앙상블 학습법
앙상블 학습은 "하나의 강력한 알고리즘보다는 조금 약할지라도 여러 개의 알고리즘을 결합하여 사용하면 더 뛰어나다"라는 이론으로 동작한다.
앙상블 학습법에는 크게 voting, bagging, boosting 방식이 있다.
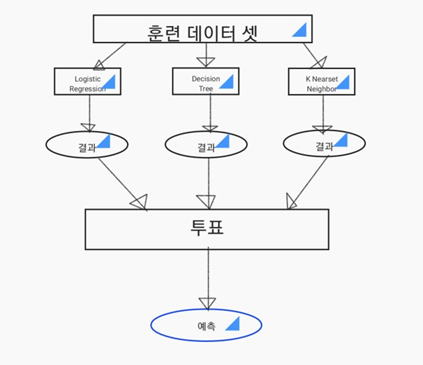
Voting 방식
- 동일한 훈련 데이터셋을 여러 알고리즘을 통해 예측을 하고 그 결과들 중 가장 나은 예측을 투표하여 선정하는 방식
Bagging 방식

-
1개의 알고리즘을 여러 번 이용.
-
동일한 모집단에서 추출한 표본을 가지고 예측 수행. 이 때 각 알고리즘에서 사용하는 표본은 원래 데이터 셋에서 각각 복원추출하여 생성됨. (이 때 데이터 셋마다 전부 다른 데이터를 사용해야만 하는 것이 아닌 서로 간의 중첩을 허용함.)
-
높은 분산과 낮은 편향을 나타내는 데이터 셋에 사용된다.
그림을 설명하면 다음과 같다.
-
부트스트래핑: 원래의 데이터 셋에서 무작위로 표본 추출을 하여 원래는 1개의 데이터 셋만 가지고 있었지만 여러 개의 데이터 셋을 가진 것과 같은 효과를 낼 수 있다. 각 표본은 약한 분류기를 이용하여 서로 병렬로, 독립적으로 교육된다.
-
집계: 정확한 추정치 계산을 위해
- 회귀의 경우에는 모든 개별 예측기 결과값의 평균이 사용되고(soft voting)
- 분류의 경우에는 가장 많이 선정된 범주로 결정된다(hard voting).
Boosting 방식
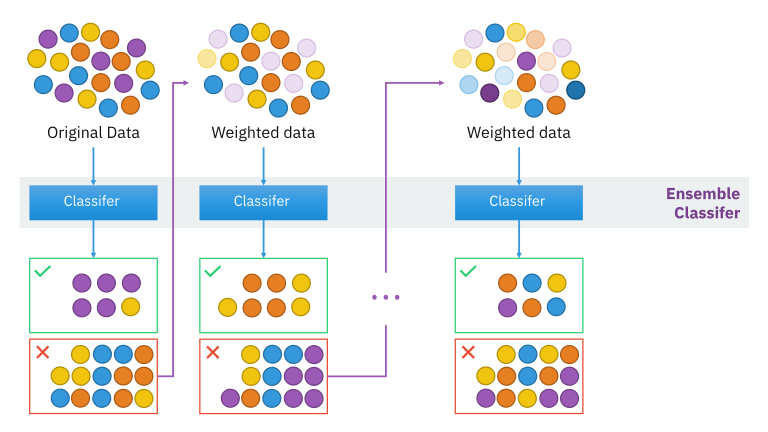
- 하나의 알고리즘을 이용하여 예측을 진행한다.
- 이전 모델이 잘못 예측한 부분에 대해 보완하여 다음 모델에서는 더 나은 예측이 진행된다. ==> 학습이 순차적으로 진행된다.
- 의사 결정 트리 알고리즘을 많이 선택한다.
- 낮은 분산, 높은 편향을 보이는 데이터 셋에 사용한다.

배움을 기록하는 습관 들이기