Review & Case Study
LeNet-5
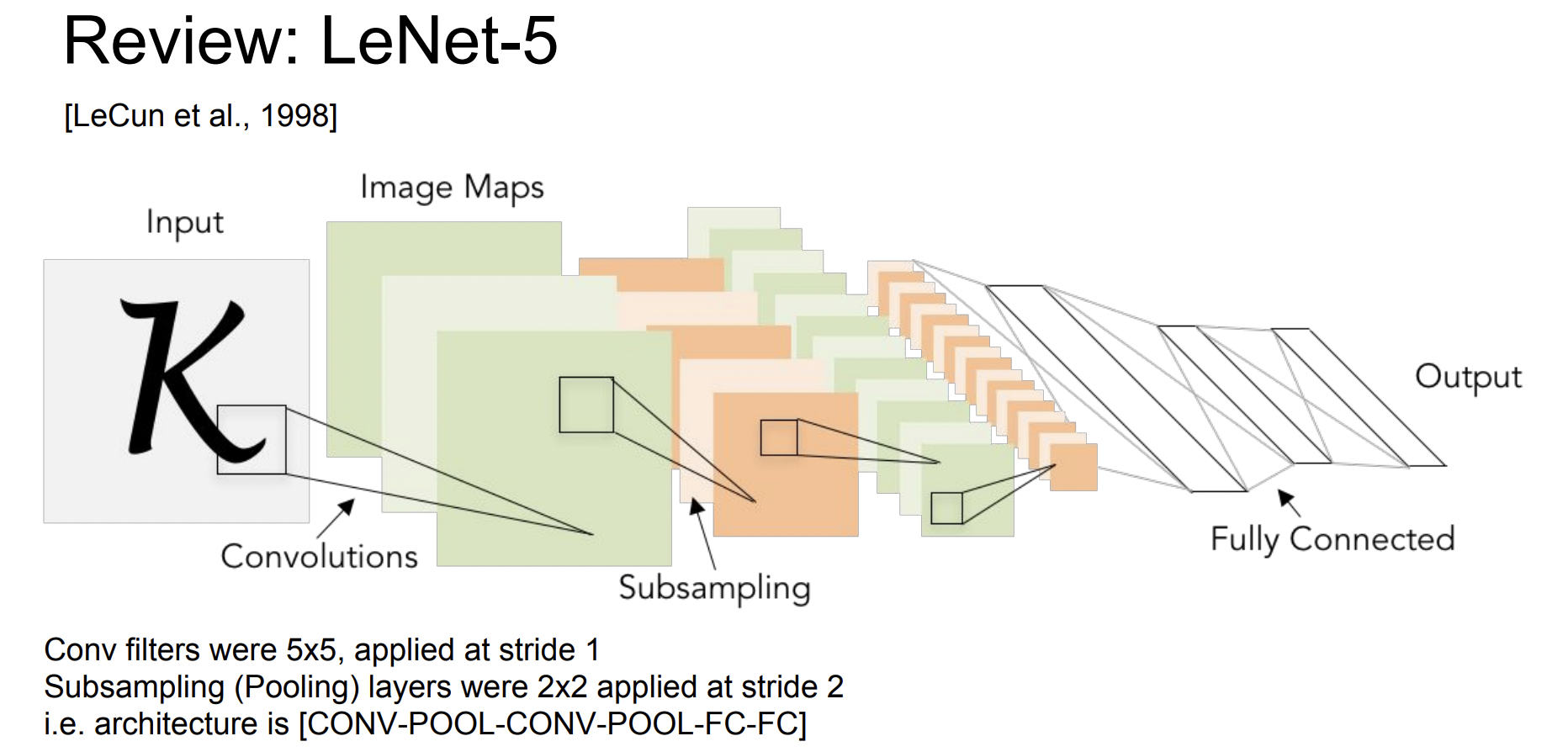
LeNet은 산업에 성공적으로 적용된 최초의 ConvNet이다. 이미지를 입력으로 받아서 stride가 1인 5x5 필터를 거치고 Convolution Layer와 Pooling Layer를 거친다. 그리고 맨 마지막에 FC layer를 통과시켜 Output이 나온다.
매우 간단한 모델이지만, 숫자 인식에서 좋은 성능을 보였다.
AlexNet

AlexNet은 최초의 large scale CNN이다. ImageNet Classification task를 아주 잘 수행했다.
Conv -> pool -> normalization 구조가 반복되는 것이 특징이다.
생긴 것만 보면 LeNet과 유사하지만 Layer의 개수가 더 많아졌다.
ZFNet
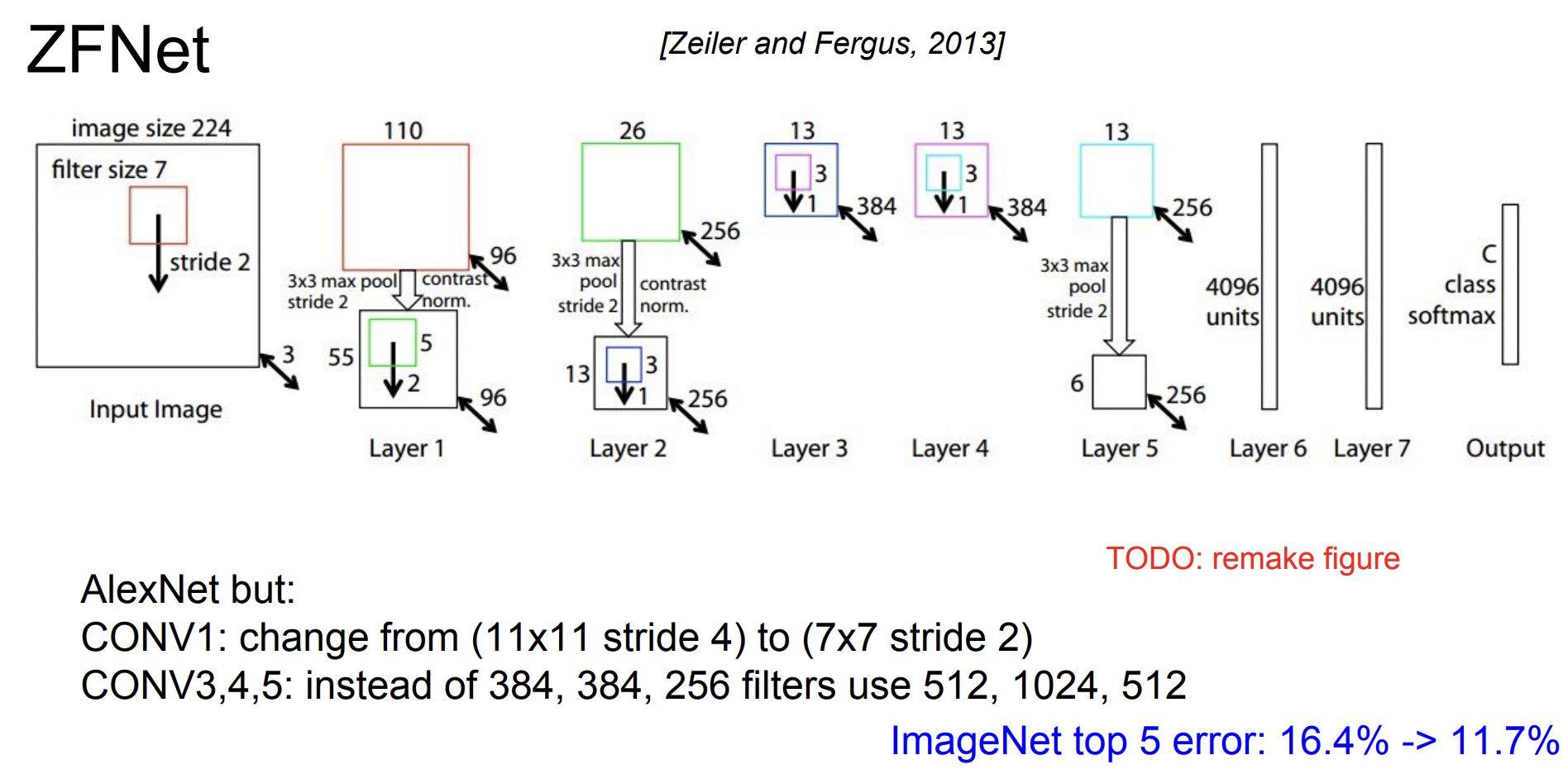
ZFNet은 AlexNet의 하이퍼 파라미터를 개선한 모델이다. AlexNet과 layer의 개수, 구조가 모두 같다. 다만 stride size나 filter의 개수를 조정해 error rate를 개선하였다.
VGGNet
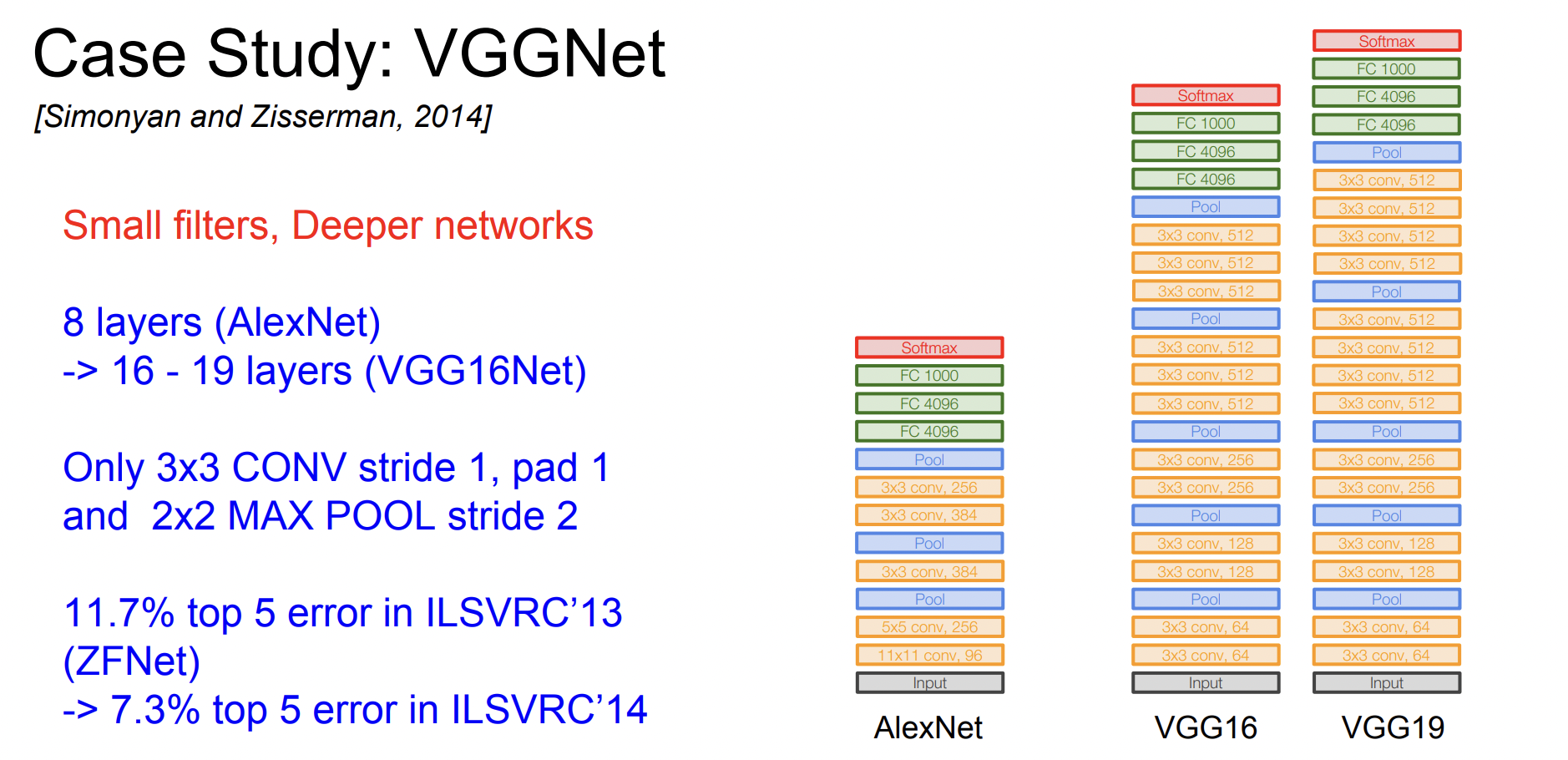
VGGNet은 더 깊어진 네트워크, 더 작은 필터라는 말로 요약할 수 있다. 항상 3x3 필터만 사용하고 주기적으로 pooling을 수행하여 네트워크를 구성한다.
필터의 크기가 작은 이유는 depth를 더 키울 수 있기 때문이다.
GoogLeNet
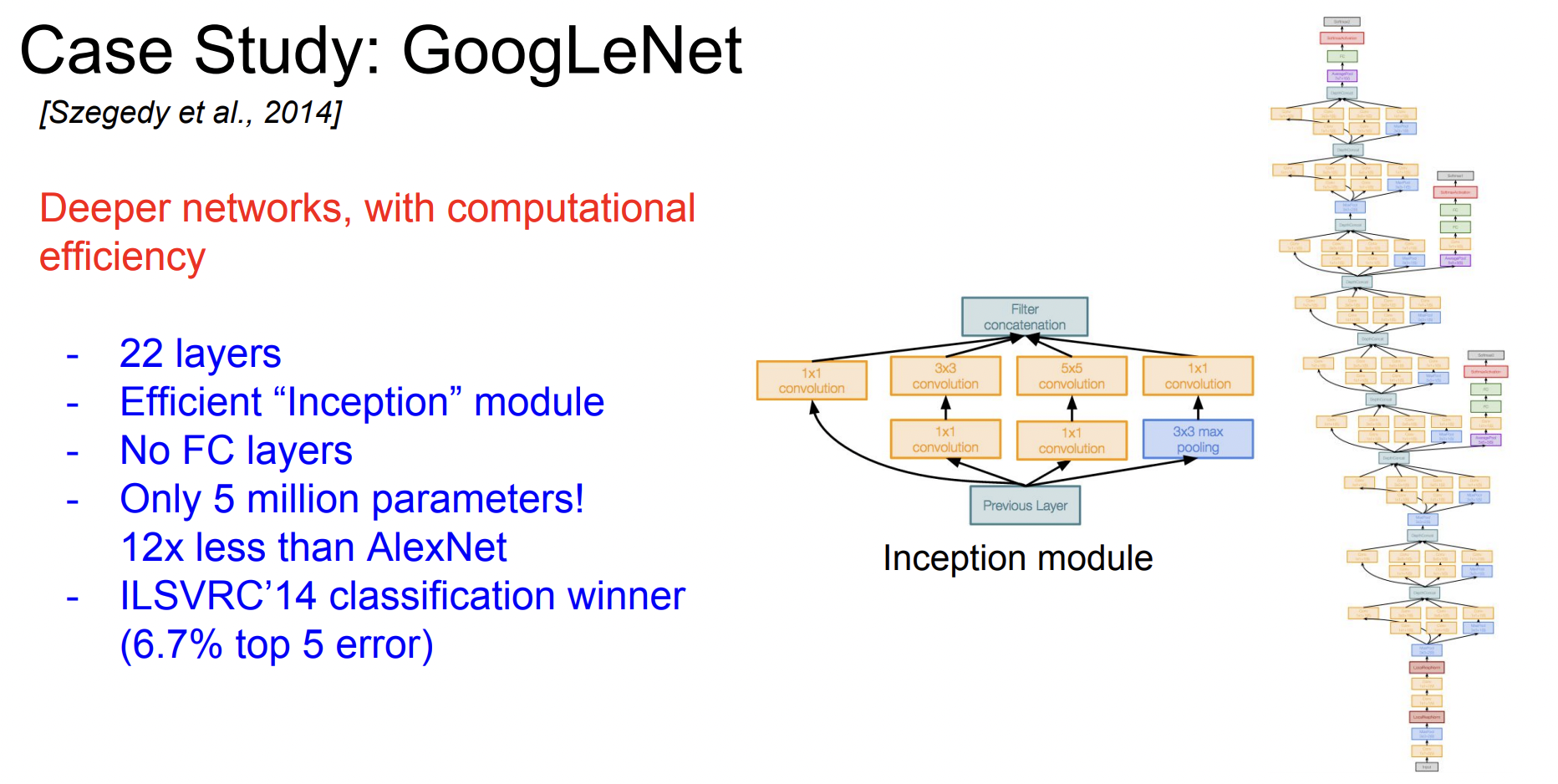
GoogLeNet은 2014년 Classification Challenge에서 우승한 모델이다. 총 22개의 layer를 가지고 있다. 또한 inception module을 사용하고 FC-layer가 없다. 파라미터를 줄이기 위해서이다. 전체 파라미터의 수는 약 5백만개인데, AlexNet보다 적은 것을 알 수 있다.
ResNet
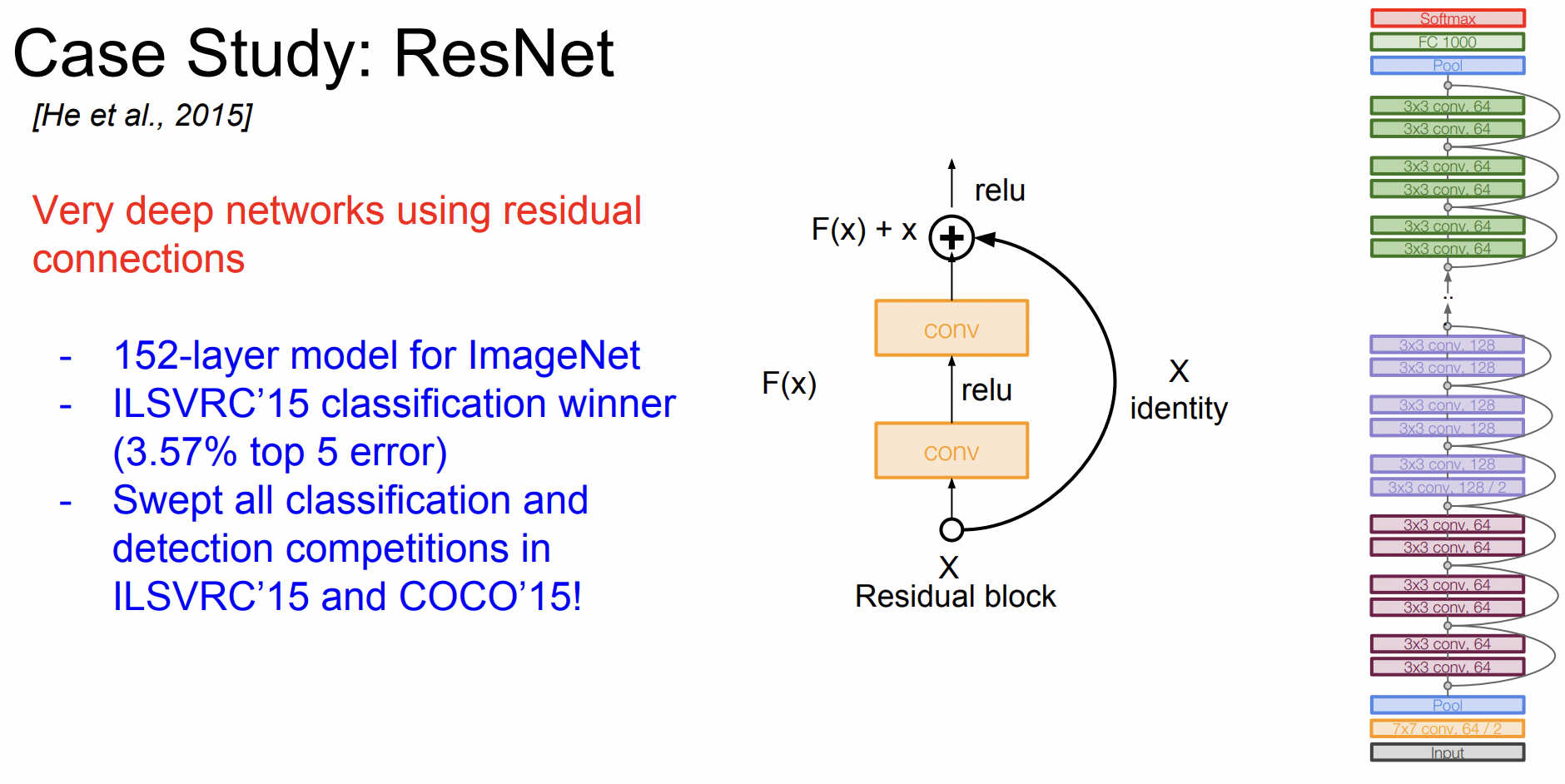
ResNet은 엄청나게 (Very deep) 깊다. 모델을 깊게 쌓기 위해 Residual connection이라는 방법을 사용한다.
일반 CNN을 더 깊게 쌓게 된다고 무조건 성능이 좋아지는 것은 아니다.
56 layer와 20 layer의 test error를 비교해 보면 56 layer가 더 안 좋은 것을 알 수 있다. 따라서 ResNet의 저자들은 모델이 깊어질수록 optimization에 문제가 생긴다는 가설을 세웠다. 그래서 더 얕은 모델의 가중치를 깊은 모델의 일부 레이어에 복사하고, 나머지 layer는 identity mapping을 하였다.
이러한 layer들이 모델에 잘 적용되기 위해 사용한 방법이 바로 Residual mapping인데, 레이어가 H(x)를 학습하지 않고 H(x)-x를 학습한다. 즉 입력 x에 대한 변화량(delta)만 학습하는 것이다.
Comparing complexity
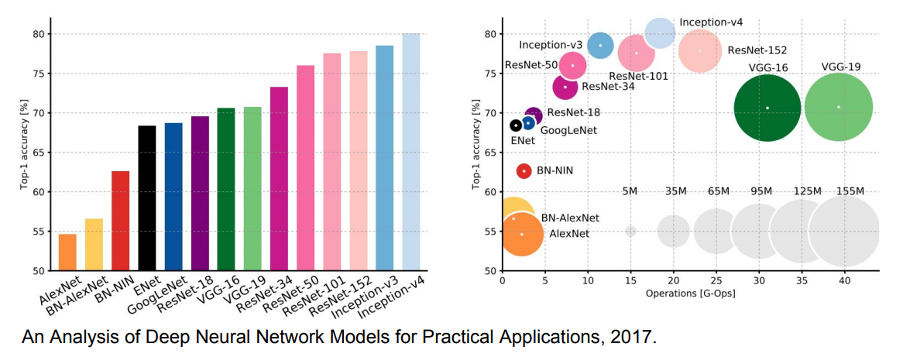
이 사진은 모델별 complexity를 비교해 놓은 그래프이다. GoogLeNet-Inception은 버전별로 여러 가지가 있는데 v4가 가장 좋은 모델인 것을 알 수 있다. 오른쪽은 계산 복잡도가 추가된 그래프이고, 원의 크기는 메모리 사용량이다.
가장 효율적인 네트워크는 GoogLeNet이고, VGGNet은 메모리도 크고 계산량도 많지만 성능이 좋다. 초기 모델인 AlexNet은 accuracy가 매우 낮고 메모리 사용도 비효율적인 것을 알 수 있다.
Other Architectures to know...
Network in Network(NiN)
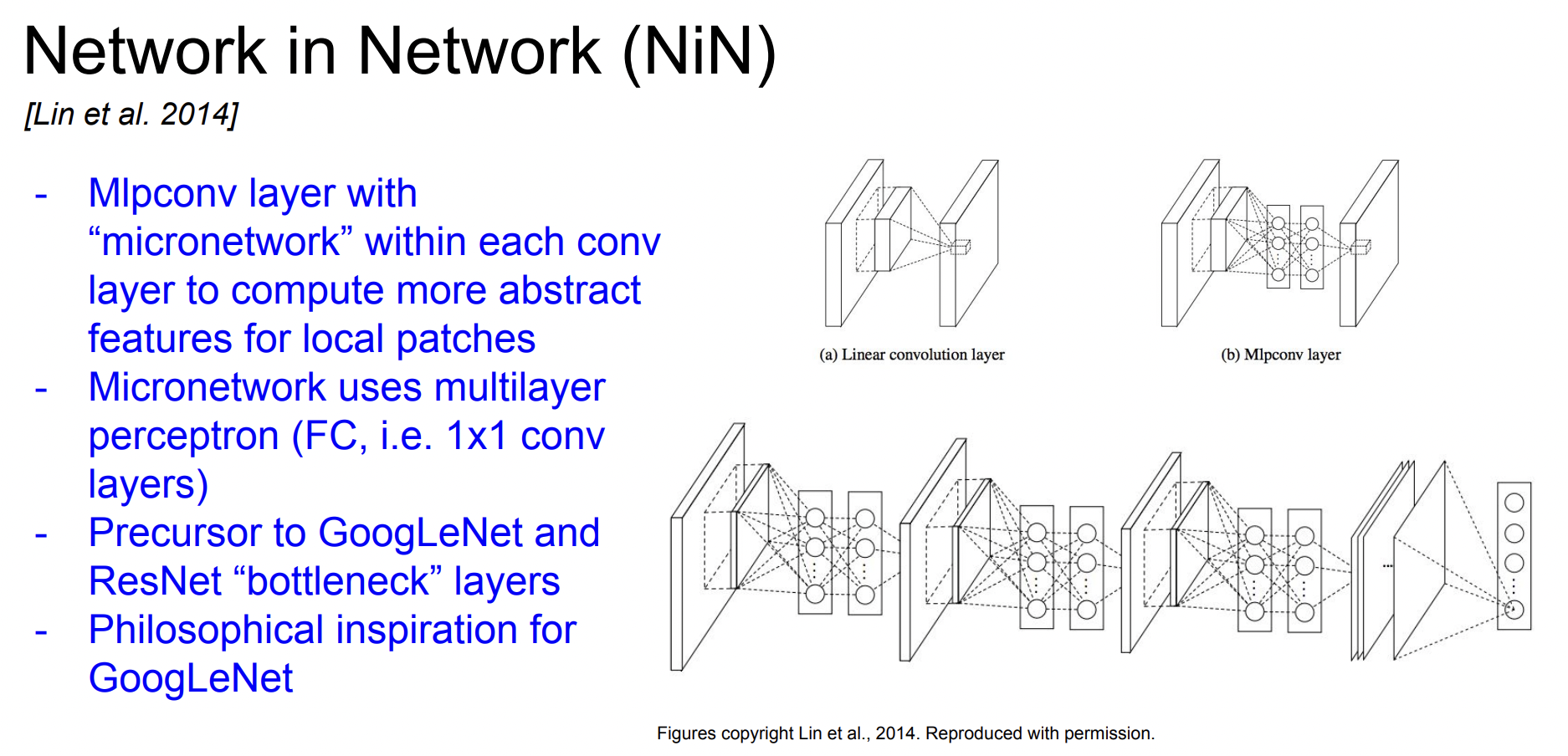
기본적인 아이디어는 MLP conv layer이다. 네트워크 안에 작은 네트워크를 삽입하는 것인데, 각 conv layer 안에 MLP(Multi-Layer Perceptron)을 쌓는다.
FC-layer 몇 개를 쌓는 것과 같다. 단순히 conv filter만 사용하지 않고 조금 더 복잡한 계층을 만들어보자는 아이디어이다.
Improving ResNets...
아래 내용은 전부 ResNet을 발전시키기 위한 시도들이다.
Identity mapping in Deep residual Networks
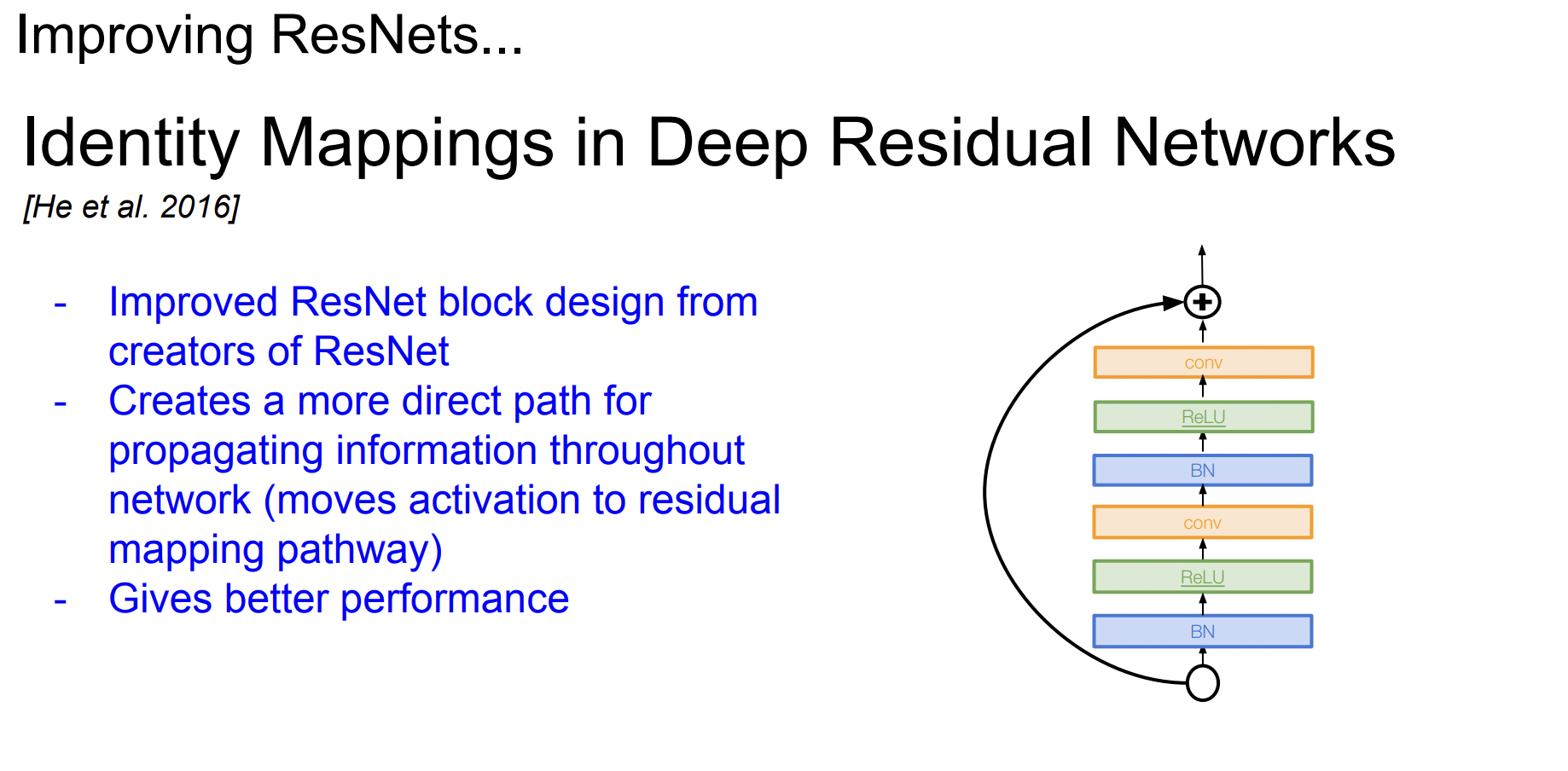
Direct path를 늘려서 정보들이 앞으로 더욱 잘 전달되고 backpropagation도 더 잘 될 수 있게 개선하였다.
Wide residual Networks
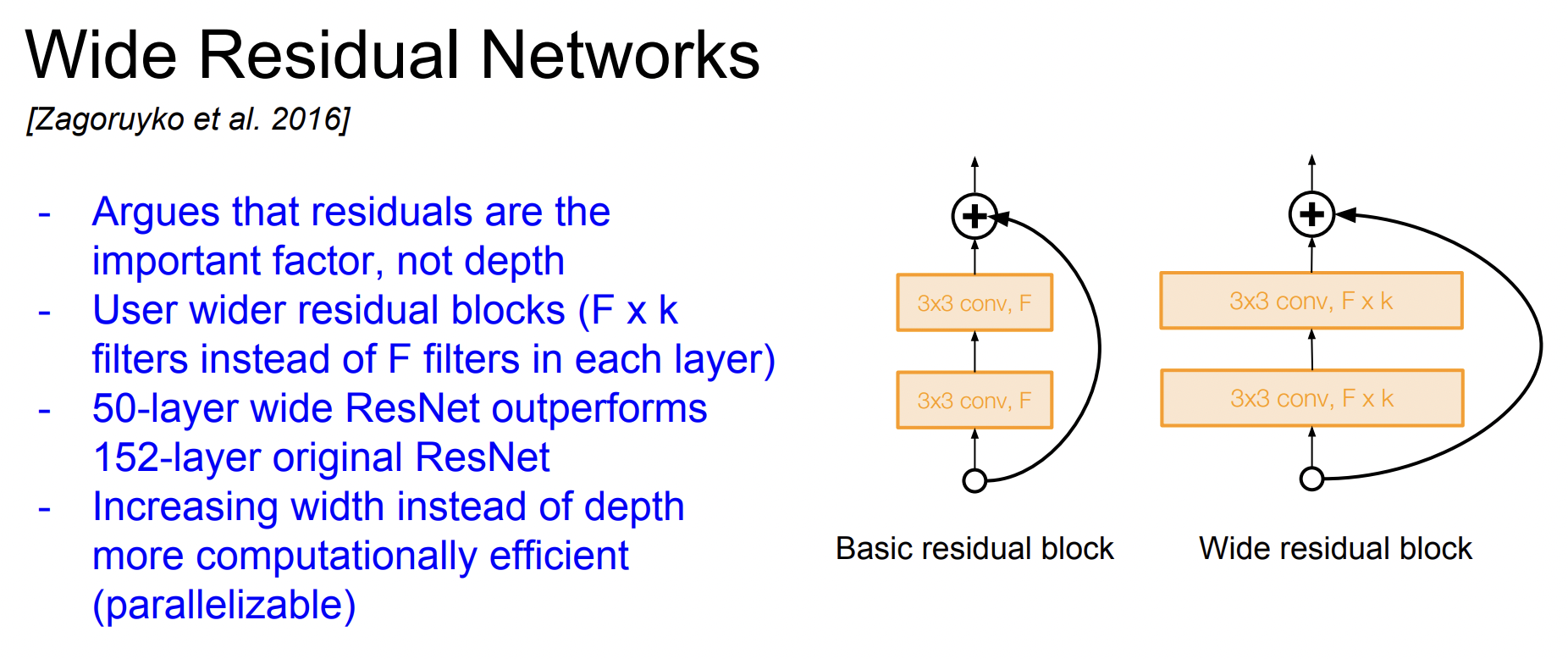
기존의 ResNet은 깊게 쌓는 것에 중점을 두었지만 사실은 depth보다 residual이 더 중요하다고 주장한 연구이다. Residual block을 더 넓게 만들어 conv layer 필터를 더 많이 추가하였다.
기존의 ResNet에는 블록당 F개의 필터만 있었다면 대신 F * K 개의 필터로 구성하였다. 각 레이어를 넓게 구성하였더니 레이어 수가 적어도 기존의 ResNet보다 성능이 좋다는 것을 입증하였다.
RexNeXt
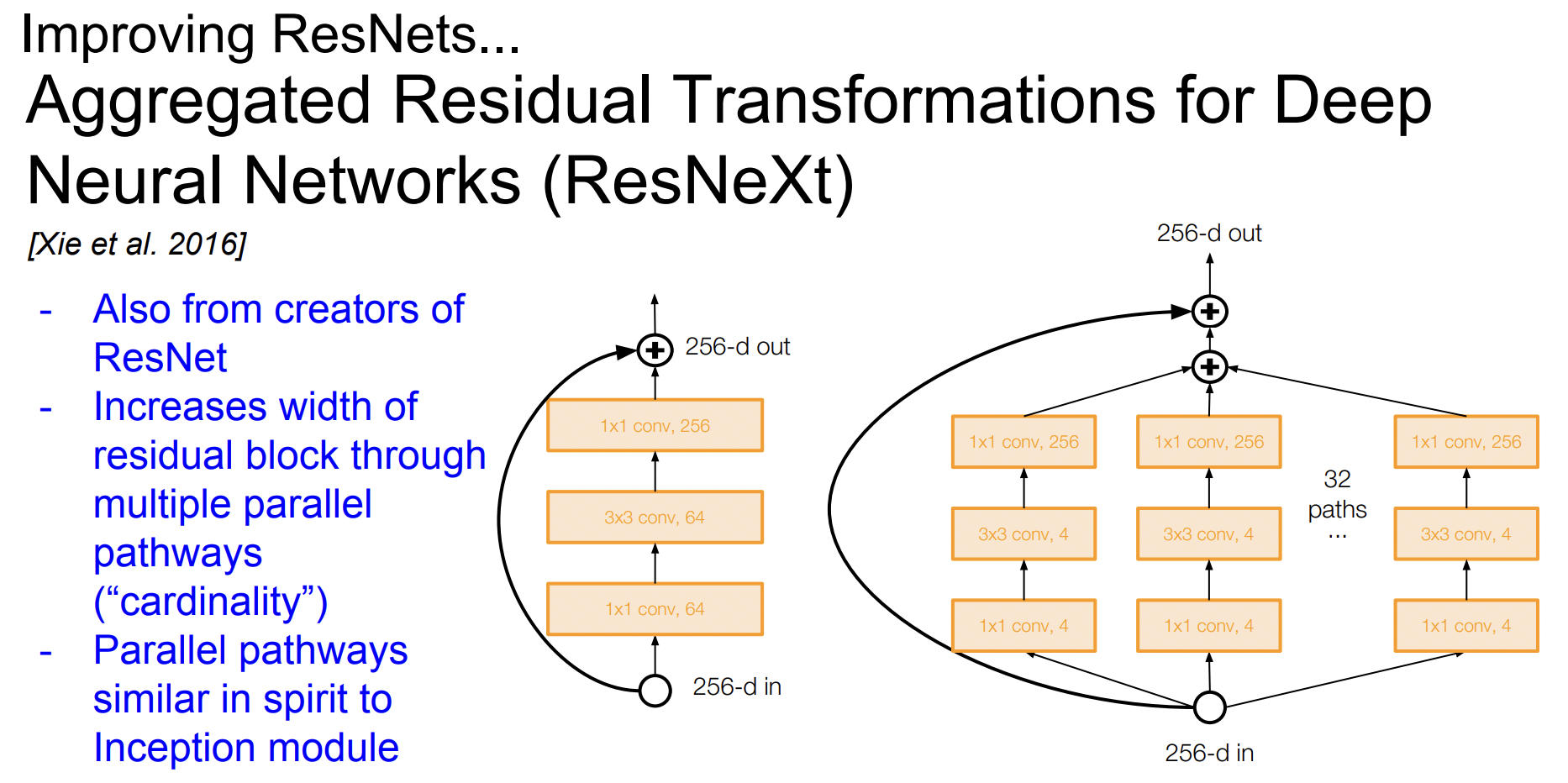
이 논문에서도 residual block의 width에 집중해 filter의 개수를 늘렸다. 각 Residual block에 multiple parallel pathway를 추가하였다.
Stochastic Depth

네트워크가 깊어질수록 Vanishing gradient 문제가 발생한다. 따라서 train time에 레이어의 일부를 제거하고 일부 네트워크를 골라 identity connection으로 만든다. 이렇게 하면 dropout과 유사하게 되어 gradient를 더 잘 전달할 수 있다.
FractalNet
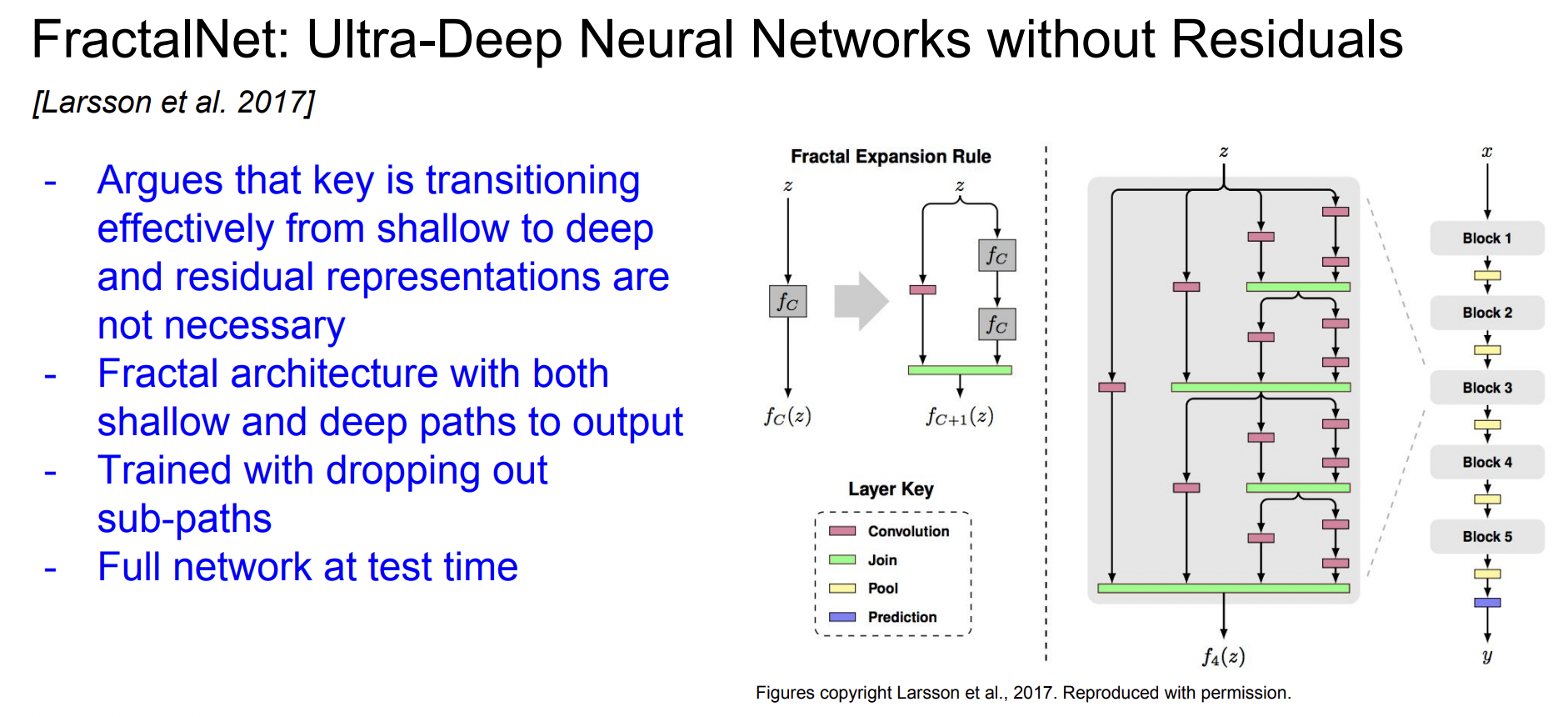
Residual connection이 전혀 없고, shallow/deep network의 정보 모두를 잘 전달하는 것이 중요하다고 생각하여 둘의 경로를 출력에 모두 연결하여 fractal한 모양의 네트워크를 만든다.
하지만 train time에는 일부 경로만 이용하여 train을 진행한다.
DenseNet
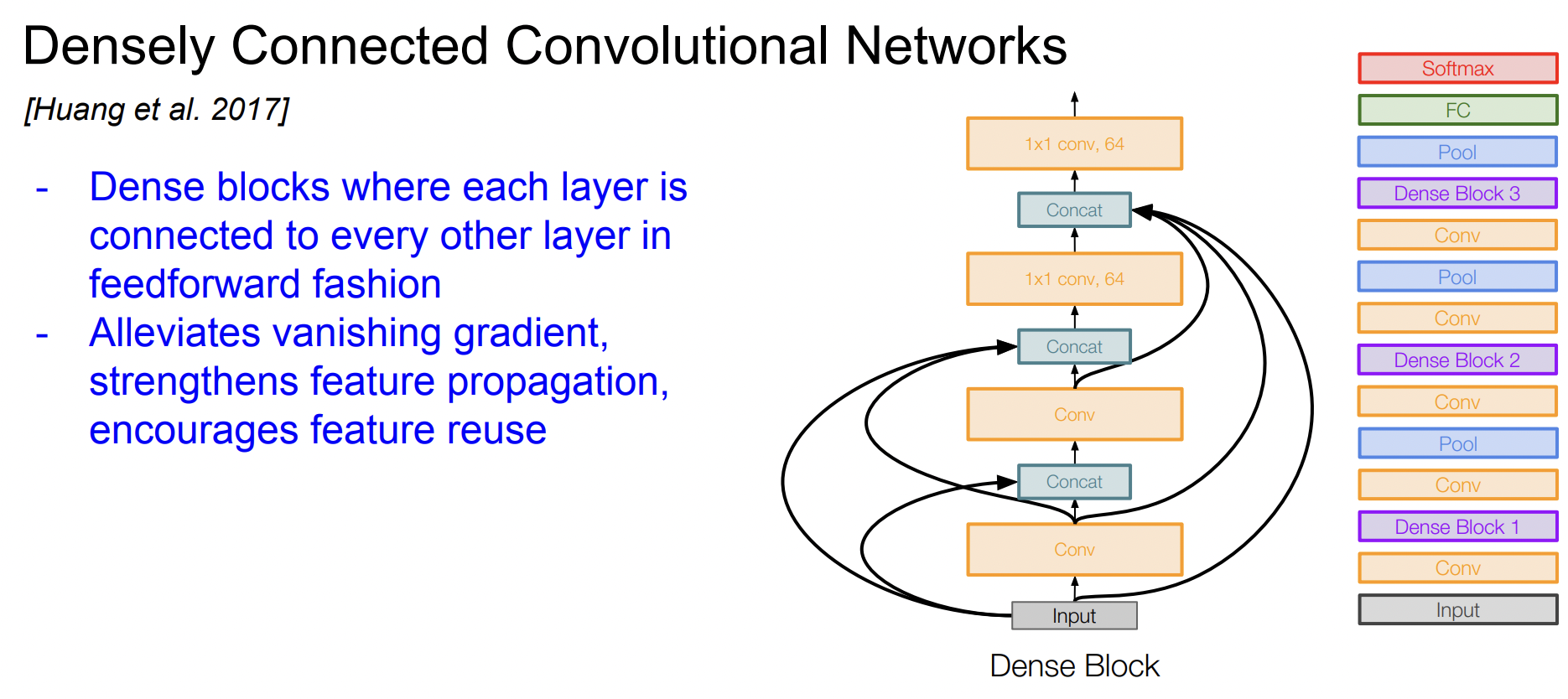
DenseNet에는 Dense block이라는 것이 있다. 한 레이어가 그 레이어 하위의 모든 레이어와 연결되어 있다. 입력 이미지가 모든 layer의 입력으로 들어가고, 모든 layer의 출력이 각 layer의 출력과 concat 되는 것이다.
이러한 dense connection이 Vanishing gradient 문제를 완화시킬 수 있다고 주장한다.
SqueezeNet

Fire module을 도입하였다. Squeeze layer는 1x1 필터로 구성되고, 이 출력값이 1x1, 3x3 필터들로 구성되는 expand layer의 입력이 된다.
SqueezeNet은 ImageNet에서 AlexNet 만큼의 accuracy를 보이지만 파라미터는 50배나 더 적다.
