1. 그래프 탐색 알고리즘
- 탐색이란 많은 양의 데이터 중에서 원하는 데이터를 찾는 과정
- 대표적인 그래프 탐색 알고리즘으로는 DFS와 BFS가 있음
- DFS/BFS는 코딩 테스트에서 매우 자주 등장하는 유형
2. Stack / Queue 자료구조
1) Stack
- 리스트를 이용해서 스택을 구현할 수 있음
stack = []
# 삽입(5) 삽입(6) - 삽입(1) - 삽입(7) - 삭제(7) - 삽입(3) - 삭제(3)
stack.append(5)
stack.append(6)
stack.append(1)
stack.append(7)
stack.pop()
stack.append(3)
stack.pop()
print(stack[::-1]) # 최상단 원소부터 출력
print(stack) # 최하단 원소부터 출력[1, 6, 5]
[5, 6, 1]import java.util.*;
public class Main {
public static void main(String[] args){
Stack<Integer> s = new Stack<>();
s.push(5); # 삽입
s.push(2);
s.push(3);
s.push(7);
s.pop(); # 삭제
s.push(1);
s.push(4);
s.pop();
while(!s.empty()){
System.out.print(q.peek() + " ");
s.pop();
}
}
}1 3 2 52) Queue
- 리스트로 큐를 구현할 수 있지만 시간 복잡도가 높아서 비효율적
- deque 라이브러리를 이용해서 queue를 구현하는 것이 효율적
from collections import deque
queue = deque()
# 삽입(5) 삽입(6) - 삽입(1) - 삽입(7) - 삭제(5) - 삽입(3) - 삭제(6)
queue.append(5) # 삽입
queue.append(6)
queue.append(1)
queue.append(7)
queue.popleft() # 삭제
queue.append(3)
queue.popleft()
print(queue) # 먼저 들어온 순서대로 출력
queue.reverse() # 역순으로 바꾸기
print(queue) # 나중에 들어온 원소부터 출력deque([1, 7, 3])
deque([3, 7, 1])import java.util.*;
public class Main {
public static void main(String[] args){
Queue<Integer> q = new LinkedList<>();
q.offer(5); # 삽입
q.offer(2);
q.offer(3);
q.offer(7);
q.poll(); # 삭제
q.offer(1);
q.offer(4);
q.poll();
while(!q.isEmpty()){
System.out.print(q.poll() + " ");
}
}
}3 7 1 43. 재귀 함수
1) 최대공약수 계산 (유클리드 호제법)
-
두 개의 자연수에 대한 최대공약수를 구하는 대표적인 알고리즘
-
유클리드 호제법
- 두 자연수 A, B에 대하여 (A > B) A를 B로 나눈 나머지를 R이라고 함
- 이때 A와 B의 최대 공약수는 B와 R의 최대 공약수와 같음
-
유클리드 호제법의 아이디어를 그대로 재귀 함수로 작성할 수 있음
def gcd(a, b):
print(f"A : {a}, B : {b}")
if a % b == 0:
return b
else:
return gcd(b, a % b)
print("gcd(192, 162) =", gcd(192, 162))A : 192, B : 162
A : 162, B : 30
A : 30, B : 12
A : 12, B : 6
gcd(192, 162) = 62) 재귀 함수 사용의 유의 사항
-
재귀 함수를 잘 활용하면 복잡한 알고리즘을 간결하게 작성할 수 있음
- 단, 오히려 다른 사람이 이해하기 어려운 코드가 될 수도 있음
-
모든 재귀 함수는 반복문을 이용하여 동일한 기능을 구현할 수 있음
-
재귀 함수가 반복문보다 유리한 경우도 있고 불리한 경우도 있음
-
컴퓨터가 함수를 반복적으로 호출하면 컴퓨터 메모리 내부의 스택 프레임에 쌓임
- 그래서 스택을 사용해야 할 때 구현상 스택 라이브러리 대신 재귀 함수를 이용하는 경우가 많음
4. DFS 알고리즘
- 깊이 우선 탐색 : 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘
- 스택 자료구조(혹은 재귀 함수)를 이용
- 구체적인 동작 과정
- 탐색 시작 노드를 스택에 삽입하고 방문 처리를 함
- 스택의 최상단 노드에 방문하지 않은 인접한 노드가 하나라도 있으면 그 노드를 스택에 넣고 방문 처리하고, 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼냄
- 더이상 2번의 과정을 수행할 수 없을 때까지 반복
- 방문 기준 : 번호가 낮은 인접 노드부터 방문
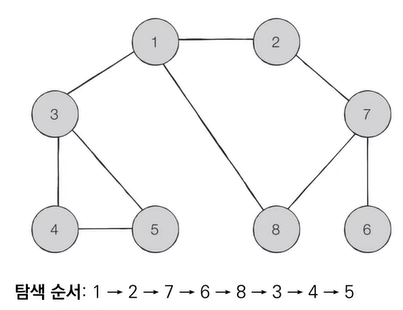
def dfs(graph, v, visited):
# 현재 노드를 방문 처리
visited[v] = True
print(v, end = ' ')
# 현재 노드와 연결된 다른 노드들을 재귀적으로 방문
for i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
# 각 노드가 연결된 정보를 2차원 리스트로 표현
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
# 각 노드가 방문된 정보를 1차원 리스트로 표현
visited = [False] * 9
# 정의된 DFS 함수 호출
dfs(graph, 1, visited)1 2 7 6 8 3 4 5import java.util.*;
public class Main {
public static boolean[] visited = new boolean[9];
public static ArrayList<ArrayList<Integer>> graph = new ArrayList<ArrayList<Integer>>();
// DFS 함수
public static void dfs(int x) {
visited[x] = true; // 현재 노드 방문 처리
System.out.print(x + " ");
// 현재 노드와 연결된 다른 노드를 재귀적으로 방문
for(int i = 0; i < graph.get(x).size(); i++){
int y = graph.get(x).get(i);
if(!visited[y])
dfs(y);
}
}
public static void main(String[] args){
// 그래프 연결된 내용 생략
// dfs(1)
}
}5. BFS 알고리즘
- 너비 우선 탐색 : 그래프에서 가까운 노드부터 우선적으로 탐색하는 알고리즘
- BFS는 큐 자료구조를 이용함
- 구체적인 동작 과정
- 탐색 시작 노드를 큐에 삽입하고 방문 처리를 함
- 큐에서 노드를 꺼낸 뒤 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리함
- 더 이상 2번의 과정을 수행할 수 없을 때까지 반복
- 방문 기준 : 번호가 낮은 인접 노드부터 방문
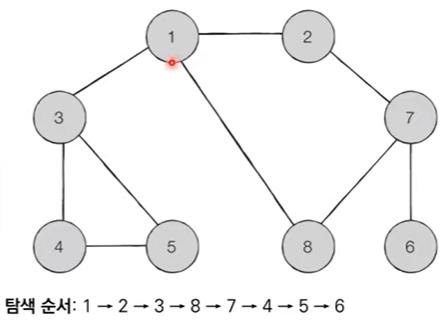
from collections import deque
def bfs(graph, start, visited):
# queue 구현을 위해 deque 라이브러리 사용
queue = deque([start])
# 현재 노드를 방문 처리
visited[start] = True
# 큐가 빌 때까지 반복
while queue:
# 큐에서 하나의 원소를 뽑아 출력
v = queue.popleft()
print(v, end = ' ')
# 아직 방문하지 않은 인접한 원소들을 큐에 삽입
for i in graph[v]:
if not visited[i]:
queue.append(i)
visited[i] = True
# 각 노드가 연결된 정보를 2차원 리스트로 표현
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
# 각 노드가 방문된 정보를 1차원 리스트로 표현
visited = [False] * 9
# 정의된 BFS 함수 호출
bfs(graph, 1, visited) 1 2 3 8 7 4 5 6import java.util.*;
public class Main {
public static boolean[] visited = new boolean[9];
public static ArrayList<ArrayList<Integer>> graph = new ArrayList<ArrayList<Integer>>();
// BFS 함수
public static void dfs(int start) {
Queue<Integer> q = new LinkedList<>();
q.offer(start);
visited[start] = true; // 현재 노드 방문 처리
while(!q.isEmpty()){ // 큐가 빌 때까지 반복
int x = q.poll();
System.out.print(x + " ");
for(int i = 0; i < graph.get(x).size(); i++){
int y = graph.get(x).get(i);
if (!visited[y]){
q.offer(y);
vivisted[y] = true;
}
}
}
}
// 메인 함수 생략
}
Backend development