1. Introduction to Flask
-
파이썬으로 웹사이트를 만들 수 있게 해주는 micro-Framework
-
설정을 따로 할 필요가 없음
-
개발 환경 : Repl.it
from flask import Flask
app = Flask("SuperScrapper")
# @ : 데코레이터
# root로 접속 요청이 들어오면 home 함수 실행
@app.route("/")
def home():
return "Hello! Welcome to mi casa!"
# /contact로 접속 요청이 들어오면 contact 함수 실행
@app.route("/contact")
def contact():
return "Contact me!"
# repl.it에서 사이트 결과를 보기 위해 host 0.0.0.0 지정
app.run(host="0.0.0.0")...생략...
* Running on http://172.18.0.141:5000/ (Press CTRL+C to quit)
172.18.0.1 - - [24/Mar/2022 13:44:59] "GET / HTTP/1.1" 200 -
172.18.0.1 - - [24/Mar/2022 13:45:03] "GET / HTTP/1.1" 200 -
172.18.0.1 - - [24/Mar/2022 13:45:14] "GET /contact HTTP/1.1" 200 -2. Dynamic URLs & Templates
main.py
from flask import Flask
app = Flask("SuperScrapper")
@app.route("/")
def home():
return "Hello! Welcome to mi casa!"
# Dynamic URLs
@app.route("/<username>") # <> : placeholder
def contact(username):
return f"Hello {username}! how are you doing"
app.run(host="0.0.0.0")
main.py
from flask import Flask, render_template
app = Flask("SuperScrapper")
@app.route("/")
def home():
# fronEnd file을 .html에서 읽어오게 함
return render_template("potato.html")
app.run(host="0.0.0.0")templates/potato.html
<!DOCTYPE html>
<html>
<head>
<title>Job Search</title>
</head>
<body>
<h1>Job Search</h1>
<form>
<input placeholder='Search for a job' required />
<button>Search</button>
</form>
</body>
</html>
3. Forms and Query Arguments
- flask는 html 파일을 rendering하고
{{}}대신에 개발자가 던져준 변수를 넣어서 출력해줌
templates/report.html
<!DOCTYPE html>
<html>
<head>
<title>Job Search</title>
</head>
<body>
<h1>Search Results</h1>
<h3>You are looking for {{searchingBy}} </h3>
</body>
</html>main.py
from flask import Flask, render_template, request, redirect
app = Flask("SuperScrapper")
@app.route("/")
def home():
return render_template("potato.html")
@app.route("/report")
def report():
# query argument
word = request.args.get('word')
if word: # 입력 받은 값이 존재할 때
word = word.lower() # 소문자로 format
else: # 입력한 값이 없으면
return redirect("/") # home으로 돌아가기
return render_template("report.html", searchingBy=word)
app.run(host="0.0.0.0")

4. Scrapper Integration
1) Fake DB / Rendering Jobs
so.py (https://velog.io/@syb0228/Building-A-Job-Scrapper)
-> scrapper.py (이전에 작성한 파일을 끌고와서 코드 수정)
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36"}
def get_last_page(url): # url를 인자로 받음
result = requests.get(url, headers=headers)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class":"s-pagination"}).find_all('a')
.. 생략 ..
def extract_jobs(last_page, url): # url를 인자로 받음
jobs = []
for page in range(last_page):
print(f"Scrapping So: Page {page}")
result = requests.get(f"{url}&pg={page+1}") # 수정
.. 생략 ..
def get_jobs(word): # 검색어를 인자로 받음
url = f"https://stackoverflow.com/jobs?q={word}" # 해당 함수 안에서 url 정의
last_page = get_last_page(url) # url 전달
jobs = extract_jobs(last_page, url)
return jobsmain.py
from flask import Flask, render_template, request, redirect
from scrapper import get_jobs
app = Flask("SuperScrapper")
# fake DB - Faster Scrapper
db = {}
@app.route("/")
def home():
return render_template("potato.html")
@app.route("/report")
def report():
word = request.args.get('word')
if word: # 입력 받은 값이 존재할 때
word = word.lower() # 소문자로 변경
existingJobs = db.get(word)
if existingJobs: # db에 존재하면
jobs = existingJobs
else: # db에 존재하지 않으면
jobs = get_jobs(word) # Scrapper 동작
db[word] = jobs # 결과를 db에 새로 저장
else:
return redirect("/") # home으로 돌아가기
return render_template(
"report.html",
resultNumber = len(jobs),
searchingBy=word,
jobs=jobs # Rendering jobs
)
app.run(host="0.0.0.0")templates/report.html
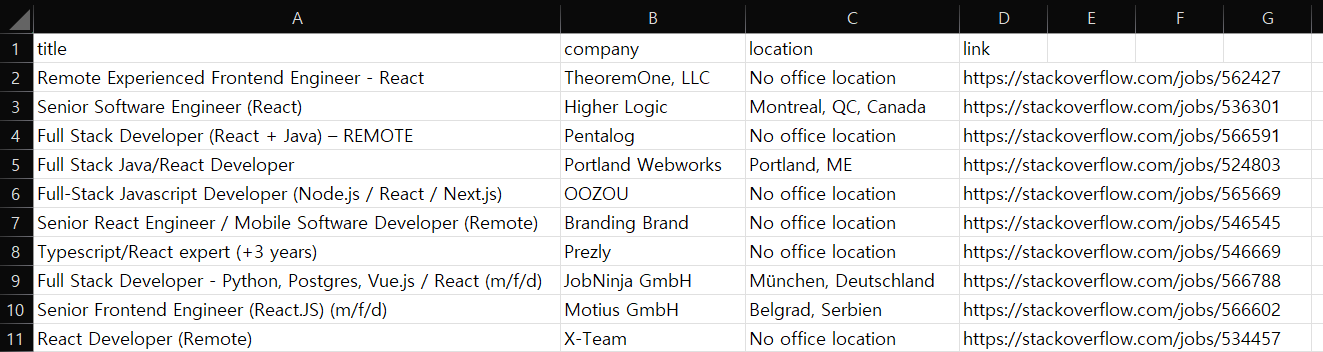
{{변수}} {% 코드 %}
<!DOCTYPE html>
<html>
<head>
<title>Job Search</title>
<style>
section {
display:grid;
gap:20px;
grid-template-columns: repeat(4, 1fr);
}
</style>
</head>
<body>
<h1>Search Results</h1>
<h3>Found {{resultNumber}} results for : {{searchingBy}} </h3>
<section>
<h4>Title</h4>
<h4>Company</h4>
<h4>Location</h4>
<h4>Link</h4>
{% for job in jobs %}
<span>{{job.title}}</span>
<span>{{job.company}}</span>
<span>{{job.location}}</span>
<a href="{{job.apply_link}}" target="_blank">Apply</a>
{% endfor %}
</section>
</body>
</html>
2) Export Route / File Download
save.py -> exporter.py (코드 수정은 없음)
import csv
def save_to_file(jobs):
file = open("jobs.csv", mode="w", newline='', encoding="utf-8-sig")
writer = csv.writer(file)
writer.writerow(["title", "company", "location", "link"])
for job in jobs:
writer.writerow(list(job.values()))
returnmain.py
from flask import Flask, render_template, request, redirect, send_file
from scrapper import get_jobs
from exporter import save_to_file
app = Flask("SuperScrapper")
.. 생략 ..
@app.route("/export")
def export():
try:
word = request.args.get('word')
if not word: # 검색어를 입력하지 않은 경우
raise Exception()
word = word.lower()
jobs = db.get(word) # db에서 바로 정보 가져오기
if not jobs: # 직업 정보가 없으면
raise Exception()
save_to_file(jobs)
return send_file("jobs.csv") # file download
except: # 예외처리
return redirect("/")
app.run(host="0.0.0.0")
templates/report.html
<!DOCTYPE html>
<html>
.. 생략 ..
<body>
<h1>Search Results</h1>
<h3>Found {{resultNumber}} results for : {{searchingBy}} </h3>
<a href="/export?word={{searchingBy}}">Export to CSV</a>
.. 생략 ..
</body>
</html>
5. 전체 코드
templates/potato.html
<!DOCTYPE html>
<html>
<head>
<title>Job Search</title>
</head>
<body>
<h1>Job Search</h1>
<form action="/report" method="get">
<input placeholder='Search for a job' required name="word"/>
<button>Search</button>
</form>
</body>
</html>templates/report.html
<!DOCTYPE html>
<html>
<head>
<title>Job Search</title>
<style>
section {
display:grid;
gap:20px;
grid-template-columns: repeat(4, 1fr);
}
</style>
</head>
<body>
<h1>Search Results</h1>
<h3>Found {{resultNumber}} results for : {{searchingBy}} </h3>
<a href="/export?word={{searchingBy}}">Export to CSV</a>
<section>
<h4>Title</h4>
<h4>Company</h4>
<h4>Location</h4>
<h4>Link</h4>
{% for job in jobs %}
<span>{{job.title}}</span>
<span>{{job.company}}</span>
<span>{{job.location}}</span>
<a href="{{job.apply_link}}" target="_blank">Apply</a>
{% endfor %}
</section>
</body>
</html>scrapper.py
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36"}
def get_last_page(url):
result = requests.get(url, headers=headers)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class":"s-pagination"}).find_all('a')
last_page = pages[-2].get_text(strip=True)
return int(last_page)
def extract_job(html):
title = html.find("h2").find("a")["title"]
company, location = html.find("h3").find_all("span", recursive=False)
company = company.get_text(strip=True)
location = location.get_text(
strip=True).strip("-").strip(" \r").strip("\n")
job_id = html['data-jobid']
return {
'title': title,
'company': company,
'location': location,
"apply_link": f"https://stackoverflow.com/jobs/{job_id}"
}
def extract_jobs(last_page, url):
jobs = []
for page in range(last_page):
print(f"Scrapping So: Page {page}")
result = requests.get(f"{url}&pg={page+1}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class":"-job"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs(word):
url = f"https://stackoverflow.com/jobs?q={word}"
last_page = get_last_page(url)
jobs = extract_jobs(last_page, url)
return jobsexporter.py
import csv
def save_to_file(jobs):
file = open("jobs.csv", mode="w", newline='', encoding="utf-8-sig")
writer = csv.writer(file)
writer.writerow(["Title", "Company", "Location", "Link"])
for job in jobs:
writer.writerow(list(job.values()))
returnmain.py
from flask import Flask, render_template, request, redirect, send_file
from scrapper import get_jobs
from exporter import save_to_file
app = Flask("SuperScrapper")
# fake DB - Faster Scrapper
db = {}
@app.route("/")
def home():
return render_template("potato.html")
@app.route("/report")
def report():
word = request.args.get('word')
if word: # 입력 받은 값이 존재할 때
word = word.lower()
existingJobs = db.get(word)
if existingJobs: # db에 존재하면
jobs = existingJobs
else:
jobs = get_jobs(word) # Scrapper 동작
db[word] = jobs # 결과를 db에 새로 저장
else:
return redirect("/") # home으로 돌아가기
return render_template(
"report.html",
resultNumber = len(jobs),
searchingBy=word,
jobs=jobs # Rendering jobs
)
@app.route("/export")
def export():
try:
word = request.args.get('word')
if not word: # 검색어를 입력하지 않은 경우
raise Exception()
word = word.lower()
jobs = db.get(word) # db에서 바로 정보 가져오기
if not jobs: # 직업 정보가 없으면
raise Exception()
save_to_file(jobs)
return send_file("jobs.csv")
except: # 예외처리
return redirect("/")
app.run(host="0.0.0.0")출처 : Python으로 웹 스크래퍼 만들기

Backend development