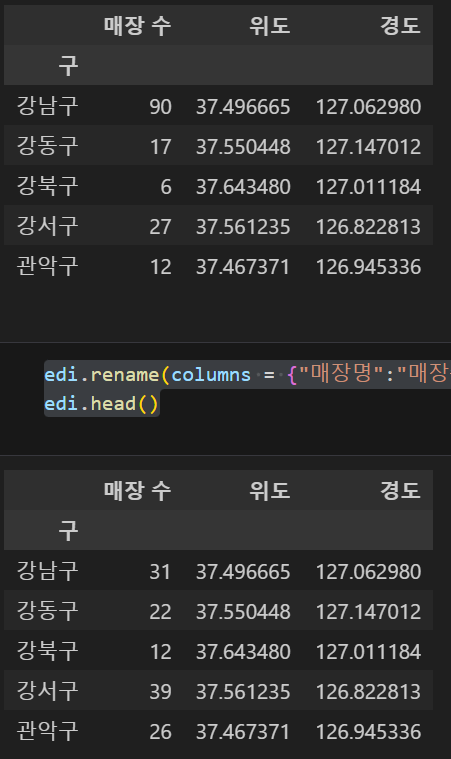
- 스타벅스 frame에 구별 주소 google map으로 추가
lat_list = []
lng_list = []
for idx, row in star.iterrows() :
tmp = gmaps.geocode(idx,language="ko")[0]["geometry"]["location"]
lat = tmp.get("lat")
lng = tmp.get("lng")
lat_list.append(lat)
lng_list.append(lng)
star["위도"] = lat_list
star["경도"] = lng_list- 이디야 frame에 구별 주소 google map으로 추가
lat_list = []
lng_list = []
for idx, row in edi.iterrows() :
tmp = gmaps.geocode(idx,language="ko")[0]["geometry"]["location"]
lat = tmp.get("lat")
lng = tmp.get("lng")
lat_list.append(lat)
lng_list.append(lng)
edi["위도"] = lat_list
edi["경도"] = lng_list- 지도시각화
my_map = folium.Map(
location = [37.5337307,126.9638275],
zoom_start = 11
)
for idx, row in star.iterrows() :
folium.Circle(
location = [row.위도, row.경도],
radius = row["매장 수"]*50,
color = "green",
fill_color = "darkgreen"
).add_to(my_map)
for idx, row in edi.iterrows() :
folium.Circle(
location = [row.위도, row.경도],
radius = row["매장 수"]*50,
color = "red",
fill_color = "darkred"
).add_to(my_map)
my_map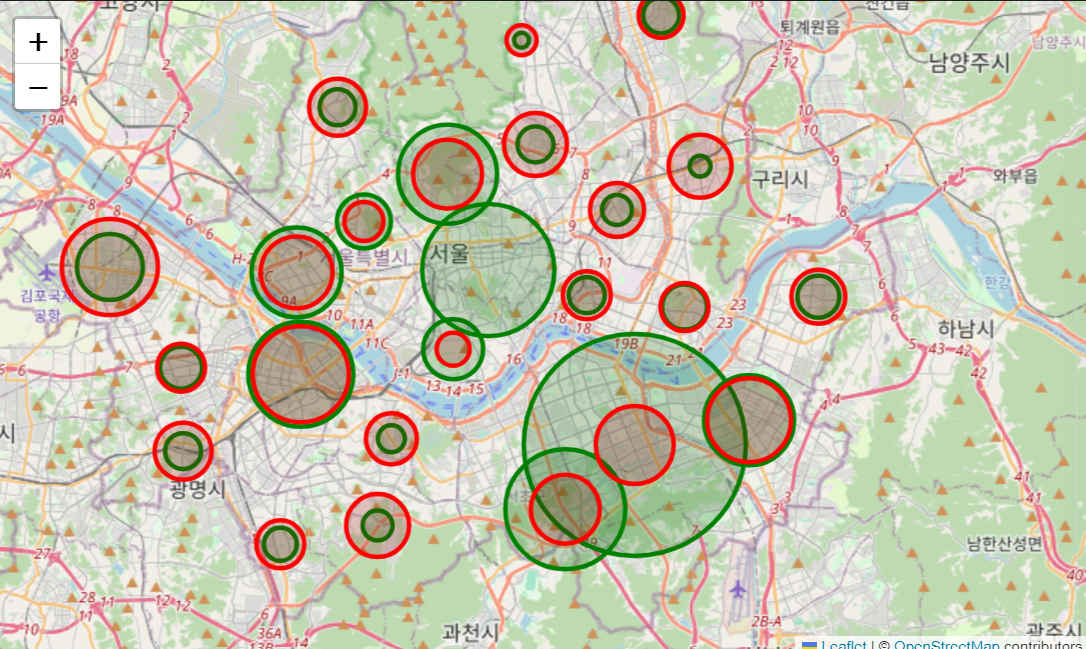
🌟 인사이트
구별 매장 수를 지도에 circle로 시각화 하였을 때,
B의 인사이트와 마찬가지로 스타벅스가 많은 구와 이디야가 많은 구가 다르다.
4. 결론
스타벅스 근처에 이디야 매장이 있다는 가설은 거짓이다.
오히려 유동인구가 많고 (정성적 기준으로) 회사가 많은 강남, 여의도 등 부근에는 스타벅스가
외곽의 1인가구 밀집지역(이것 또한 정성적 판단)에 이디야가 많은 것을 알 수 있다.
📌 전체코드
- 100점 맞았다 야호

Zero Base 데이터분석 스쿨
Daily Study Note

Study Log
잘 보고갑니다 ㅎㅎ