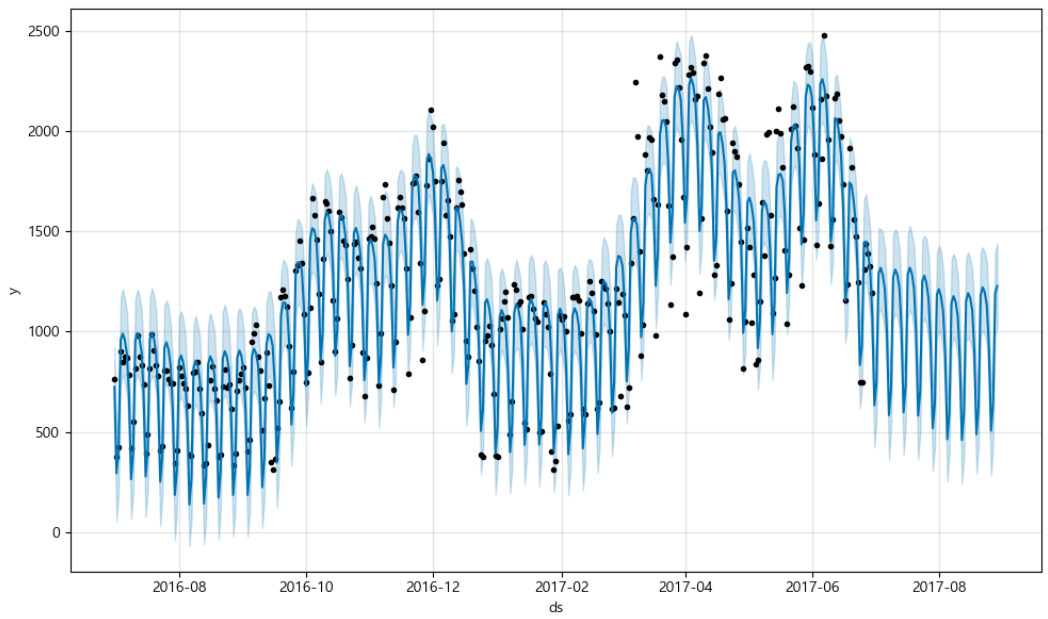
forecast(시계열 분석)
시간의 흐름에 대해 특정 패턴과 같은 정보를 가지고 있는 경우를 시계열 데이터라고 함.
설치
- 윈도우의 경우 Visual C++ Build Tool을 먼저 설치
- conda install pandas-datareader
- conda install -c conda-forge fbprophet
로 하면 아래와 같은 error가 뜬다 😅
TypeError: This is a python-holidays entity loader class. For entity inheritance purposes please import a class you want to derive from directly: e.g., `from holidays.countries import Entity` or `from holidays.financial import Entity`.해당 벨로그 확인해보니 fp-prophet -> Prophet 개명됨을 확인
(정리해주신 선배기수 감사합니다 사람살리셨어요 !)
- conda install -c conda-forge prophet
- pip install plotly
까지 추가로 설치완료 !
- from pandas_datareader import data
- from prophet import Prophet
함수(def) 기초
📌 (''' 내용 ''') or """ 내용 """ : Docstring
쌍따옴표 혹은 홑따옴표를 문장 앞 뒤에 사용하여 주석을 달아주면, 독스트링을 통해 내용확인이 가능하다
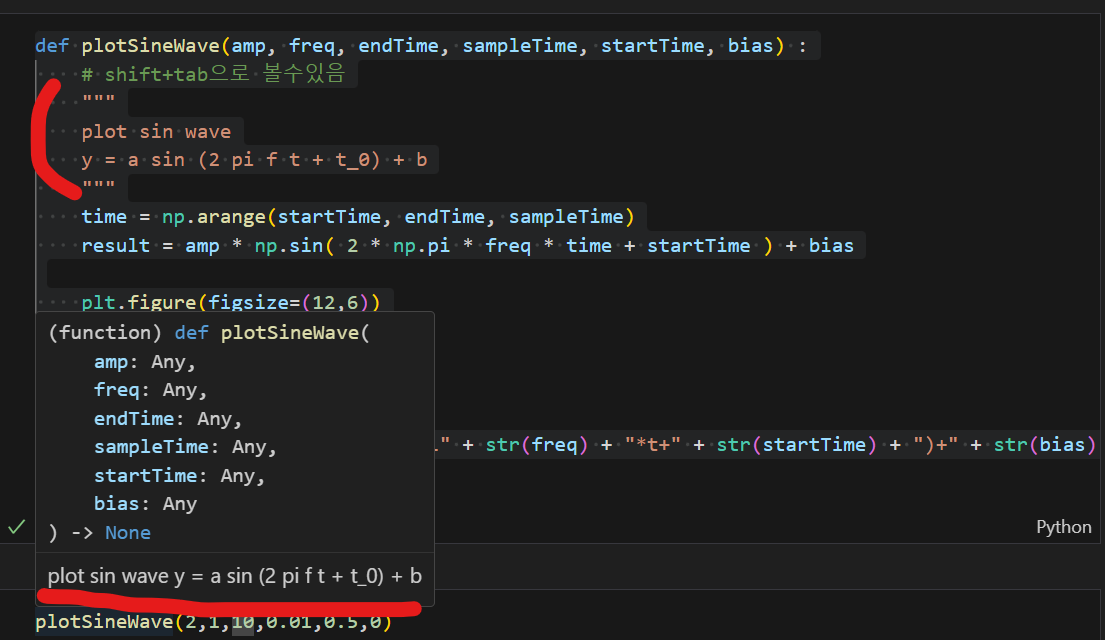
(Docstring | jupyter note에선 shift + tab / vs code에서는 마우스커서를 위로 올려확인)
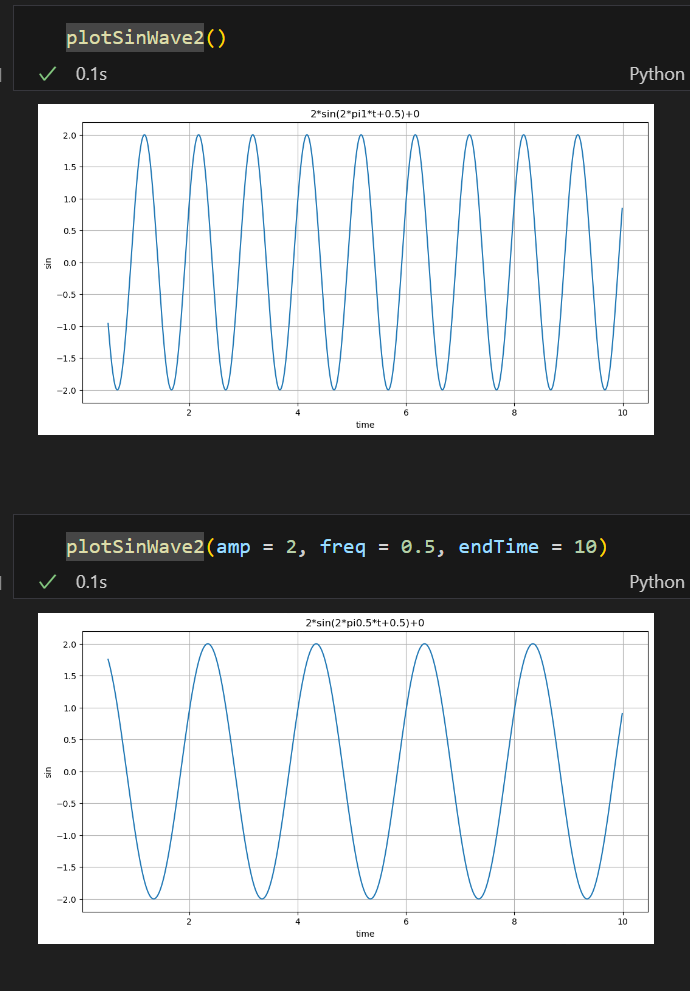
📌 keyword argument
함수의 인자가 많아 위치가 헷갈릴 때 사용한다.
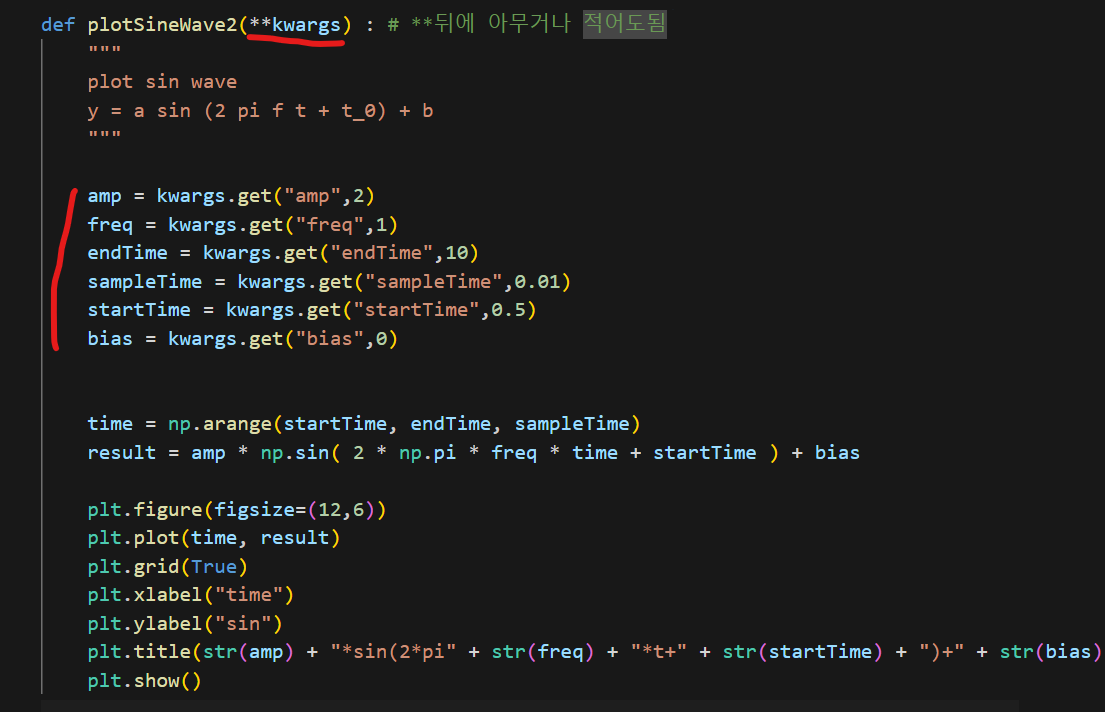
**뒤에 특정문구를 기재해주고,
특정문구.get(옵션명, 디폴트값)으로 사용
특정바꾸고싶은 인자는 함수에서 인자=값 으로 변경가능
모듈 import
📌 생성
현재경로에서 python 모듈을 만들고 싶을 때,
%%writefile ./파일명.py
상위 폴더로 가고 싶을 때 마다 .의 갯수를 늘려서 적어주면된다.
나 같은 경우 현재 __main__폴더는 basic이고,
모듈을 생성하고자 하는 경로는 basic -> module 폴더이므로
%%writefile ./module/set_matplotlib_hangul.py로 한글설정 모듈을 생성하였다.
📌 import
하위폴더일 경우 import 폴더명.모듈명
상위폴더일 경우 from .(폴더명) import 모듈명
(이때 .의 갯수는 상위로 올라가야하는 파일 수)
참고문서
prophet 기초
Facebook에서 개발한 시계열 예측 라이브러리로, Python 기반의 예측 모델링 도구
import pandas as pd
import numpy as np
import matplotlib.pyplot as pyplot
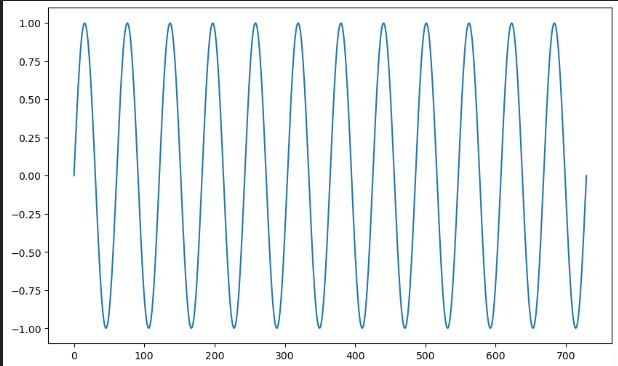
%matplotlib inlinetime = np.linspace(0,1,365*2)
result = np.sin(2*np.pi*12*time)
# 시간과 결과값 생성
ds = pd.date_range("2022-01-01", periods=365*2, freq="D")
#날짜범위생성 *freq : 주기
df = pd.DataFrame({"ds":ds, "y" :result})
# 데이터프레임 생성
df["y"].plot(figsize=(10,6));
#시계열데이터 시각화- 2년간의 균일한 데이터를 만든 후 sin함수에 넣어줌
from prophet import Prophet
m=Prophet(yearly_seasonality=True,daily_seasonality=True)
#연간 계절성과 일간계절성을 모델에 포함
m.fit(df);
# Prophet 모델생성 및 학습
future = m.make_future_dataframe(periods=30)
# 미래의 30일에 대한 예측 수행
forecast = m.predict(future)
m.plot(forecast)
# 예측 결과 시각화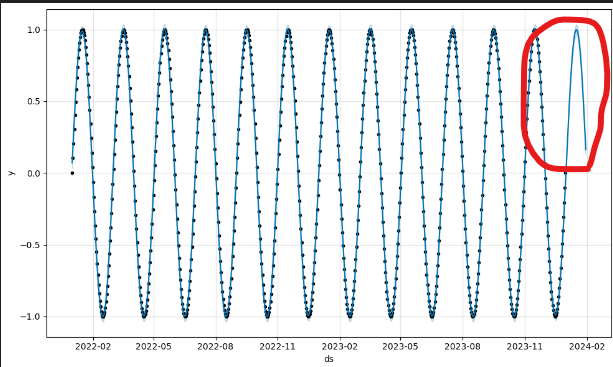
웹 유입량 데이터 분석
앞서 실습한 prophet을 이용해 https://pinkwink.kr/ 사이트의 웹 유입량 데이터를 분석해보자.
1. pinkwink의 날짜, 유입량이 담긴 csv 파일 가져오기
pinkwink_web = pd.read_csv(
"C:/Users/solbi/OneDrive/Documents/ds_study/data/05_PinkWink_Web_Traffic.csv",
encoding="utf-8",
thousands=",",
names=["date","hit"], #열 이름 지정
index_col=0
)
2. 전체 데이터 그려보기
pinkwink_web["hit"].plot(figsize=(12,4),grid=True)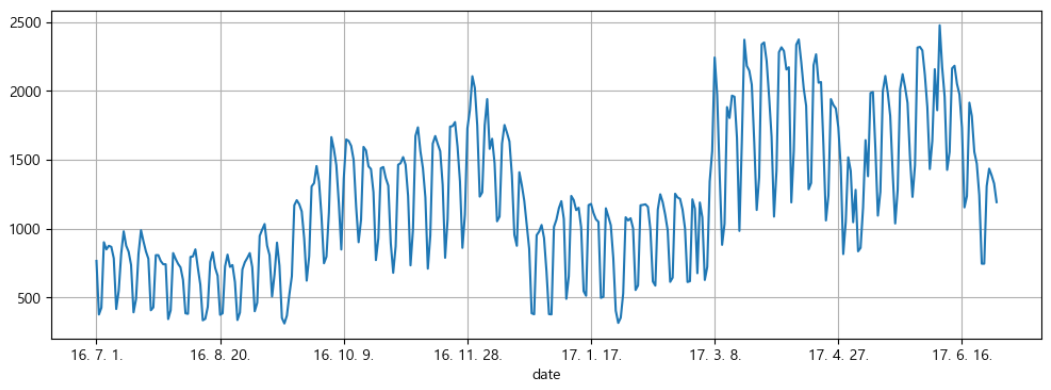
: 사실상 ["hit"]를 붙히지 않아도 컬럼이 하나라 동일한 그래프를 그릴 수 있다.
3. trend분석을 시각화 하기 위한 x축 값 만들기
time = np.arange(0,len(pinkwink_web))
traffic = pinkwink_web["hit"].values #유입량
fx = np.linspace(0,time[-1],1000)-
numpy arange | 지정된 범위 내에서 일정한 간격으로 값을 생성하여 1차원 배열을 생성
즉, 0부터 len(pinkwink_web)의 리스트를 생성한다.
pinkwink_web 파일엔 365일간의 유입량 데이터가 담겨있으므로,
len(pinkwink_web) = 365 -
numpy linspance | 지정된 범위에서 일정한 간격으로 값을 생성하여 1차원 배열을 생성
0부터 time-1까지 일정한간격으로 1000개의 수를 생성하여 리스트화 시킴
4. 1차, 2차, 3차, 15차 함수 시각화
f1p = np.polyfit(time, traffic,1)
f1 = np.poly1d(f1p)
f2p = np.polyfit(time, traffic,2)
f2 = np.poly1d(f2p)
f3p = np.polyfit(time, traffic,3)
f3 = np.poly1d(f3p)
f15p = np.polyfit(time, traffic,15)
f15 = np.poly1d(f15p)plt.figure(figsize=(12,4))
plt.scatter(time, traffic, s=10)
plt.plot(fx, f1(fx), lw = 4, label = "f1")
plt.plot(fx, f2(fx), lw = 4, label = "f2")
plt.plot(fx, f3(fx), lw = 4, label = "f3")
plt.plot(fx, f15(fx), lw = 4, label = "f15")
plt.grid(True, linestyle = "-", color = "0.75")
plt.legend(loc=2)
plt.show()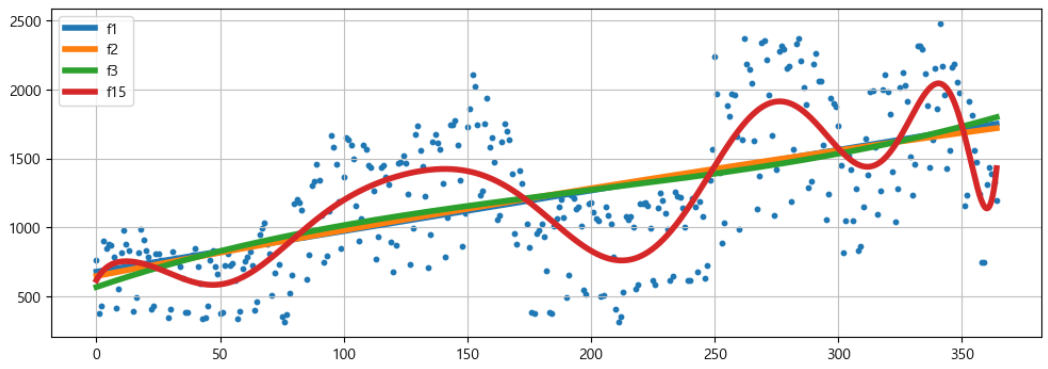
5. 예측값 시각화
df = pd.DataFrame({"ds":pinkwink_web.index, "y" : pinkwink_web["hit"]})
df.reset_index(inplace=True)
df["ds"] = pd.to_datetime(df["ds"], format="%y. %m. %d.")
del df["date"]
m = Prophet(yearly_seasonality=True, daily_seasonality=True)
m.fit(df);# 60일에 해당하는 데이터예측
future = m.make_future_dataframe(periods=60)
future.tail()# 예측결과는 상한/하한의 범위를 포함해서 얻어진다.
forecast = m.predict(future)
forecast[["ds","yhat","yhat_lower","yhat_upper"]].tail()
m.plot(forecast)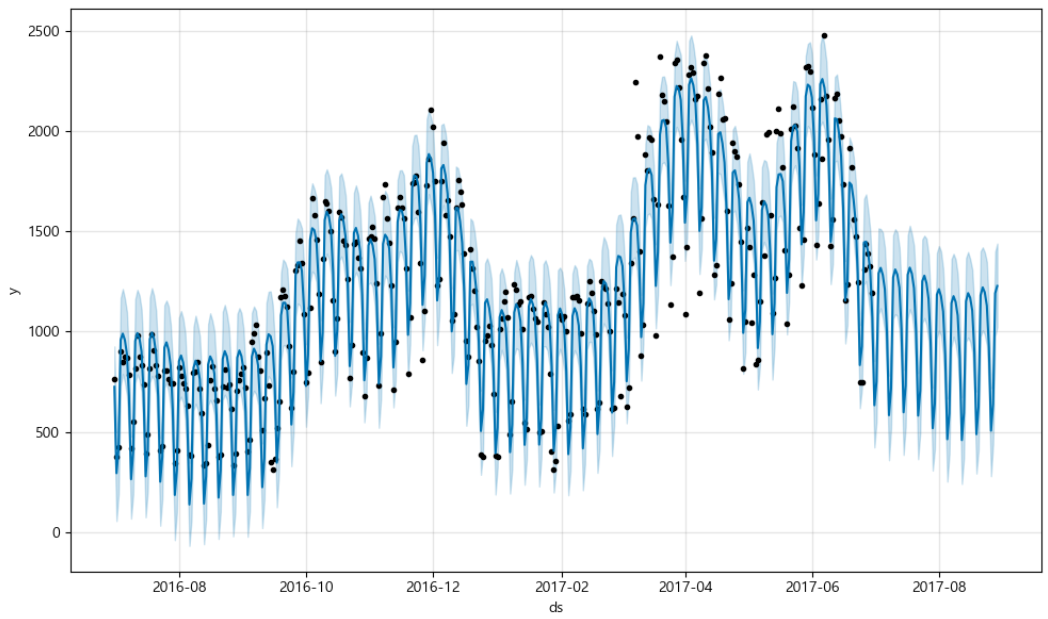
6. plot_components
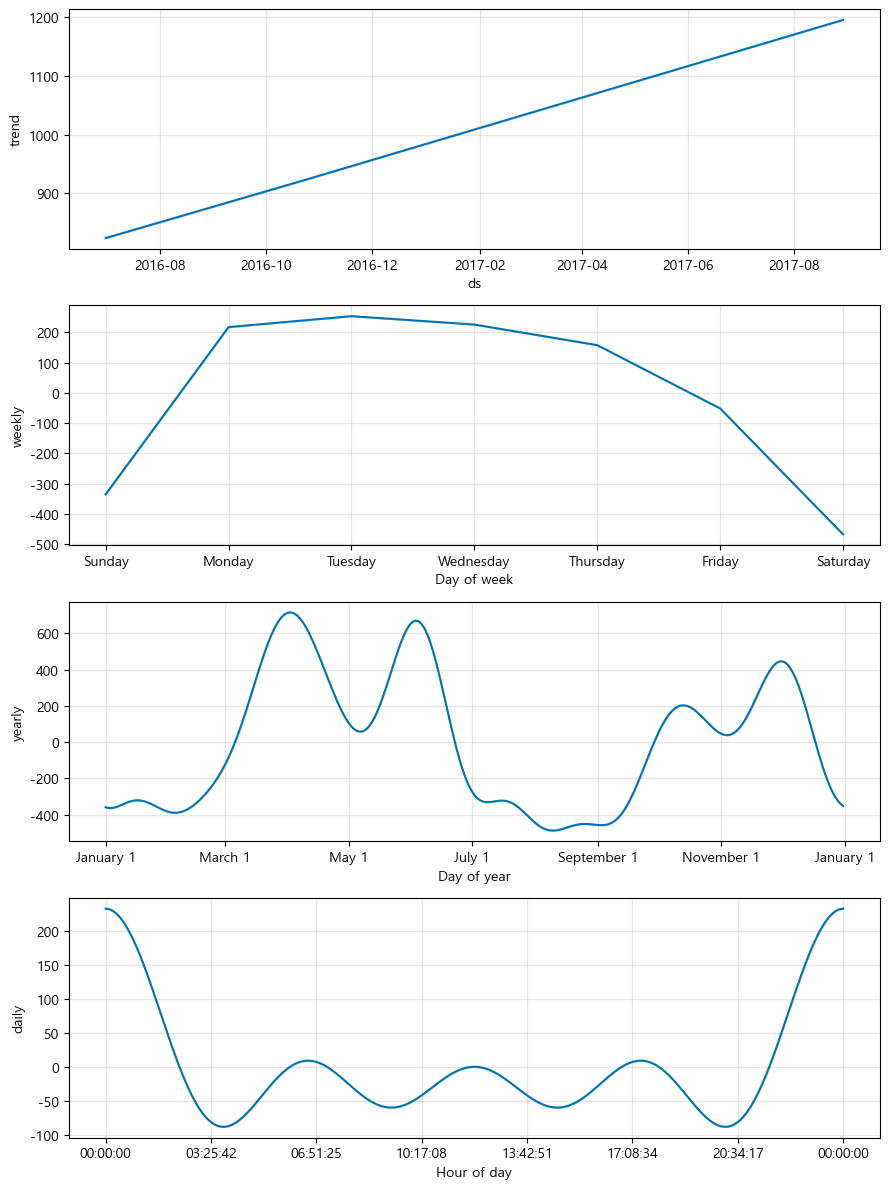
Daily Study Note
