
Dynamic Programming
- 퍼펙트한 모델에서 optimal policies 을 계산을 하는데 사용되는 알고리즘의 집합이다.
- RL에 쓰는 방법의 이해의 기초
→ less computation으로 하거나 perfect model of the environment이 아닌 곳에서 하는
Key idea of DP?
-
value func을 이용해 좋은 정책을 찾아나가는 것
-
optimal value functions을 찾으면 optimal policies 도 잘 찾을 수 있다.
-
가치 함수가 이렇게 되어 야 할 것 같은데 approximation을 하는데 이것을 update를 해서 계선을 시키다 보면 이것이 결국 policy를 찾아가는 과정이 된다.
-
가치 함수 : 축적 리워드의 기댓값을 최대화시키도록 하면 그게 optimal policy가 된다.
⇒ 가치함수와 액션가치함수를 최대화하는 것이 결국 정책을 최대화 시키는 것이다.
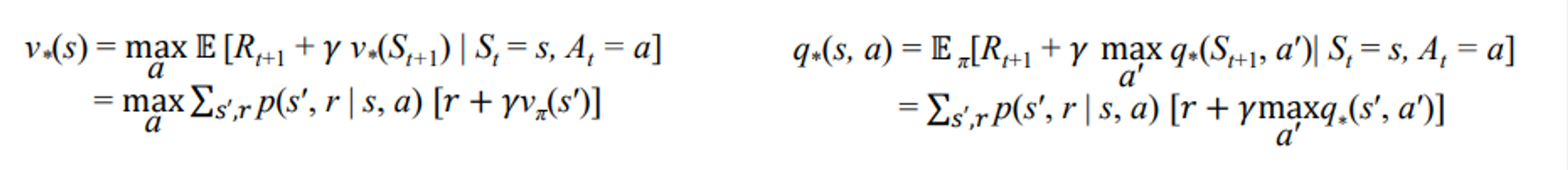
✅ Policy Evaluation = prediction problem
우리가 현재 만들어져 있는 정책대로 행동했을 때 어느정도 좋은 결과물을 얻을 수 있는지 평가할 수 있다면 이전에 가지고 있던 정책의 결과물과 현재 바꾼 정책의 결과물을 정량적으로 비교할 수 있다.
→ 더 좋은 정책을 택함 → 계속 반복 → 최적 정책에 도달
⇒ 이를 위해서 어떤 정책이 좋은 것 인지 평가할 것인지 명확한 정의가 있어야 한다.
What is policy evaluation?
- state-value function v_π
state에 있는 것 만으로도 예상되는 리워드 기댓값
- 현재 state가 정해졌을 때 이 state로부터 앞으로 뻗어 나가서 얻을 수 있는 리워드들의 기댓값
- 정책에 따라 기댓값이 달라질 수 있다.
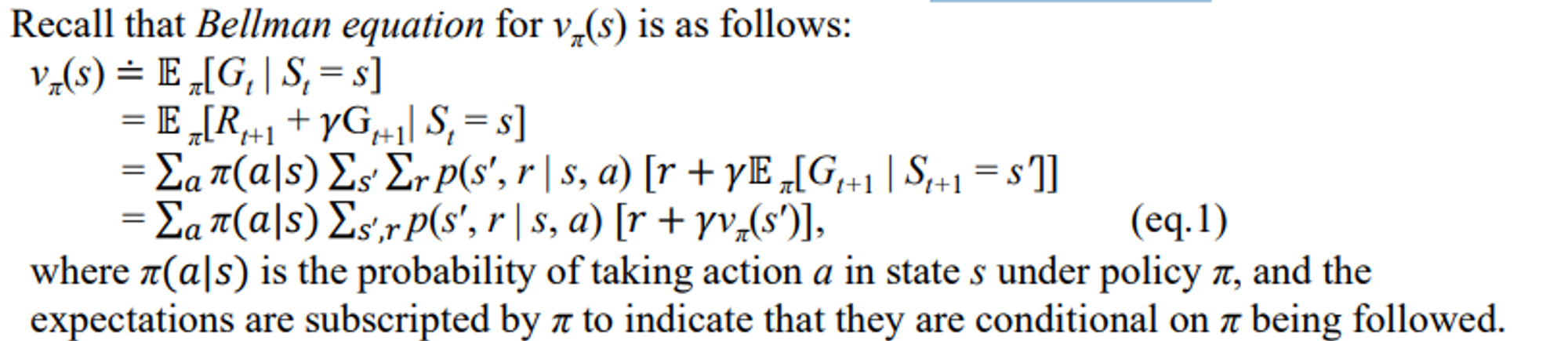
- 만약 모든 것이 온전히 알려져 있다면, 연립방적식을 이용해 풀 수 있다.
- state 에서 다른 state로 가는 과정이 많으면 연립 방정식의 복잡성이 올라간다. 근데 일반적으로 다 복잡하다.
⇒ 연립장적식을 쓰지 않고 iterative하게 풀자. policy를 evaluation할 때 관찰 가능한 부분에 대해서만 evaluation하고 반복되는 과정 속에서 추후 업데이트 한다.
Iterative policy evaluation
앞에서는 가치함수를 구할 때 이후 state를 전부 고려해 확률을 내서 구했다. 이걸 구하려면 전부 다 따라가서 뭐 해야하고 맨 끝까지가서 역으로 계산을 했어야 했다.
반면 여기서는 내 눈앞에 보이는 애들만 반복적으로 수렴할 때까지 계산한다.
Expected update
기댓값 기반의 업데이트
더 이상 안 변할 때까지 업데이트 한다는 것은 operation이 변하지 않다는 것을 의미하낟. v0 v1 v2 를 연속적으로 업데이츠 할 대 파이가 주어졌을 때 state가 어떤 값어치를 갖는 지 찾는다.
- 파이는 평가를 진행하고 있는 와중에 변하지 않는다.
- next state를 samplling하지 않는다
→ s0부터 전이 가능한 것니 s10이다. 샘플링한다는 것은 여기 있는 것 중 몇 개 뽑아서 할게요 이런게 아니고 모두 고려해서 쓰는 것이다.
- 구현을 위해 2개의 array 가 필요하다
⇒ 문제 ) 메모리가 두 배로 든다.
- 다른 방식은 in-place 방식으로 업데이트가 끝나면 바로 그 순간 그 자리에 바로 덮어쓴다.
→ 이미 업데이트 된 것이 사용되지만 상관 없어 그냥 그거 쓸게.
→ 이렇게 한 알고리즘이 수렴하고 대부분의 상황에서 빠르게 수렴하한다.
✅ Policy Improvement
value 함수를 구하는 이유는 policy improvement를 하기 위해서
Find Better Policies
정책을 바꿔서 액션을 선택하는 확률을 바꿔야하는지 알고 싶다.
이 질문에 답을 하기 위해 a를 선택하는 방법을 선택을 한다. 그 다음에 나머지를 파이르 따라 한 다음에 더 좋아졌는지 본다
- 현재 state에서 내가 선택할 수 있는 action을 바꾸어 본다는 것이다.
원래와 조금 다른 방식으로 가보자!
→ 바꾼 action에 대해 평가를 해서 원래보다 좋다면 더 좋은 정책이라 한다.
이 정책을 했을 때 어느정도
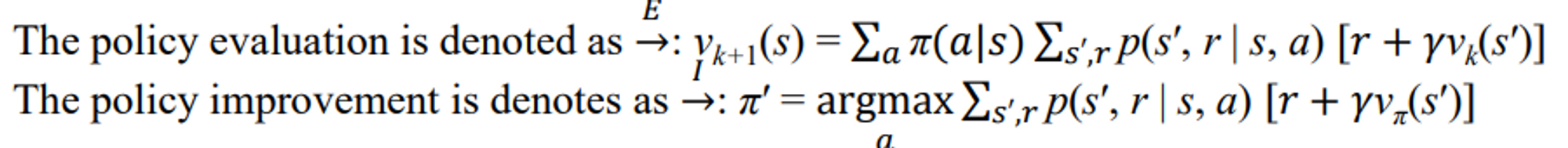
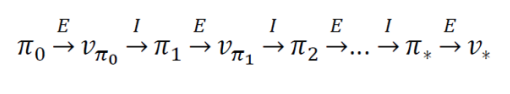
⇒ 이 두가지가 같이 사용되면서 policy iteration
✅ Value Iteration
위 두개 단계를 하나로 섞은 것이다.
현재 상태를 평가를 함에 있어서 가장 극대화할 수 있는 a로 적용
반복 과정을 하나로 합친 것이라 생각하면 된다.
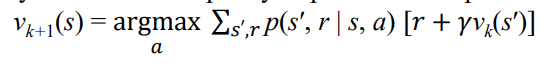
Policy Iteration: iteration이 짧아 빠르게 수렴- 각 iteration이 computationally expensive ( 두 과정이 나눠져 있기 때문)
Value Iteration- 조금 더 iteration이 많이 필요
- 두 과정을 하나로 묶으면서 computational costs 가 적어진다.
✅ Generalized Policy Iteration
이것으로 발전된다
- policy evaluation and policy improvement processes interact를 통해 더 좋은 policy를 찾아가는 과정을 통칭한다.
- 거의 대부분의 RL은 이 GPI로 설명이 가능하다.
- evaluation and improvement processes in GPI can be viewed as both competing and cooperating.
- 최종적 목표 the optimal value function and an optimal policy를 찾아 가기 위해 행해진다.
Granularity
어느 정도의 복잡성을 가지고 할 것인가.
- fine-grained policy evaluation process : value 함수를 엄청 정확하게 찾으려고 하는 것
- coarse-grained policy evaluation process : 정확히 안하고 대충 하려는 것
→ 속도도 빠르고 이터도 적고 빠른 수렴
🖇Reference
이 글은 강형엽 교수님의 게임공학[GE-23-1] 수업을 수강하고 정리한 내용입니다.
[mdpw] https://en.wikipedia.org/wiki/Markov_decision_process
[sutton] Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press
