Collaborative Filtering 이란?
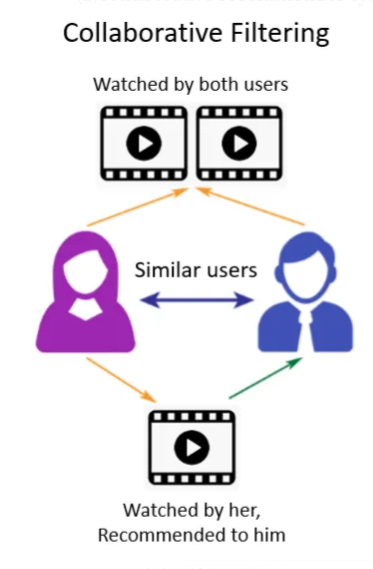
Collaborative Filtering (CF)은 사용자들의 행동 데이터를 기반으로 선호도를 예측하고 추천하는 기술이다. CF는 비슷한 취향을 가진 사용자들이 유사한 선호도를 보일 것이라는 가정에서 출발한다. 즉, 어떤 사용자가 특정 아이템을 좋아했다면, 그 사용자와 비슷한 취향을 가진 다른 사용자도 해당 아이템을 좋아할 가능성이 높다는 것이다.
Collaborative Filtering의 원리
CF의 기본 아이디어:
- 사용자들의 아이템에 대한 선호도 (평점, 구매 이력 등)를 수집
- 사용자들 간의 유사도 또는 아이템들 간의 유사도를 계산
- 유사도를 기반으로 사용자가 아직 경험하지 않은 아이템 중에서 선호할 만한 아이템을 추천
예를 들어, 영화 추천 시스템에서:
- 사용자 A와 사용자 B가 많은 영화에 대해 비슷한 평점을 남겼다면, 두 사용자는 유사한 취향을 가진 것으로 볼 수 있음
- 사용자 A가 좋아한 영화 중에서 사용자 B가 아직 보지 않은 영화를 사용자 B에게 추천할 수 있음
Collaborative Filtering의 종류
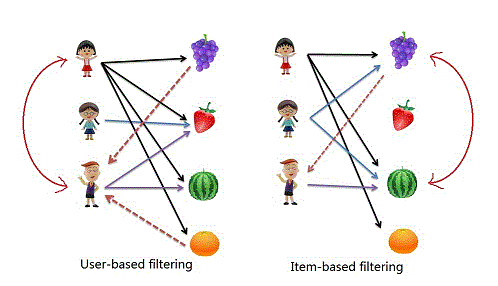
Memory-based CF
- 사용자-아이템 상호작용 데이터를 직접 사용
- 유사도 계산을 통해 유사한 사용자 또는 아이템을 찾음
- 사용자 기반(User-based) 과 아이템 기반(Item-based) 으로 나뉨
- 사용자 기반: 유사한 사용자가 선호하는 아이템을 추천
- 아이템 기반: 사용자가 선호한 아이템과 유사한 아이템을 추천
Model-based CF
- 사용자-아이템 상호작용 데이터를 기반으로 모델을 학습
- 대표적인 방법으로
Matrix Factorization이 있음- 사용자-아이템 행렬을 두 개의 낮은 차원 행렬로 분해
- 사용자와 아이템의 잠재 요인을 찾아내 선호도 예측
- (: 사용자-아이템 행렬, : 사용자 잠재 요인 행렬, : 아이템 잠재 요인 행렬)
Collaborative Filtering의 한계
1. Cold-start 문제
- 새로운 사용자나 아이템에 대한 추천이 어려움
- 충분한 상호작용 데이터가 없으면 유사도 계산이 불가능
- 이를 해결하기 위해 콘텐츠 기반 필터링과의 하이브리드 방식 등이 사용됨
2. 희소성 문제
- 사용자-아이템 행렬의 대부분이 비어있는 경우 발생
- 사용자가 평가한 아이템 수가 전체 아이템에 비해 매우 적음
- 유사도 계산의 신뢰도가 낮아지고 추천의 질이 저하될 수 있음
- 차원 축소 기법이나 행렬 분해 방식으로 해결 가능
3. 확장성 문제
- 사용자와 아이템 수가 증가할수록 계산량이 기하급수적으로 증가
- 실시간 추천이 어려워질 수 있음
- 분산 처리, 근사 알고리즘 등을 활용해 확장성을 개선할 수 있음
4. 다양성 부족
- 인기 있는 아이템이 더 자주 추천되는 경향이 있음
- 사용자의 취향을 좁게 해석할 위험이 있음
- 다양성을 고려한 추천 알고리즘이 필요
5. 설명 가능성 부족
- 추천 결과에 대한 설명을 제공하기 어려움
- 사용자의 신뢰도를 낮출 수 있음

천천히 꾸준히 취미처럼 냐미😋