Abstract
기존의 YOLO에 여러 기법을 도입하여 성능을 향상시켰다. 지난번(YOLOv2) 모델보다는 조금 무겁지만 더 정확하다. 또한 속도는 여전히 빠르다. (SSD보다 3배 빠르다고 한다)
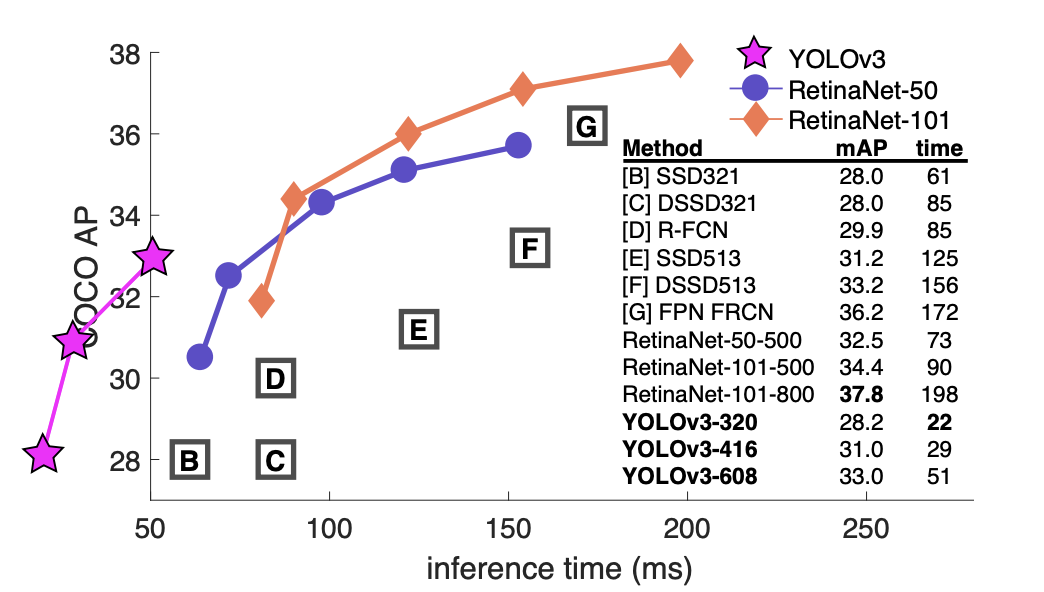
YOLOv3의 성능을 나타낸 그래프이다. YOLOv3만 왼쪽으로 치우쳐져 있는 이유는 다른 method들보다 눈에 띄게 빠르기 때문이다.
Bounding Box Prediction
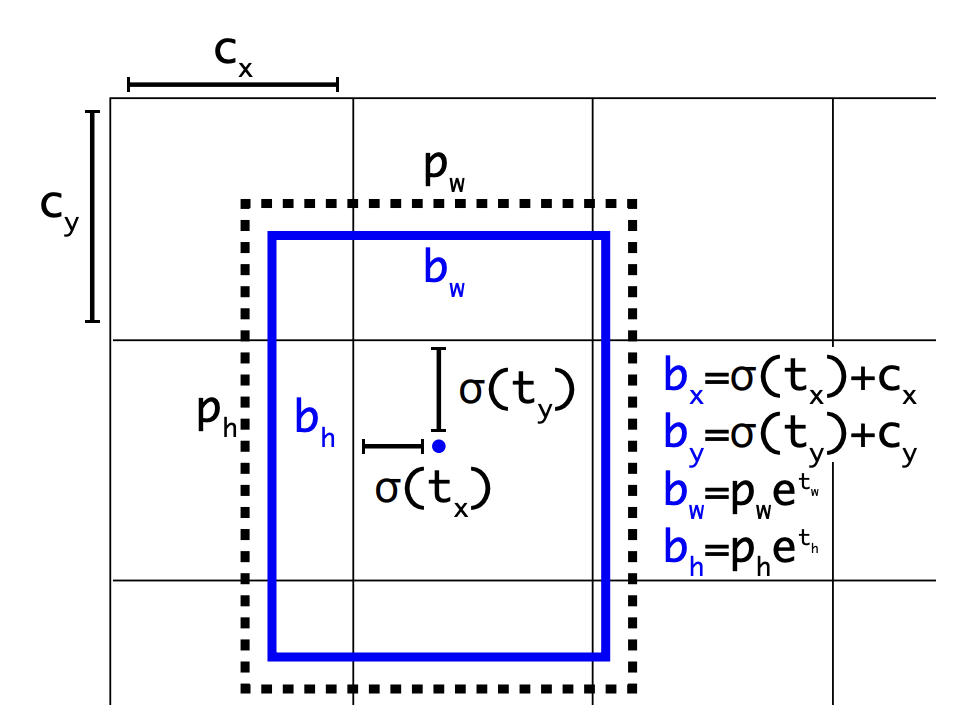
YOLOv3에서 bbox를 예측하는 방법은 v2와 동일하다. , , , 가 예측되고 예측값 중에 와 는 시그모이드 함수를 거쳐서 범위가 0~1 사이로 제한된다.
그리고 이 값이 , 와 각각 더해져서 bbox의 x,y값이 된다. 와 는 객체를 포함하고 있는 grid sell의 좌표이다.
와 는 자연상수 e 위에 올라가 , 와 곱해진다. 와 는 이전 bbox의 width와 height값이다.
이렇게 다양한 정규화 방법을 통해 학습이 안정적으로 이루어지도록 한다.
objectness score(객체 포함시 1, 없으면 0)은 logistic regression을 이용하여 예측한다. 만약 예측한 bbox가 기존의 bbox보다 ground-truth와의 IOU값이 높다면 1이 된다.
Class Prediction
각각의 box는 bbox의 class를 예측한다. softmax를 사용하지 않고 (좋은 performance를 위해 필요없다는 것을 발견하였다) 단순하게 independent logistic classifiers를 사용한다.
이 classifier는 training을 할 때 class prediction을 위해 binary cross-entropy loss를 사용한다. 이 방법이 복잡한 데이터셋으로 YOLO를 학습할 때 도움이 된다고 한다.
Prediction Across Scales
YOLOv3에서는 예측을 위해 3개의 서로 다른 scale이 사용된다. feature pyramid networks FPN 와 비슷하게 특징은 feature pyramid에서 추출한다.
3개의 scale이 사용되므로, 총 3개의 pyramid의 level에서 특징을 추출한다는 의미이다.
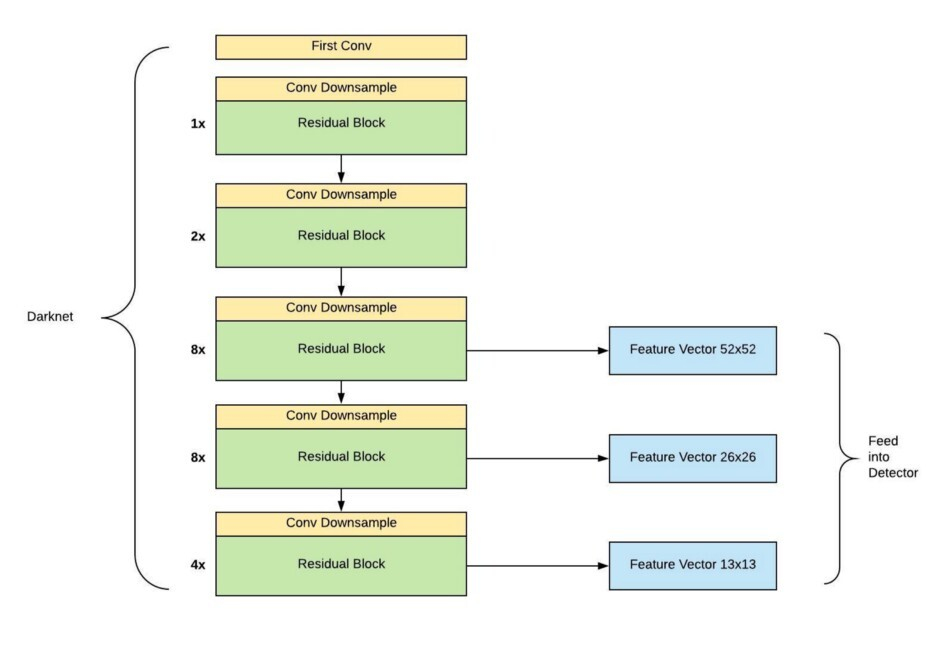
먼저 416 x 416 크기의 이미지를 네트워크에 입력하여 52 x 52, 26 x 26, 13 x 13이 되는 layer에서 각각 feature map을 추출한다.
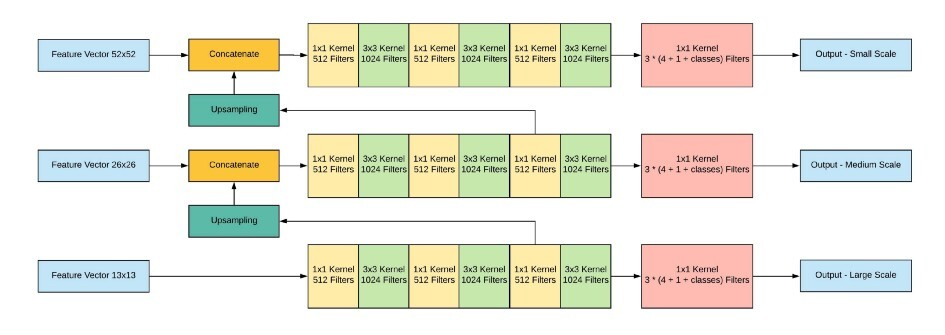
그 다음 가장 높은 level (해상도가 가장 낮은) feature map을 1x1, 3x3의 conv layer로 구성된 작은 FCN에 입력한다. 그 이후 FCN의 output channel이 512가 되는 지점에서 feature map을 추출한 뒤 2배로 upsampling을 진행한다. 이후 바로 아래 level의 feature map과 concat해준다. 이렇게 합쳐진 feature map을 FCN에 다시 입력한다.
이를 통해 3개의 scale을 가진 feature map을 얻을 수 있다.
이때 각 scale의 filter(output channel) 수가 3*(4+1+classes)가 되도록 조정한다.
여기서는 COCO 데이터셋을 사용했으므로 classes는 80이다.
3은 grid cell당 예측하는 anchor box의 개수이고 4는 bbox offset, 1은 objectness score이다.
bbox offset : 이미지가 실제 위치가 되려면 기존의 bbox를 얼마나 옮겨야 하는지
Feature Extractor
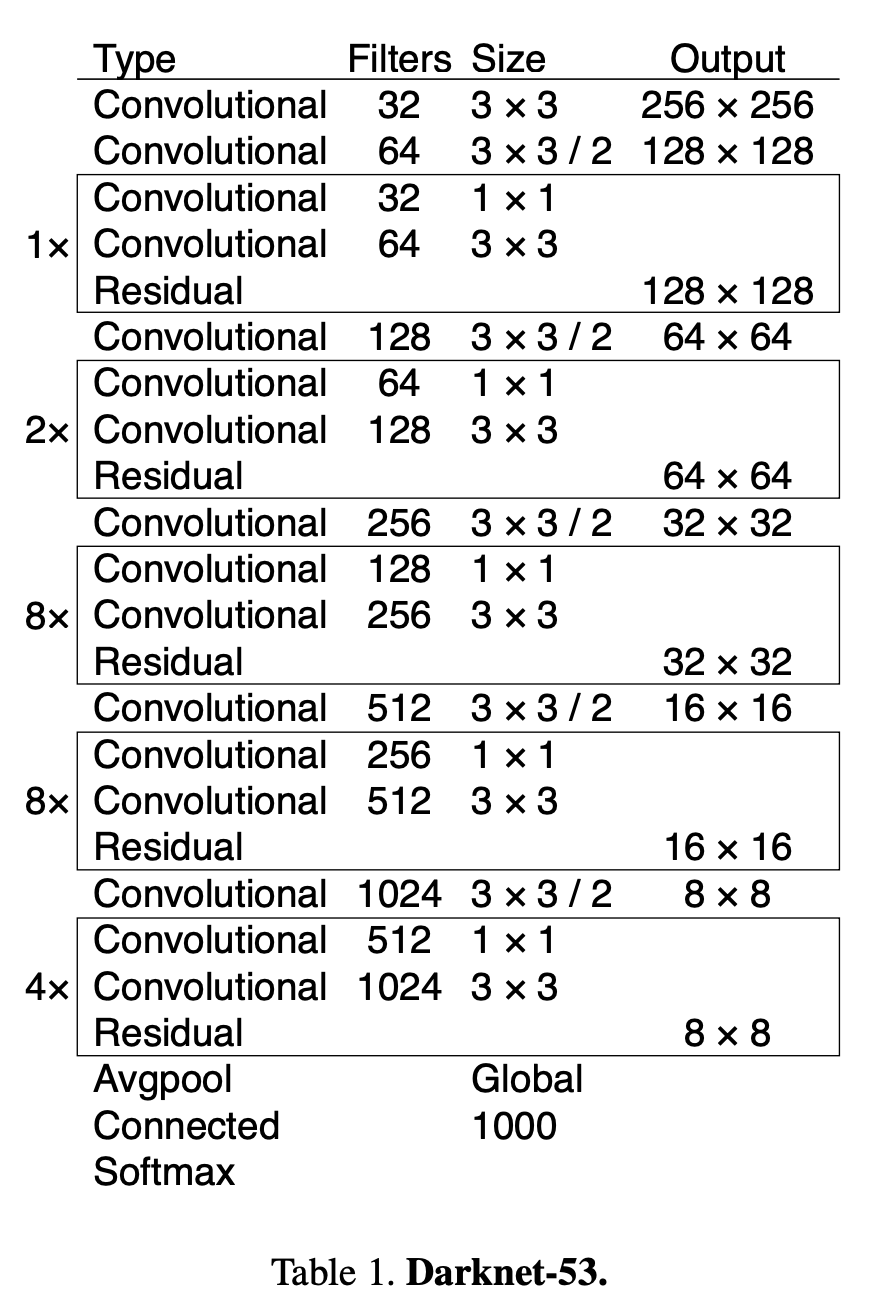
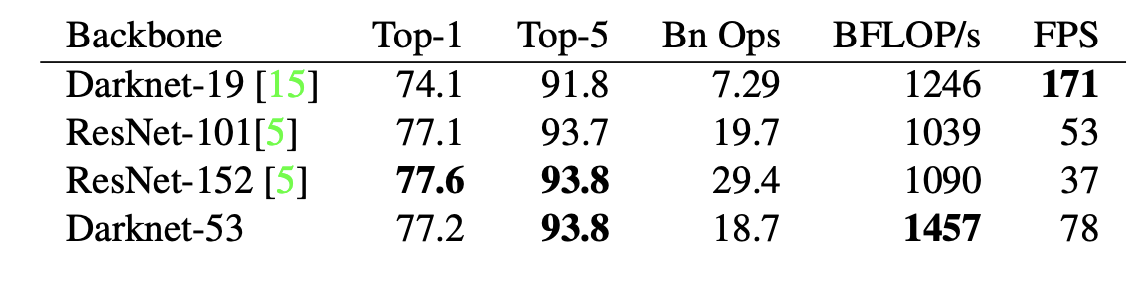
YOLOv3에서는 Darknet-53을 backbone network로 사용한다. 이는 사진으로 알 수 있듯 ResNet-101보다 1.5배 빠르며 ResNet-152와는 비슷한 성능을 보이지만 2배 이상 빠르다.
Python code
하이퍼 파라미터의 목록이다.
_BATCH_NORM_DECAY = 0.9
_BATCH_NORM_EPSILON = 1e-05
_LEAKY_RELU = 0.1
_ANCHORS = [(10, 13), (16, 30), (33, 23),
(30, 61), (62, 45), (59, 119),
(116, 90), (156, 198), (373, 326)]
_MODEL_SIZE = (416, 416) # refers to the input size of the model.모델을 정의할 때, batch normalization 기법이 많이 사용되므로 따로 함수를 만들어 정의하였다.
def batch_norm(inputs, training, data_format):
return tf.layers.batch_normalization(
inputs=inputs, axis=1 if data_format == 'channels_first' else 3,
momentum=_BATCH_NORM_DECAY, epsilon=_BATCH_NORM_EPSILON,
scale=True, training=training)그리고 ResNet implementation of fixed padding을 정의한다.
# ResNet implementation of fixed padding
def fixed_padding(inputs, kernel_size, data_format):
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
if data_format == 'channels_first':
padded_inputs = tf.pad(inputs, [[0, 0], [0, 0],
[pad_beg, pad_end],
[pad_beg, pad_end]])
else:
padded_inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end],
[pad_beg, pad_end], [0, 0]])
return padded_inputs
# Strided 2-D convolution with explicit padding
def conv2d_fixed_padding(inputs, filters, kernel_size, data_format, strides=1):
if strides > 1:
inputs = fixed_padding(inputs, kernel_size, data_format)
return tf.layers.conv2d(
inputs=inputs, filters=filters, kernel_size=kernel_size,
strides=strides, padding=('SAME' if strides == 1 else 'VALID'),
use_bias=False, data_format=data_format)fixed padding과 conv2d fixed padding을 반환하는 함수를 만든다.
#Creates a residual block for Darknet
def darknet53_residual_block(inputs, filters, training, data_format, strides=1):
shortcut = inputs
inputs = conv2d_fixed_padding(inputs, filters=filters, kernel_size=1, strides=strides, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs = conv2d_fixed_padding( inputs, filters=2 * filters, kernel_size=3, strides=strides, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs += shortcut
return inputsbackbone network인 Darknet53을 구현한다. 이 코드는 residual block을 만드는 코드이고, 전체 darknet53 네트워크는 너무 길어 첨부하지 못했다. 출처 링크에 들어가면 전문을 볼 수 있다.
etc...
나중에 feature pyramid network에 대한 논문도 읽어봐야겠다.
