
Pandas란?
파이썬의 데이터 분석 라이브러리
엑셀처럼 행과 열을 다루는 방식으로 데이터를 간편하게 처리한다.
Pandas의 자료구조
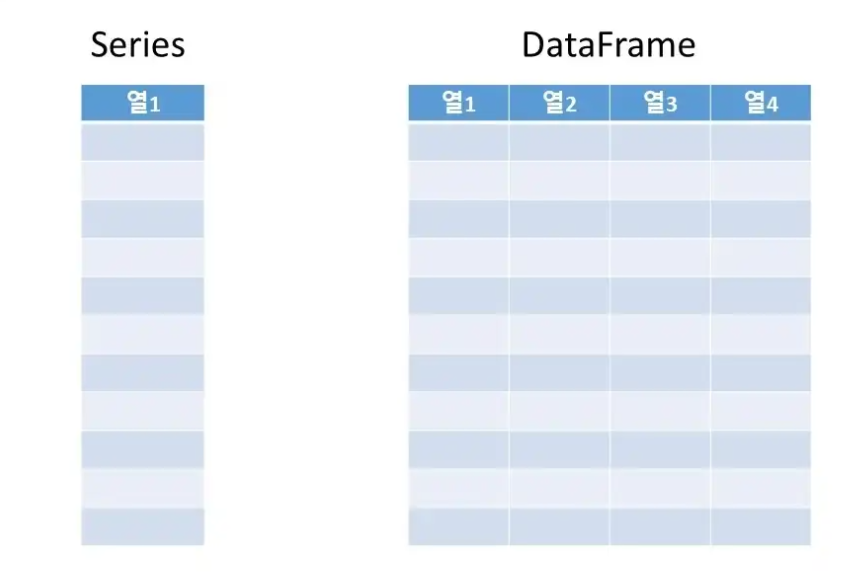
- Series (1차원)
- Data Frame (2차원)
1. Series
index와 value로 이루어져 있고, 한가지 데이터 타입만 가질 수 있다.
List, Array, Dict, Scalar로 생성한다.
e.g. list : pd.Series([1,2,3,4]) dic : pd.Series({"1번":1,"2번":2,"3번":3,"4번":4}) array : pd.Series(np.array([1,2,3]))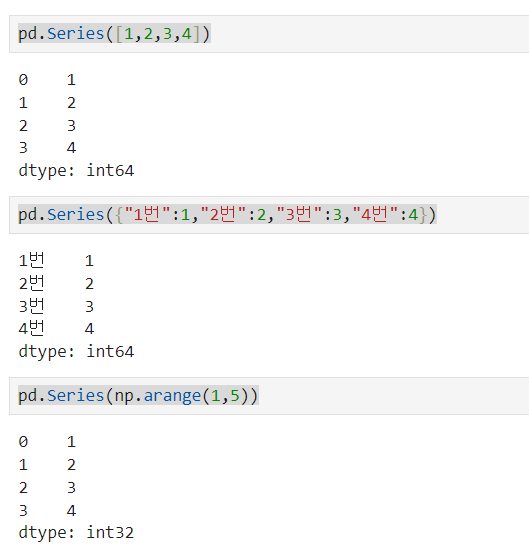
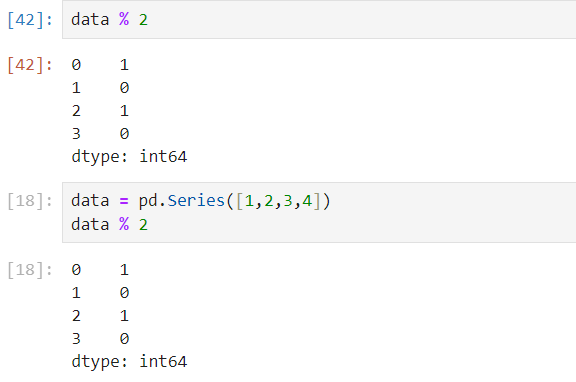
🧷 int로만 이루어진 Series를 연산해보자
(str이 있다면 error)
🧷series의 data타입을 변경해보자
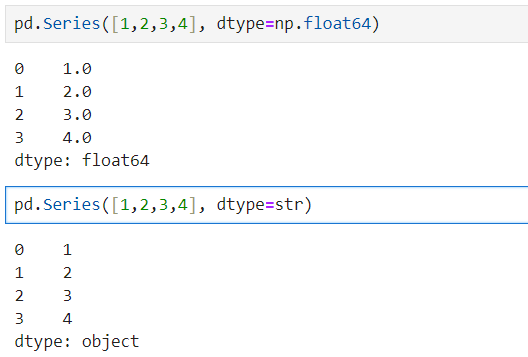
series의 dtype은 아래 문서를 통해 가능한 형태를 확인 할 수 있다.
(float의 경우 numpy모듈을 사용해야함)
🧷날짜데이터를 추출해보자
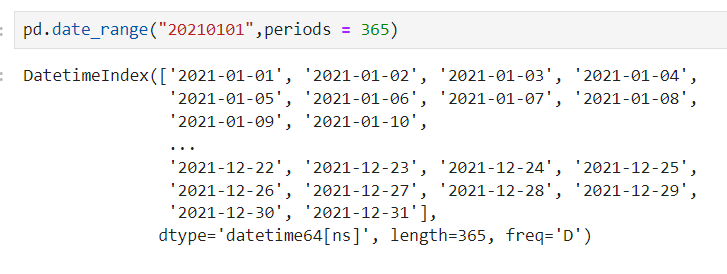
➕ numpy
대규모 다차원 배열을 다룰 수 있게 도와주는 python 라이브러리
- pandas 는 통상 pd
- numpy 는 통상 np
2. Dataframe
index, value, columns로 이루어진 2차원 테이블
🧷 생성
data.DataFrame(data,index,columns) 형태로 생성한다.
- data = table의 value
- index = table의 행
- columns = table의 열
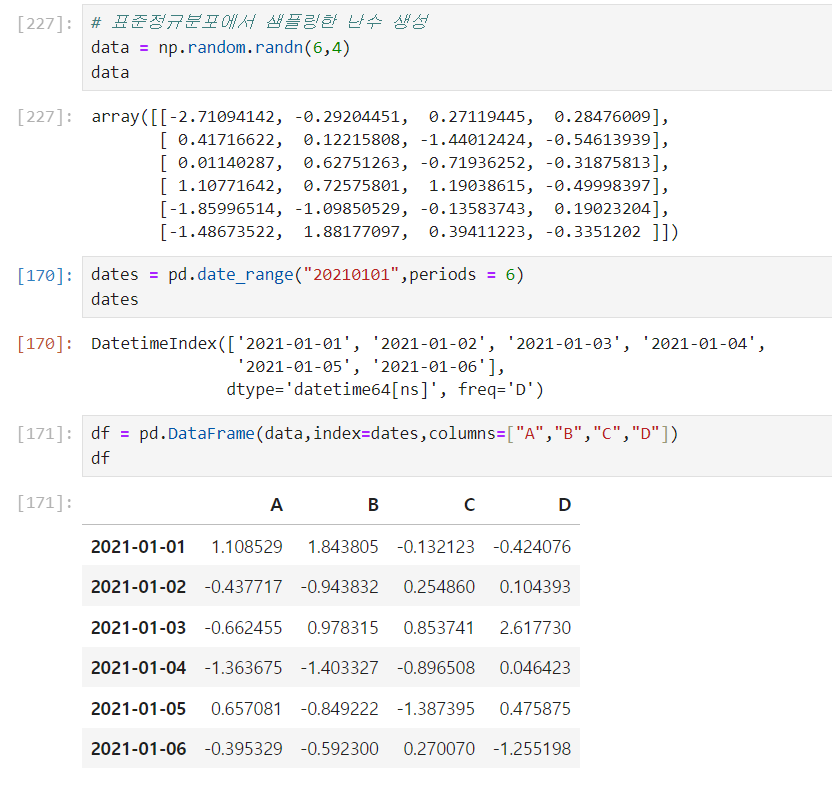
e.g.
- data = numpy생성 난수
- index = 20210101~20210106의 날짜
- columns = "A","B","C","D"
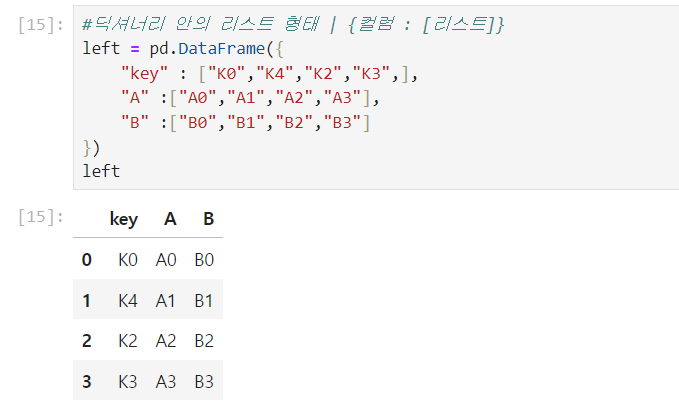
➕ 딕셔너리 안의 리스트형태 {컬럼 : [리스트]}
컬럼명 : [데이터] 형태로 Dataframe에 넣어줌
➕ 리스트안에 딕셔너리 형태 [{컬럼명1 : 데이터1}]
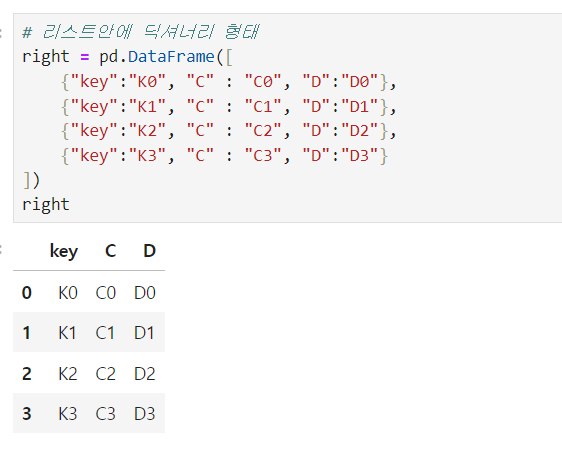
리스트안에
{컬럼명1 : 데이터1 ,컬럼명2 : 데이터1,...},
{컬럼명1 : 데이터2, 컬럼명2 : 데이터2,...}형태로 Dataframe에 넣어줌
🧷 탐색
head(), tail()
index,columns, value
index,columns, value(=data_정보를 따로 추출 할 수 있다.
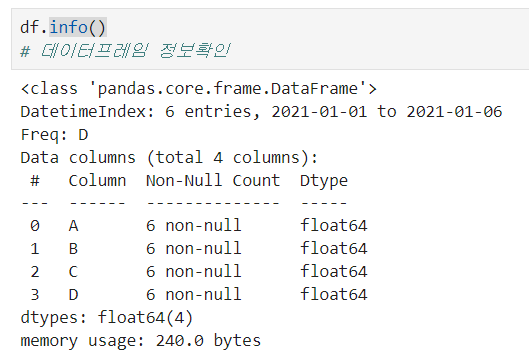
info()
데이터 프레임 정보 확인이 가능하다.
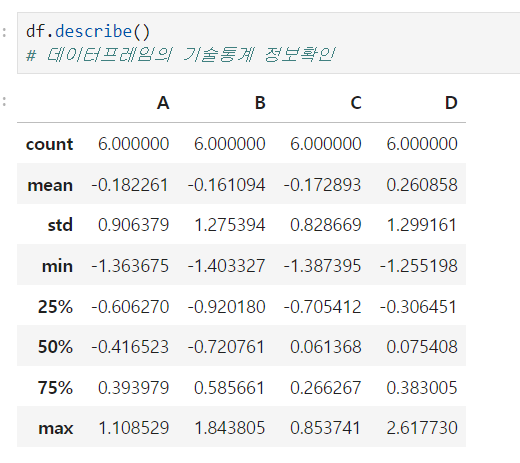
describe()
데이터프레임의 기술통계 정보확인
🧷 정렬
sort_values(by="컬럼명",ascending)
특정 컬렴을 기준으로 데이터 정렬
위에부터 B열 기준으로 내림차순 B열 기준으로 오름차순 -> inplace 원본 데이터 변경여부
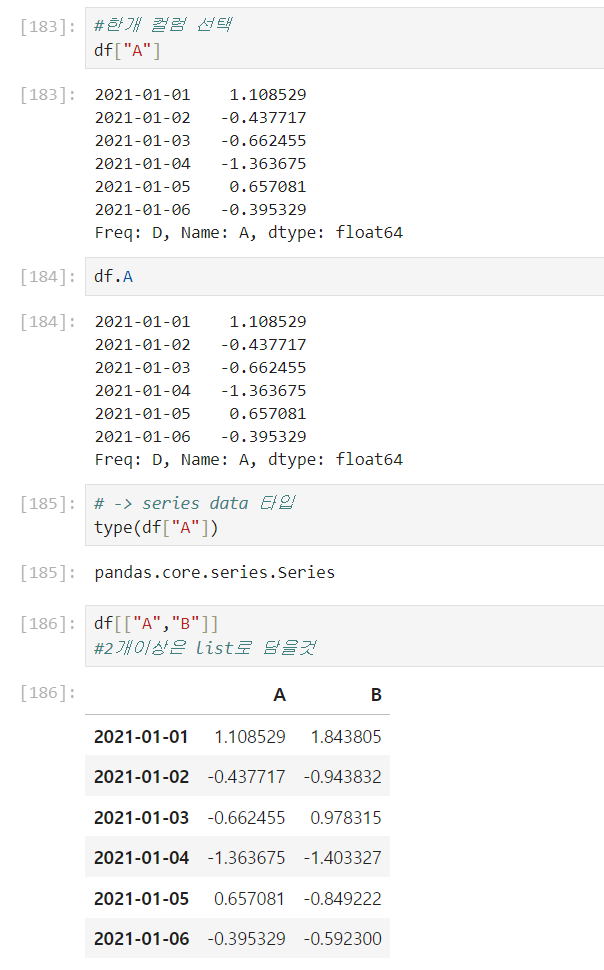
🧷 데이터선택
data["컬럼명"] data.컬럼명 data[["컬럼명","컬럼명"]]
특정 컬럼명 데이터 선택
-> series data타입으로 출력
isin("컬럼명")
특정요소가 있는지 확인
True False로 반환되며, 해당 data에 다시 넣어줄경우 True에 해당하는 행만 선택
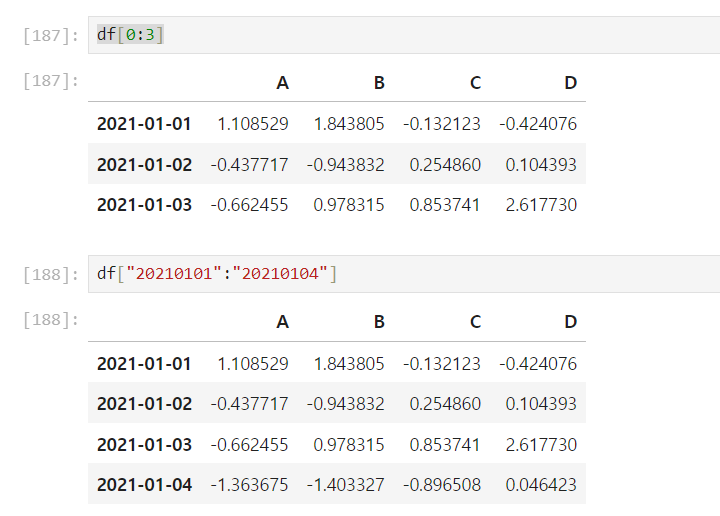
🧷 offset index
[n:m]
행을 기준으로 n부터 m-1까지 선택
- 단 컬럼명으로 : 를 넣을경우 m까지
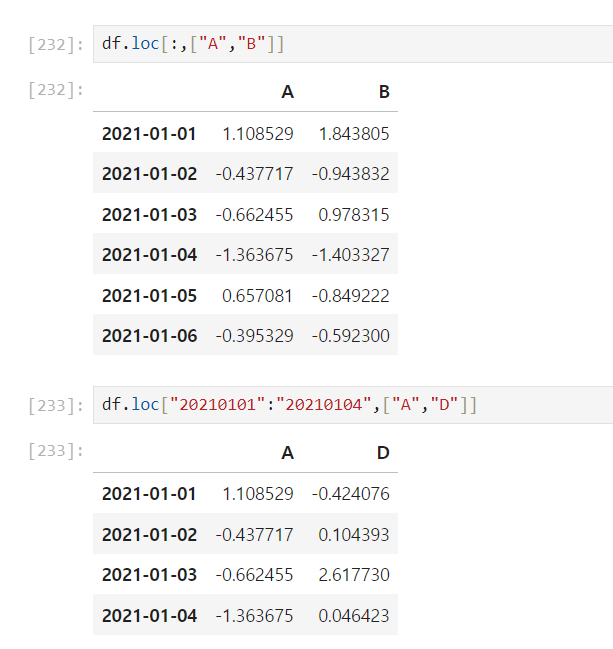
.loc[행범위 , 열범위]
인덱스의 이름과 컬럼명으로 행, 열 범위 선택
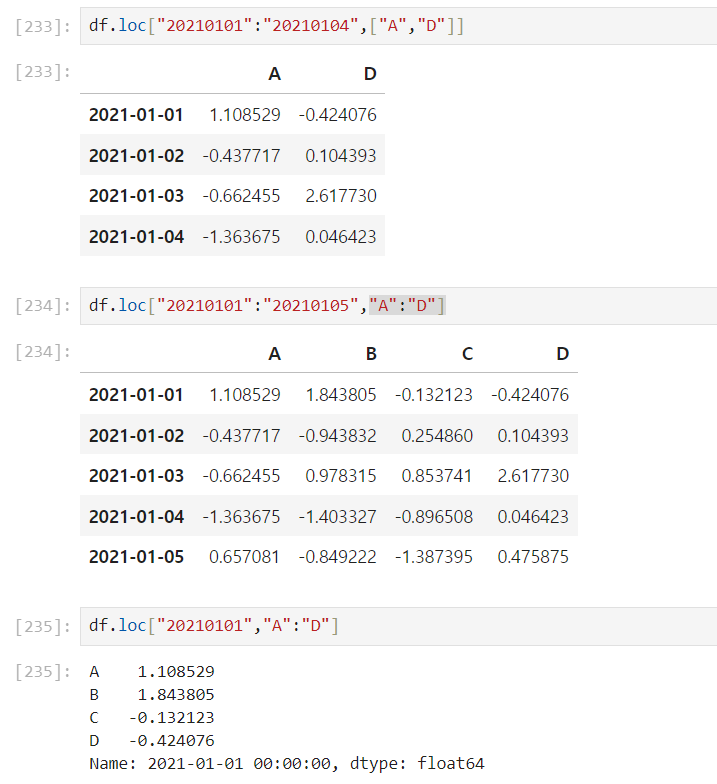
범위가 아닌 특정 컬럼명 지정["",""]도 가능하다.
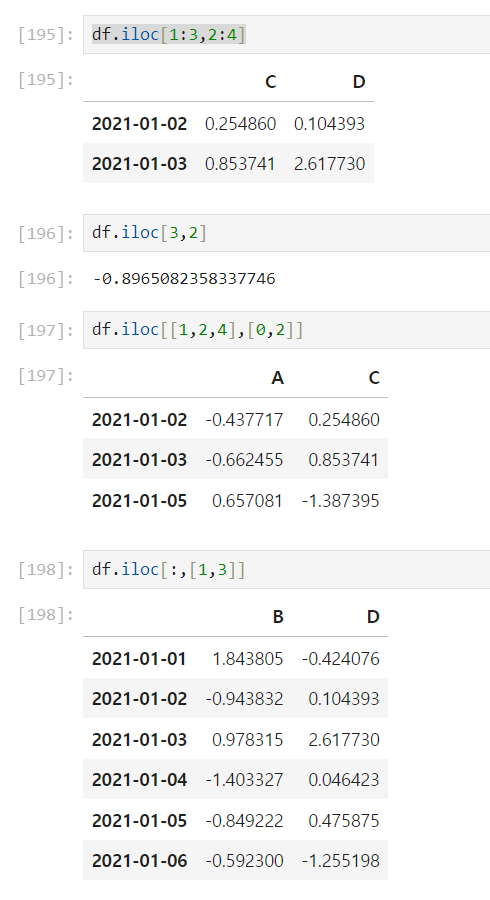
.iloc[행범위, 열범위]
컴퓨터가 인식하는 인덱스 값으로 선택
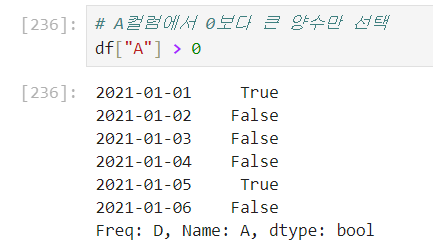
🧷 condition
data["컬럼명"] > 0
bool type으로 출력
data[data["컬럼명"] > 0]
특정 컬럼에서 True인 행만 추출
➕ NaN : Not a Number
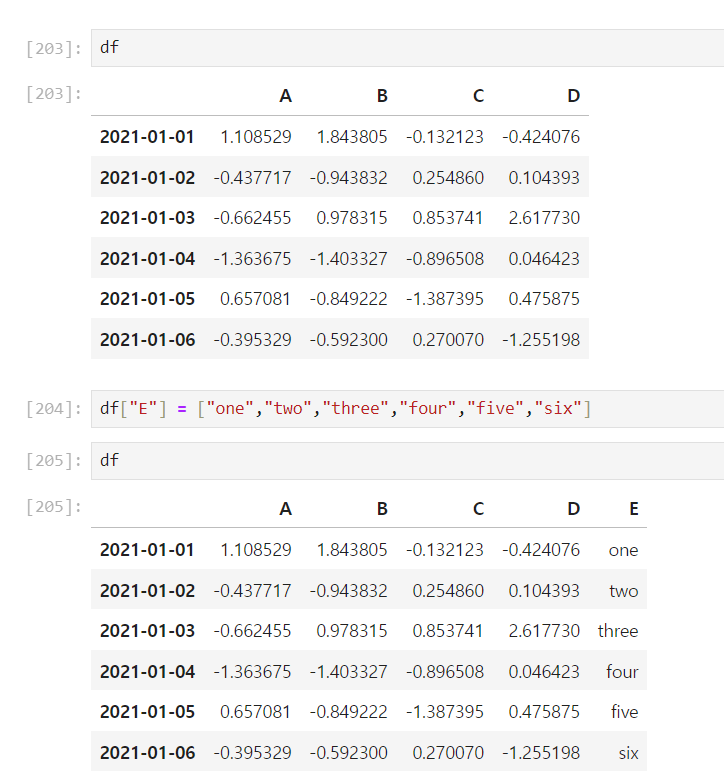
🧷 컬럼추가
- 기존컬럼이 없으면 추가
= 기존컬럼이 있으면 수정
data["컬럼"] = [value]
단, value는 data 행의 개수와 일치해야함
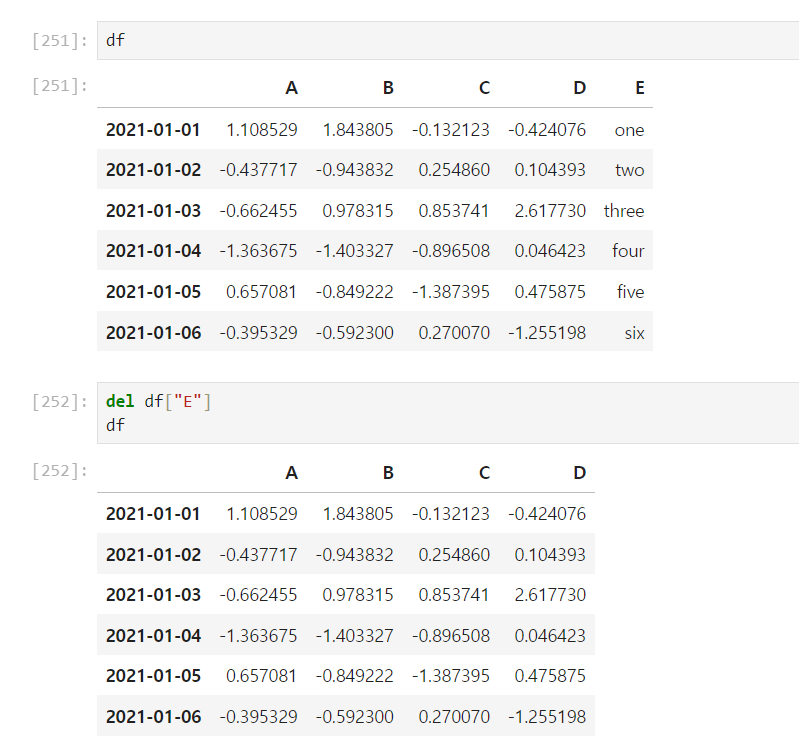
🧷 컬럼삭제 del, drop()
del data["컬럼명"]
특정 컬럼 삭제
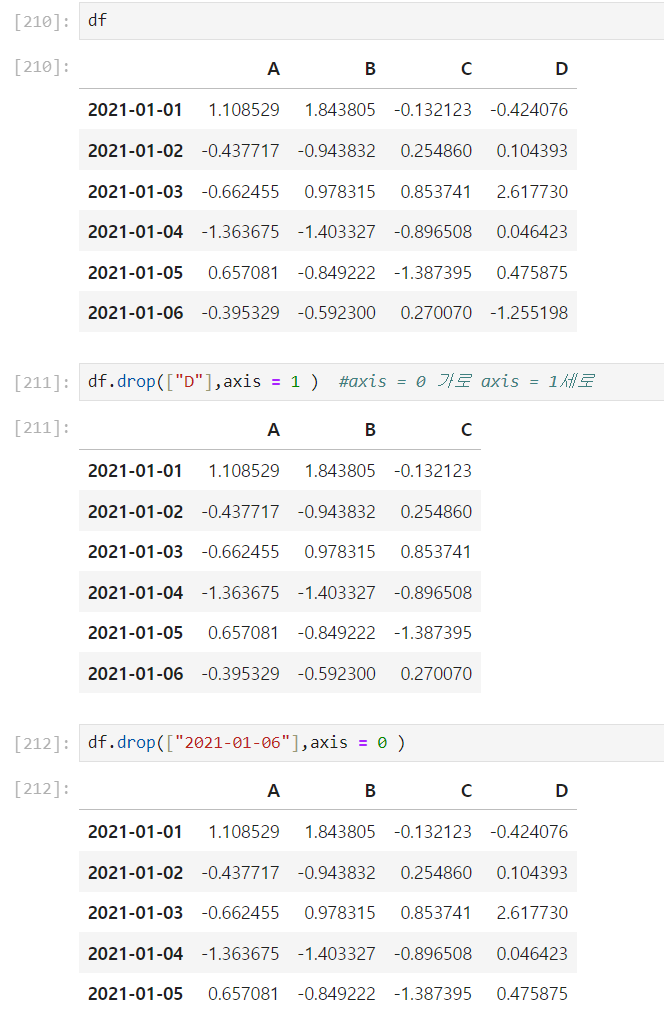
drop(["컬럼명 or 인덱스명"],axis = 1or2)
- 인덱스명 일 경우 : axis = 0 가로
- 컬럼명 일 경우 : axis = 1 세로
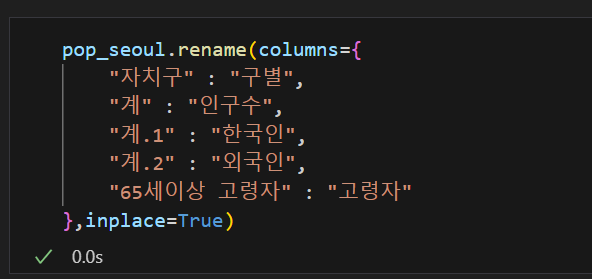
🧷 컬럼명 변경 rename()
df.rename(columns = "{컬럼명:바꿀컬럼명}")
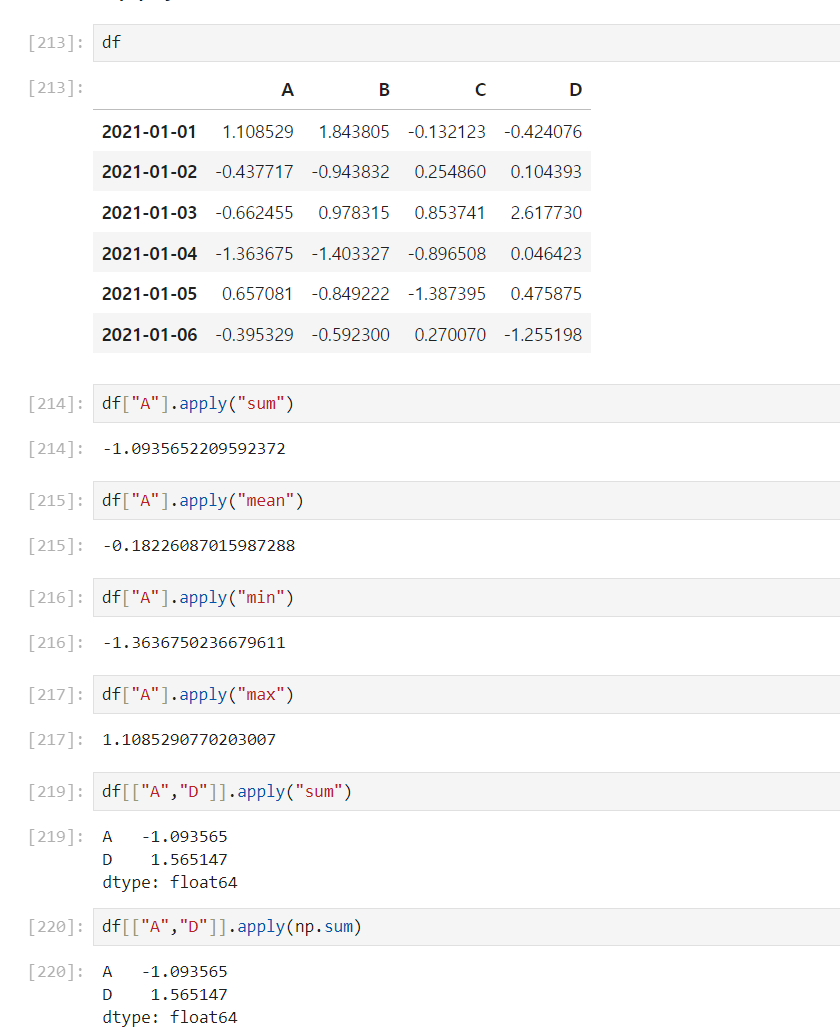
🧷 apply() | math
data["특정컬럼"].apply("적용문구")
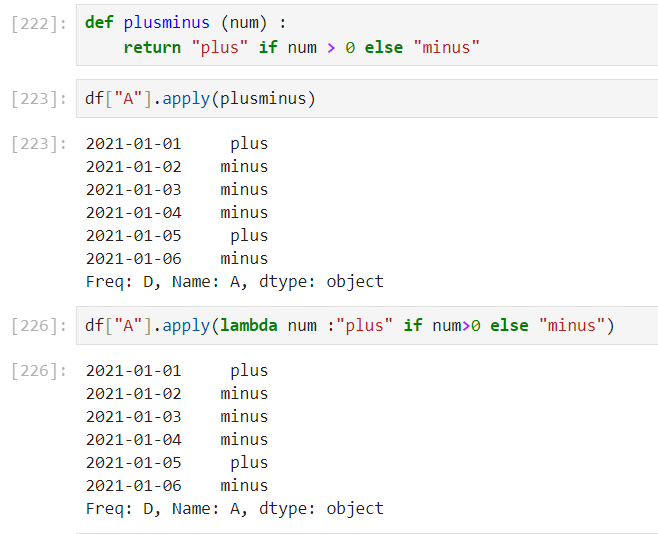
❗ 파이썬 함수를 생성하여 사용도 가능
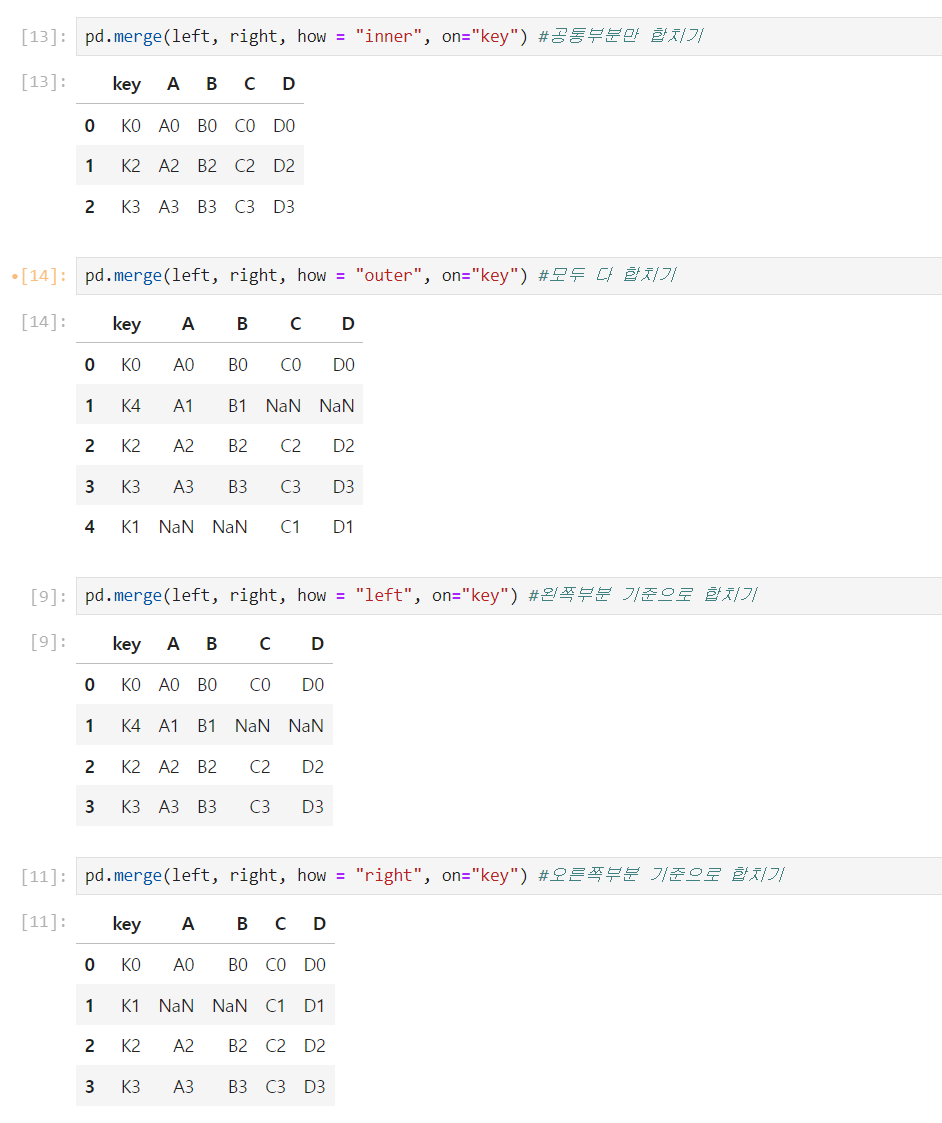
🧷 두 데이터합치기 merge()
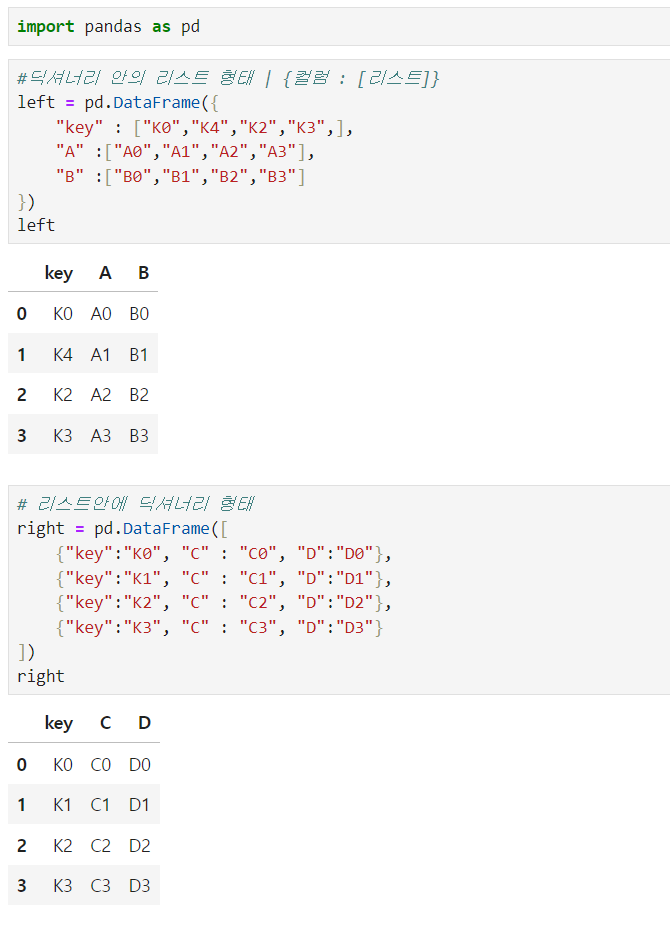
위와 같은 Dataframe 2개가 있을 때,
pd.merge()
()안에 합칠테이블1, 합칠테이블2, how = "" ,one = "키 컬럼명"을 넣어준다
➕ how
생략 & inner : 공통부분만 합치기
outer : 모두 다 합치기
left : 왼쪽 key 기준 합치기
right : 오른쪽 key 기준 합치기
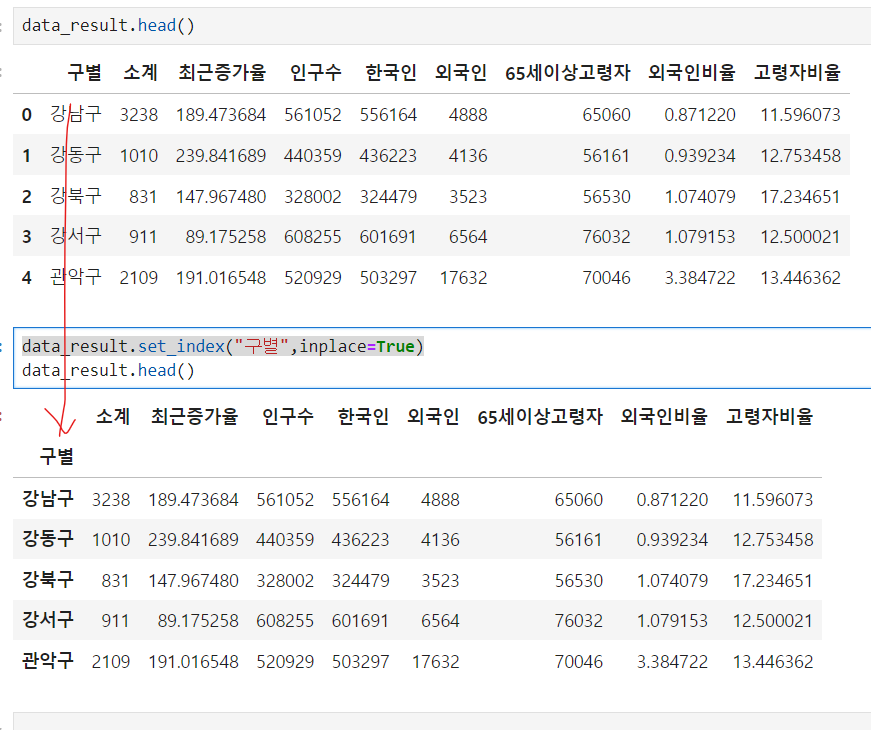
🧷 인덱스지정 set_index()
data_result.set_index("컬럼명",inplace=True)
🧷 인덱스리셋 reset_index()
Daily Study Note
