1. What is Web Scrapping
- 웹 상의 데이터를 추출하는 것
url로부터 유튜브 동영상 제목과 썸네일 이미지 등을 가져와서 트위터 preview로 보여줌- 구글에서 다른 웹 사이트에서 제공하는 정보를 추출해서 보여줌
2. Navigating with Python
import requests
indeed_result = requests.get('https://www.indeed.com/jobs?q=python&limit=50') # request를 만들고 그 결과를 변수에 넣음
# print(indeed_result.text) # indeed html 가져오기
-
requests = "2.27.1"
: 파이썬에서 요청을 만드는 기능을 모아놓은 것 -
beautifulsoup4 = "4.10.0"
: html에서 정보를 추출하기에 유용한 패키지
3. Extracting Indeed Pages
indeed.py
import requests
# BeautifulSoup : 웹 페이지를 표현하는 HTML 분석
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
# 재사용이 가능하도록 indeed pages를 추출하는 것을 함수로 만듦
def get_last_page():
# request를 만들고 그 결과를 변수에 넣음
result = requests.get(URL) # 1번째 페이지
#### html에서 정보 추출하기 (페이지 개수 가져오기) ####
# HTML 파일을 사용해서 BeautifulSoup 객체 생성
# indeed_result.text : indeed html 가져오기
# "html.parser" : HTML을 분석해라
soup = BeautifulSoup(result.text, "html.parser")
# HTML 태그 추출 : class가 pagination인 div 태그 추출
pagination = soup.find("div", {"class": "pagination"})
# 각 링크(auchor) 안에서 span 추출
links = pagination.find_all('a')
pages = []
for link in links[:-1]: # 마지막 두 요소(Next) 제외
# 링크 안에서 string만 가져온 후,
# string으로 가져온 숫자를 다시 integer로 변경해서 리스트에 넣어줌
pages.append(int(link.string))
max_page = pages[-1] # 마지막 페이지 번호
return max_page
# html에서 일자리 정보 추출
def extract_job(html):
# title 추출
job_title = html.find("h2", {"class": "jobTitle"})
title = job_title.find("span").string
if title == "new": # title만 뽑아내기
title = job_title.find_all("span")[1].string
# company 추출
company = html.find("span", {"class": "companyName"})
company_auchor = company.find("a")
# company 정보가 없는 경우를 위해
if company_auchor is not None:
company = str(company_auchor.string)
else:
company = str(company.string)
# company location 추출
location = html.find("div", {"class":"companyLocation"}).text
# job_id를 이용해서 apply link 가져오기
job_id = html["data-jk"]
return {
'title': title,
'company': company,
'location': location,
'apply_link': f"https://www.indeed.com/viewjob?jk={job_id}"
}
# 각 페이지에서 일자리 정보 추출 후 반환
def extract_jobs(last_page):
jobs = []
# 마지막 페이지 수만큼 request 보내기
for page in range(last_page):
print(f"Scrapping Indeed : Page {page}")
result = requests.get(f"{URL}&start={page*LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("a", {"class": "fs-unmask"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobsmain.py
from indeed import get_jobs as get_indeed_jobs
indeed_jobs = get_indeed_jobs()
print(indeed_jobs) # testoutput
C:\Users\syb02\AppData\Local\Programs\Python\Python36-32\python.exe C:\Users\syb02\pythonProject\main.py
Scrapping Indeed : Page 0
Scrapping Indeed : Page 1
Scrapping Indeed : Page 2
Scrapping Indeed : Page 3
Scrapping Indeed : Page 4
[{'title': 'Python Software Engineering Teaching Assistant (Part-Time)', 'company': 'Hackbright Academy', 'location': '+2 locationsRemote', 'apply_link': 'https://www.indeed.com/viewjob?jk=cc10e115d1ed386e'}, {'title': 'Software Developer – Entry Level', 'company': 'Grant Street Group', 'location': 'Remote', 'apply_link': 'https://www.indeed.com/viewjob?jk=37529d6dc65e1669'}, ...<중략>...
Process finished with exit code 0
4. Extracting Stackoverflow Pages
1) html에서 jobs 정보 추출
html에서 jobs 정보를 나타낼 때 사용하는 태그와 class 이름을 확인
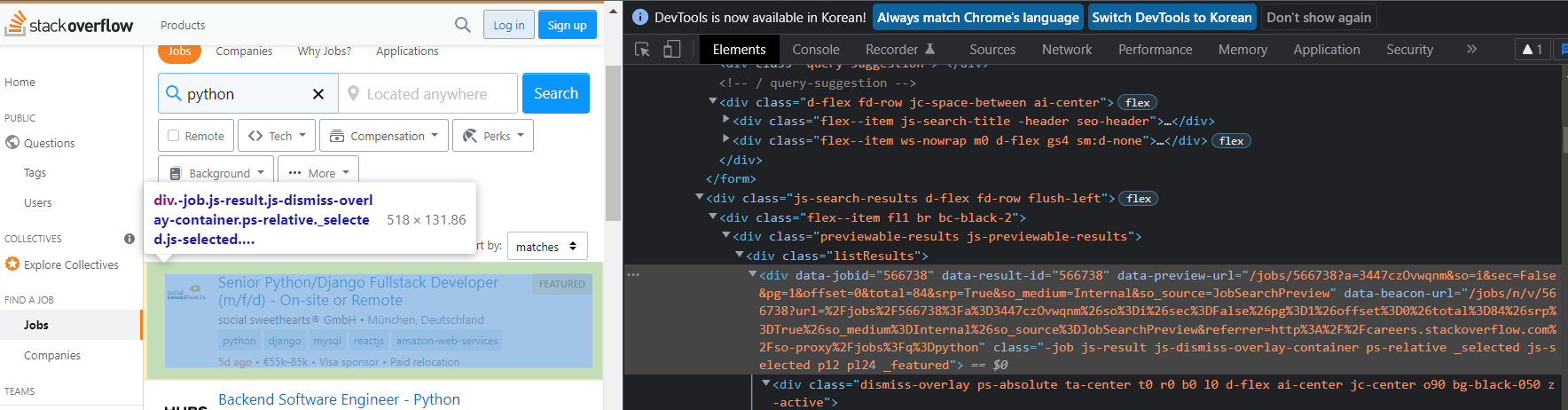
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
result = requests.get(f"{URL}&pg={page+1}")
# print(result.status_code) # test
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"-job"})
for result in results:
print(result["data-jobid"]) # test2) job title 추출

def extract_job(html):
title = html.find("h2").find("a")["title"]
return title # test3) company 추출
<h3>태그 안에<span>태그가 두개 존재<h3>태그 안에 회사명과 회사 위치에 대한 정보가 있음- 리스트 안에 두 개의 요소가 있는지 알고 있으면 따로 불러오는 것이 가능함(unpacking)
- 모든 정보를 불러오지 않고, 첫 단계에 있는
<span>만 불러오기 위해recursive = False로 작성

def extract_job(html):
company, location = html.find("h3").find_all("span", recursive=False)
company = company.get_text(strip=True)
location = location.get_text(
strip=True).strip("-").strip(" \r").strip("\n")
print(company, location)
4) 전체 코드
"User-Agent"
- http://www.useragentstring.com/ 사이트에서 알 수 있음
requests.get함수의 인자로 Agent 정보를 전달- 자기 컴퓨터로 보는 것과 html 결과를 일치시키기 위함
so.py
import requests
from bs4 import BeautifulSoup
URL = f"https://stackoverflow.com/jobs?q=python"
headers = {"User-Agent" : "자기 컴퓨터의 Agent(운영체제와 브라우저) 정보"}
def get_last_page():
result = requests.get(URL, headers=headers)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class":"s-pagination"}).find_all('a')
last_page = pages[-2].get_text(strip=True) # space 제거
return int(last_page)
def extract_job(html):
# job title 추출
title = html.find("h2").find("a")["title"]
# company 추출
company, location = html.find("h3").find_all("span", recursive=False)
company = company.get_text(strip=True)
location = location.get_text(
strip=True).strip("-").strip(" \r").strip("\n")
# apply link
job_id = html['data-jobid']
return {
'title': title,
'company': company,
'location': location,
"apply_link": f"https://stackoverflow.com/jobs/{job_id}"
}
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
print(f"Scrapping So: Page {page}")
result = requests.get(f"{URL}&pg={page+1}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"-job"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobsmain.py
from so import get_jobs as get_so_jobs
so_jobs = get_so_jobs()
print(so_jobs) # testoutput
Scrapping So: Page 0
Scrapping So: Page 1
Scrapping So: Page 2
Scrapping So: Page 3
[{'title': 'Data Engineer (Python, ETL)', 'company': 'Finsera', 'location': 'No office location', 'apply_link': 'https://stackoverflow.com/jobs/536631'}, {'title': 'Backend Engineering Manager (Python) - Spekit - High Growth Series A Startup', 'company': 'SpekitviaSource Coders', 'location': 'No office location', 'apply_link': 'https://stackoverflow.com/jobs/566634'}, ...<중략>...
Process finished with exit code 0
5. indeed jobs + so jobs
main.py
from indeed import get_jobs as get_indeed_jobs
from so import get_jobs as get_so_jobs
so_jobs = get_so_jobs()
indeed_jobs = get_indeed_jobs()
jobs = so_jobs + indeed_jobs
print(jobs)output
Scrapping So: page 0
Scrapping So: page 1
Scrapping So: page 2
Scrapping So: page 3
Scrapping Indeed : page 0
Scrapping Indeed : page 1
Scrapping Indeed : page 2
Scrapping Indeed : page 3
Scrapping Indeed : page 4
[{'title': 'Software Developer (Python)', 'company': 'Picnic', 'location': 'Amsterdam, Netherlands', 'apply_link': 'https://stackoverflow.com/jobs/292346'}, {'title': 'Backend Engineering Manager (Python) - Spekit - High Growth Series A Startup', 'company': 'SpekitviaSource Coders', 'location': 'No office location', 'apply_link': 'https://stackoverflow.com/jobs/566634'}, ...<중략>...
Process finished with exit code 06. CSV 파일로 저장
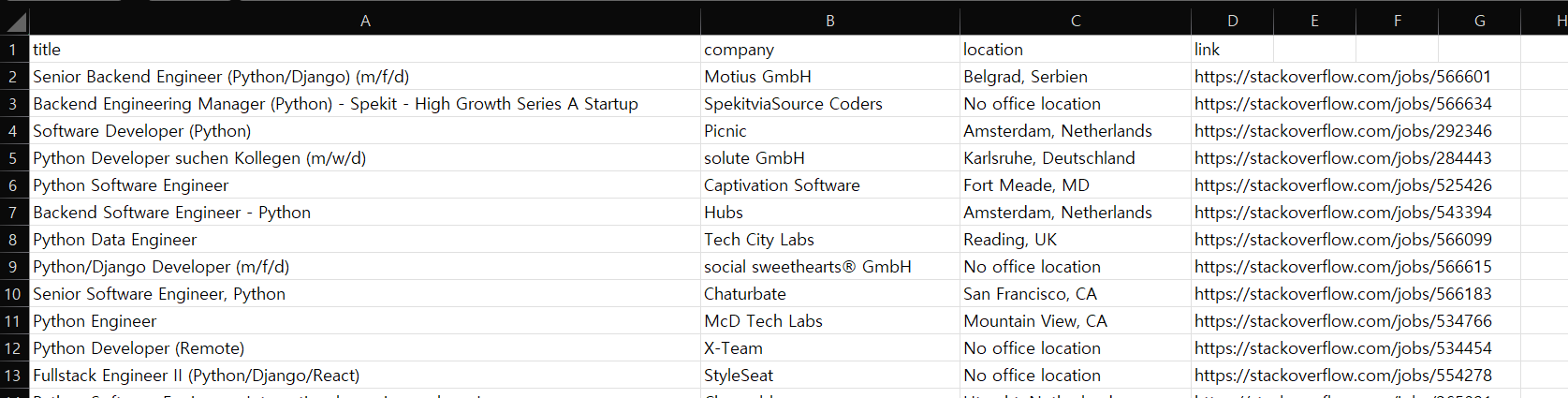
CSV: Comma Separated Valuescolums: comma를 기준으로 나눔rows: new line
save.py
import csv
def save_to_file(jobs):
# newline='' : 줄 바꿈이 2번 들어 가는 것을 방지
# encoding="utf-8-sig" : 언어 인코딩 오류 해결
file = open("jobs.csv", mode="w", newline='', encoding="utf-8-sig") # 파일 생성
writer = csv.writer(file) # 쓰기를 수행할 파일 지정
writer.writerow(["title", "company", "location", "link"]) # 첫 줄 작성
for job in jobs:
# job dictionary에서 value만 불러오기
# dictionary -> list
# list로 저장된 job 정보를 파일에 write
writer.writerow(list(job.values()))
returnmain.py
from indeed import get_jobs as get_indeed_jobs
from so import get_jobs as get_so_jobs
from save import save_to_file
so_jobs = get_so_jobs()
indeed_jobs = get_indeed_jobs()
jobs = so_jobs + indeed_jobs
save_to_file(jobs)jobs.csv

Backend development