

나에게 주어진 첫번째 과제 - '우리팀에서 사용할 코드 컨벤션을 지정하는 것'
- 위 짤 처럼 되지 않기 위해서 다른 자료를 참고해 내가 잘할수 있게 + 다른사람이 알아보기 편하게 + 최대한 기존 코드들을 수정하기 쉽게 만들었다. (파이썬도 마찬가지)
SQL
General
General
- SQL 코드 - 주석 가능하면 /를 닫고 /를 닫습니다. 그렇지 않으면 주석 앞에 '--' 를 붙이고 간결하게 끝냅니다
/* Updating the file record after writing to the file */
UPDATE file_system
SET file_modified_date = '1980-02-22 13:19:01.00000',
file_size = 209732
WHERE file_name = '.vimrc';- ISO 8601 호환 시간 및 날짜 정보를 저장하는것을 기본으로 합니다. (
YYYY-MM-DD HH:MM:SS.SSSSS). - SELECT 문에는 필요한 컬럼만 가지고 옵니다.
- 가능한 조건 컬럼에는 별도의 연산을 걸지 않는것이 좋습니다.
- `WHERE date(cust_date) ='0000-00-00' 보다
WHERE cust_date between '2012-03-11 00:00:00' and '2012-05-11 23:59:00'이 더 낫습니다. → 연산이 더 적어짐
1. WHERE SUBSTR(EMPNAME,1,5) = 'david' -> WHERE EMPNAME LIKE 'david%'
2. WHERE EMPNAME||DEPTNAME = 'DAVIDSERVICE' -> WHERE EMPNAME = 'DAVID' AND DEPTNAME = 'SERVICE'
3. WHERE SAL + 1000 < 2000 -> WHERE SAL < 1000피해야 하는것

- CamelCase : 단어가 합쳐진 부분마다 맨 처음 글자를 대문자로 표기하는 방법 (ex,FaceBook)
- 처음 글자를 대문자로 표현하는 카멜 법과는 다릅니다.
- 복수형인지 파악하기 어려운 단어사용 - 자연스러운 집합 용어를 대신 사용합니다. 예를 들어
staff대신employees또는people대신individuals. - 객체 지향 설계 원칙은 SQL이나 데이터베이스 구조에 적용 되어서는 안 됩니다.
Naming conventions
General
- 이름이 고유하고 예약된 키워드 로 존재하지 않는지 확인하십시오 .
- 이름에는 문자, 숫자 및 밑줄만 사용하십시오.
- 이름은 문자로 시작해야 하며 밑줄로 끝날 수 없습니다.
- 길이를 최대 30바이트로 유지하십시오. 다중 바이트 문자 집합을 사용하지 않는 한 실제로는 30자입니다.
- 여러 개의 연속 밑줄을 사용하지 마십시오. 이는 읽기 어려울 수 있습니다.
- 약어를 피하고(?) 사용해야 하는 경우 일반적으로 이해할 수 있는지 확인하십시오.
테이블
- 테이블에 열 중 하나와 동일한 이름을 지정하지 마십시오. 그 반대의 경우도 마찬가지입니다.
- 가능하면 두 개의 테이블 이름을 연결하여 관계 테이블(JOIN 후의 테이블)의 이름을 생성하지 마십시오.
- services 로 명명 (cars_mechanics X)
열
- 항상 단수 이름을 사용하십시오.
- 고유 명사와 같이 적절하지 않은 경우를 제외하고는 항상 소문자를 사용하십시오.
date또는month열 이름 과 같은 키워드를 사용하지 마십시오 .- 선택하는 컬럼이 길어지는 경우에는 열을 바꾸고 , 를 작성합니다.
SELECT column1,
column2,
column3
FROM tablealiasing 또는 correlations
- aliasing하는 개체 또는 표현식과 어떤 식으로든 관련되어야 합니다.
- 항상
AS키워드를 포함하십시오. 명시적이므로 읽기 쉽습니다. - 이름은 개체 이름에 있는 각 단어의 첫 글자를 사용합니다. (card_info 라면 c)
- 동일한 이름과 이미 상관 관계가 있는 경우 번호를 추가합니다.
- (
card_info 가 있는데 card_cust 가 나타나는 경우 각각 ci cc)date_details.fiscal_quarter 라면 각각 dd fq
- (
- 계산된 데이터(
SUM(),AVG()등)의 경우 스키마에 정의된 열인 경우 지정한 이름을 사용합니다.
SELECT first_name AS fn
FROM staff AS s1
JOIN students AS s2
ON s2.mentor_id = s1.staff_num;
Query syntax
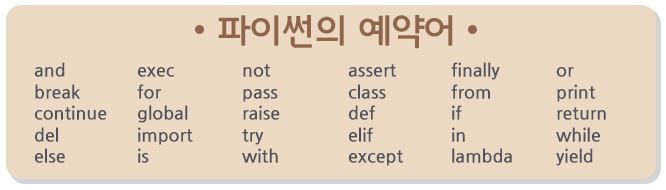
Reserved words 예약어
- 항상 대문자를 사용 (SELECT FROM WHERE)
- Dbeaver 자동 대문자 세팅 참고 (LINK)
- 축약된 키워드를 피하고 가능한 경우 전체 길이의 키워드를 사용하는 것이 가장 좋습니다(
ABSOLUTE)ABS.
White space 여백
- 코드를 읽기 쉽게 하려면 올바른 간격 보완을 사용하는 것이 중요합니다. 코드를 복잡하게 만들거나 자연어 공간을 제거하지 마십시오.
- 코드를 정렬하는 데 공백을 사용합니다.
- ( = ) 같음 표시 전후로 공백을 사용합니다.
- 선택하는 컬럼을 붙여서 써야하는 경우가 있다면 ( , ) 쉼표 뒤에 공백을 사용합니다.
- apostrophes (
') 로 둘러쌓는 경우에 공백을 사용합니다.
SELECT a.title, a.release_date, a.recording_date
FROM albums AS a
WHERE a.title = 'Charcoal Lane'
OR a.title = 'The New Danger';
줄 간격
AND또는OR사용시에 줄바꿈/ 세로 공백을 포함합니다.- 더 쉽게 읽을 수 있도록 쿼리를 구분하기 위해 세미콜론( ; ) 뒤에 줄바꿈 혹은 세로 공백을 포함합니다.
- 각 키워드 정의 후 줄바꿈/ 세로 공백을 포함합니다.
INSERT INTO albums (title, release_date, recording_date)
VALUES ('Charcoal Lane', '1990-01-01 01:01:01.00000', '1990-01-01 01:01:01.00000'),
('The New Danger', '2008-01-01 01:01:01.00000', '1990-01-01 01:01:01.00000');- 여러 열을 논리 그룹으로 구분할 때 쉼표 뒤에 세미콜론 뒤에 줄바꿈/ 세로 공백을 포함합니다.
들여 쓰기
JOIN
- 테이블 끼리 구분할수 있게 FROM 절 뒤에 JOIN을 사용하는 경우에 들여써서 사용합니다.
- 한번 더 JOIN이 필요한 경우 새 줄로 그룹화해야 합니다.
SELECT r.last_name
FROM riders AS r
INNER JOIN bikes AS b
ON r.bike_vin_num = b.vin_num
AND b.engine_tally > 2
INNER JOIN crew AS c
ON r.crew_chief_last_name = c.last_name
AND c.chief = 'Y';하위 쿼리
- 계층구조를 확인할수 있게 들여쓰기 합니다.
- 어떠한 식을 활용하여 컬럼을 새로 생성하는 경우 다른 컬럼의 위치와 동일하게 설정합니다.
SELECT r.last_name,
(SELECT Max(Year(championship_date))
FROM champions AS c
WHERE c.last_name = r.last_name
AND c.confirmed = 'Y') AS last_championship_year
FROM riders AS r
WHERE r.last_name IN (SELECT c.last_name
FROM champions AS c
WHERE Year(championship_date) > '2008'
AND c.confirmed = 'Y');
공통 테이블 표현식(CTE)
- 공통 쿼리는 WITH문을 사용하여 통합하여 사용합니다.
- CTE를 사용하여 다른 테이블을 참조하십시오.
- CTE는 쿼리 맨 위에 배치해야 합니다.
- 성능이 허용되는 경우 CTE는 단일 논리적 작업 단위를 수행해야 합니다.
- CTE 이름은 명확하면서도 가능한 간결해야 합니다.
- 긴 이름은 피하고
replace_sfdc_account_id_with_master_record_id - CTE에 주석이 있는 짧은 이름을 선호합니다.
- 긴 이름은 피하고
- 혼란스럽거나 주목할만한 논리가 있는 CTE는 파일에 주석을 달고 dbt 문서에 문서화해야 합니다.
선호하는 형식 (수정필요)
AND로 결합하는 것 대신 가능하다면 BETWEEN 을 사용합니다.- OR대신 IN 을 사용합니다.
UNION 절과 temporary table 을 가능하면 사용하지 않습니다.- Prefer
!=to<> PreferLOWER(column) LIKE '%match%'tocolumn ILIKE '%Match%'- Prefer
WHEREtoHAVING(둘 다 가능하다면) - 명시적 날짜 함수를 선호합니다
extract < **date_part** ~~Sub-query보다CTE를 선호 합니다 .~~~~UNION ALL보다Window Function을 선호합니다.~~~~CASE문보다IF문을 선호합니다. (한줄에서만)~~- DISTINCT, UNION 과 같은 중복 값을 제거하는 함수를 최소화 합니다.
- 데이터양이 많을 수록 중복값을 제거하기 위한 함수를 사용하면 연산의 시간이 많이 걸립니다.
- DISTINCT 를 사용하기 보다는 EXISTS 를 사용하는 방법이 있고, 불가피하게 사용해야 한다면, 테이블의 크기, 데이터량을 최소화 하는 것이 좋습니다.
SELECT DISTINCT A.deptname
FROM dept A,
emp B
WHERE A.deptno = B.deptno
SELECT A.deptname
FROM dept A
WHERE EXISTS (SELECT 1
FROM emp B
WHERE A.deptno = e.deptno)빠른수정 (Instant SQL Formatter)
https://www.dpriver.com/pp/sqlformat.htm
여기서
| Output: | SQL(html:span) |
|---|---|
| Keywords case | default |
| Table name case | default |
| Column name case: | default |
| Function case | default |
| Datatype case | default |
| Variable case | default |
| Alias case | default |
| Quoted identifier case | default |
| Other identifier case | default |
Linebreaks with comma: Before
List and Parameters Style: Stacked
Stacked align: Align left
Max length per line in compact mode: 80
레퍼런스
https://about.gitlab.com/handbook/business-technology/data-team/platform/sql-style-guide/

data analyst