히스토그램은 이미지의 픽셀 값 분포를 시각화하고 분석하는 데 사용된다.
회사 업무 중 두 이미지의 유사도 비교를 해야하는 과제에 직면했다.
여러 방법을 탐구한 후, 이미지 히스토그램이 제일 적합하여 활용했다.
정의
이미지의 픽셀 값 분포를 시각화한 그래프.
이미지의 픽셀 값이란?
컴퓨터는 이미지를 픽셀(pixel)이라는 작은 정사각형 단위로 인식한다.
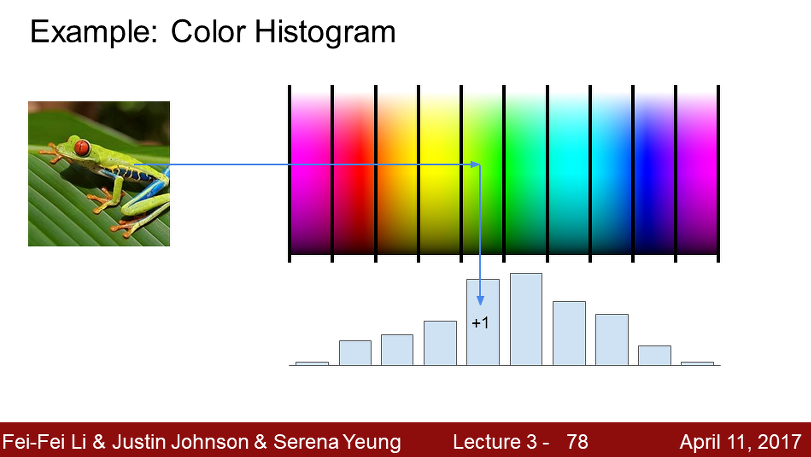
cs231n 3강에 잠깐 언급되었던 이미지 히스토그램 교안 부분을 가지고 왔다.
히스토그램을 통해 각 색마다 몇개의 픽셀이 존재하는지 히스토그램 막대로 표현된다.
예시로 교안의 개구리 사진에는 초록색이 많다. 따라서 초록색에 해당되는 축의 막대가 가장 높다.
반대로 보라색 계열은 사진에서 거의 보이지 않는다. 따라서 보라색에 해당되는 축의 막대는 높지 않다. 막대만 보고 어떤 색이 많은지는 직관적으로 확인할 수는 없다.
3개가 있다. 색에 따른 숫자는 변환을 한번 더 거쳐야 한다.
참고 블로그
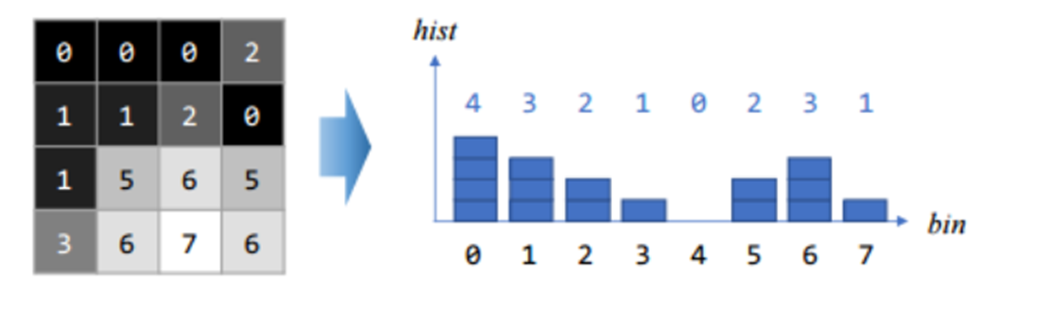
이해를 위한 추가 4x4 이미지. 명도 1차원만 고려한 그래프다.
이미지 히스토그램 계산, 생성하는 파이썬 코드
cv2.calcHist(images, channels, mask, histSize, ranges, accumulate=None, normType=cv2.NORM_L2)파라미터 설명
channel: 히스토그램을 표현할 수 있는 채널 3가지.
OpenCV의 cv2.calcHist 함수는 HSV(Hue, Saturation, Value) 색공간으로 히스토그램 표현한다.
히스토그램 계산을 위해서는 RGB 색공간에서 HSV으로 이미지를 변환한 후, 계산을 진행한다.- 0 Hue: 색상
- 1 Saturation: 채도
- 2 Value: 명도
channels=[1]: Saturation 채널에 대한 히스토그램을 계산.
-
Mask: 일부 해상도 측정.
그렇다면 굳이 TEMPLATE MATCHING 안 쓰고 MASK를 조정해서 쓰면 되지 않을까?
Mask = None: 마스크를 사용하지 않고, 모든 화소에서 히스토그램을 계산.
-
histSize: 각 채널별 bin의 개수를 지정.
ex)histSize = [180,256]: hue를 위한 bin 개수 180개, saturation을 위한 bin 개수 256개 (hist.shape으로 확인 가능)
normType에 따라 앞 파라미터들의 사용법이 달라진다. -
ranges: 히스토그램 빈(bin)의 범위
ranges=[0, 256]: 0부터 256까지만 히스토그램값 계산. -
normType: 정규화 방법.cv2.NORM_MINMAX: 최솟값이 0, 최댓값이 지정한 값(보통 1 또는 255)이 되도록 정규화cv2.NORM_L1: L1 노름이 1이 되도록 정규화cv2.NORM_L2: L2 노름(Euclidean norm)이 1이 되도록 정규화 (기본값)
참고 블로그:
https://seokii.tistory.com/16
코드 예시
import cv2
# 이미지 로드
img = cv2.imread('image.jpg')
# BGR에서 HSV 색공간으로 변환
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# 히스토그램 계산
hist = cv2.calcHist([hsv], [0, 1], None, [180, 256], [0, 180, 0, 256])
# 2차원 히스토그램 시각화
hist_img = np.zeros([256, 360, 3], dtype=np.uint8)
cv2.normalize(hist, hist, 0, 255, cv2.NORM_MINMAX)
for x in range(180):
for y in range(256):
hist_img[256 - y, x] = (hist[x, y], hist[x, y], hist[x, y])
cv2.imshow('2D Histogram', hist_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 출처: 클로드 짱- [hsv]: 입력 이미지 배열.
- [0, 1]: Hue 채널(0)과 Saturation 채널(1)을 지정.
- None: 마스크 이미지를 지정하지 않음.
- [180, 256]: Hue 채널에 대해 180개의 bin, Saturation 채널에 대해 256개의 bin을 사용.
- [0, 180, 0, 256]: Hue 채널은 0~180 범위, Saturation 채널은 0~256 범위를 사용.
- 계산된 2차원 히스토그램은 hist에 저장되며, 이를 시각화하기 위해 cv2.normalize()를 사용하여 0~255 범위로 정규화한다.
- 2차원 배열(hist_img)에 히스토그램 값을 할당하여 이미지로 렌더링한다.
