CNN의 일반적인 구조
일반적인 CNN은 다음과 같은 순서로 배열된 레이어들로 구성됩니다:
- 입력 레이어: 원시 픽셀 데이터를 받아들이는 레이어.
- 합성곱 레이어: 입력 데이터에 합성곱 연산을 적용하여 특징을 추출.
- 활성화 함수: 비선형성을 도입하여 모델의 표현력을 높임 (예: ReLU).
- 풀링 레이어: 공간적 차원(높이와 너비)을 줄여 계산량을 감소시키고 과적합을 방지.
- 완전 연결 레이어: 추출된 특징을 기반으로 높은 수준의 추론 및 분류를 수행.
- 출력 레이어: 최종 예측이나 분류 결과를 제공.
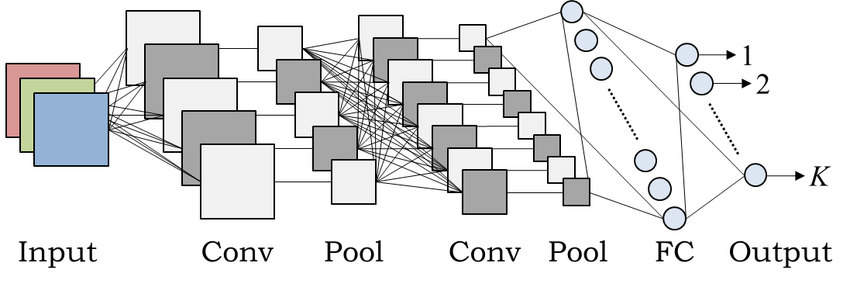
예시로 각 레이어별 데이터 형태 변화 설명:
예시: 32x32 픽셀의 그레이스케일 이미지
-
입력 레이어:
- 입력 형태:
(높이, 너비, 채널 수) - 예시 형태:
(32, 32, 1)(그레이스케일 이미지이므로 채널 수는 1)
- 입력 형태:
-
첫 번째 합성곱 레이어:
- 연산: 학습 가능한 필터(커널)를 입력에 적용.
- 파라미터:
- 필터 수 (예: 16개)
- 커널 크기 (예: 3x3)
- 스트라이드 (예: 1)
- 패딩 (예: 'same' 또는 'valid')
- 출력 계산:
- 패딩이 'same'인 경우 출력 차원은 입력과 동일.
- 출력 형태:
(32, 32, 16)(필터 수 만큼 채널 증가)
형태 변화 설명:
- 패딩을 사용하여 높이와 너비는 유지.
- 채널 수는 필터 수 만큼 증가.
-
활성화 함수(ReLU 등):
- 연산: 각 요소에 비선형 함수를 적용.
- 출력 형태: 입력과 동일.
- 활성화 후 형태:
(32, 32, 16)
-
첫 번째 풀링 레이어:
- 연산: 윈도우 내에서 최대값이나 평균값을 취해 다운샘플링.
- 파라미터:
- 풀 크기 (예: 2x2)
- 스트라이드 (예: 2)
- 출력 계산:
- 새로운 높이 = (이전 높이 - 풀 높이) / 스트라이드 + 1
- 스트라이드가 풀 크기와 같고 'valid' 패딩인 경우 단순화됨.
- 출력 형태:
(16, 16, 16)
형태 변화 설명:
- 풀링을 통해 높이와 너비가 절반으로 감소.
- 채널 수는 그대로 유지.
-
두 번째 합성곱 레이어:
- 파라미터:
- 필터 수 (예: 32개)
- 커널 크기 (예: 3x3)
- 스트라이드 (예: 1)
- 패딩 (예: 'same')
- 출력 형태:
(16, 16, 32)
- 파라미터:
-
활성화 함수:
- 출력 형태: 동일.
- 활성화 후 형태:
(16, 16, 32)
-
두 번째 풀링 레이어:
- 파라미터:
- 풀 크기 (예: 2x2)
- 스트라이드 (예: 2)
- 출력 형태:
(8, 8, 32)
- 파라미터:
-
평탄화(Flatten) 레이어:
- 연산: 3D 출력을 1D 벡터로 변환하여 완전 연결 레이어에 입력.
- 계산:
- 총 유닛 수 = 높이 x 너비 x 채널 수
- 총 유닛 수:
8 x 8 x 32 = 2048
- 출력 형태:
(2048,)
-
완전 연결(Dense) 레이어:
- 파라미터:
- 유닛 수 (예: 128개 뉴런)
- 연산: 입력의 가중합을 계산하여 출력 생성.
- 출력 형태:
(128,)
- 파라미터:
-
활성화 함수(ReLU 등):
- 출력 형태: 동일.
- 활성화 후 형태:
(128,)
-
출력 레이어:
- 파라미터:
- 유닛 수 (예: 클래스 수 만큼, 숫자 0~9를 분류한다면 10)
- 활성화 함수 (예: 소프트맥스)
- 출력 형태:
(10,)
- 파라미터:
각 레이어의 상세 설명:
-
합성곱 레이어:
지역적인 패턴과 특징(에지, 텍스처, 형태 등)을 감지하는 역할을 합니다. 필터가 입력 데이터 위를 슬라이딩하며 요소별 곱셈과 합산(합성곱 연산)을 수행합니다.
-
패딩:
- 'Same' 패딩: 출력이 입력과 동일한 공간적 차원을 가지도록 입력 주위에 0을 추가.
- 'Valid' 패딩: 패딩을 사용하지 않으며, 커널 크기에 따라 출력 크기가 감소.
-
스트라이드:
필터 창이 입력 매트릭스 위를 이동하는 픽셀 수입니다. 스트라이드가 클수록 출력이 작아집니다.
-
활성화 함수:
비선형성을 도입하여 복잡한 패턴을 학습할 수 있게 합니다. ReLU(Rectified Linear Unit)는 기울기 소실 문제를 완화하여 널리 사용됩니다.
-
풀링 레이어:
공간적 차원을 줄여 계산량을 감소시키고 과적합을 방지합니다. 대표적인 종류로는 최대 풀링과 평균 풀링이 있습니다.
-
평탄화 레이어:
다차원 출력을 완전 연결 레이어에 입력하기 위해 1차원 배열로 변환합니다.
-
완전 연결 레이어:
이전 레이어의 모든 뉴런과 연결되어 있으며, 합성곱 레이어에서 추출된 특징을 기반으로 예측을 수행합니다.
-
출력 레이어:
최종 출력을 생성합니다. 분류 작업의 경우 소프트맥스 활성화 함수를 사용하여 각 클래스에 대한 확률을 출력합니다.
추가 고려 사항:
-
배치 크기:
데이터는 일반적으로 배치 단위로 처리됩니다. 배치 크기가
N인 경우 입력과 출력 형태는(N, 높이, 너비, 채널 수)가 됩니다. -
컬러 이미지:
RGB 이미지를 사용하는 경우 초기 입력 형태는
(높이, 너비, 3)입니다. -
깊은 네트워크:
VGG, ResNet, Inception과 같은 현대적인 CNN은 더 많은 레이어를 포함하며, 추가적인 합성곱 및 풀링 레이어, 배치 정규화 레이어, 스킵 연결 등을 포함합니다.
-
정규화 기법:
- 드롭아웃 레이어: 학습 시 무작위로 일부 입력 유닛을 0으로 설정하여 과적합을 방지.
- 배치 정규화: 미니배치마다 입력을 정규화하여 학습 과정을 안정화.
-
RGB 이미지 예시:
64x64 픽셀의 RGB 이미지를 사용한다고 가정합니다.
- 입력 형태:
(64, 64, 3)
3x3 크기의 32개 필터를 가진 합성곱 레이어를 통과하면:
- 출력 형태:
(64, 64, 32)
'Valid' 패딩을 사용하면 공간적 차원이 감소합니다:
- 출력 높이와 너비:
64 - 3 + 1 = 62 - 출력 형태:
(62, 62, 32)
풀 크기가 2x2이고 스트라이드가 2인 풀링을 적용하면:
- 출력 형태:
(31, 31, 32)
- 입력 형태:
출력 차원 계산을 위한 수학 공식:
-
합성곱 레이어 출력 차원:
출력 높이 = (입력 높이 - 커널 높이 + 2 x 패딩) / 스트라이드 + 1 출력 너비 = (입력 너비 - 커널 너비 + 2 x 패딩) / 스트라이드 + 1 -
풀링 레이어 출력 차원:
출력 높이 = (입력 높이 - 풀 높이) / 스트라이드 + 1 출력 너비 = (입력 너비 - 풀 너비) / 스트라이드 + 1
실용적인 팁:
-
커널 크기 선택:
일반적인 커널 크기는 3x3이나 5x5입니다. 작은 커널은 세부 정보를, 큰 커널은 더 넓은 특징을 포착합니다.
-
네트워크의 깊이:
레이어 수를 증가시키면 복잡한 특징을 학습할 수 있지만, 과적합 위험과 계산 비용이 증가할 수 있습니다.
-
필터 수:
일반적으로 깊은 레이어에서는 더 복잡한 특징을 포착하기 위해 필터 수를 증가시킵니다.
-
최적화:
학습률 스케줄링, 모멘텀, Adam과 같은 적응형 옵티마이저를 사용하여 학습을 개선합니다.
Fully Connected layer의 유닛
- 중간 특징 학습
완전 연결 레이어의 유닛 수는 CNN의 최종 특징을 압축하거나, 학습을 통해 중요한 패턴을 더 잘 잡아내기 위해 설정된 중간 유닛 수입니다. 이 레이어의 유닛 수는 보통 임의로 설정되며, 특정한 특징이나 패턴을 좀 더 잘 학습할 수 있도록 모델을 조정하는 단계입니다. - 유닛 수 선택
보통 128, 256, 512 등의 유닛 수를 사용하는데, 이는 CNN이 학습한 복잡한 특징을 모아 최종 분류(또는 예측)를 위해 준비하는 역할을 합니다.
prompt: 일반적인 cnn의 구조를 알고싶어. 그리고 구조를 지날 때 input data shape이 어떻게 변화하는지 예시를 들어가며 알려줘. 최대한 길게 많은 내용을 (한국어로) 설명해
