Introduction
많은 현재의 (당시 2013년) NLP 시스템과 기술들은 단어를 atomic unit으로 다루고 있다. 따라서 개별적인 단어를 표현할 뿐 단어 간의 유사성을 표현하지 못하였다.
이러한 방법은 방대한 양의 데이터에 대해 굉장히 적은 계산으로 언어를 표현할 수 있다는 장점이 있다. 대표적 예시로는 통계적 언어 모델링에 이용되는 N-gram 모델이 있다.
하지만 단순한 기술은 많은 task에서 한계가 있다. 예를 들어 특정 도메인에 한정된 데이터의 경우 성능은 고품질의 데이터셋에 달려 있다.
하지만 machine translation(기계 번역) 분야에서 현재 존재하는 corpora들은 충분하지 못한 크기를 가지고 있다. 또한 단순하게 scaling up하는 작업은 좋은 성능을 보여주지 못한다.
따라서 우리는 advanced technique에 초점을 맞출 필요가 있다.
최근 몇 년 간 머신러닝 기술이 발달하면서, 더 복잡한 모델을 더 큰 데이터셋으로 훈련하는 것이 가능해졌다. 또한 일반적으로 그 모델들은 단순한 모델보다 좋은 성능을 보인다.
아마도 가장 성공적인 concept는 단어들의 distributed representation을 이용하고 있다. 예를 들어 언어 모델을 기반으로 한 neural network는 N-gram보다 좋은 성능을 보이고 있다.
Model Architectures
먼저 본 논문에서 훈련에 필요한 parameter 수에 따른 시간 복잡도를 정의한다. 수식은 다음과 같다.
E는 training epoch의 수, T는 training set에 있는 단어의 개수, Q는 각 모델의 특성에 따라 정의된다. 가장 일반적으로는 E는 3~50으로, T는 10억 이상으로 선택한다.
모든 모델은 stochastic gradient descent와 backpropagation을 이용해 훈련한다.
NNLM
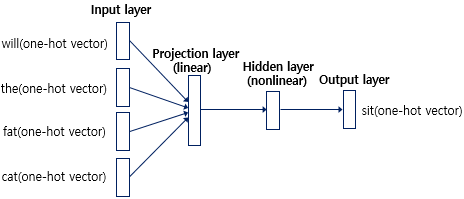
확률적 feedforward neural network language model(NNLM)은 링크에서 제안되고 있다.
이 모델은 input, projection, hidden layer, output layer로 구성되어 있다. input layer에서는 N개의 이전 단어가 1-of-V coding으로 인코딩된다. 이때 V는 전체 단어의 개수이다.
그 이후 input layer는 projection layer인 P로 projection된다. P는 N x D의 차원을 가지고 있다.
NNLM architecture는 projection과 hidden layer 사이의 연산이 점점 복잡해지게 된다. N=10일 때, layer P의 크기는 500에서 2000 사이가 된다. hidden layer 크기인 H는 일반적으로 500에서 1000 unit 사이이다.
게다가 H는 V차원을 가진 output layer에 연결된다. 따라서 계산 복잡도는 다음과 같다.
하지만 실제로는 이러한 복잡한 계산을 피하기 위해서 softmax를 사용하거나 un-normalized model을 사용하기도 한다.
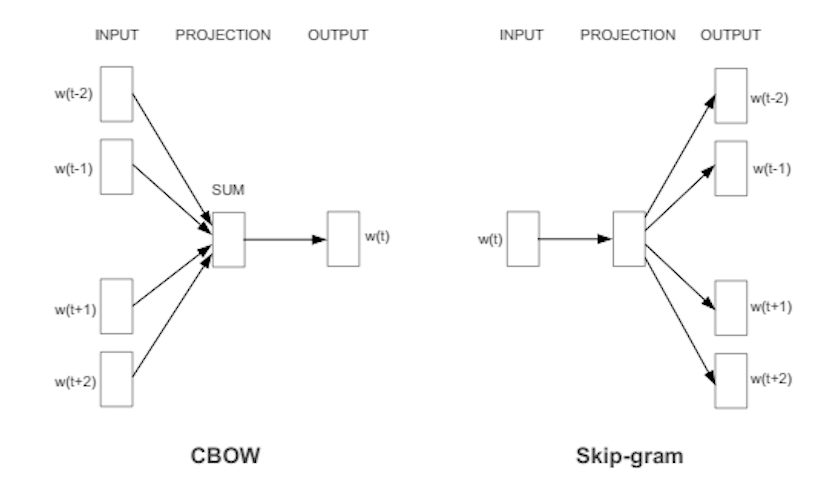
CBoW
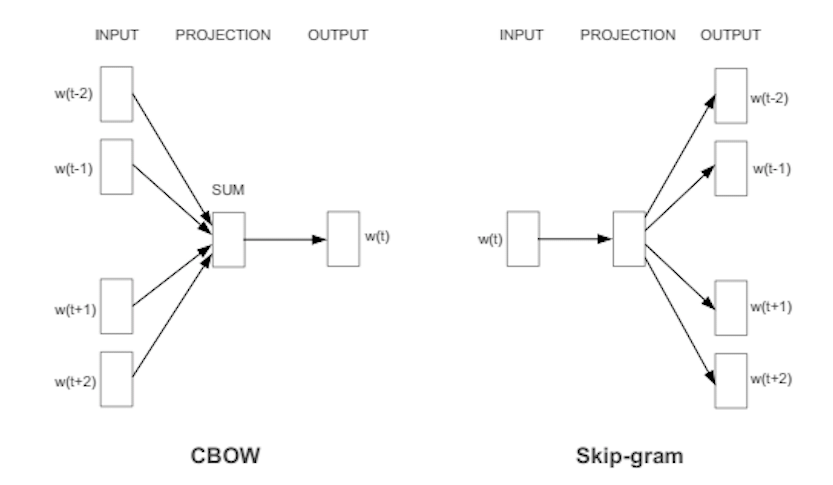
왼쪽에 있는 것이 CBoW architecture인데, hidden layer가 제거되고 모든 layer가 projection layer를 공유하는 형태이다. 모든 단어들이 동일한 weight matrix를 사용한다. 즉 feedforward NNLM과 유사하다.
모든 단어는 같은 position으로 projection된다. 이러한 구조를 Bag of Word(BoW) 라고 하는데, 이전에 projection된 단어들은 영향을 미치지 못한다는 특징이 있다.
또한 log-linear classifier를 사용한다. 4개의 과거 단어와 4개의 미래 단어를 input으로 넣어 가운데에 있는 현재 단어를 훈련해 가장 좋은 성능을 도출한다.
훈련 복잡도는 다음과 같다.
Continuous Skip-gram Model
사진 오른쪽의 모델이 skip-gram 모델이다. 모델의 구조는 CBoW와 유사하다. 하지만 문맥을 기반으로 현재의 단어를 예측하는 대신 같은 문장 안에서 다른 단어들을 기반으로 단어의 분류를 최대화한다.
이 논문에서는 단어의 범위를 증가시킬수록 결과값이 좋아지는 것을 발견하였다. 하지만 동시에 계산 복잡도도 증가된다.
단어 사이의 거리가 멀수록 관련도 적게 되어있기 때문에, 먼 단어에는 weight를 적게 주는 식으로 training시킬 수 있다.
훈련 복잡도는 다음과 같다.
이때의 C는 단어간 거리의 max값이다.
Results
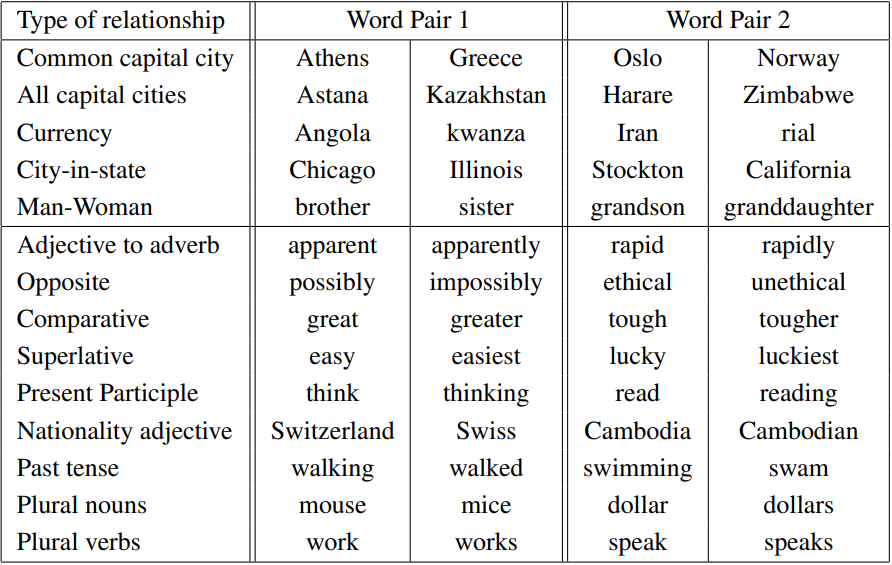
논문에서 정의한 test 셋이다.
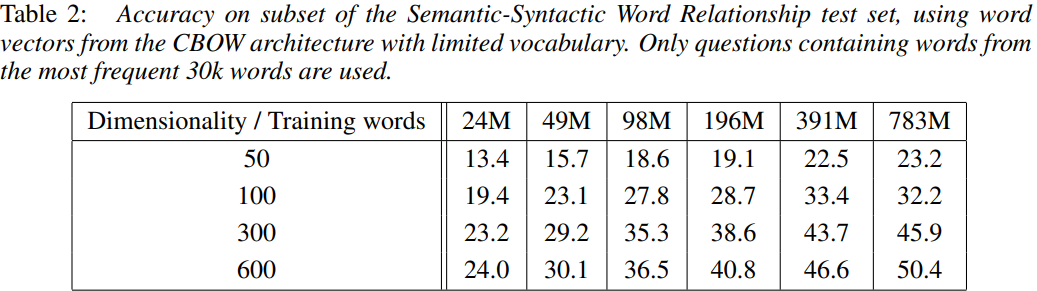
벡터의 차원과 훈련 데이터를 키울수록 정확도가 향상됨을 알 수 있다.
