MF (Matrix Factorization, 행렬 분해)

- 사용자와 상품 간의 관계 학습한다.
- ex. 넷플릭스 사용자별 상품 추천.
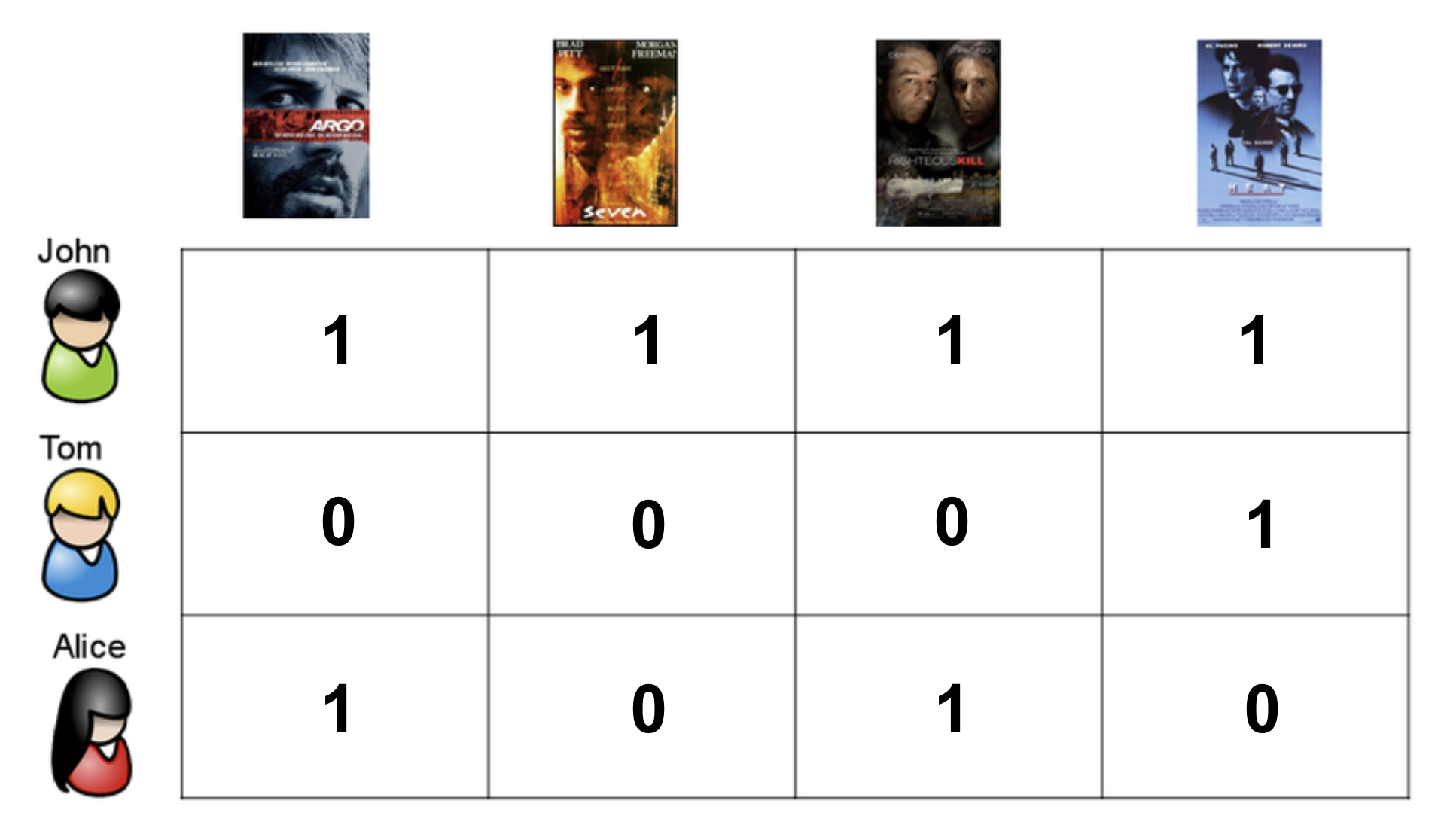
사진과 같이 세 사람이 4개의 영화에 대해 좋았다고 평점을 주는 상황이 있다고 가정하자. Tom과 Alice는 못봐서 평점을 주지 못한 영화가 있다. FM은 0점인 부분의 점수를 예측하는 알고리즘이다.
mf의 원리
위 1개의 행렬을 두개의 저차원 행렬로 분해 한다.
MF로 분해하면 두 개의 잠재 요인 행렬로 나뉘게 된다.
예를 들어, 사용자의 선호도와 영화의 특성을 나타내는데, 여기서는 영화의 장르를 잠재 요인 중 하나로 가정한다.
첫번째 사진의 사용자-영화 행렬은 위와 같은 두개의 저차원 행렬 2개로 분해될 수 있다.
저차원 행렬은 각각
- 사용자 잠재 요인 행렬(U)
- 아이템(영화) 잠재 요인 행렬(V)
이다.
잠재요인(Latent Factor)
- 우리가 해석하기 쉬운 형태로 명확히 드러나지 않고, 데이터 내에 숨겨진 패턴을 추상화하여 표현하는 변수.
- 영화 추천 시스템에서 잠재 요인은 장르, 인기도, 작품성, 배우 등 다양한 특성들을 포괄적으로 표현할 수 있다. 예를 들어서 첫 번째 잠재 요인이 장르와 관련된 것이라면, 이 잠재 요인의 값은 코미디, 로맨스, 액션 등 여러 장르에 대한 선호도를 모두 포함하는 것일 수 있다.
MF의 계산
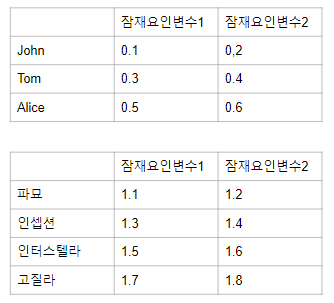
- 잠재 변수 개수를 정한다. 예시에서는 2개로 정했다.
- 위 사진과 같이 초기 세팅의 값. 랜덤하게 설정한다.
- 예측 평점 계산 U와 V의 행렬 곱을 통해 예측 평점 행렬(R^)을 계산한다.
- 손실 함수 계산 실제 평점 행렬(R)과 예측 평점 행렬(R^) 간의 차이를 계산한다.
- Ex) RMSE(Root Mean Square Error)
- Ex) RMSE(Root Mean Square Error)
- 경사 하강법을 통한 최적화 손실 함수를 최소화하는 방향으로 U와 V 행렬을 업데이트한다. 이 과정에서 학습률(learning rate)를 설정해야 한다.
- 반복 및 수렴 설정한 횟수만큼 3~4 단계를 반복하며, 손실 함수가 수렴할 때까지 진행한.
- 최종 예측 평점 계산 학습된 U와 V 행렬을 통해 최종 예측 평점 행렬을 계산한다.
FM (Factorization Machines)
- 선형 모델의 확장. 고차원 데이터에서 변수 간 상호 작용을 고려하여 모델링
- 특징 간의 상호 작용을 학습하여 예측 성능 향상
- 희소한 데이터에서도 효과적
- 사용자와 상품 간의 상호 작용 고려에 유용
수식
: 전역 편향
: i번째 변수의 가중치
: i번째와 j번째 변수의 2차 상호작용을 모델링하는 요인
공통점
- 변수를 f차원의 잠재 요인(Latent Factor)으로 매핑
- 변수 간의 상관관계를 잠재 요인의 내적으로 모델링
- 변수 간의 복잡한 관계를 효과적으로 학습 가능
차이점
| 구분 | FM | MF |
|---|---|---|
| 사용 정보 | 다양한 특성 결합 가능 | 사용자, 상품, 평점 정보만 사용 |
| 평점 계산 방식 | 모든 특성을 하나의 벡터로 치환하여 다항 회귀와 유사 | 사용자와 상품의 내적으로 평점 계산 |
| 희소 데이터 처리 | 희소한 데이터에서도 파라미터 추정 가능 | - |
| 상호 작용 고려 | 변수 간의 상호 작용을 고려하여 예측 가능 | - |

천천히 꾸준히 취미처럼 냐미😋