Introduction
DNN(Deep Neural Network)는 speech recognition과 visual object recognition 등에서 좋은 성과를 달성해 왔다. 하지만 input size가 고정되어 있다는 단점이 존재한다.
따라서 이 논문에서는 2개의 LSTM을 encoder, decoder로 사용해 이러한 문제점을 해결하려고 했다.
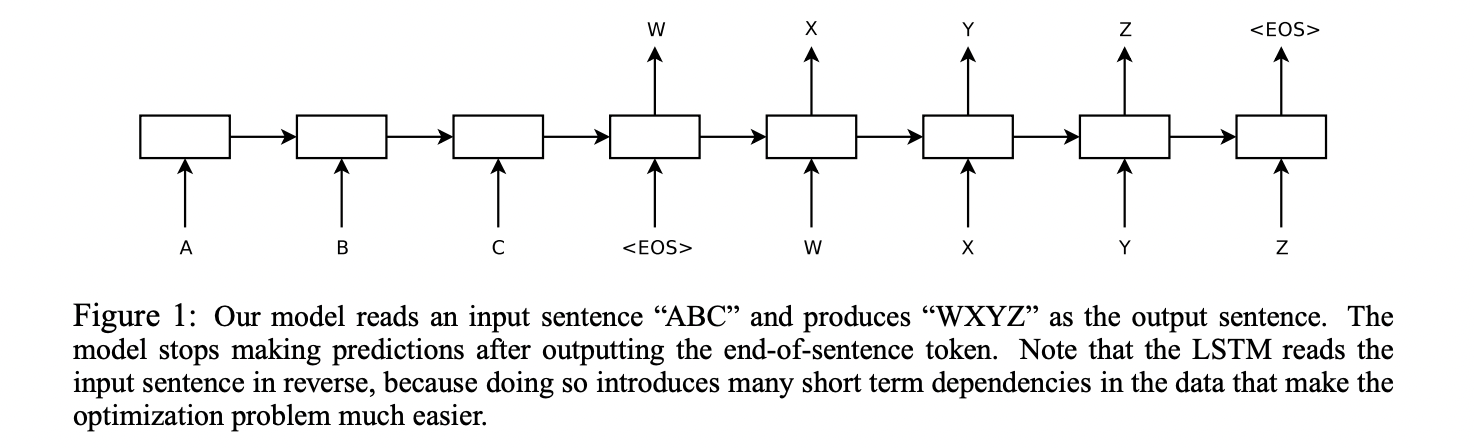
사진을 보면 input sentence로 ABC가 들어가고 해당 입력에 대한 결과인 output sentence인 WXYZ가 두 번째 LSTM을 통해서 나온다.
각 문장의 끝은 EOS라는 토큰으로 구분된다.
Model Architecture
원래는 sequence data를 다루기 위해 RNN 모델을 사용하려고 했으나 RNN은 long-term dependency에 취약하기 때문에 LSTM 모델을 사용하였다.
LSTM은 다음과 같은 식으로 output을 추출한다.
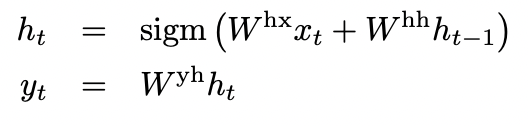
LSTM의 최종 목표는 conditional probability P(y1, ... yt | x1, ... , xt)에서 만들어낸 문장 T'가 target sequence T와 가장 유사하도록 하는 것이다.
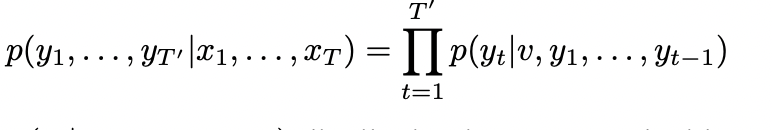
이때 output에 softmax를 적용하면 확률값으로 바뀌게 된다. 이를 통해 conditional probability를 최대화하고자 하였다.
Results
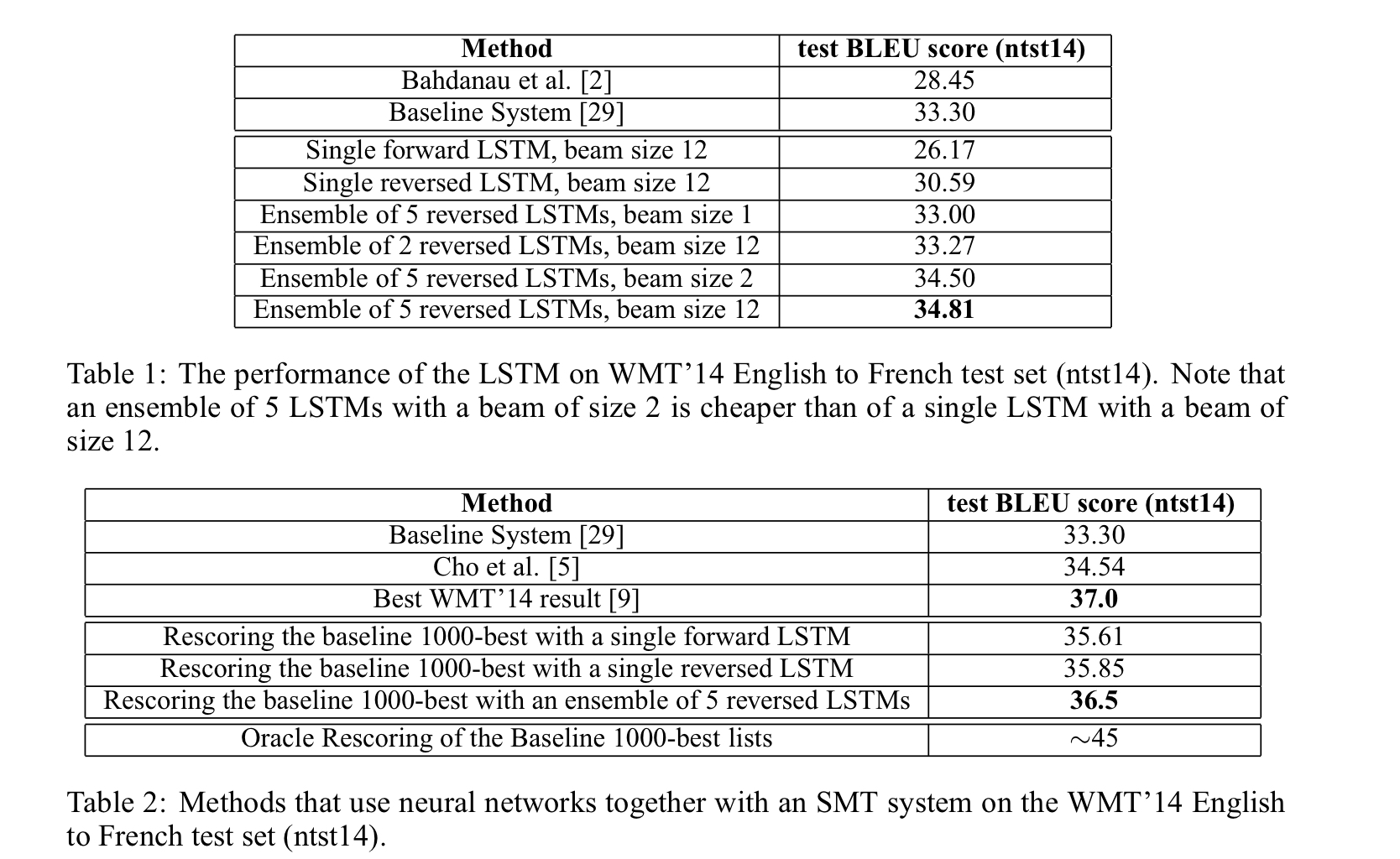
확실히 성능이 향상한 것을 볼 수 있다. single model보다 ensemble한 모델의 score가 더 높은 것도 확인할 수 있다.

fake traveler