Java
Java 컬렉션 프레임워크
배열을 사용하다보면 여러가지 비효율적인 문제가 생김.
가장 큰 문제는 크기가 고정적이라는 것.
- 배열의 크기는 생성할 때 결정되며 그 크기를 넘어가게 되면 더이상 데이터를 저장할 수 없음.
- 또 데이터를 삭제하면 해당 인덱스는 데이터가 비어있어 메모리가 낭비됨
따라서 자바는 배열의 이러한 문제점을 해결하기 위해, 널리 알려져있는 자료구조를 바탕으로 객체나 데이터들을 효율적으로 관리 (추가, 삭제, 검색, 저장)할 수 있는 자료구조들을 만들어놓음.
이런 자료구조들이 있는 라이브러리를 컬렉션 프레임워크라고 한다.
대표적으로 크게 List, Set, Map이 있다.
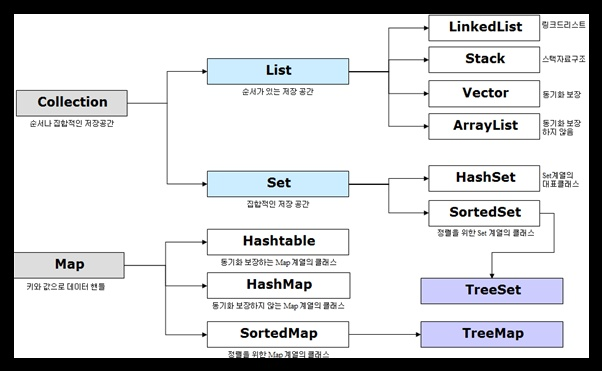
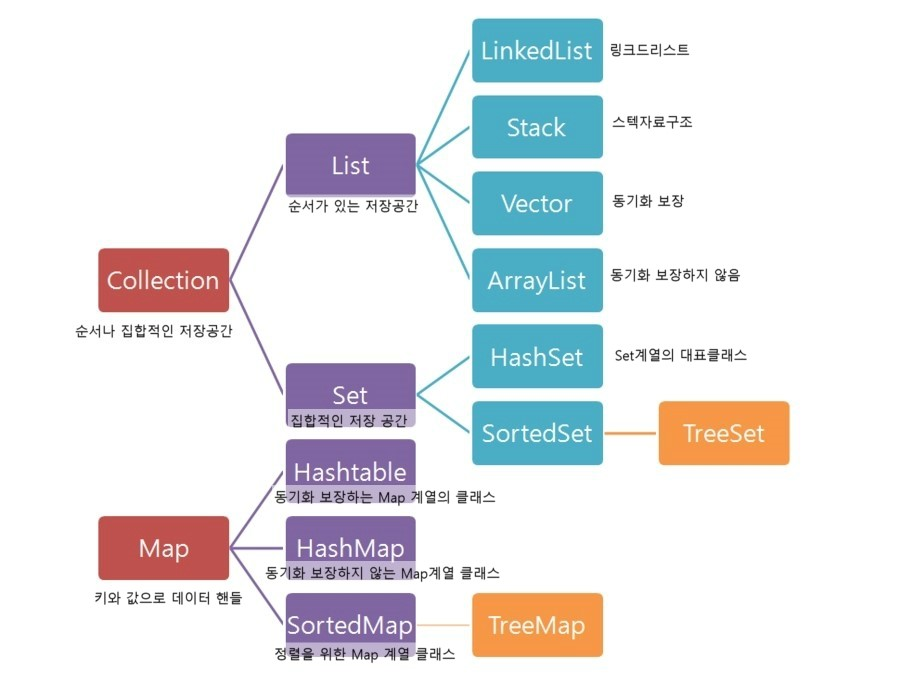
각 인터페이스의 특징
출처 :
https://hackersstudy.tistory.com/26
https://2ssue.github.io/programming/190424_PJI/
| 인터페이스 | 구현 클래스 | 특징 |
|---|---|---|
| List | LinkedList Stack Vector ArrayList | 순서가 있는 데이터의 집합. 데이터의 중복 허용 |
| Set | HashSet TreeSet | 순서를 유지하지 않는 데이터의 집합. 데이터의 중복을 허용하지 않음 |
| Map | HashMap TreeMap HashTable | 키(key)와 값(value)의 쌍으로 이루어진 데이터의 집합. 순서는 유지되지 않고, 키는 중복을 허용하지 않으며, 값은 중복을 허용 |
| 인터페이스 | 구현 클래스 | 특징 |
|---|---|---|
| List(중복 허용) | ArrayList | 배열같은 List, 순서대로 메모리 잡히는 List |
| LinkedList | 리스트 배열과 비슷하지만, 주소로 순서정하는 List | |
| vector, stack | 이것도 리스트 | |
| Set(중복 허용 X) | HashSet | 무작위로 값을 담는 Set, 효율좋다. |
| LinkedHashSet | 넣은 순서대로 값을 담는 Set | |
| TreeSet | 자동정렬해서 값을 담는 Set, 가장 바쁨 | |
| Map(key,value)쌍 | HashMap | 무작위로 키와 값이 담기는 Map |
| LinkedHashMap | 넣은 순서대로 키와 값이 담기는 Map | |
| TreeMap | 키값으로 정렬되어 담기는 Map |
Collection Interface
모든 컬렉션의 상위 인터페이스로 컬렉션들이 갖고있는 핵심 메서드를 선언
(add, contain, isEmpty, remove, size, iterator ...)
List
특징
- 인스턴스의 저장 순서를 유지
- 동일한 인스턴스의 중복 저장 허용
- 인덱스(Index)를 이용한 접근 가능
ArrayList
- 내부적으로 배열을 생성해서 인스턴스를 저장
- capacity보다 많은 인스턴스를 저장할 필요가 생기면, 내부적으로 capacity를 늘린다. (배열의 길이를 늘린다는 것은 더 긴 배열을 생성해서 교체한다는 것을 의미, 한번 생성된 배열은 길이를 늘릴 수 없으므로)
- 장점
- 저장된 인스턴스의 참조가 빠르다.
- 인덱스 값을 통해 원하는 위치에 바로 접근할 수 있다. O(1)
- 단점
- 저장공간을 늘리는 과정에서 시간이 비교적 많이 소요
- 인스턴스 삽입, 삭제 과정에서 많은 연산이 필요할 수 있음 (O(n)) 따라서 느릴 수 있다.
Vector
- ArrayList의 구버전, 모든 메소드가 동기화되어있다.
- 잘 사용되지 않음
LinkdedList
- 연결리스트 자료구조를 기반으로 디자인된 클래스
- 삽입시 새로운 노드를 생성하고 포인터 연결만 해주면 되기 때문에 ArrayList보다 삽입 삭제에 부하가 적다. O(1)
- 양방향 포인터 구조로 데이터의 삽입, 삭제가 빈번할 경우 빠른 성능 보장
- 그러나 리스트에 저장된 인스턴스에 인덱스로 접근시 순차 탐색을 해야하므로 ArrayList에 비해 느리다. (O(n))
- 스택, 큐, 양방향 큐 등을 만들기 위한 용도로 사용
- LinkedList는 Deque, List, Queue 모두 구현함
Set
특징
- 저장 순서가 유지되지 않는다.
- 저장되는 인스턴스의 중복을 허용하지 않는다.
- 중복 판단 기준은 Object클래스에 정의되어있는 다음 두 메소드의 호출 결과를 근거로한다.
public boolean equals(Object obj)public int hashCode(): 인스턴스가 저장된 주소값을 기반으로 반환값이 만들어지도록 정의되어있음
- 인스턴스가 다르면 Object 클래스의 hashCode()는 다른 값을 반환
- 인스턴스가 다르면 Object 클래스의 equals()는 false를 반환
- 즉 Object클래스의 hashCode와 equals는 저장하고 있는 값을 기준으로 인스턴스의 동등여부 판단하지 않음
- 따라서 값을 기준으로 인스턴스의 동등여부를 따지도록 오버라이딩 해야한다.
- 하지만 클래스를 정의할 때마다, 모든 멤버변수와 해시 알고리즘의 성능적 측면까지 고려하면서 hashCode()를 정의하는 것은 쉽지 않다.
- 따라서 자바에서는 Objects 유틸 클래스에 static 메서드로 hash()함수를 제공한다.
- 따라서 클래스에서 hashCode를 오버라이딩 할때 Objects.hash()메소드를 이용해서 오버라이딩 하자
@Override
public int hashCode() {
// hash 함수는 가변인자를 받는다. 따라서 멤버변수 다 전달해주면 됨
return Objects.hash(model, color);
}HashSet
- 가장 빠른 임의 접근 속도 : O(1)
- 순서를 전혀 예측할 수 없다.
- 저장된 순서와 출력되는 순서가 다를 수 있음
- Iterable을 구현하기 때문에 Iterator를 얻어서 순회 가능하지만, 입력 순서대로 순회는 보장하지 않는다.
- Set에서 말했듯이 중복을 허용하지 않으므로, 저장되는 객체의 동일함 여부를 알기 위해 equals()와 hashCode() 메소드를 재정의(오버라이딩)해야한다.
참고 : HashSet 입력순서
TreeSet
- 정렬된 순서대로 보관하며 정렬방법 지정 가능 (데이터 하나하나 저장할때 정렬한다, 이진탐색트리 기반으로 저장하기때문)
- Comparable 인터페이스를 구현하거나, 생성자의 인자로 Comparator을 구현한 인스턴스 전달해주면 된다.
LinkedHashSet
- Set 인터페이스를 구현하고 HashSet 클래스를 상속받은 LinkedList
- 순회시 인스턴스가 입력된 순서를 보장한다.
- null을 허용
- performance는 hashSet보다 약간 떨어진다.
- 동기화가 되지 않는다.
Map
key value 쌍으로 연관지어 객체를 저장
HashMap
- 중복을 허용하지 않고 순서를 보장하지 않음
- 키와 값으로 null 허용
HashTable
- HashMap보다 느리지만, 동기화 지원
- 키와 값으로 null 허용하지 않음
TreeMap
- 이진 검색 트리의 형태로 키와 값의 쌍으로 이루어진 데이터 저장
- 정렬된 순서로 키/값 쌍을 저장하므로 빠른 검색 가능 (정렬기준은 당연히 Key이다.)
- 저장시 정렬(오름차순)을 하기 때문에 저장시간이 다소 오래 걸림
LinkedHashMap
- 입력된 순서를 보장
- 기본적으로 HashMap을 상속받아 HashMap과 매우 흡사
- Map에 있는 엔트리들의 연결리스트를 유지하므로, 입력한 순서대로 반복가능
출처 : https://2ssue.github.io/programming/190424_PJI/
한줄정리 : Java List Set Map 차이 + StringBuffer StringBuilder 차이
Primitive 타입과 Wrapper 타입
Primitive Type
- Java에서는 총 8가지의 Primitive Type을 미리 정의하고 제공함
- boolean(1 byte)
- char(2 byte)
- byte(1 byte), short(2 byte), int(4 byte), long(8 byte)
- float(4 byte), double(8 byte)
- 객체가 아니기 때문에 null 값을 가질 수 없다.
- OS에 따라 자료형의 길이가 변하지 않는다.
- Primitive Type에 null을 넣고싶다면 Wrapper Class를 활용
- Stack 메모리에 저장된다. (지역변수기 때문에?)
- 기본형 변수는 값을 그대로 저장, 반면 참조형 변수는 객체의 레퍼런스를 저장한다.
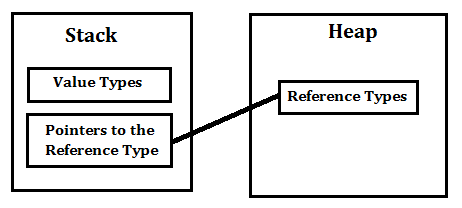
Reference Type (참조형 타입)
- Java에서는 Primitive Type을 제외한 타입들이 모두 Reference Type
- Reference Type은 Java에서 최상위 클래스인 java.lang.Object 클래스를 상속하는 모든 클래스를 의미
- new 키워드를 통해 인스턴스를 생성
- Heap 영역에 인스턴스가 생성되고, Garbage Collector가 돌면서 메모리를 해제함
- 클래스 타입, 인터페이스 타입, 배열 타입, 열거 타입이 있다.
- 빈 객체를 의미하는 null이 존재
왜 기본형과 참조형 두 개념이 있을까?
참고 : https://sowells.tistory.com/162
기본형도 참조형처럼 레퍼런스를 참조하게 되면 개발자가 구분할 필요없을 것 같은데 왜 차이를 둘까?
일단 기본형을 참조형처럼 레퍼런스로 참조하는 방식을 쓰면, 기본형으로 사용했을때에 비해 참조 비용이 증가한다.
변수가 몇개 안되면 성능차이가 안느껴질 수도 있겠지만, int[]의 사이즈가 매우 크다고 생각했을 때, 모든 요소를 참조할 때마다 힙영역의 메모리 주소를 또 다시 참조해야한다고 하면 비용차이가 커질 수 있다.
문자열 클래스
| 분류 | String | StringBuffer | StringBuilder |
|---|---|---|---|
| 변경 | Immutable | Mutable | Mutable |
| 동기화 | Synchronized 가능 (Thread Safe) | Synchronized 불가능 |
String
특징
- new 연산을 통해 생성된 인스턴스의 메모리 공간은 변하지 않는다 (Immutable)
- Garbage Collector 로 제거되어야한다.
- 문자열 연산시 새로 객체를 만드는 오버헤드 발생
- 객체가 불변하므로 멀티 스레드 환경에서 동기화를 신경쓸 필요가 없다. (조회 연산에서 매우 큰 장점이다.)
정리
문자열 연산이 적고, 조회가 많은 멀티스레드 환경에서 좋다.
StringBuffer, StringBuilder
공통점
- new 연산으로 클래스를 **"한번만" 만든다. (Mutable)
- 문자열 연산시 새로 객체를 만들지 않고, 크기를 변경시킨다.
- StringBuffer와 StringBuilder는 클래스의 메소드가 동일하다.
차이점
- StringBuffer는 Thread Safe하다.
- StringBuilder는 Thread Safe하지 않다. (그래서 여러 스레드에서 참조되지 않는 경우 이게 성능 더 좋으니 이거 사용)
정리
- StringBuffer : 문자열 연산이 많은 Multi Thread 환경
- StringBuilder : 문자열 연산이 많은 Single Thread 또는 Thread를 신경쓰지 않는 환경
고유락과 Synchronized 블록
자바의 모든 객체는 락(lock)을 갖고있다.
모든 객체가 갖고있으니 고유락(intrinsic lock)이라고도 하고,
모니터처럼 동작한다고 하여 모니터 락(monitor lock)혹은 그냥 모니터(monitor)라고도 한다.
자바의 synchronized 블록은 동시성 문제를 해결하는 가장 간편한 방법으로, 고유락을 이용하여 여러 스레드의 접근을 제어한다.
public Class Counter {
private int count; // 공유변수(공유자원)
public int increase() {
return ++count; // Thread Safe하지 않은 연산
}
}위에서 정의한 Counter Class는 숫자를 셀 때 사용하는 클래스로, increase()를 호출할 때마다 count 변수를 1만큼 증가하고, 그 값을 반환한다.
++count 문은 한줄짜리 코드로 원자적(atomic)으로 동작할 것 같지만, 사실 그렇지 않다.
++연산자를 호출했을 때, 실제로는 세 가지 연산이 순차적으로 수행된다.
- 변수를 메모리에서 읽고 (CPU의 캐시로 가져온다. read한다.)
- 증가시키고 (CPU가 연산한다.)
- 다시 메모리에 쓴다. (다시 메모리에 write한다.)
이는 동시성 프로그래밍에서 문제가 되는 전형적인 Read - Modify - Write 패턴이다.
두 스레드가 동시에 같은 값을 읽고, 값을 증가시켜 저장하면, increase() 호출 횟수와 count값에 차이가 발생한다.
동시성 문제는 결국 여러 스레드가 공유자원으로 접근하기 때문에 발생한다. 여기서 공유자원은 count 변수이다.
동시성 문제를 해결하기 위해 count변수로 접근하는 스레드들을 제어해야한다.
이제 고유락 즉, synchronized 블록을 이용하여 Counter 클래스를 Thread Safe하게 만들어볼 것이다.
public class Counter {
private Object lock = new Object();
private int count;
public int increase() {
synchronized(lock) {
return ++count;
}
}
}lock이라는 Object 인스턴스를 이용하여 여러 스레드가 동시에 count 변수에 접근하지 못하도록 제어했다. (인스턴스는 고유락을 가지고있으니, lock인스턴스가 lock 자체라 생각하면된다.)
이제 increase()는 한 번에 한 스레드만 실행할 수 있다.
그리고 사실 이 코드에서 락을 위해 별도의 객체를 생성할 필요가 없다. Counter 인스턴스도 자바 객체이므로 락으로 사용할 수 있다.
public class Counter {
private int count;
public int increase() {
synchronized(this) {
return ++count;
}
}
}this를 이용하여 별도의 락 생성없이 synchronized 블록을 구현했다.
하지만, 좀 더 쉽게 구현할 수 있다.예제의 synchronized 블록은 increase() 메서드 전체를 감싸고 있는데, 이런 경우에는 메서드에 synchronized 키워드를 붙여주는 것으로 대신할 수 있다.
public class Counter {
private int count;
public synchronized int increase() {
return ++count;
}
}재진입 가능성 (Reentrancy)
자바의 고유락은 재진입 가능하다.
재진입이 가능하다는 것은 락의 획득이 호출 단위가 아닌 스레드 단위로 일어난다는 것을 의미한다.
이미 락을 획득한 스레드는 같은 락을 얻기 위해 대기할 필요가 없다. 이미 락을 갖고있으므로, 같은 락에 대한 synchronized 블록을 만났을 때 대기없이 통과한다.
public class Reentrancy {
public synchronized void a() {
System.out.println("a");
// b가 synchronized로 선언되어 있지만 a진입시 이미 락을 획득하였으므로,
// b를 호출할 수 있다.
b();
}
public synchronized void b() {
System.out.println("b");
}
public static void main(String[] args) {
new Reentrancy().a();
}
}만약 자바의 고유락이 재진입 가능하지 않다면 위 코드는 a 메서드 내부의 b를 호출하는 지점에서 데드락이 발생한다. (자기가 가지고 있는 락을 가지기 위해 대기함 ㅋㅋㅋ)
구조적인 락(Structured Lock)
고유락을 이용한 동기화를 구조적인 락이라고 한다.
synchronized 블록 단위로 락의 획득/해제가 일어나므로 구조적이라고 한다.
synchronized 블록을 진입할 때 락의 획득이 일어나고, 블록을 벗어날 때 락의 해제가 일어난다.
따라서 구조적인 락 A와 B가 있을 때,
A획득 -> B획득 -> B해제 -> A해제는 가능하지만,
A획득 -> B획득 -> A해제 -> B해제는 불가능하다. (A를 해제하려면 A블럭을 빠져나가야하는데, 그러기 위해선 먼저 B블럭을 빠져나가야 하기 때문)
이런 순서로 락을 사용해야하는 경우라면 ReentrantLock과 같은 명시적인 락을 사용해야한다.
가시성 (Visibility)
동시성 프로그램의 이슈중 하나는 가시성이다.
"synchronized를 적용하기 이전의 Counter 예제"로 돌아가보자. 이 코드는 두 스레드가 절대로 동시에 increase()를 호출하는 일이 없다고 해도 문제가 있다. (동시에 공유변수에 write하지 않는다.)
한 스레드가 쓴 값을 다른 스레드가 볼 수도 있고, 그렇지 않을 수도 있기 때문이다. 이를 가시성 문제라고 한다. (동시에 공유변수를 write하진 않아서 결과값은 제대로 수행되지만, 동시에 read 할 수 있기 때문에 결과가 적용된 값을 제대로 읽는다는 보자이 없다. 마치 DB의 repeatable read가 보장 안되는 것과 비슷)
이 문제의 원인은 다양하다. 최적화를 위해 컴파일러나 CPU에서 발생하는 코드 재배열 (Reordering) 때문에 이런 문제가 발생할 수도 있고, 멀티 코어 환경에서는 코어의 캐시 값이 메모리에 제때 쓰이지 않아 문제가 발생할 수도 있다.
락을 사용하면 가시성 문제가 사라질까? 그렇다.
자바에서는 스레드가 락을 획득하는 경우, 그 이전에 쓰였던 값들의 가시성을 보장한다. (락을 획득하는 순간 획득하기 이전의 값들을 믿고 사용할 수 있다. 최신 값임을 보장한다.)
synchronized가 적용된 Counter 예제에서 스레드 A, 스레드 B 순서로 increase()를 호출했을 때, 스레드 B는 스레드 A가 쓴 값을 읽을 수 있다. (visible하다.)
이는 고유락 뿐만아니라 ReentrantLock같은 명시적인 락에서도 똑같이 적용된다.
출처 : http://happinessoncode.com/2017/10/04/java-intrinsic-lock/
Concurrent Programming 동시성 프로그래밍, 가시성, 원자성
Object Class
가지고 있는 메서드
- toString()
- hashCode()
- wait()
- 갖고 있던 고유 lock 해제, Thread를 잠들게 함
- notify()
- 잠들어있던 Thread중 임의의 하나를 깨움
- notifyAll()
- 잠들어있던 Thread를 모두 깨움
wait, notify, notifyAll
- 호출하는 스레드가 반드시 대상 객체의 고유락을 가지고 있어야한다.
- 다시말해 Synchronized 블록 내에서 실행되어야한다.
- 고유락을 획득하지 않은 상태에서 위의 메서드를 호출하는 경우 IllegalMonitorStateException 발생
- wait()
- 호출하면 락을 해제하고, 스레드는 잠이 든다.
- 누군가가 깨워줄 때까지 wait()은 리턴되지 않는다.
- notify(), notifyAll()
- wait()로 잠든 스레드를 깨운다.
- notify()는 어느 스레드를 깨울지 선택할 수 없기 때문에 제어가 어렵다.
- 그래서 보통은 notifyAll()을 사용한다.
- notifyAll()은 모든 스레드를 깨우긴 하지만, 이 메서드가 호출된다고 해서 잠들어있던 모든 스레드가 동시에 동작하는 것은 아니다.
- wait()로 잠든 코드가 synchronized 블록 안에 있다는 것을 떠올려봐라.
- notifyAll()로 깨어난 스레드들은 다시 락을 획득하기 위해 경쟁해야한다.
- 락을 획득한 스레드만이 wait()함수를 리턴시키고, 그 다음 로직을 수행할 수 있다.
참고 : http://happinessoncode.com/2017/10/05/java-object-wait-and-notify/
예외처리
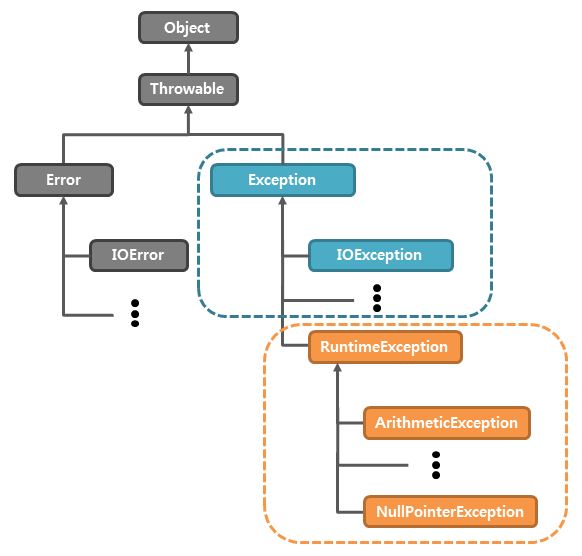
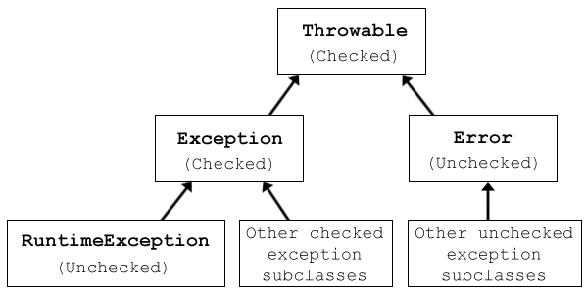
자바의 예외 클래스의 최상위 클래스는 바로 Throwable이다.
이를 상속하는 예외 클래스는 3가지 부류로 나뉜다.
- Error 클래스를 상속하는 예외 클래스
- Exception 클래스를 상속하는 예외 클래스
- RuntimeException 클래스를 상속하는 예외 클래스
- RuntimeException은 Exception을 상속한다.
Error
Error는 시스템레벨에서 발생하며, 개발자가 어떻게 조치할 수 없는 수준을 의미한다.
개발자가 어떻게 조치할 수 없기 때문에, 처리할 수 있는 예외가 아니다
➡ 예외 처리를 강제하지 않는다.
➡ unchecked
예시
- VirtualMachineError : 가상머신에 심각한 오류 발생
- OutOfMemoryError : VirtualMachineError를 상속하는 예외 클래스로, 이는 프로그램의 실행에 필요한 메모리 공간이 부족한 상황에서 발생하는 예외이다. 따라서 이 예외가 발생하면 메모리를 비효율적으로 또는 부적절하게 사용하는 부분의 코드를 수정해야한다.
- IOError : 입출력 관련해서 코드 수준으로 복구가 불가능한 오류 발생
Exception
Exception은 또 2가지로 나눌 수 있다.
- Checked Exception
- Unchecked Exception
Checked Exception
예외처리가 필수이며, 처리하지 않으면 컴파일되지 않는다. JVM 외부와 통신(네트워크, 파일, 시스템 등)할 때 주로 쓰인다.
- RuntimeException 이외의 모든 Exception
- IOException, SQLException 등
try catch문으로 예외처리를 하거나, throws해서 호출한쪽에 예외 처리를 위임하거나 해야한다.
예외처리를 명시적으로 해야한다.
Unchecked Exception
컴파일때 체크되지 않고(unchecked), Runtime에 발생하는 Exception
RuntimeException이 발생하는 대표적인 예시 코드를 보겠다.
// NegativeArraySizeException 예외 발생
Object[] arr = new Object[-5];위의 상황은 코드를 수정해야할 상황이지 예외처리를 해야할 상황이 아니다.
물론 상황에 따라 프로그래머가 예외 처리를 해야하는 경우도 있을 수 있다. (NPE의 경우 있을 수 있음)
따라서 예외 처리를 강제하지 않는다. (코드를 수정해야하는 상황이지 프로그램 돌려놓고 예외처리하는게 아니다.)
JVM Garbage Collector
테코톡 : https://www.youtube.com/watch?v=Fe3TVCEJhzo
Stop the World
GC를 실행하기 위해 JVM이 애플리케이션 실행을 멈추는 것
어떤 GC 알고리즘을 사용하게 되더라도 "Stop the World"는 발생하게 되는데, 대부분의 GC 튜닝은 이 "Stop the World" 시간을 줄이는 것.
GC를 해도 더이상 사용가능한 메모리 영역이 없는데, 계속 메모리 할당을 하려고 하면, OutOfMemoryError가 발생하여 WAS가 다운될 수도 있다.
행(Hang) 즉, 서버가 요청을 처리못하고 있는 상태가 된다.
따라서 규모있는 Java 애플리케이션을 효율적으로 개발하기 위해서는 GC에 대해 잘 알아야한다.
Garbage Collection
자바는 C/C++과 달리 개발자가 명시적으로 객체를 해제할 필요가 없다. 자바언어의 큰 장점이기도 하다.
참조되지 않는 객체(Unreachable)를 메모리에서 삭제하는 작업을 GC라고 부르며 JVM에서 GC를 수행한다.
JVM의 메모리 영역은 크게 5가지 (메소드, 스택, 힙, 네이티브 메소드, PC)로 나뉘는데, GC는 힙 메모리만 관리한다.
일반적으로 다음 경우가 GC 대상이된다.
- 객체가 null인 경우
- 블럭 실행 종료 후, 블럭 안에서 생성된 객체
- 부모 객체가 null인 경우 포함하는 자식 객체
GC 메모리 해제 과정
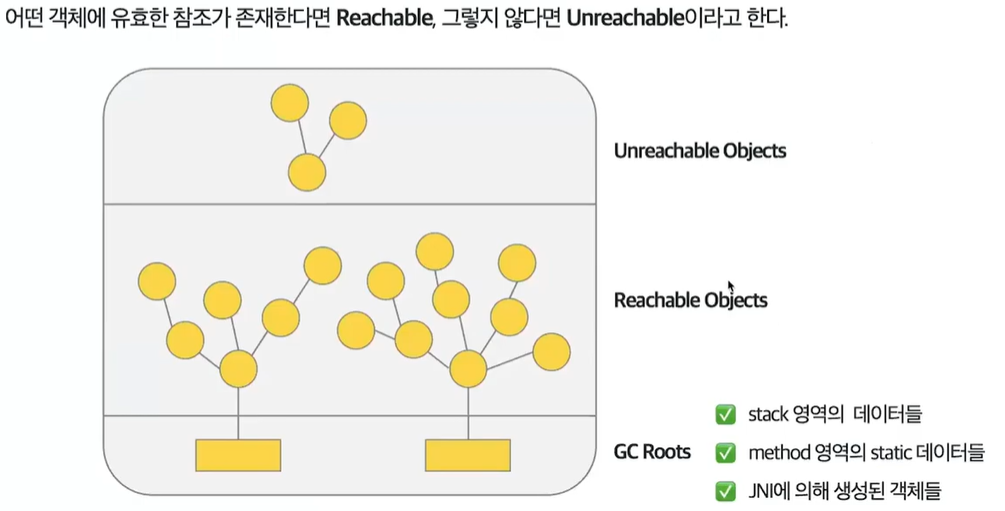
GC Root에서부터 reachable한 Object를 차례로 탐색한다.
탐색결과 unreachable한 객체들을 메모리에서 해제한다.
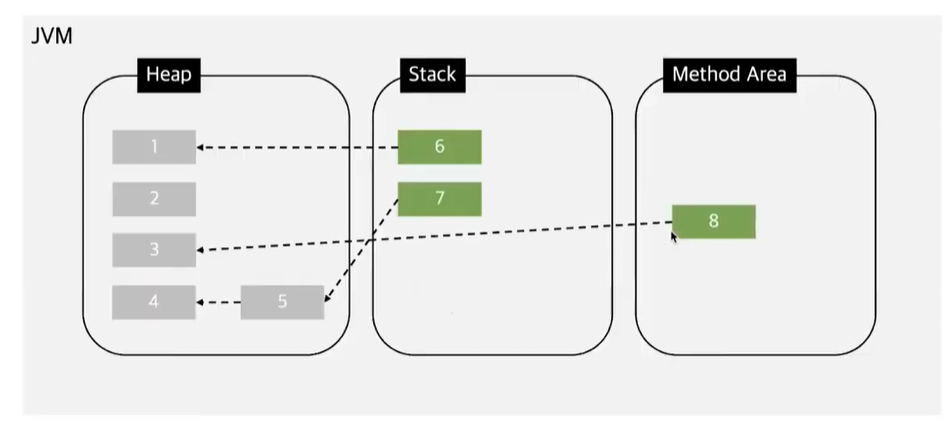
- JVM runtime memory area의 method area에 있는 데이터 (gc root)
- stack 영역의 데이터
- gc root는 아니지만 heap영역안의 객체에게 또 다시 참조되는 객체들
이러한 객체들을 타고타고 탐색해나간다.
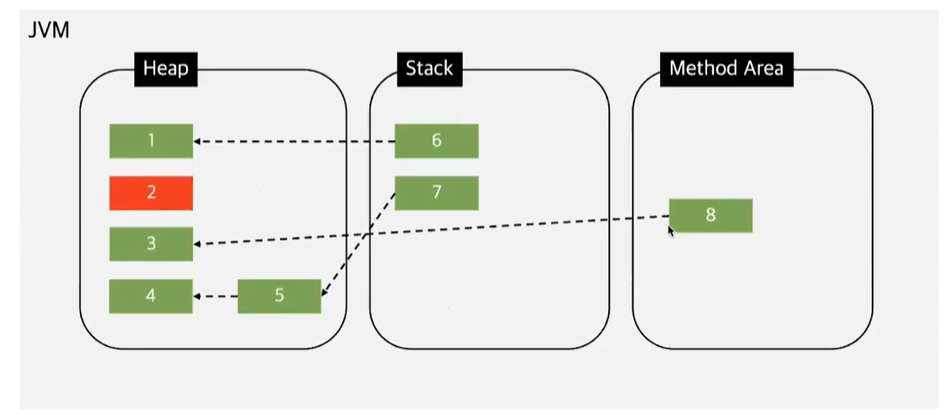
그 결과 어디서도 참조되지 않는 객체만 남는데, 그 객체를 unreachable하다고한다. 그리고 해당 객체가 바로 GC의 수거 대상이다.
GC 과정
- Garbage Collector가 Method영역의 static 변수, Stack의 모든 변수를 스캔하면서 각각 어떤 객체를 참조하고 있는지 찾아서 마킹 (Mark)
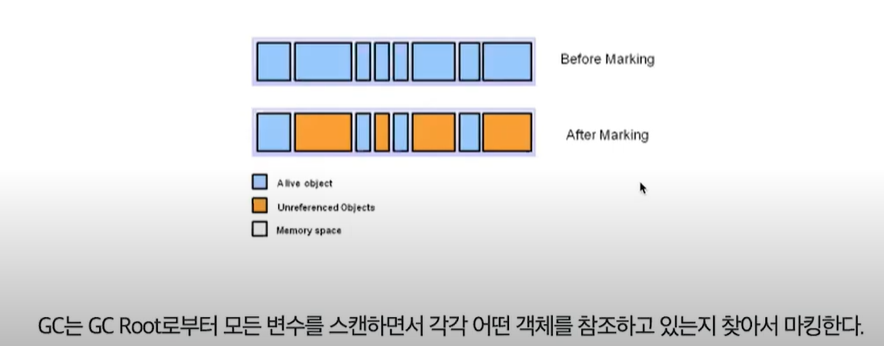
- Reachable Object가 참조하고 있는 객체도 찾아서 마킹 (Mark)
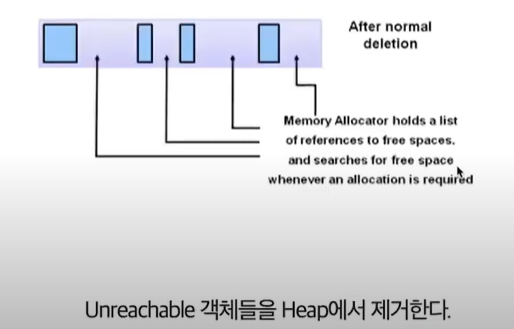
- 마킹되지 않은 객체(Unreachable한 객체)를 Heap에서 제거 (Sweep)
- 알고리즘에 따라서 (Compact) 과정도 추가됨. Sweap 후에 남아있는 객체들을 한 군데에 모아서 메모리 단편화를 막아주는 것
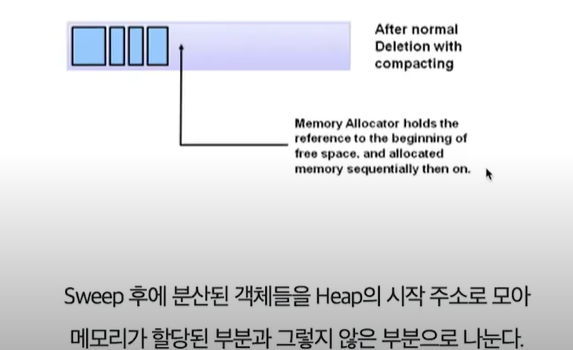
Mark & Sweep (+ Compact) : GC 발생시 수행되는 한 사이클
Heap
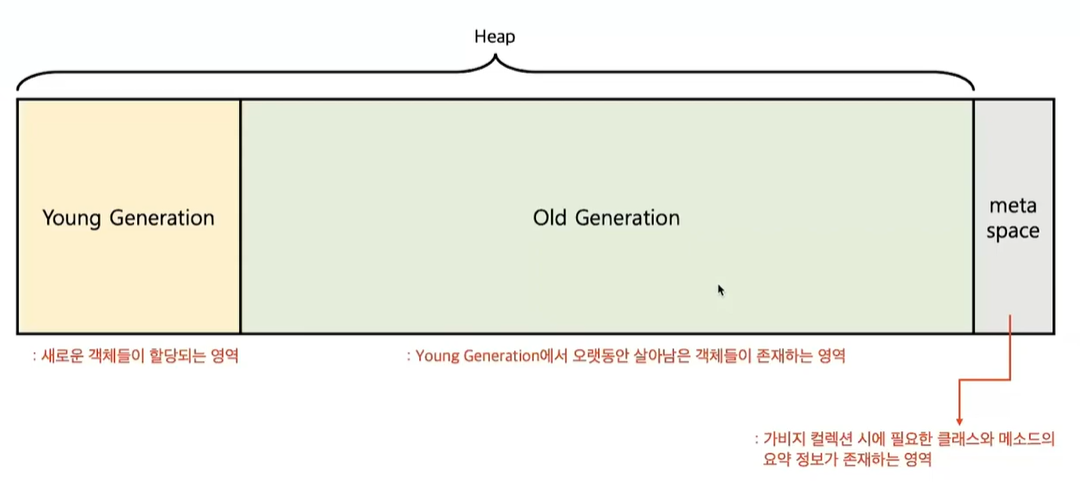
- Heap은 크게 Young Generation과 Old Generation으로 나뉜다.
- Young Generation은 새로 생성된 객체들이 할당되는 공간
- Old Generation은 Young Generation에서 오랫동안 살아남은 객체들이 존재하는 공간
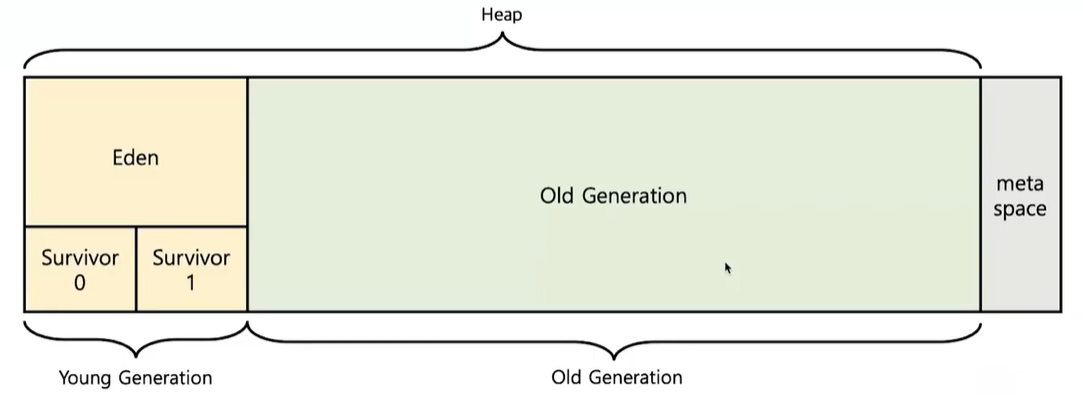
GC 발생시기
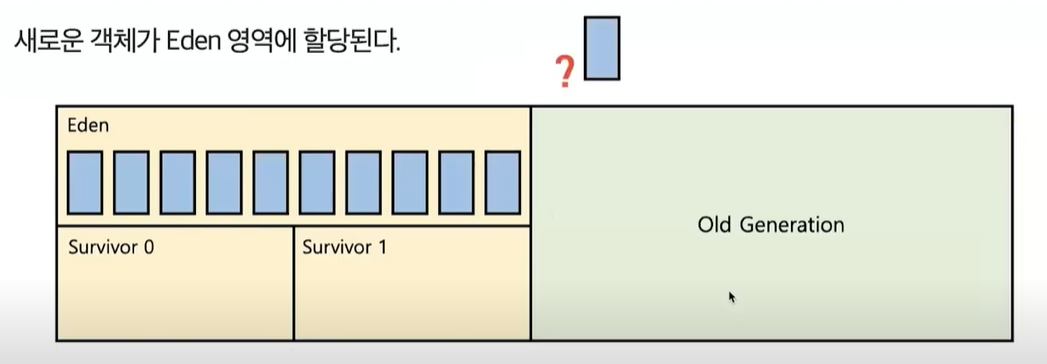
- 새로운 객체들이 Eden 영역에 할당된다
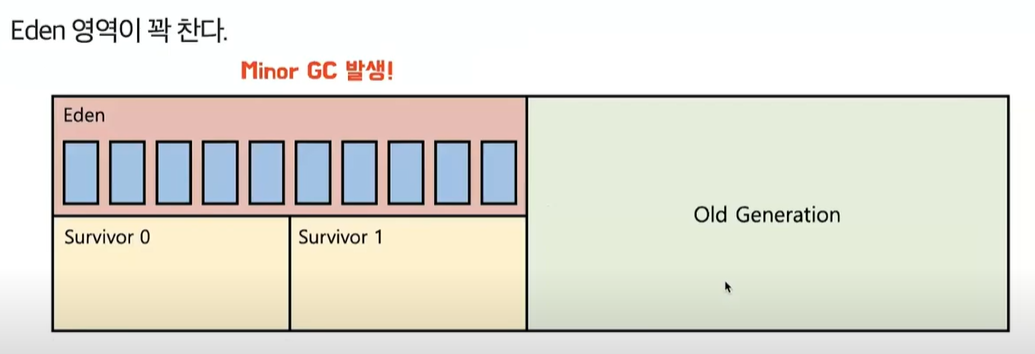
- Eden 영역이 꽉 찬다 (Minor GC 발생 - Young Generation에서 발생하는 GC를 Minor GC라고 한다.)
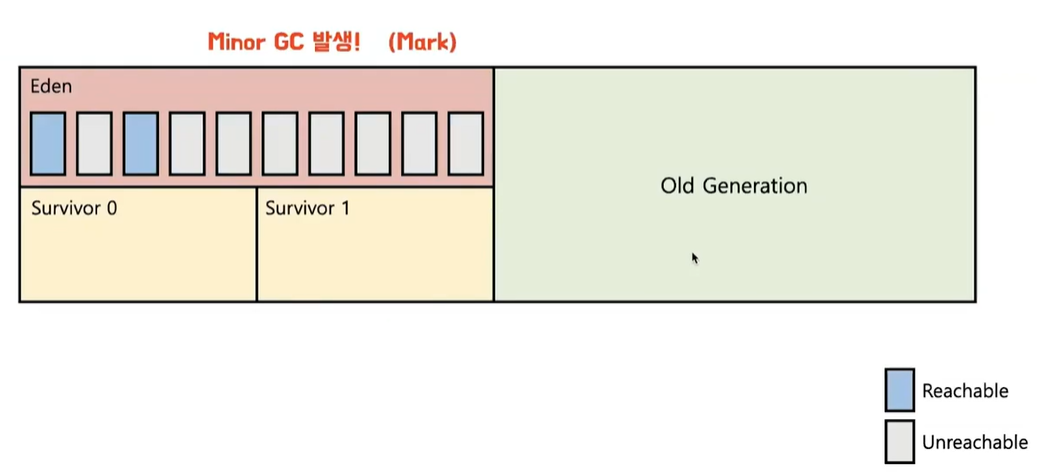
- GC가 발생하면 Mark & Sweap 과정이 일어남.
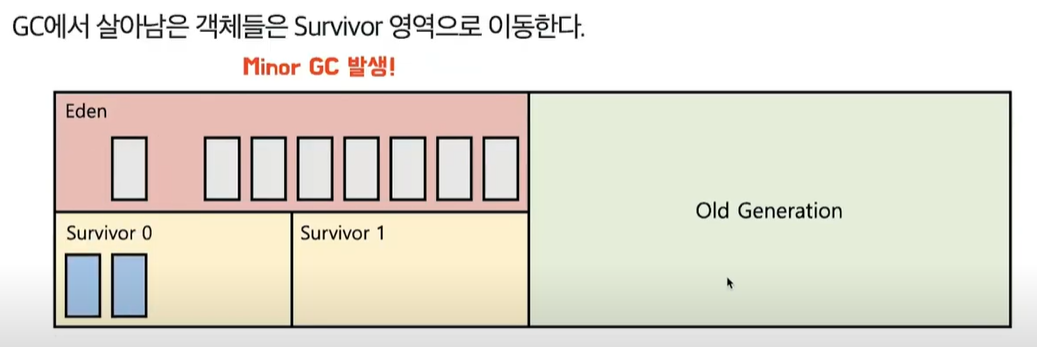
- Mark를 통해 Reachable한 객체를 Survivor 영역으로 이동시킨다.
- survivor 영역에는 규칙이 있는데, 2개의 survivor 영역 중 한 곳에만 인스턴스가 존재할 수 있다.
- Sweep과정을 통해서 unreachable한 객체들이 삭제된다
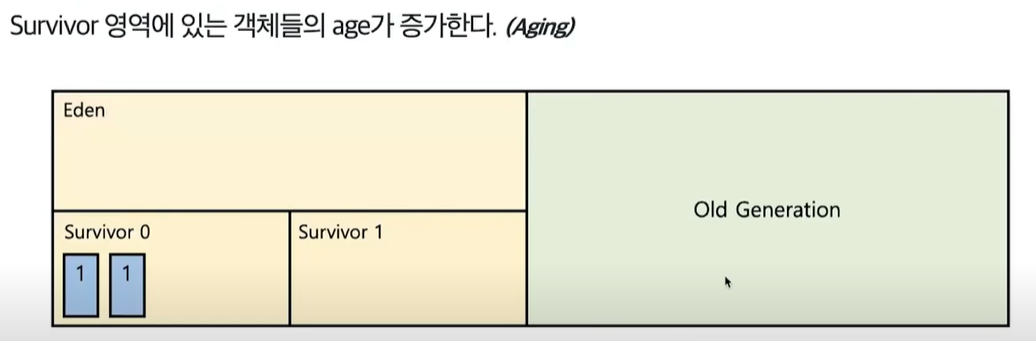
- GC과정을 통해 살아남은 객체들은 age 값이 증가한다.
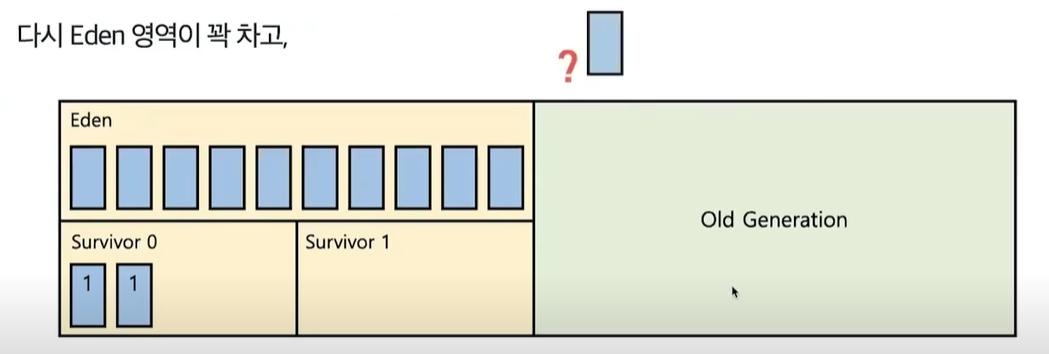
- 다시 Eden 영역에 새로운 객체들이 꽉차고 Minor GC가 일어난다.
- 이번에 살아남은 객체들은 survivor1 영역으로 옮겨간다.
- 이렇게 Minor GC가 한번 발생할 때 마다, survivor 영역을 왔다갔다 한다.
- unreachable한 객체는 지워지고, 또 다시 살아남은 객체의 age 값이 증가한다.
- 해당 과정 계속 반복
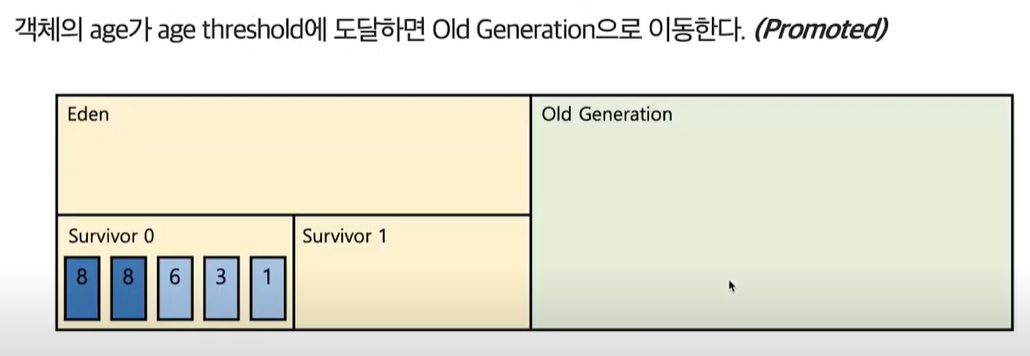
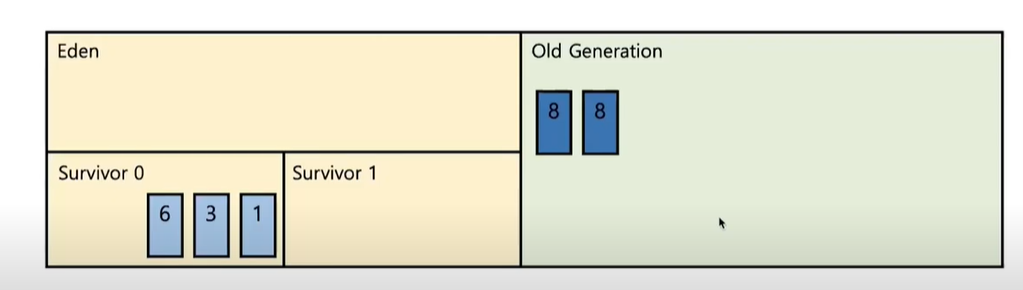
- 객체의 age 값이 특정 임계점(Treshold)를 넘으면 Young Generation에서 Old Generation으로 옮겨간다.
- 이 과정을 Promoted(Promotion)라고한다.
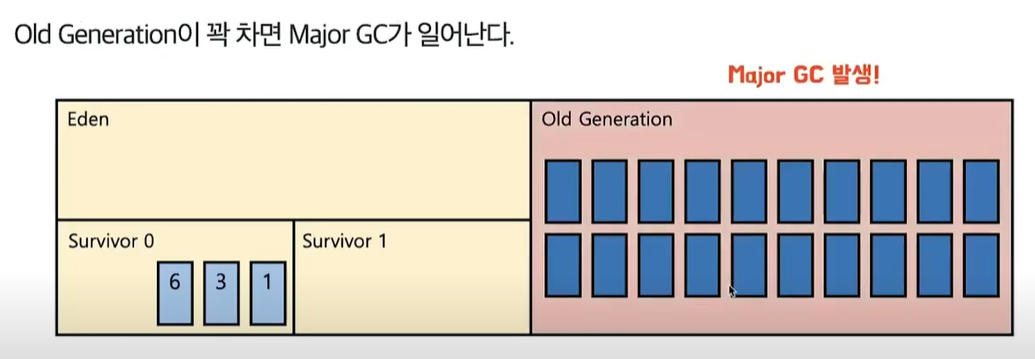
- 계속된 promoted 과정으로 인해 Old Generation이 꽉차게 되면 Major GC가 발생한다.
이렇게 동작하는 이유?
Weak Generational Hypothesis
- 대부분의 객체는 금방 접근 불가능한 상태(Unreachable)가 된다. 즉, 금방 garbage가 된다.
- 오래된 객체에서 젊은 객체로의 참조는 아주 적게 존재한다.
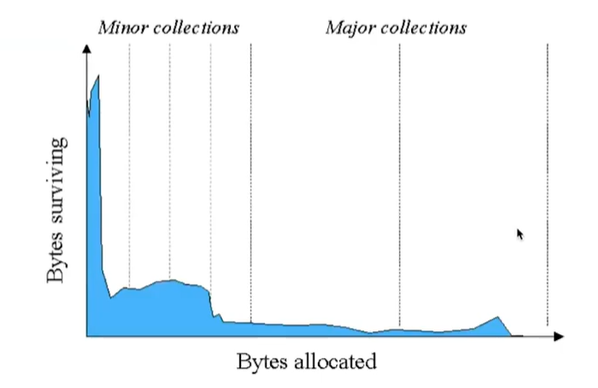
- y축은 할당된 바이트 메모리 크기, x축은 바이트가 할당된 시간
- 시간이 갈 수록 적은 객체들만 남는다.
- 위의 그림을 보면 파란색들이 메모리를 차지하는 객체들이라고 생각하면 된다.
- minor collection은 minor gc, major collection은 major gc
- minor gc를 통해 꽤 많은 객체들이 차지하는 메모리가 줄어듦
- 따라서 minor gc는 좀 빈번하게 일어나도 괜찮음
- 오히려 그게 메모리 낭비를 막을 수 있음
- 따라서 Young Generation이 Old Generation보다 작고, 그래서 금방 차므로 더 자주 일어남
- 반면에 major gc는 한번 일어나도 별로 수거되는 객체들 (garbage collection 되는 객체들)이 별로없다.
GC 종류
Stop the World
GC를 실행하기 위해 JVM이 애플리케이션 실행을 멈추는 것
GC를 실행하는 스레드 외의 모든 스레드가 작업을 중단한다.
종류
- Serial GC
- Parallel GC
- Parallel Old GC
- CMS GC (Concurrent Mark Sweep)
- G1 GC (Garbage First)
Serial GC
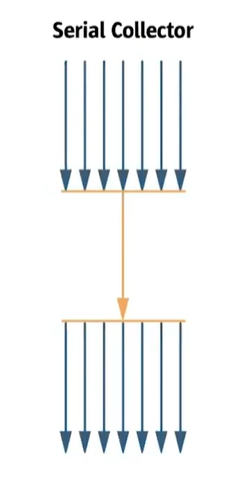
- 가장 단순하고 기본적인 GC
- GC를 처리하는 스레드가 1개 (싱글 스레드)
- 다른 GC에 비해 Stop the world 시간이 길다.
- Mark-Compact(Sweep 포함) 알고리즘 사용
Parallel GC
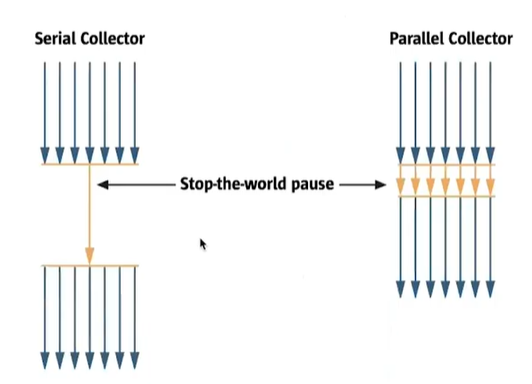
- Java8의 default GC
- Young 영역에 한해서 GC를 멀티스레드로 수행
- 따라서 Serial GC에 비해 stop-the world 시간 감소
Parallel Old GC
- Parallel GC를 개선
- Old 영역에서도 멀티 스레드 방식의 GC 수행
- Mark-Summary-Compact 알고리즘 사용
- Sweep : 단일 스레드가 Old 영역 전체를 훑는다.
- Summary : 멀티 스레드가 Old 영역을 분리해서 훑는다.
CMS GC (Concurrent Mark Sweep)
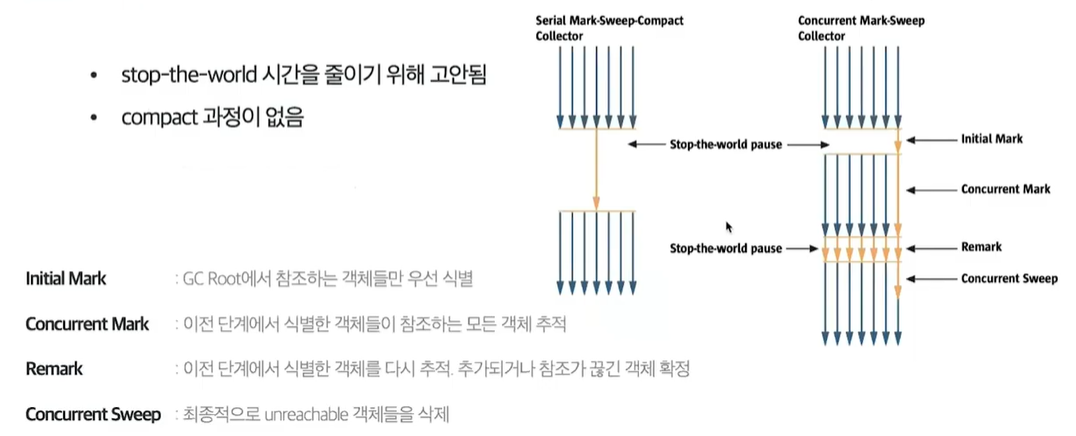
- Stop the world 시간을 줄이기 위해 고안됨
- Compact 과정이 없기 때문에 메모리 단편화 문제가 아쉬움
- reachable한 객체들을 한번에 찾지 않고, 순차적으로 찾는 것이 특징
- GC를 처리하는 스레드는 하나지만, 나머지 스레드들은 계속해서 작업을 진행하고있음
G1 GC (Garbage First)
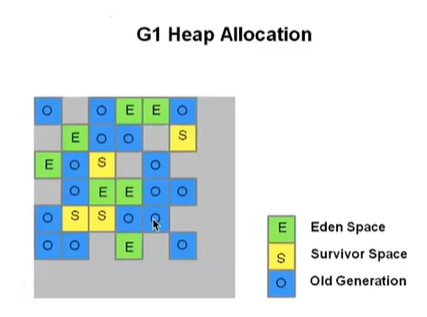
- CMS GC를 개선
- Java 9 이상의 default GC
- 방금 본 CMS GC의 메모리 단편화 문제를 개선한 알고리즘
- Heap 영역을 일정한 크기의 Region으로 나눔
- Young Generation, Old Generation 이렇게 물리적으로 나누지 않고 Region이라는 일정한 크기의 단위로 나눈 것
- Garbage만 있는 Region은 처음에 수거해감 Garbage 1(First)
- 마킹을 할 때, 전체 Heap을 뒤지지 않고 할당된 Region (위에서 할당되지 않은 영역은 회색) 에 대해서만 찾는 방식으로 동작
- 뭔가 개인적인 느낌으로는 이전까지는 세그멘테이션 같은 느낌이고, G1은 페이징 같은 느낌, 그정도 차이아닐까 생각
