Abstract
그 당시 CNN은 고정된 사이즈(fixed-size) 의 input image를 요구했다. 이 조건은 "artificial"하다. arbitrary한 이미지들의 크기를 제한한다면 성능이 reduce될 수 있기 때문이다.
CNN이 고정된 사이즈의 image를 요구한 이유는 FC-layer의 크기가 일정하기 때문이다.
convolution layer에서는 sliding window 방식을 사용하기 때문에 고정된 사이즈가 필요하지 않다.
따라서 이 논문에서는 SPP-net이라고 하는 새로운 structure를 제안한다. 이 구조에는 spatial pyramid pooling이라고 하는 풀링 기법이 사용되며, 이미지의 사이즈나 scale에 상관없이 고정된 길이의 벡터를 생성할 수 있다.
또한 SPP-net은 object detection task에서 매우 유용한데, R-CNN에서는 생성된 ROI 2000개를 전부 입력하였지만 이미지를 딱 한 번만 입력하면 된다.
기존 CNN의 문제점

기존의 CNN은 사진으로 보다시피 고정된 사이즈의 벡터만 입력으로 받기 때문에 이미지를 자르거나 비율을 왜곡시켜 정방형으로 resize하여 입력해야 했다.
Convolution filter는 이미지를 sliding window 방식으로 훑어나가는데, 이미지가 사진처럼 주요 객체가 잘리거나 비율이 왜곡되면 성능의 저하가 발생할 수 있다. 특히 이미지 내의 객체를 검출하는 object detection에서는 더욱 치명적이다.
SPP
SPP는 spatial pyramid pooling의 약자로, 논문에서 제안하는 주요 풀링 기법이다.
conv layer를 거친 image는 사이즈가 제각각이었기 때문에 feature map의 크기 또한 제각각이다. 이때 pyramid pooling을 사용하면 전부 bin * 256의 크기로 feature를 압축할 수 있다.

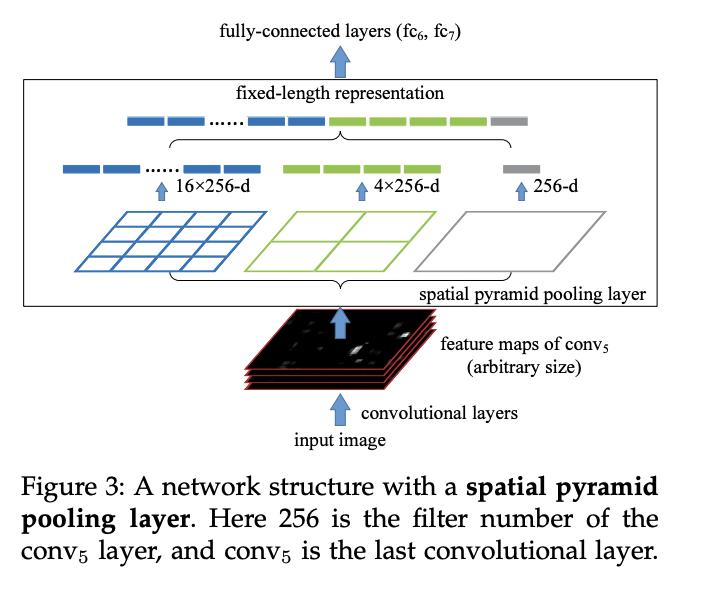
Figure 3을 보면 feature map들을 4x4, 2x2, 1x1의 세 가지 영역으로 받는다. 이 영역을 피라미드라고 부른다. 이 예시에서는 피라미드가 3개이다.이렇게 피라미드 형식으로 feature map을 가공해 한 번만 통과해도 되도록 한다.
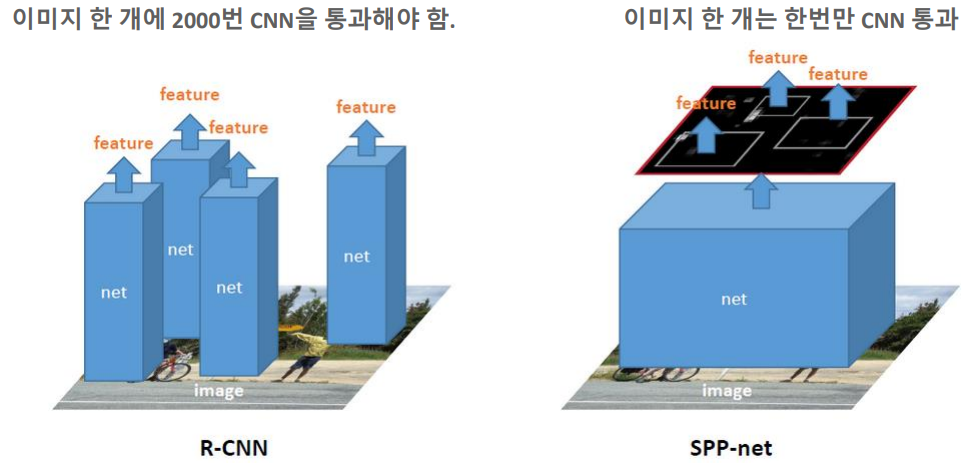
문제점
end-to-end 구조가 아니라서 feature들을 저장해 따로 학습시켜야 한다.
따라서 CNN 알고리즘도 svm과 regressor의 결과와 따로 학습된다.
