ML 모델 서빙이란?
훈련된 모델을 실서비스에 사용할 수 있도록, 클라이언트에게 모델 예측 결과를 효율적으로 전달하는 방식.
모델을 훈련했다고 해서 끝나는 것이 아닌, 그것을 어떻게 서비스로 제공할 것인가가 MLOps의 최종 과제. 즉, 훈련이 된 모델을 통해 새로운 Data Points에서 “추론 (Inferenece)”를 하는 것 까지가 MLOps의 최종 과제다!
모델 서빙의 매우 간단한 예시 (Seq2Seq을 사용한 간단한 대화 예측 앱)
Serving Machine Learning Model in Production — Step-by-Step Guide
모델 서빙의 방법
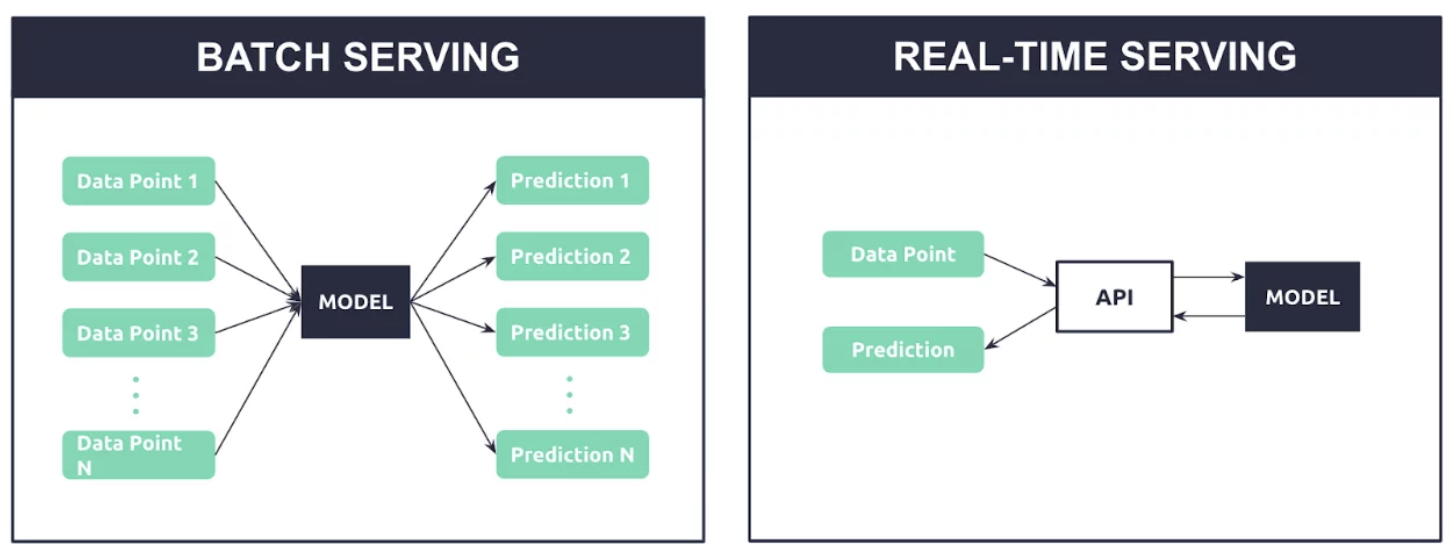
- Batch Serving
- 즉각적인 결과 도출이 필요하지 않으며, 한번에 여러 개의 예측 결과를 도출하는 방식
- Batch Inference
- Real-time Serving
- 즉각적인 예측 결과가 필요할 경우 사용
- 한번에 한 개의 예측 결과를 실시간으로 도출.
- 요청에 따른 응답이 필요하므로, API를 통해 요청과 응답이 이루어진다. (RESTful API, gRPC)
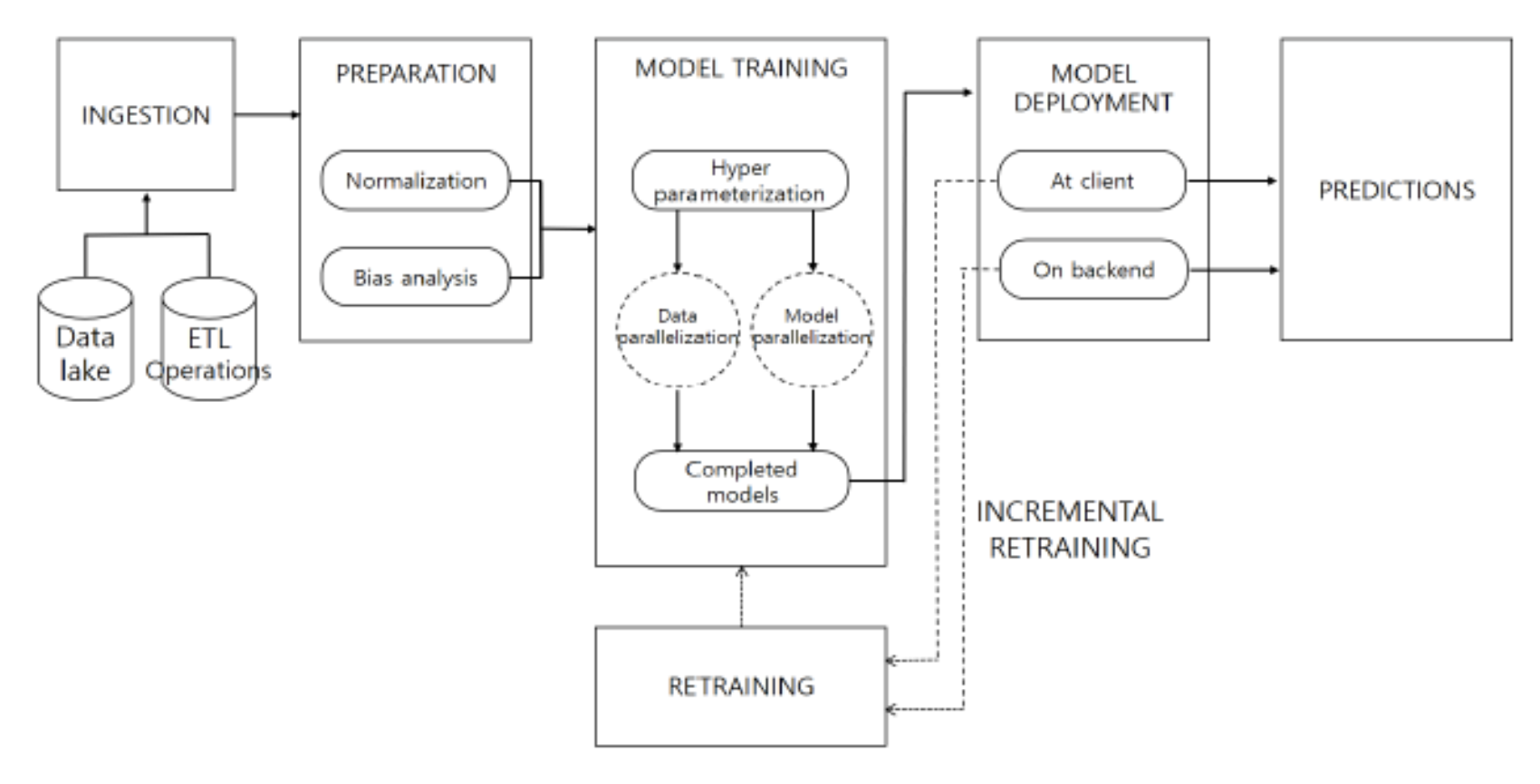
모델 서빙 Pipeline의 구조
: 크게 세 개의 파이프라인으로 이루어져 있다.
- 데이터 파이프라인: 데이터 스트림 또는 배치 처리를 통해 모델 파이프라인이나 데이터 레이크에 데이터 운반
- 모델 파이프라인: 사전 설정된 하이퍼 파라미터를 통해 하나 또는 그 이상의 모델들을 학습시킴.
- 서빙 파이프라인: 이전의 파이프라인에서 학습된 모델들을 예측 서비스 등의 서비스에 서빙.
기본적인 ML Pipeline의 구조
실서비스와의 결합을 위한 Serving Pipeline
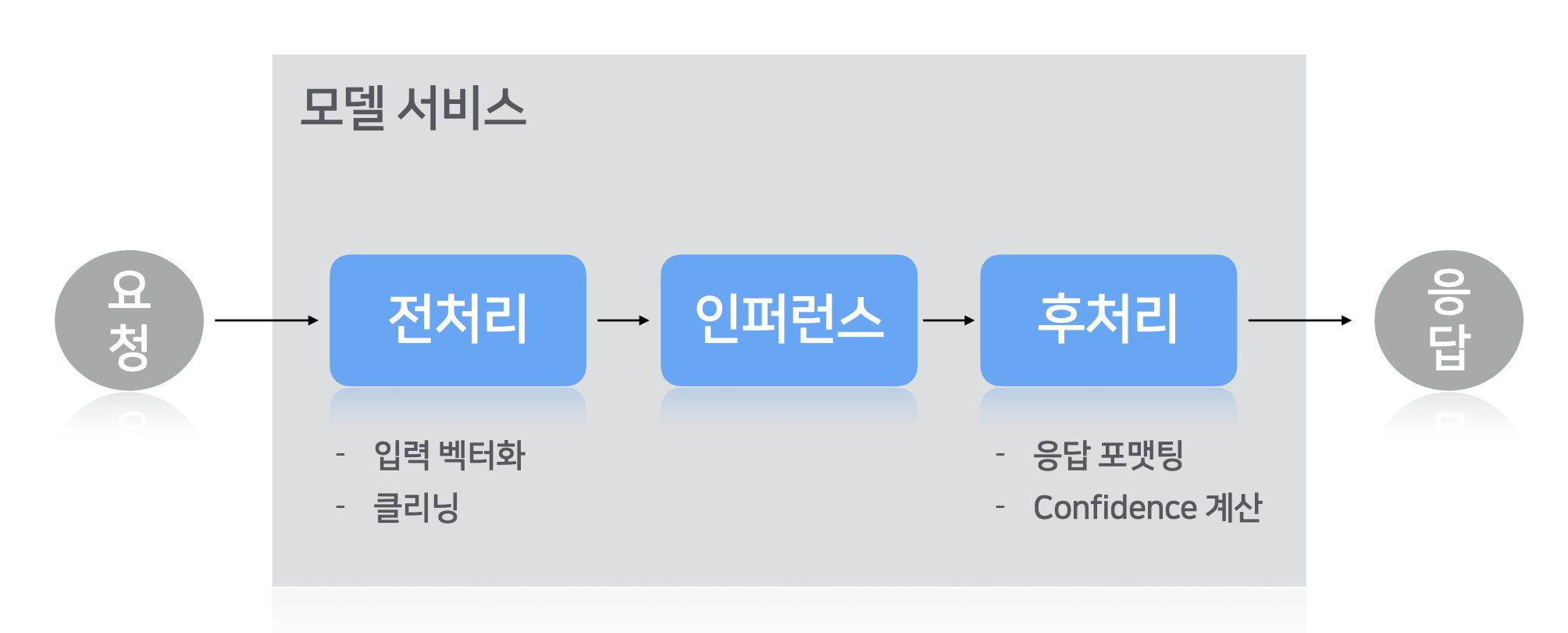
: 일반적인 모델 서빙 파이프라인의 구조
- 전처리: 모델의 추론을 위한 입력 데이터 백터화, 또는 클리닝 작업
- 인퍼런스 (추론): 훈련된 모델이 입력값에 따른 예측 결과를 도출하는 과정
- 후처리: Reponse 형식화 및 Confidence 계산
(DEVIEW 2020)

: 모델 서빙의 기본적인 구조 (초기화 → 헬스 체크 → Warm up → 전처리 → 인퍼런스 → 후처리)
(mds : 공통 모델 서빙 모듈)
- 학습된 Weight, inference 코드로 Flask를 통한 기초적인 서빙
- 모듈 공통화를 통한 효율적인 서빙 구현
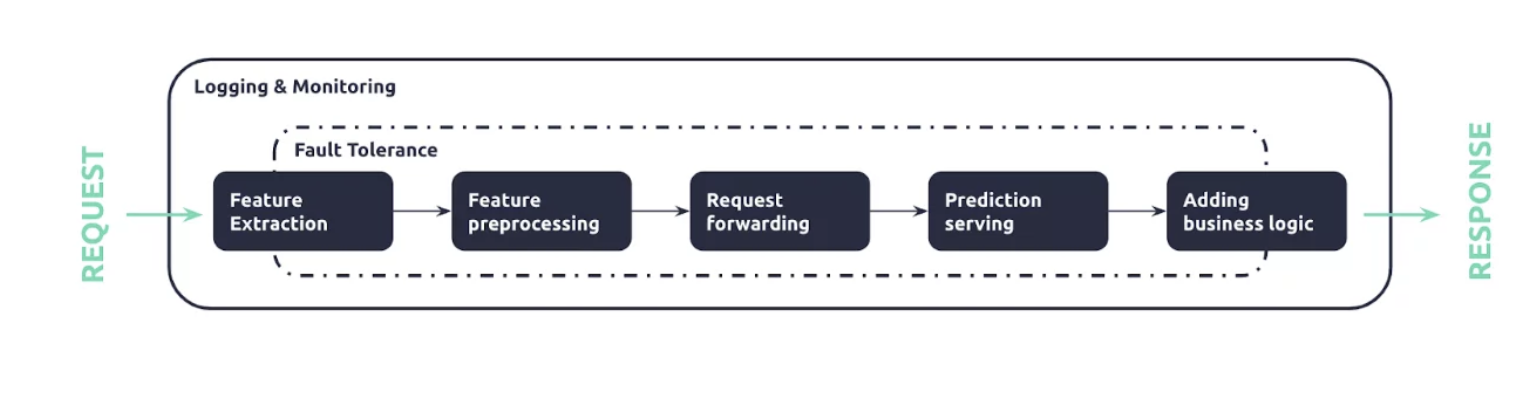
: 세분화된 모델 서빙 파이프라인 구조
- Feature Extraction: Feature Store에 아직 적재되지 않은 추가 Feature를 Request로부터 추출
- Feature Preprocessing: tabular 형식의 추출된 features 전처리 및 구조화 되지 않은 데이터에 대한 전처리
- Request Forwarding: 모델 인스턴스를 조정하기 위한 요청 라우팅
- Prediction Serving: 모델 예측 결과를 도출하기 위해 전처리된 입력값을 모델에 입력 (Inference Process)
- Adding Business Logic: 각 기업별로 의미있는 데이터 형식을 출력하기 위한 비즈니스 로직 추가
⇒ 최종적인 Response를 통한 모델 예측 결과 도출 (모델 서빙의 결과 도출)
Multimodel Pipeline

멀티 모델 파이프라인 예시:
pipeline:
name: test_pipeline
start_node_name: m1
nodes:
- name: m1
model_load_meta:
handler_module: m1.dummy_python_model
# 해당 노드 다음으로 호출할 노드. 명시하지 않으면 다음에 리스팅된 노드가 next로 설정됨.
next: m3
- name: m2
model_load_meta:
handler_module: m2.dummy_python_model
- name: m3
model_load_meta:
handler_module: m3.dummy_python_modelCI/CD/CT 및 Model Serving이 이루어지는 완전한 Pipeline
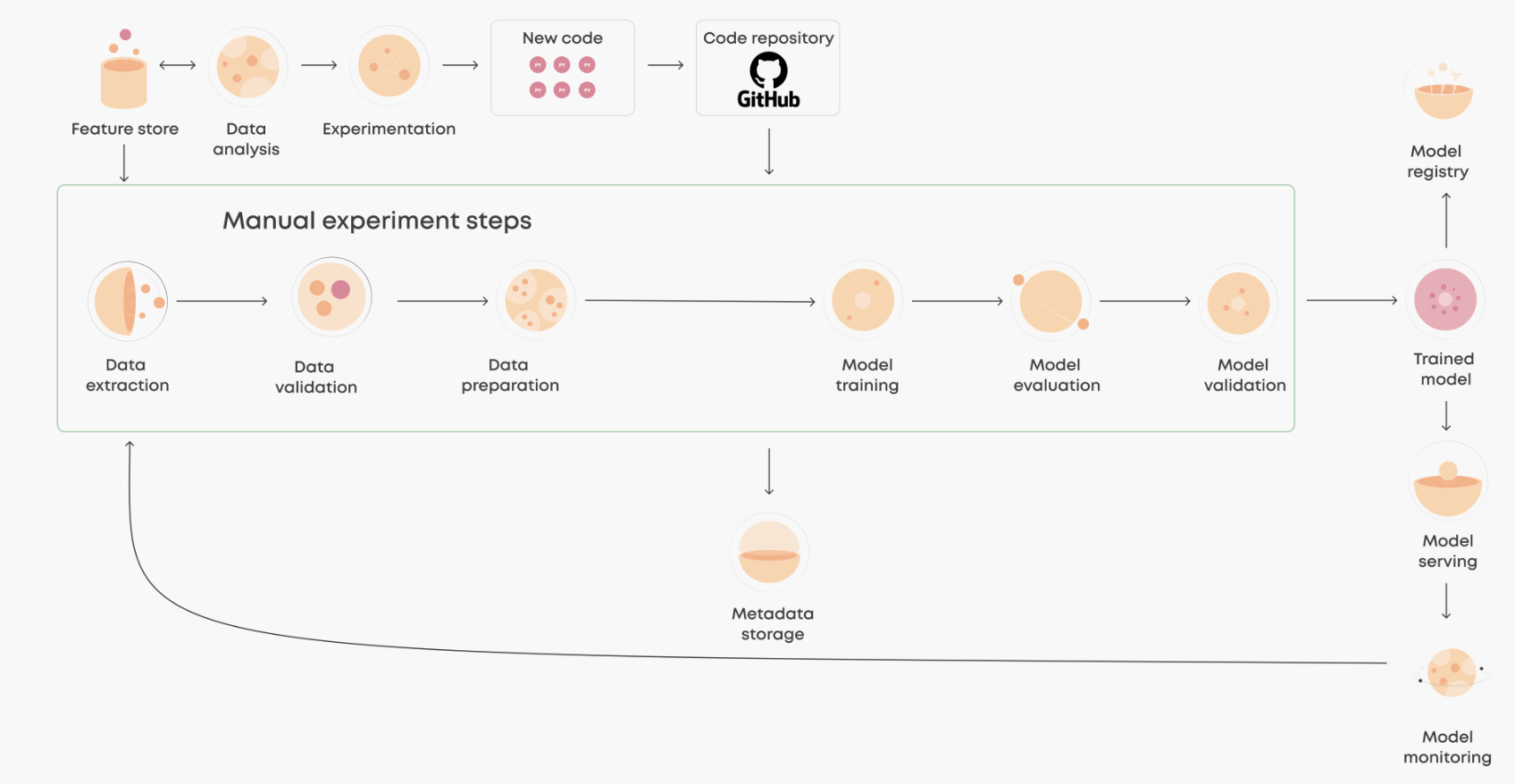
: 그러나 추론 서빙 (Inference Serving, or Model Serving)은 여러 이유로 복잡성을 띈다.
- 다중의 모델 프레임워크: TensorFlow, PyTorch, TensorRT, ONNX Runtime 등의 프레임워크 각각에는 프로덕션 환경에서 모델을 구동하게 해줄 실행용 백엔드가 필요.
- 다양한 유형의 추론 쿼리: 추론 서빙(inference serving)에서는 실시간 온라인 예측, 오프라인 배치(batch), 스트리밍 데이터, 다중 모델의 복잡한 파이프라인 등 여러 유형의 추론 쿼리를 처리하며, 이들 각각은 추론을 위한 특별한 프로세스를 요구한다.
- 진화를 거듭하는 모델: 모델들은 새로운 데이터와 알고리즘을 바탕으로 재훈련과 업데이트를 거듭하므로 이에 대한 지속적인 업데이트가 필요.
- 다양한 CPU와 GPU: 모델들은 CPU 또는 GPU를 기반으로 실행될 수 있으며, CPU와 GPU에는 다양한 종류가 있다.
⇒ 이를 해결해주는 것이 NVIDIA Triton Inference Server의 Serving Pipeline (뒤에 설명)
Serving Pipeline에서의 Framework
: 일반적인 요청/응답과 달리 모델 서빙 파이프라인 에서의 요청/응답은 상당한 오버헤드 발생
⇒ 모델 서빙 파이프라인의 Input : 이미지 Tensor, Complex tensor….
⇒ Serving Framework 효율성의 중요도 up
FastAPI
: 파이썬 웹 프레임워크를 이용한 서버 구축

- 쉽고 간단하게 API 구축 가능 + 비교적 간단한 API 구현
- 기본적으로 웹 프레임워크다 보니, 모델 서빙 프레임워크의 핵심 기능인 gRPC 지원여부, 모델 포멧, Dynamic Batch Inference (고정된 크기의 배치로 요청을 보내는 것이 아닌, 서버에서 자동으로 배치를 만들어 인퍼런스 수행) 등을 지원하지 않음 (직접 구현해야 함)
TensorFlow Serving
: TensorFlow로 구현한 모델을 그대로 서빙할 수 있는 프레임워크
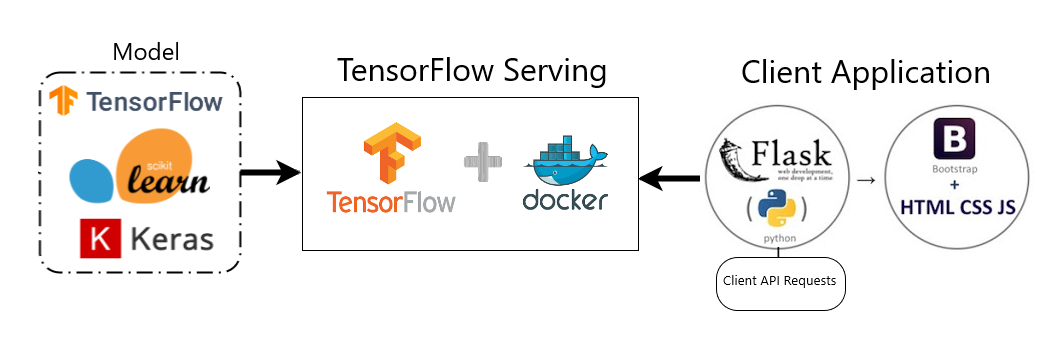
- 강력한 TensorFlow 호환성 및 TensorFlow 모델 서빙의 편리함
- 그 외의 형태의 모델은 호환 안됨
Triton
: 다양한 딥러닝 모델 포맷을 지원하는 모델 서빙 프레임 워크
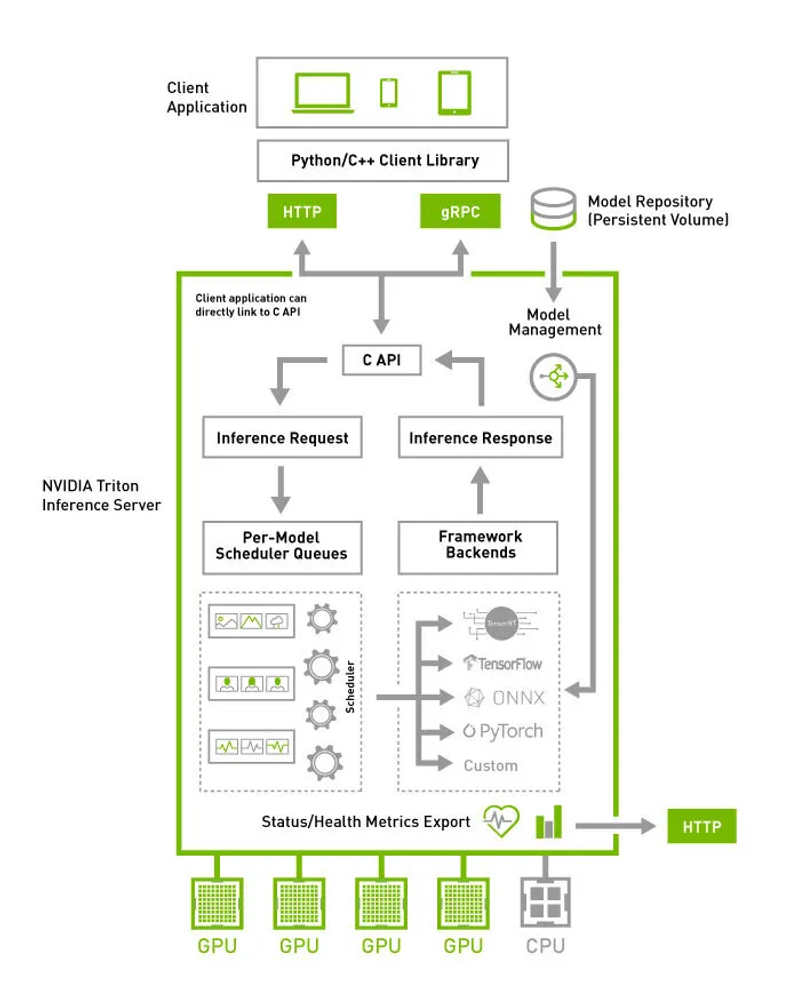
- TensorFlow Serving과 다르게 요청을 보낼 때 JSON 형태가 아닌 바이너리 데이터로 변환하고 이를 Base64로 인코딩
- TensorFlow Serving에서 요청을 바이너리 데이터로 변환하려면 Input Signature가 변경되어야 하지만 Triton에서는 별도의 변경사항 불필요
세 프레임워크의 HTTP 프로토콜 성능 비교
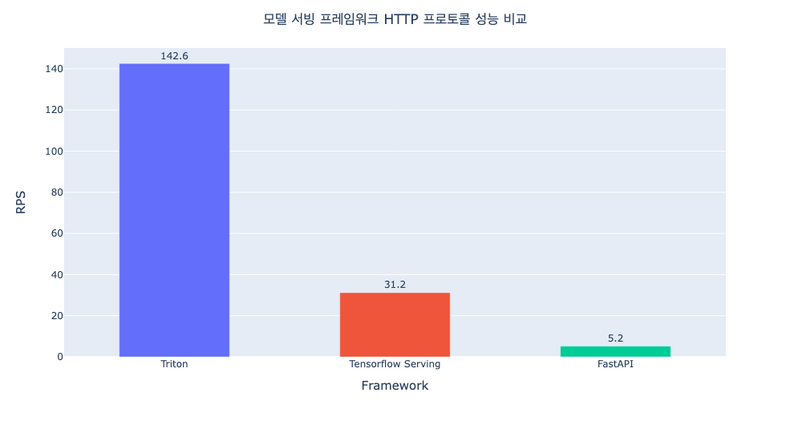
출처: https://tech.kakaopay.com/post/model-serving-framework/
ML Model Pipeline 사례
Vertex AI Pipeline
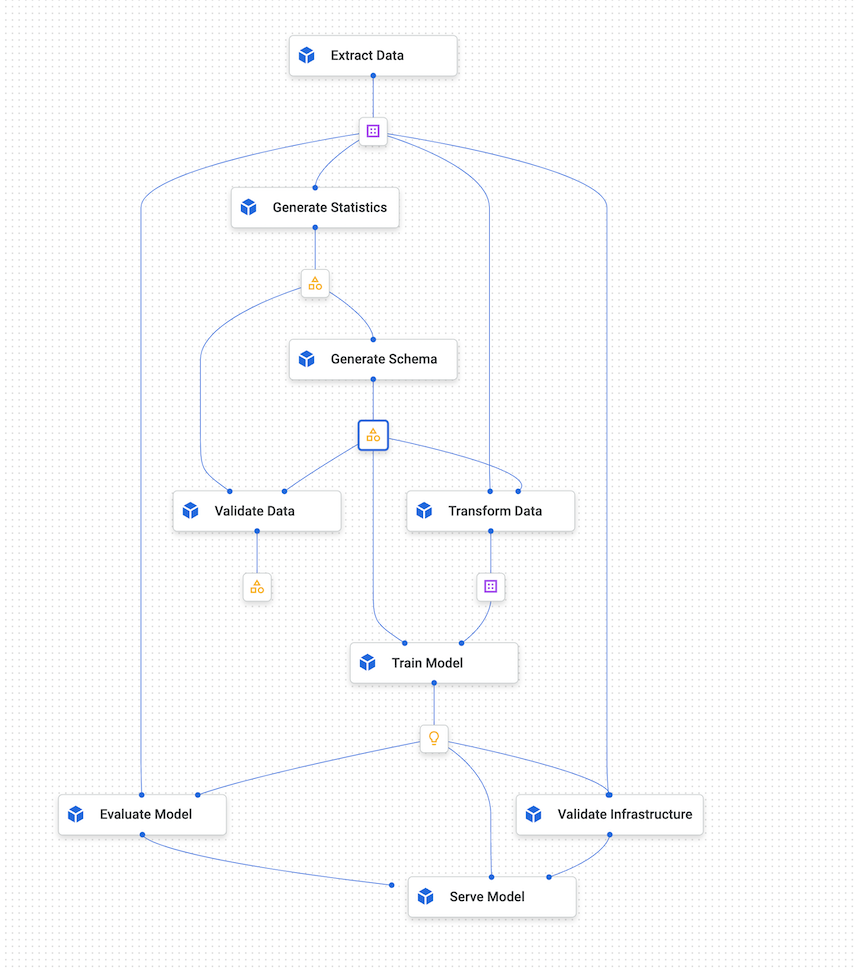
: Vertex AI Pipeline의 시각화 그래프
- Google Cloud 내에서 ML Pipeline을 구축할 수 있게 하는 워크플로우 툴
- ML Workflow를 서버리스 방식으로 조정하여 워크플로우 아키텍트를 저장
- ML 시스템을 자동화, 모니터링 및 제어
파이프라인 실행 | Vertex AI | Google Cloud
NVIDIA Triton Inference Server의 Serving Pipeline
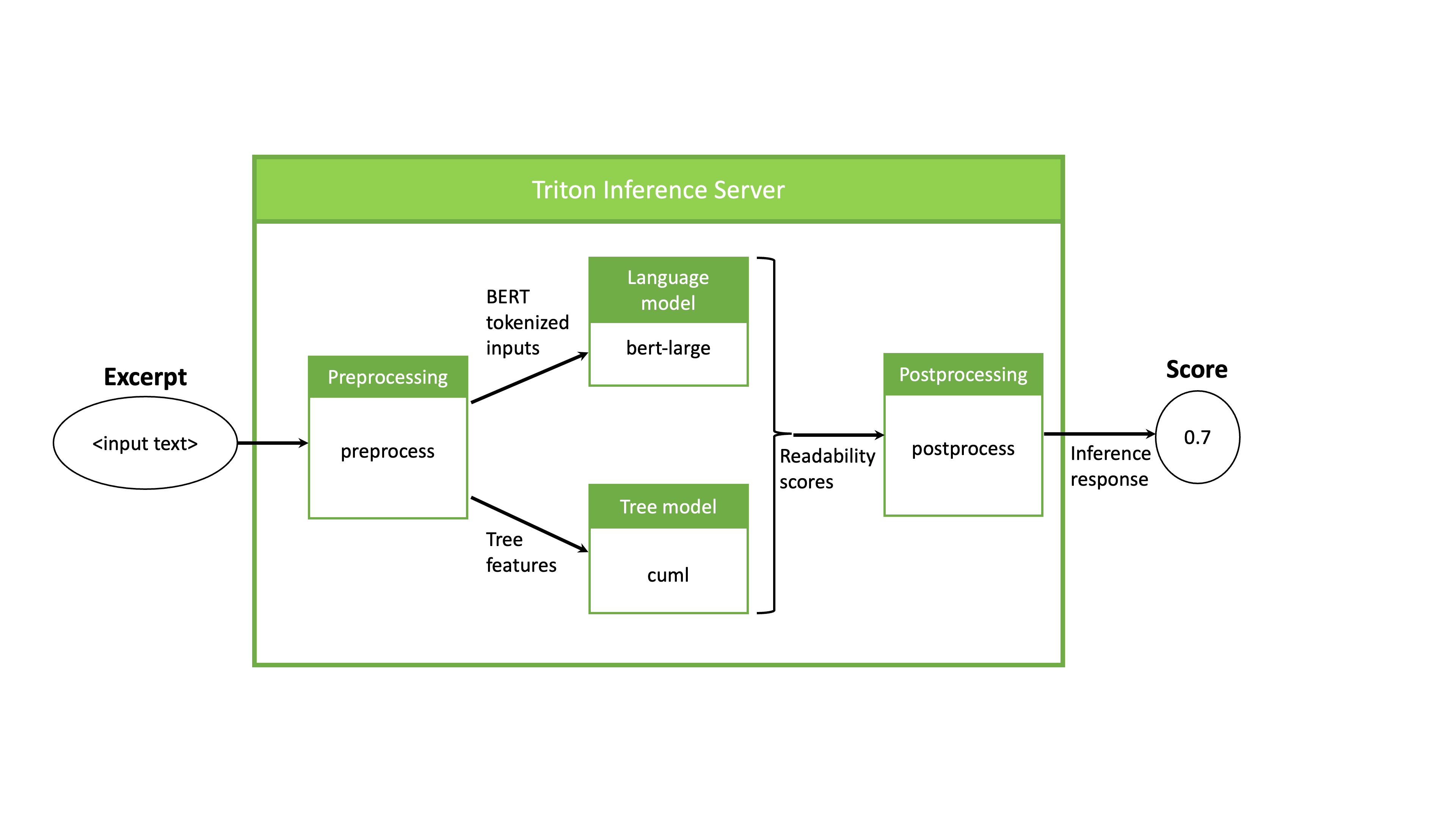
: NVIDIA Triton Inference Server는 Preprocessing, Postprocessing 과정을 포함한 Inference Pipeline (Serve Pipeline) 을 GPU 내에서 실행할 수 있도록 함.
- Single Model Pipeline이 될 수도 있고, 여러 모델들이 결합한 결합한 Ensemble Model을 지원함
- Stateless Models, Stateful Models, Ensemble Models 지원
- 모델 관리 API (HTTP/REST, gRPC, C AP 등)을 통해 쿼리하고 제어할 수 있음
효율적인 모델 추론 서비스를 위한 Nvidia Triton 아키텍처 소개 및 Quick Start
SOCAR의 Model Serving System - 자체 Pipeline 구축
: 딥러닝 모델 서빙 시스템 (kubeflow, sagemaker, autoML)을 모든 조직원들이 습득하기에는 허들이 존재하여, 자체적인 클라우드 기반 모델 서빙 시스템을 구축함
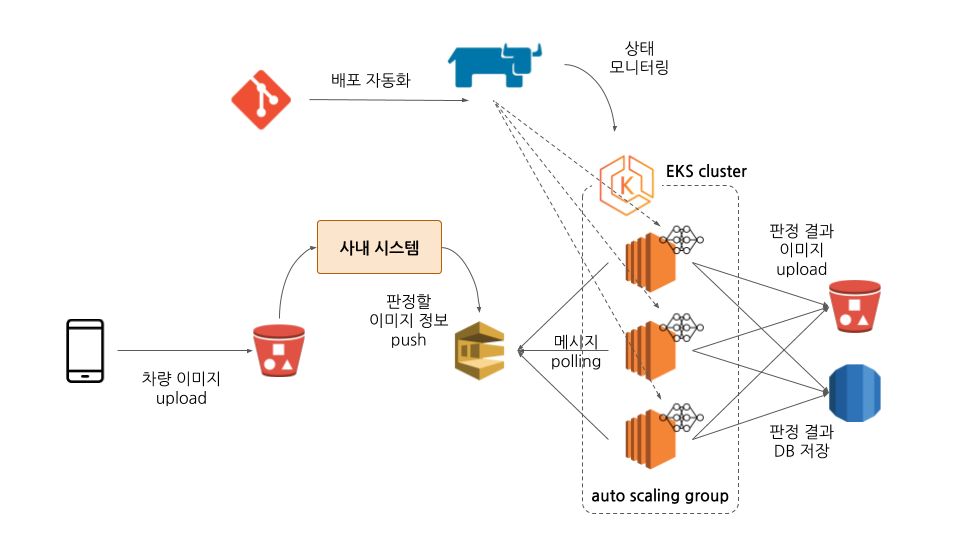
: AWS SQS + Kubernetes + Git + Rancher + S3, DB
대략적 순서도
- 클라이언트에서 이미지 Upload → S3에 저장
- AWS SQS (단순 메시징 큐)에 이미지 URL과 기타정보를 묶어 Push
- 판정 모델은 SQS를 polling하여 요청된 메시지를 받아와 판정 작업 처리
- Model Serving
- S3 + Agent (Python Application / Docker) + Kubernetes
- Agent란? : Python으로 작성되고 Docker Image로 빌드한 자체 서빙 시스템
- 손상 판정 모델 초기화
- SQS에서 메시지를 pull하고 모델에 이미지 전달
- 모델의 판정 결과를 사내 시스템에 전달
- 모델 및 Agent의 상태를 확인하고 로그 저장
- S3 + Agent (Python Application / Docker) + Kubernetes
- 서빙 관련 배포 및 모니터링 (Git + Rancher)
- Git에 소스를 Push하면 자동으로 트리거되어 도커 이미지 빌드부터 K8s 배포까지 한방에 가능
- Rancher GUI를 통해 노드 및 파드의 상태 모니터링 및 로그 확인
Reference
효율적인 모델 추론 서비스를 위한 Nvidia Triton 아키텍처 소개 및 Quick Start
[Tutorial]: Serve an ML Model in Production using FastAPI
What is a Machine Learning Pipeline?
머신러닝 파이프라인 (Machine Learning Pipeline) > 도리의 디지털라이프
파이프라인 실행 | Vertex AI | Google Cloud
