참고 : SQL튜닝 방법론
ORACLE Select 쿼리 튜닝 순서
튜닝 프로젝트에 투입되었다고 가정하고, 성능이 느린 Select문 하나를 받았을 때 튜닝을 어떻게 해야 하는지에 대해서만 설명
1. 적절한 인덱스를 사용하여 Block I/O를 최소화 하라
- I/O 효율화 원리
1. 라이브러리 캐시 최적화
2. 데이터베이스 Call 최소화
3. I/O 효율화 및 버퍼캐시 최적화- 위의 세 가지 다 중요하지만 그 중 가장 중요한 것을 꼽으라면 세번째라고 말할 수 있다.
- 앞쪽 두가지 튜닝 요소는, 핵심 원리만 이해하고 몇 가지 튜닝 기법만 잘 숙지하면 누구나 쉽게 적용할 수 있는 것들이다.
그러나 I/O 효율화를 달성하기는 쉽지 않은데다 장기간 훈련이 필요하다.- I/O 효율화 튜닝을 잘하려면 인덱스 원리, 조인 원리, 옵티마이저 원리에 대한 이해가 필수적이다.
그리고 이를 바탕으로 실전에서 고급 SQL 활용을 통해 문제 해결 경험을 많이 쌓아야만 한다.
- 오라클을 포함한 모든 DBMS에서 I/O는 블록(다른 DBMS에서는 주로 페이지(page)라는 용어를 사용) 단위로 이루어진다.
- 블록 단위로 I/O를 한다는 것은, 하나의 레코드에서 하나의 컬럼만을 읽으려 할 때도 레코드가 속한 블록 전체를 읽게 됨을 뜻한다.
- Sequential 액세스 : 하나의 블록을 액세스해서 그 안에 저장돼 있는 모든 레코드를 순차적으로 읽어들이는 것.
- 무거운 디스크 I/O를 수반하더라도 비효율은 없다.- Random 액세스 : 레코드 하나를 읽으려고 블록을 통째로 액세스 하는 것.
메모리 버퍼에서 읽더라도 비효율이 존재함.
블록 단위 I/O 원리 때문에 아래 세 쿼리를 처리할 때 서버에서 발생하는 I/O 측면에서의 일량은 같다.
이것은 실행계획이 같을 때이고, 실행 계획이 같더라도 네트워크를 통해 클라이언트에 전송되는 일량에는 차이가 남
조인이 없는 경우는 적절한 인덱스를 사용하는 것 만으로도 상당한 효과를 볼 수 있다. 조인이 있는 경우는 특히 Driving(선행) 집합에 신경을 써야 한다. 왜냐하면 Nested Loop 조인을 사용했고, 선행집합의 건수가 많다면, 후행집합의 조인의 시도횟수가 증가하므로 성능이 느려진다.
따라서 적절한 인덱스를 이용하여 선행집합의 건수를 줄인다면, 혹은 가장 적은 집합을 선행으로 놓는다면, 후행집합으로의 조인건수는 줄어든다. 물론 이때에도 후행집합의 적절한 인덱스는 필수 조건이다. Driving 집합의 Block I/O를 줄이기 위하여 최적화된 인덱스가 없다면 생성하고, 있다면 그것을 사용하라. 다시 말해 최적의 Access Path를 만들어라.
- 즉 전부 다 가져오지말고 where 절에서 시간,혹은 어떠한 조건으로 일정 테이블만 들고올수 있다면 들고오라는 뜻
운영중인 시스템이라면 최적의 Access Path를 위해 인덱스를 변경하거나 생성할 때는 주의해야 한다. 현재 튜닝하고 있는 SQL에 최적화된 인덱스를 생성하더라도 다른 SQL에 악영향을 줄 수 있기 때문이다. (단순히 조회할때는 크게 신경쓰지 않아도 되는듯 하다.) 인덱스를 생성하거나 변경할 때는 그 테이블을 사용하는 다른 SQL의 실행계획이 변경되지 않는지 각별히 신경을 써야 한다. 이런 이유 때문에 개발과정에서 효율적인 인덱스 설계가 중요시 된다.
2. 조인방법과 조인순서를 최적화 하라
온라인에서 사용하는 Select문은 좁은 범위를 검색하는 경우가 많다. 이럴 때는 대부분 Nested Loop Join이 유리하다. 그러므로 조인 건수가 소량인 SQL에 Hash Join이나 Sort Merge Join이 발견되면 Nested Loop Join으로 변경하는 것이 더 유리한지 검토해야 한다. 물론 여기서도 Nested Loop 조인에 관해서만 다룬다.
Nested Loop 조인에서 가장 중요한 것은 조인순서이다.
From절에 테이블(집합)이 두 개라면 후행집합의 관점에서는 적절한 인덱스만 존재한다면 그것으로 족하다.만약 From절에 테이블(집합)이 세 개 이상이라면 조인순서를 변경할 수 있는지에 대한 두 가지 원리를 사용하라.
두 가지 원리는 아래의 단락에서 소개된다. 아무리 조인할 집합이 많다고 하더라도 이 두 가지의 원리는 동일하게 적용될 수 있다. 두 가지 원리를 이용할 때 필요하다면 Leading 힌트를 사용해야 한다.
- 첫 번째, 후행집합에 적절한 인덱스가 없는 경우에 조인순서를 바꾸면, 최적의 인덱스를 사용할 수 있는 경우가 많다. 예컨대, 튜닝전의 조인순서가 Aà B à C 라고 하면, 중간집합인 B에 적절한 인덱스가 없고 오히려 C에 적절한 인덱스가 존재하는 경우가 있다.
이럴 때는 B에 인덱스를 무작정 생성하지 말고, 조인순서를 A à C à B로 바꿀 수 있는지, 바꾸는 것이 더 효율적인지 검증하라. 조인순서만 바꾸어 주어도 일량이 획기적으로 줄어드는 경우가 많다. 만약 조인순서를 바꿀 수 없거나, C를 중간집합으로 하는 것이 비효율적이라면, B를 중간집합으로 유지하고 적절한 인덱스를 사용해야 한다.
- 두 번째, 조인되는 집합 중 특정 인덱스에서 Block I/O가 증가하는 경우에 조인순서의 변경을 검토하라. 이때 10046 Trace나 DBMS_XPLAN.Display_Corsor를 이용하면 조인집합들의 Block I/O량을 관찰할 수 있다.
예를 들어, 튜닝전의 조인순서가 Aà B à C 라고 하고, 집합 B에서 Block I/O량이 증가하면 A à C à B로 바꾸면 일량이 줄어드는 경우가 많다. C를 먼저 조인(Filter)하여 선행집합(B의 입장에서는 C가 선행이다)의 건수를 줄이고 B에 조인하면 성능이 향상된다.
3. Table Access(Random Access)를 최소화 하라
Random Access란 rowid(로우아이디)로 테이블을 엑세스하는 것을 말한다. 1번과 2번을 최적화 했다면 Random Access도 자동으로 많이 줄어들었을 것이다. 하지만 그것이 끝은 아니다. 여전히 성능이 만족스럽지 못하다면 Random Access 횟수를 줄이는 것을 간과해서는 안 된다.
인덱스를 사용하면 rowid가 자동으로 획득된다.(로우아이디를 기반으로 인덱스를 만드니까) 만약 인덱스에 없는 컬럼을 Select 해야 한다면 rowid로 테이블을 엑세스 해야 한다. 이때 테이블로 엑세스 해야 할 건수가 많고, 인덱스의 컬럼순으로 테이블이 sort되어있지 않다면 성능이 매우 저하된다. 왜냐하면 테이블이 인덱스 기준으로 sort되어 있지 않기 때문에 테이블을 방문할 때마다 서로 다른 블럭을 읽어야 하기 때문이다.
-
비유적으로 설명해보자. 우리가 심부름을 할 때 세 군대의 상점(A,B,C)을 들러야 한다고 치자. 그 상점들이 모두 한 건물 내부에 존재한다면 얼마나 좋겠는가? 그 심부름은 매우 빠른 시간에 끝날 것이다. 하지만 반대로 상점 A는 부산에 있고 상점 B는 대구에 있고, 상점 C는 서울에 있다면? 만약 당신의 성격이 매우 좋아서 그 심부름을 한다고 해도 시간이 많이 걸릴 것이다.
-
Random Access도 마찬가지이다. 인덱스의 rowid로 테이블(상점)을 방문할 때, 테이블이 인덱스 기준으로 sort되어 상점처럼 다닥다닥 붙어있다면 성능은 매우 빠르고, 흩어져 있을수록 성능이 느려진다.
(오라클에서는 테이블이 인덱스 기준으로 sort 되어 있는 정도를 Clustering Factor라고 한다.) -
바로 이런 이유 때문에 index scan보다는 Table Scan이 느린 것이다. 따라서 우리는 Random Access의 부하를 최소화 해야 한다.
- Random Access의 부하를 줄이는 방법은 네 가지이다.
- 첫 번째, 테이블의 종류를 변경하는 방법이다. IOT나 클러스터를 이용하면 Clustering Factor가 극단적으로 좋아진다. 또한 파티션을 이용하면 같은 범위의 데이터를 밀집시킬 수 있다.
- 두 번째, 효율적인 인덱스를 사용하거나 조인방법과 순서를 조정하여 Table Access를 최소화 하는 방법이다. 이 방법은 1번과 2번에서 이미 설명 되었다.
- 세 번째, 인덱스에 컬럼을 추가하여 Table Access를 방지하는 방법이다.
예를 들어 Select절의 특정 컬럼 때문에 테이블이 엑세스 된다면, 인덱스의 마지막에 그 컬럼을 추가하면 된다. - 네 번째, 인덱스만 엑세스 하고 테이블로의 엑세스는 모든 조인을 끝내고 마지막에 시도하여 Random Access의 횟수를 줄이는 방법이다. 해당 글을 참조하라.
4. Sort나 Hash 작업을 최소화 하라
1,2,3번을 통하여 최적의 Access Path와 Join을 사용했다면, Block I/O의 관점에서는 튜닝이 끝난 것이다. 하지만 1,2,3번이 모두 해결되었다 해도 Order by나 Group By 때문에 성능이 저하 될 수 있다. 특히 결과가 많은 경우, sort는 치명적이다.
- 인덱스가 sort 되어있다는 특성을 이용하면 order by 작업을 대신할 수 있다.
- Group By도 sort 가 발생하는데 group by 단위와 인덱스의 컬럼이 동일 하다면 sort는 발생하지 않는다.
- 최적의 인덱스를 사용하면 Access Path를 개선하는 효과뿐만 아니라 Sort의 부하도 없어진다.
Union All을 제외한 집합연산(Union, Minus, Intersect)를 사용하면 Sort Unique 혹은 Hash Unique가 발생한다.
1. Union은 Union All로 바꿀 수 없는지 검토해야 하고,
2. Minus는 Not Exists 서브쿼리 혹은 not in을 이용하여 Anti Join으로 바꿀 수 없는지 고려해야 한다.
3. Intersect는 교집합이므로 조인으로 바꿀 수 있는지 검토해야 한다.
4. 아주 가끔 Distinct를 사용한 SQL이 눈에 뛰는데 이 또한 Sort Unique 혹은 Hash Unique를 발생시킨다. 모델러나 설계자에게 문의하여 Distinct를 제거할 방법이 없는지 문의해야 한다.
(키값이라면 중복되는건지 아닌지 확인해본다)
Oracle 10g부터는 Hash Group By가 발생할 수 있는데, 이미 적절한 인덱스를 사용하는 경우라면 Hash Group By를 사용할 필요는 없다. 이런 경우 NO_USE_HASH_AGGREGATION 힌트를 사용하면 Sort Group By로 바꿀 수 있다.
이렇게 해주면 실행계획에 “SORT GROUP BY NOSORT” Operation이 발생하며, Sort나 Hashing 작업이 전혀 발생하지 않는다. Group By의 부하를 해결하는 또 하나의 방법은 스칼라 서브쿼리를 사용하는 것이다.

- 조인을 사용하면 Sum 값을 구하기 위해 Group By가 필수적이다. 하지만 스칼라 서브쿼리를 사용하면 Group By를 사용하지 않고도 sum 이나 Min/Max 값을 구할 수 있다.
- 또한 분석함수의 Ranking Family(rank, dens_rank, row_number)를 최적화된 인덱스와 같이 사용하면 Group By나 Sort를 하지 않고도 Min/Max 값을 구할 수 있다. 이때는 실행계획에 “WINDOW NOSORT” Operation이 발생한다. 관련 글을 참조하기 바란다.
5. 한 블록은 한번만 Scan하고 끝내라
같은 데이터를 반복적으로 Scan하는 SQL이 의외로 많다. 대표적인 경우가 Union All로 분리되었지만 실제로는 그럴 필요가 없는 경우이다. 예를 들어 Where 절에 구분코드가 1일 때 , 2일 때, 3일 때 별로 SQL이 나누어져 있는 경우이다.
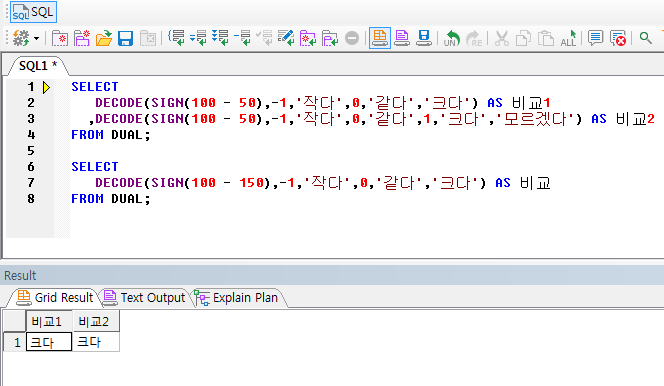
- Where 절을 구분코드 in (1,2,3) 으로 처리하고, Select절에서 Decode나 Case 문을 사용하여 구분코드별로 처리해준다면 Union All은 필요 없다.
- Union All을 사용하는 또 한가지의 경우는 Sub Total(소계)과 Grand Total(총계)를 구해야 하는 경우 이다.
2-1. 이 경우도 Rollup/Cube나 Grouping Sets를 Group By절에 사용한다면 소계나 총계를 위한 별도의 Select문을 실행 시킬 필요는 없다.
- 1~4번의 과정은 SQL문의 변경이 없거나 최소화 된다. 하지만 5번의 경우는 SQL을 통합시켜야 하기 때문에 시간이 많이 소모되며, 많은 사고가 요구되는 창조적인 과정이다. 여기까지 했다면 진행되었다면 원본 SQL 자체의 튜닝은 완료 된 셈이다.
6. 온라인의 조회 화면이라면 페이징처리는 필수이다
부분범위 처리를 해야 한다. 물론 전체 건을 처리해야 하는 경우는 있을 것이다. 하지만 조회화면이라면 몇 십만 건 혹은 몇 만 건이나 되는 결과를 모두 볼 수 없다. 따라서 볼 수 있는 단위로 끊어서 출력해야 한다.
예를 들어 결과 건수가 10만 건이라고 해도 최초의 50건을 화면에 먼저 뿌린다면 1,2,3,4 번에서 설명했던 모든 부하(Block I/O의 부하, 조인의 부하, Random Access의 부하, Sort의 부하)를 한꺼번에 감소시킬 수 있다. 따라서 가능하면 개발자를 설득하거나 책임자를 설득하여 페이징 처리를 하는 것이 바람직하다.
페이징 처리를 해도 효과를 볼 수 없는 몇 가지 예외가 있다. 분석함수를 사용하거나, Connect By + Start With를 사용한다면 페이징 처리의 효과는 없다. 분석함수의 경우 인라인뷰의 외부로 뺄 수 있다면 부분범위 처리가 가능하다. 이에 관해서는 해당 글을 참조하기 바란다. Connect By + Start With를 사용한 경우는 부분범위처리가 불가능하다. 하지만 11g R2의 신기능인 Recursive With절을 사용한다면 페이징 처리의 효과를 볼 수 있다. 이때, Recursive With절에 Search절(Order By절과 같은 기능)을 사용한다면 Connect By와 마찬가지로 페이징 처리의 효과가 없으니 주의해야 한다. 즉 인덱스의 구성을 적절히 하여 Sort를 대신해야 한다. Recursive With가 무엇인지 궁금한 사람은 관련 글을 참조하기 바란다.
7. 답이 틀리면 안 된다. SQL을 검증하라
7번은 SQL 자체를 튜닝하는 것은 아니다. 하지만 7번을 튜닝 방법에 추가한 이유는 있다. 튜닝을 하였음에도 답이 틀린다면, 튜닝을 하지 않은 것 보다 못하다. 그러므로 튜닝 후에 답이 옳은지 항상 검증해야 한다. 1번~ 7번 중에 가장 중요한 것이 7번이다.
방법론 정리
-
적절한 인덱스를 사용하여 Block I/O를 최소화 하라. -
조인방법과 조인순서를 최적화 하라. -
Table Access(Random Access)를 최소화 하라 -
Sort나 Hash 작업을 최소화 하라 -
한 블록은 한번만 Scan하고 끝내라 -
온라인의 조회화면이라면 페이징처리는 필수이다 -
답이 틀리면 안 된다. SQL을 검증하라
방법론의 의미
만약 1~7번을 모두 적용할 수 있는 경우임에도 불구하고 하나라도 빠진다면 그것은 최적화된 SQL이 아니다. 물론 튜닝을 할 때 위의 1~6번을 항상 적용할 수 있는 것은 아니다. 경우에 따라서는 하나만 적용될 수도 있고, 두 개만 적용할 수 있는 SQL도 있다. 하지만 1~6번을 모두 적용할 수 있는지 꼼꼼히 살펴야 한다.
출처: https://scidb.tistory.com/entry/SQL튜닝-방법론 [Science of Database]
