데이터베이스
인덱스
목적
RDMS에서 검색 속도를 높이기 위한 기술
테이블의 Column을 색인화한다. (따로 파일로 저장)
-> 해당 테이블의 레코드를 full scan (테이블의 데이터를 처음부터 끝까지 전체 스캔하는 것) 하지 않는다.
-> (B+ 트리 구조로) 색인화된 Index 파일 검색으로 검색속도 향상
배경
인덱스는 책의 목차에 주로 비유됨
하지만 일반적인 책을 생각해보면 목차가 문자열 순으로 되어있지는 않다.
// 목차 예시
1. Intro
2. SQL
3. DML
...
10. Transaction
11. Concurrency Control
...
50. Outro문자열 순이 아닌 책의 내용 순으로, 주요 타이틀을 기준으로 목차를 만든다.
목차가 없는 것보다는 더 편리하지만, 책의 주요 내용을 가나다 순으로 정리한 목록이 있으면, 내가 원하는 특정내용을 더 찾기 쉬울 것이다.
어느정도 두꺼운 책에서는 색인(ES에서 나오던 역색인 - 책의 맨뒤에 단어 가나다순 목록과 등장하는 페이지 적어놓은것)이라는 것을 제공해서 바로 이러한 편의성을 제공한다.
이때 색인은 영어로 Index이며, DB의 Index와 완전히 동일한 기능을 한다.
예시1 - 특정 챕터의 첫 페이지 찾기
10000페이지짜리 데이터베이스 서적이 다음과 같이 테이블에 저장되어있다.
page title
1 Intro
2 Intro
3 Intro
… …
512 SQL
513 SQL
… …
5544 Optimizer
5545 Transaction
5546 Transaction
5547 Transaction
… …
5700 Transaction
5701 Transaction
5702 ConcurrenctControl
5703 ConcurrenctControl
… …
9999 Outro
10000 OutroTransaction 파트는 5545 페이지부터 5701 페이지 까지라는 것을 알 수 있다.
검색방식을 쿼리로 표현하면 아래와 같다. (테이블명은 db_book)
SELECT page
FROM db_book
WHERE title = 'Transaction';말 그대로 db_book이라는 테이블에서 title이 'Transaction'이라는 page를 찾는 것이다.
해당 페이지를 찾으려면 1번 페이지부터 5545페이지까지 전부 확인해보고 나서야 Transaction 파트를 찾을 수 있을 것이다.
그리고 DB입장에서는 5545번 페이지 뿐 아니라 더 뒤쪽에도 'Transaction'이라는 키워드가 있을 수도 있다고 생각한다. (그리고 실제로도 있다.)
결국 DB는 10000건의 데이터를 전체 검색하는 Full Scan을 수행하게 된다.
Full Scan은 말 그대로 테이블의 전체 데이터를 몽땅 순회하는 것이다.
우리가 원하는 정보는 Transaction 파트가 시작하는 5545번 페이지일 뿐, 나머지 페이지는 필요하지 않다.
따라서 고생하는 DB를 위해 인덱스를 만들어줄 것이다.
인덱스도 결국에는 하나의 테이블이다. index_title이라는 테이블을 만들 것이다.
'Transaction'이라는 키워드를 쉽게 찾을 수 있도록 abc 순으로 정렬하면 좋을 것이다.
title page
ConcurrenctControl 5702
ConcurrenctControl 5703
… …
Intro 1
Intro 2
Intro 3
… …
SQL 512
SQL 513
… …
Optimizer 5544
Outro 9999
Outro 10000
… …
Transaction 5545
Transaction 5546
Transaction 5547
Transaction 5700
Transaction 5701편의를 위해 title 컬럼과 page 컬럼의 순서를 바꾸었다.
그리고, 중복된 내용은 해당 내용의 가장 첫 번째 페이지만 남기고 전부 지우자!
title page
ConcurrenctControl 5702
Intro 1
SQL 512
Optimizer 5544
Outro 9999
Transaction 5545편의상 6개의 title외에 다른 title은 없다고 가정한다.
이제 DB는 index_title 테이블에서 6개의 데이터만 찾아보면 되며, 심지어 문자열 순으로 정렬까지 되어있기 때문에 더욱 빠르게 'Transaction'이라는 문자열을 찾을 수 있다.
예시2 - 서점에서 책 찾기
예시 1에서는 인덱스가 얼마나 드라마틱한 성능을 보이는지 설명하기 위해 편의상 인덱스 테이블에서 중복을 제거했지만, 실제로는 인덱스 테이블에서 중복을 제거하는 작업이 들어가지는 않는다.
다음 테이블을 보자
서점에 진열된 책들의 이름, 카테고리, 위치를 저장한 테이블이다.
10000권의 책이 있고, A~Z까지 랜덤한 위치에 진열되어있다.

어떤 사람이 서점에 방문해 카테고리가 java인 책을 모두 구매하려한다.
카테고리가 java인 책의 이름과 위치를 전부 찾기위해 다음과 같이 쿼리했다.
테이블 명은 book_store이다.
SELECT name, location
FROM book_store
WHERE category = 'java'결과는 아래와 같다.
name location
let’s start java A
let’s start java C
java? java! Z
javavara K현재 인덱스가 없기 때문에, 1000개의 데이터를 모두 뒤져서 결과를 찾았을 것이다. (full scan)
이번에도 불쌍한 DB를 위해 인덱스를 만들자
category를 기준으로 데이터를 찾고있기 때문에, category를 기준으로 인덱스 정렬하자
그리고 DB가 쉽게 찾아갈 수 있도록 rowid를 같이 넣어주자.
(다른 column까지 모두 인덱스에 넣어버리면 결국 원본 테이블과 내용이똑같아져서 공간 낭비가 되기 때문에 rowid(주소값)만 넣어주는 것이다. 책의 목차에도 제목과 페이지수만 적혀있을 뿐, 전체 내용이 적혀있지 않듯이...)
category id
… …
C++ 10000
… …
java 1
java 4
java 4222
java 9999
javascript 3
… …
python 2
python 4223
… …인덱스는 문자열 순서대로 정렬되어있기 때문에,
'java'라는 문자열을 계속 검색하다가 'javascript'라는 문자열을 만나는 순간, 이제 더이상 'java'라는 문자열을 존재하지 않는다고 탐색을 종료할 수 있다!!
게다가 내부적으로 데이터를 B-Tree라는 구조에 저장하기 때문에, 'java'라는 문자열을 찾아낼 때 맨 처음부터 순차적으로 조회하는 것보다 훨씬 빠르다.
그리고 찾아낸 rowid값을 기준으로 데이터베이스에 조회하면 그만이다.
인덱스에서 찾아낸 rowid값은 1, 4, 4222, 9999 이므로 다음과 같이 검색하면 된다.
SELECT name, location
FROM book_store
WHERE row_id IN (1, 4, 4222, 9999)book_store 테이블에서 row_id가 1, 4, 4222, 9999인 책의 이름과 위치를 조회하는 쿼리이다.
이때 category = 'java'로 검색하는 것과 무슨 차이가 있을까 의문이 생길 수 있다.
row_id는 사실 데이터를 삽입할 때 DB 내부에서 자동적으로 생성하는 값으로, 해당 row(행)의 고유한 주소값을 가리킨다.
따라서 rowid가 주어지면 DB는 해당 데이터의 위치가 어디있는지 일일이 찾지 않아도 rowid를 통해 바로 접근할 수 있다.
정리하면 이 rowid를 통한 검색은 DB에서 가장 빠르게 데이터를 찾아낼 수 있는 검색 방법이라는 사실을 알고있으면 된다.
즉, 인덱스를 만드는 이유는 바로 이 rowid를 기준으로 데이터를 탐색할 수 있도록 유도해서 쿼리의 성능을 향상시키기 위함이다.
실제 사용시에는 이러한 일련의 과정을 사용자가 직접 입력할 필요없이 다음과 같이 인덱스를 생성해놓으면 내부적으로 알아서 작동한다.
CREATE INDEX index_category ON book_store(category)위와 같이 book_store 테이블의 category 컬럼에 index_category라는 인덱스를 생성한 후, 기존과 똑같이 사용하면 된다. (그럼 내부적으로 위에서 작업했던 과정이 수행되면서 성능 향상된다.)
SELECT name, location
FROM book_store
WHERE category = 'java'출처 : 데이터베이스 인덱스 개념
정의
추가적인 쓰기 작업과 저장공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조
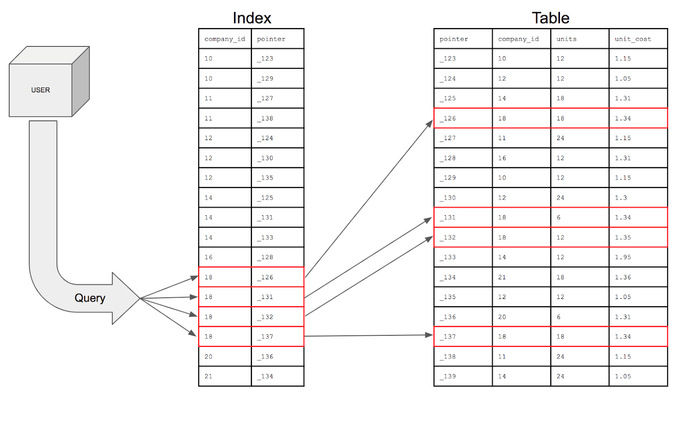
인덱스를 활용하면, 데이터를 조회하는 SELECT 외에도 UPDATE나 DELETE의 성능이 함께 향상된다. 그러한 이유는 해당 연산을 수행하려면 해당 대상을 조회해야만 작업을 할 수 있기 때문이다!!
// Mang이라는 이름을 업데이트해주기 위해선 Mang을 조회해야한다.
UPDATE USER SET NAME = 'MangKyu' WHERE Name = 'Mang';만약 index를 사용하지 않은 컬럼을 조회해야하는 상황이라면 전체를 탐색하는 full scan을 수행해야한다. full scan은 전체를 비교하여 탐색하기 때문에 처리 속도가 떨어진다.
인덱스의 관리
DBMS는 index를 항상 최신의 정렬된 상태로 유지해야 원하는 값을 빠르게 탐색할 수 있다.
그렇기 때문에 인덱스가 적용된 컬럼에 INSERT, UPDATE, DELETE가 수행된다면 각각 다음과 같은 연산을 추가적으로 해줘야하며, 그에 따른 오버헤드가 발생한다.
- INSERT : 새로운 데이터에 대한 인덱스를 추가함
- DELETE : 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업을 진행
- UPDATE : 기존의 인덱스를 사용하지 않음 처리하고, 갱신된 데이터에 대해 인덱스를 추가함
인덱스의 장단점
장점
- 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
- 전반적인 시스템 부하를 줄일 수 있다.
단점
- 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 필요하다.
- 인덱스를 관리하기위해 추가 작업이 필요하다.
- 인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생할 수 있다.
만약 CREATE, DELETE, UPDATE (DML) 가 빈번한 속성(column)에 인덱스를 걸게 되면 인덱스의 크기가 비대해져서 성능이 오히려 저하되는 역효과가 발생할 수 있다.
그러한 이유 중 하나는 DELETE와 UPDATE 연산 때문이다. 앞에서 설명한대로 UPDATE와 DELETE는 기존의 인덱스를 삭제하지 않고 "사용하지 않음"처리를 해준다. 만약 어떤 테이블에 UPDATE와 DELETE가 빈번하게 발생된다면 실제 데이터는 10만건이지만, 인덱스는 100만건이 넘어가게 되어, SQL문 처리시 비대해진 인덱스에의해 오히려 성능이 떨어지게 될 것이다.
인덱스를 사용하면 좋은 경우
- 규모가 작지 않은 테이블
- INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼
- JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼 (고유한 값 위주로)
- 기타 등등
인덱스를 사용하는 것 만큼이나 생성된 인덱스를 관리해주는 것도 중요하다. 그렇기 때문에 사용하지 않는 인덱스는 바로 제거를 해주어야한다.
카디널리티
카디널리티가 높을 수록 인덱스 설정에 좋은 컬럼
= 한 컬럼이 갖고있는 값의 중복 정도가 낮을 수록 좋다.
컬럼에 사용되는 값의 다양성 정도, 즉 중복 수치를 나타내는 지표
컬럼에 인덱스를 걸 때, 내가 원하는 데이터를 선택하는 과정에서 최대한 많은 데이터가 걸러져야 성능이 좋을 것이다
(선택하는 데이터가 많아질수록 full scan에 가까워지므로)
즉, 여러 컬럼을 동시에 인덱싱할 때, 카디널리티가 높은 컬럼(중복이 적은 컬럼을) 우선순위로 두는 것이 인덱싱 전략에 유리하다.
예를 들면 users 테이블에 인덱스를 걸어보자
(테이블의 여러 컬럼이 결합해 하나의 인덱스를 이루는 경우, 이를 결합인덱스라고 한다. 결합인덱스는 컬럼의 순서에 따라 엑세스하는 범위가 달라지므로 유의해야한다.)
CREATE INDEX idx_location_first ON users(location, name, id);
CREATE INDEX idx_id_first ON users(id, name, location);전자의 경우 location (카디널리티가 낮은 컬럼 : 중복도가 높은 컬럼)을 우선적으로 인덱싱했고,
후자의 경우 id (카디널리티가 높은 컬럼 : 중복도 낮은 컬럼)을 우선적으로 인덱싱했다.
전자는 인덱스 정의한 순서대로 location -> name -> id 순으로 값을 필터링한다.
후자는 id-> name -> location 순으로 필터링한다.
앞에서 필터링할 때 먼저 많이 걸러줄수록 뒤에서 탐색해야하는 범위가 줄어드므로 카디널리티 높은 항목을 우선적으로 적용하는 것이 좋다.
출처 :
인덱스 효과적으로 설정하는 방법
카디컬리티란?
인덱스의 자료구조
인덱스를 구현하기 위한 자료구조는 여러가지가 있다.
대표적으로 해시테이블과 B+ Tree가 있다.
해시테이블
해시테이블은 key, value로 데이터를 저장하는 자료구조 중 하나로 빠른 데이터 검색이 필요할 때 유용하다. 해시 테이블은 Key값을 이용해 고유한 index를 생성하여 그 index에 저장된 값을 꺼내오는 구조이다.
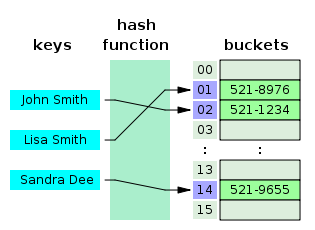
해시테이블 기반의 DB 인덱스는 (데이터 = 컬럼의 값, 데이터의 위치)를 (Key, Value)로 사용하여 컬럼의 값으로 생성된 해시를 통해 인덱스를 구현하였다.
하지만 DB 인덱스에서 해시 테이블이 사용되는 경우는 제한적인데, 그 이유는 해시가 등호(=) 연산에만 특화되어있기 때문이다. 해시 함수는 값이 1이라도 달라지면 완전히 다른 해시 값을 생성하는데, 이러한 특성에 의해 부등호 연산(>,<)이 자주 사용되는 데이터베이스 검색을 위해서는 해시테이블이 적합하지 않다.
즉, 예를들어 "나는"으로 "시작하는"(부등호연산) 모든 데이터를 검색하기 위한 쿼리문은 인덱스의 혜택을 전혀받지 못하게된다. 이러한 이유로 데이터베이스의 인덱스에서는 B+ Tree가 일반적으로 사용된다.
B Tree
이진트리를 확장해서 더 많은 수의 자식을 가질 수 있게 일반화시킨 것이 B-Tree
자식 수에 대한 일반화를 진행하면서 하나의 레벨에 더 저장되는 것 뿐만아니라 트리의 균형을 자동으로 맞춰주는 로직까지 갖춤. 단순하고 효율적이며, 레벨로만 따지면 완전히 균형을 맞춘 트리
▶ 따라서 균형잡힌 확장된 이진 탐색트리이므로 시간복잡도 O(logN)보장
대량의 데이터를 처리해야할 때 검색구조의 경우 하나의 노드에 많은 데이터를 저장할 수 있는 것은 상당히 큰 장점이다.
대량의 데이터는 메모리보다 블럭단위로 입출력하는 하드디스크 or SSD에 저장해야하기 때문이다.
ex) 한 블럭이 1024 바이트면, 2바이트를 읽으나 1024바이트를 읽으나 똑같은 입출력 비용이 발생하기 때문. 따라서 하나의 노드를 모두 1024바이트로 꽉 채워서 조절할 수 있다면 입출력에 있어서 효율적인 구성을 갖출 수 있다.
규칙
- 최대 M개의 자식을 가질 수 있는 B트리를 M차 B트리라고 한다
- 노드의 자료수가 N이면, 자식수는 N+1이어야 한다.
- 각 노드의 자료는 정렬된 상태여야한다.
- 루트노드는 적어도 2개 이상의 자식을 가져야한다.
- 루트노드를 제외한 모든 노드는 적어도 M/2개의 자료를 가지고있어야한다.
- 외부 노드로 가는 경로의 길이는 모두 같다.
- 입력 자료는 중복될 수 없다.
참고 : B Tree
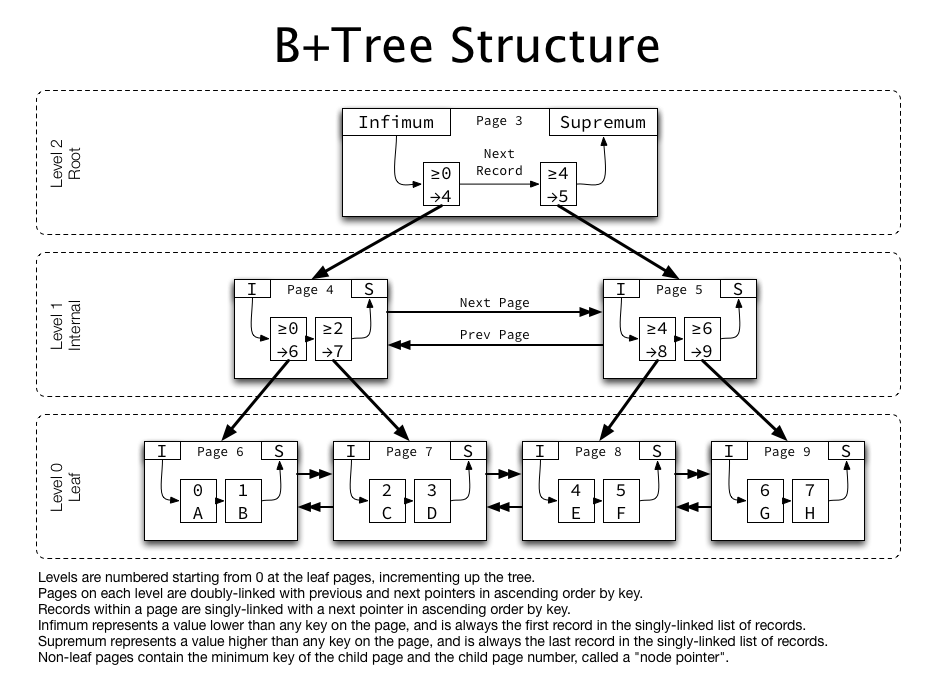
B+ Tree
B+ Tree는 DB의 인덱스를 위해 자식 노드가 2개 이상인 B-Tree를 개선시킨 자료구조이다. B+ Tree는 모든 노드에 데이터(Value)를 저장했던 B Tree와 다른 특성을 가지고 있다.
- 리프노드(데이터노드)만 인덱스와 함께 데이터(Value)를 가지고 있고, 나머지 노드(인덱스노드)들은 데이터를 위한 인덱스(Key)만을 갖는다.
- 리프노드들은 LinkedList로 연결되어있다.
- 데이터노드 크기는 인덱스 노드의 크기와 같지 않아도 된다.
데이터베이스의 인덱스 컬럼은 부등호를 이용한 순차 검색 연산이 자주 발생될 수 있다. 이러한 이유로 B Tree의 리프노드들을 LinkedList로 연결하여 순차검색을 용이하게 하는 등 B Tree를 인덱스에 맞게 최적화하였다. (물론 Best Case에 대해 리프노드까지 가지 않아도 탐색할 수 있는 B Tree에 비해 무조건 리프노드까지 가야한다는 단점도 있다.)
이러한 이유로 B+ Tree는 O(log2N)의 시간복잡도를 갖지만 해시테이블보다 인덱싱에 더욱 적합한 자료구조가 되었다.
B Tree, B+ Tree 비교
이진 트리는 하나의 부모가 두 개의 자식밖에 가지질 못하고, 균형이 맞지 않으면 검색 효율이 선형검색 급으로 떨어진다 (최악의 경우 편향된 구조로 시간복잡도 O(logN))
하지만 이진 트리 구조의 간결함과 균형만 맞다면 검색, 삽입, 삭제 모두 O(logN)의 성능을 보이는 장점이 있기 때문에 계속 개선시키기 위한 노력이 이루어지고 있다.
B+ 트리는 B 트리의 변형구조로, 데이터의 빠른 접근을 위한 인덱스 역할만 하는 비단말 노드가 추가로 있다.
기존의 B Tree와 데이터의 연결리스트로 구현된 색인구조이다.
B Tree의 변형구조로 index부분과, leaf 노드로 구성된 순차데이터 부분으로 이루어진다. 인덱스 부분의 key값은 leaf에 있는 key 값을 직접 찾아가는데 사용된다.
장점은 블럭사이즈를 더 많이 이용할 수 있다는 것 (key에 대한 값(value)에 대한 하드디스크 엑세스 주소가 없기 때문)
leaf 노드끼리 연결리스트로 연결되어있어서 범위 탐색에 매우 유리하다.
단점은 B Tree의 경우 최상 케이스에서는 루트에서 끝날 수 있지만, B+ Tree는 무조건 leaf 노드까지 내려가야한다.
B Tree는 각 노드에 데이터가 저장된다.
B+ Tree는 index노드와 leaf 노드로 분리되어서 저장된다.
또한 leaf노드는 서로 연결되어 있어서 임의접근이나 순차 접근 모두 성능이 우수하다.
B Tree는 각 노드에서 key와 data가 모두 들어갈 수 있고, data는 disk block으로 포인터가 될 수 있다.
B+ Tree는 각 노드에서 key만 들어간다. 따라서 data는 모두 leaf 노드에만 존재한다.
B+ Tree는 add와 delete가 모두 leaf노드에서만 일어난다.
정리
- 인덱스는 데이터가 저장된 물리적 구조와 밀접한 관계가 잇다.
- 인덱스는 레코드가 저장된 물리적 구조에 접근하는 방법을 제공한다.
- 레코드의 삽입과 삭제가 빈번하게 일어나는 경우, 인덱스의 개수를 최소로 하는 것이 효율적이다.
- 인덱스가 없으면 특정한 값을 찾기위해 모든 데이터 페이지를 확인하는 TABlE SCAN이 발생한다.
- 기본키를 위한 인덱스를 기본 인덱스라 하고, 기본 인덱스가 아닌 인덱스들을 보조 인덱스라고 한다. 대부분의 관계형 데이터베이스 관리 시스템에서는 모든 기본키에 대해서 자동적으로 기본 인덱스를 생성한다.
- 레코드의 물리적 순서가 인덱스의 엔트리 순서와 일치하게 유지되도록 구성하는 인덱스를 클러스터드 인덱스라고 한다.
클러스터드 인덱스
- 인덱스 키의 순서에 따라 데이터가 정렬되어 저장되는 방식
- 실제 데이터가 순서대로 저장되어 있어 인덱스를 검색하지 않아도 원하는 데이터를 빠르게 찾을 수 있다.
- 데이터 삽입, 삭제 발생 시 순서를 유지하기 위해 데이터를 재정렬해야한다.
- 한 개의 릴레이션에 하나의 인덱스만 생성 가능
넌클러스터드 인덱스
- 인덱스의 키 값만 정렬되어 있을 뿐 실제 데이터는 정렬되지 않는 방식
- 데이터를 검색하기 위해서는 먼저 인덱스를 검색하여 실제 데이터 위치를 확인해야 하므로 클러스터드 인덱스에 비해 검색 속도가 떨어진다.
- 한 개의 릴레이션에 여러 인덱스를 만들 수 있다.

미춌따미쵸쏘!!!