
들어가며
이번에 캡스톤 디자인을 하면서 OCR 모델을 사용해야 할 때가 왔었다. 당시 사용한 OCR 모델은 파이썬 기반 Pororo OCR 로, 여러 pip 라이브러리를 필요로 했는데, 로컬에서는 잘만 돌아가는 게, EC2에서는 유독 의존성 충돌이 일어나서 아예 모델 자체를 컨테이너화 시켰다.
다만, 아무래도 OCR 모델이 pipenv 라는 파이썬 가상머신에서 돌아가는 형태다 보니, Docker build 과정에서 무수한 오류가 일어났었다. Base Image를 파이썬이 아닌 Ubuntu로 아래처럼 일일이 파이썬을 설치하고 관련 라이브러리들을 추가하는 형태로 Dockerfile을 작성했다.
FROM amd64/ubuntu:22.04
WORKDIR /app
ENV PYTHONUNBUFFERED=1
ENV DEBIAN_FRONTEND=noninteractive
COPY Pipfile Pipfile.lock /app/
RUN apt -y update && apt -y upgrade
RUN apt install -y pip && pip install pipenv
RUN apt install software-properties-common -y
RUN add-apt-repository ppa:deadsnakes/ppa && apt -y update
RUN apt-get install -y fonts-noto-cjk
RUN apt install -y python3.11
RUN pipenv --python /usr/bin/python3
RUN pipenv install
COPY . /app/
RUN pipenv run pip install cmake
RUN pipenv run pip install easyocr
RUN pipenv run pip install fuzzywuzzy
EXPOSE 8000
CMD ["pipenv", "run","uvicorn", "main:app", "--host","0.0.0.0","--port","8000"]마침내 잘 돌아가는 모습을 보고 OCR 모델을 돌려봤는데, 로컬에서는 6~7초가 걸린 것이, 컨테이너 안에서는 35초가 걸렸었다. 당시 GPU가 활성화된 AWS EC2의 G 인스턴스를 사용하고 있었는데, NVIDIA Tesla GPU를 사용해도 이렇게 느리니, "GPU 칩이 안 좋은건가...?" 라고 생각했다.
그러나, 결론은 컨테이너는 기본적으로 GPU를 사용할 수 없었기 때문에 일어난 일이었다. 즉, GPU가 아닌 CPU로 이미지를 처리해야 했기 때문에 실행속도가 느린 것이었다.
왜 컨테이너에서는 기본적으로 GPU에 접근이 불가능한 것일까?
이번 글에서는 위의 질문에 대한 답을 하기 위해 필요한 가상화 기술에 대한 원리, 그리고 컨테이너에서 GPU를 사용하기 위한 과정에 대해 다룰 것이다.
가상화 기술의 원리
맨 처음 던졌던 질문에 대한 이유를 알려면 컨테이너 격리 기술이 어떻게 이루어져야 하는지부터 이해해야 한다.
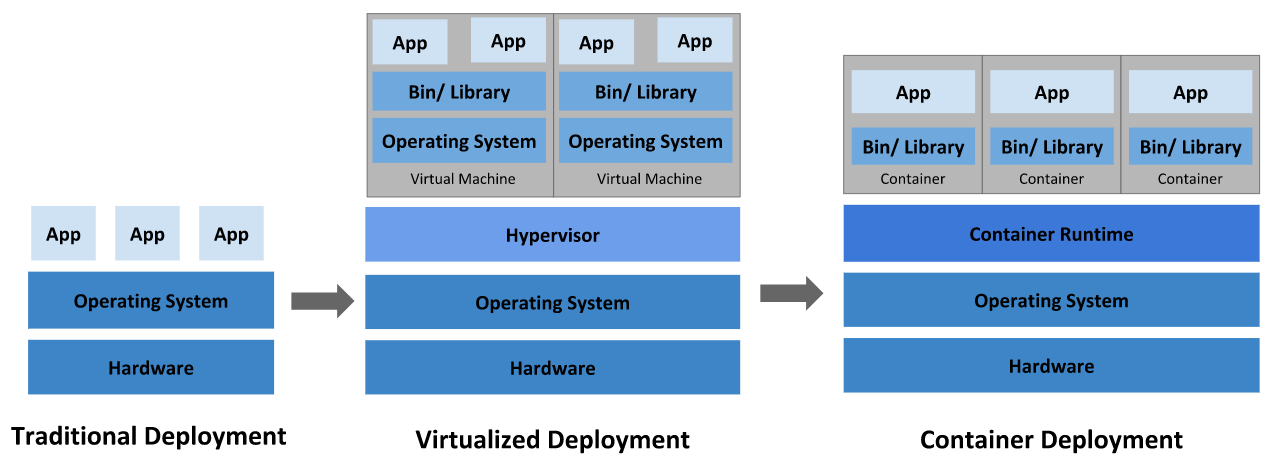
컨테이너는 일종의 "가상화" 기술이다. 다만, VMWare 같이 가상 머신을 통해 가상화하는 기술은 운영체제와 커널을 통째로 가상화하는 반면, 컨테이너는 단순히 말하면 파일 시스템 만을 가상화하는 기술이다.
컨테이너에 대한 용어를 한번이라도 들었던 경험이 있다면, 정말 귀에 피가 날 정도로 "Virtual Machine VS Containter" 이런 식의 글을 많이도 들었을 것이다. 컨테이너와 가장 비교를 하는 가상화 기술이 "가상 머신을 통한 전가상화 기술"이기 때문이다. 그렇다면 컨테이너가 등장하기 전 많이 사용했던 가상 머신 기술은 어떻게 가상화를 했을까?
Hypervisor (제 1형, 제 2형)
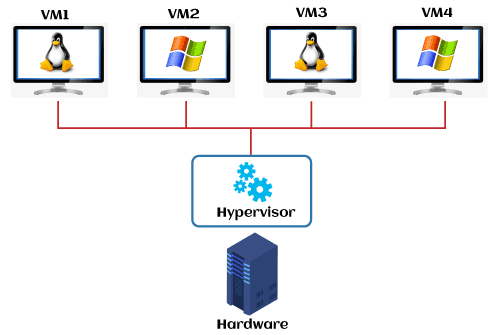
우리가 Windows를 사용한다고 가정할 때, Ubuntu와 같은 새로운 운영체제를 또 하나 띄우려 한다면, 원래 사용하던 Windows와는 완전히 격리된 환경에서 Ubuntu를 사용할 것이다. 가상 머신은 커널 뿐만 아니라 하드웨어까지 통째로 가상화하기 때문에, 얼마나 가상화를 해서 그 운영체제에게 나누어 줄 것인지를 결정해야 한다. 그 결정을 하기 위해 사용하는 것이 하이퍼바이저 (Hypervisor)이다.
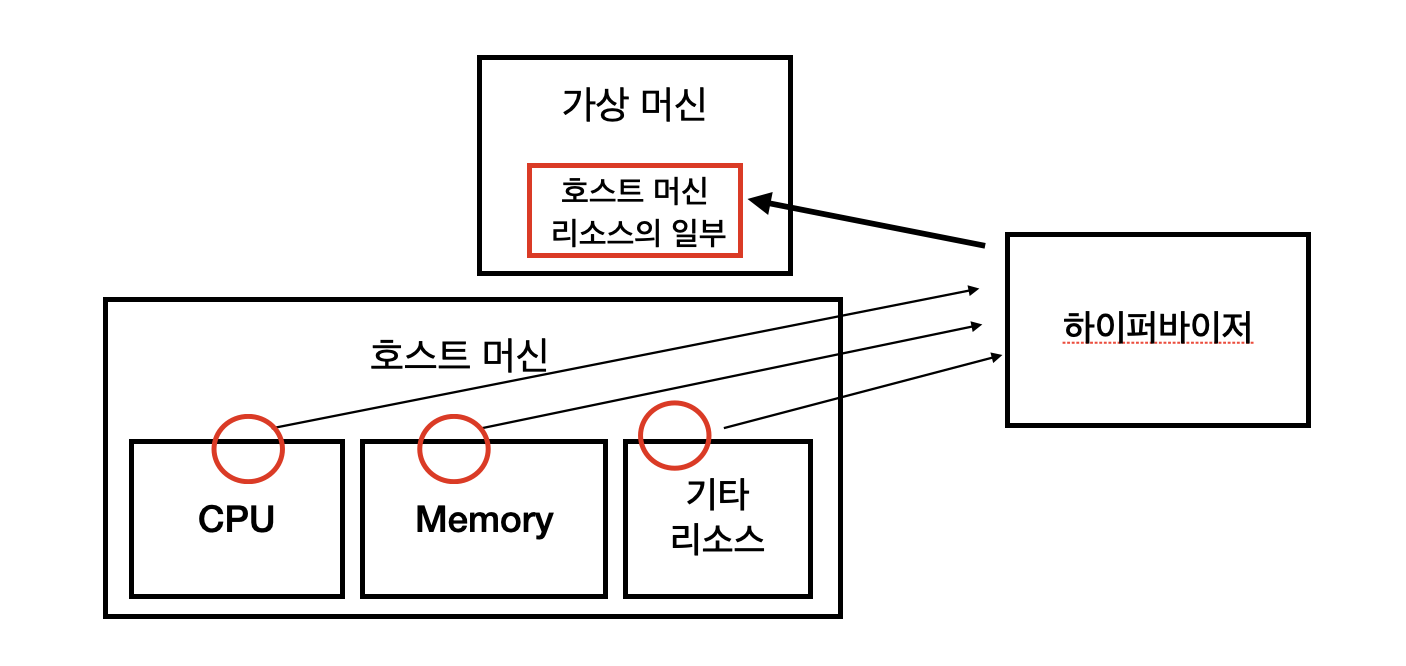
조금 더 사전적인 의미로 넘어가보자. 정확히 말하면, 하이퍼바이저 (Hypervisor)란, 가상 머신을 생성할 때 사용되는 일종의 소프트웨어다. 보통 가상머신을 만들 때는 주인이 되는 호스트 머신 (Host Machine)의 하드웨어 리소스 (CPU, Memory 등) 을 분할하여 할당한다. 이러한 역할을 하는 것이 바로 하이퍼바이저다.
놀랍게도 하이퍼바이저에도 그 종류가 있는데, 제 1형 (Native), 그리고 제 2형 (Host Hypervisor)로 나뉘어져 있다.
Native Hypervisor (제 1형)
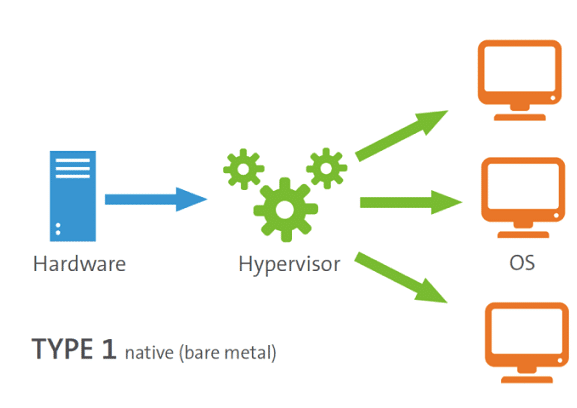
제 1형 Hypervisor는 "하드웨어" 에 직접 설치되어있는 하이퍼바이저다. 즉, 별도의 소프트웨어 (VMWare, Virtual Box)를 설치할 필요없이, 아예 호스트 머신의 하드웨어에 기본적으로 설치되어 있는 Hypervisor를 의미한다.
이전 글에서 잠깐 언급했던 내 홈서버 (a.k.a 완돌이) 가 바로 이 제1형 하이퍼바이저를 사용한다.
 위 사진은 완돌이에 설치된 VMWare의 esxi로, 제1형의 하이퍼바이저의 예시 중 하나다.
위 사진은 완돌이에 설치된 VMWare의 esxi로, 제1형의 하이퍼바이저의 예시 중 하나다.
제 1형 하이퍼바이저의 장점은 다음과 같다:
-
내결함성: 만일 하이퍼바이저가 설치된 물리 서버에 어떤 문제가 발생했다면, 인스턴스들을 신속하게 다른 물리 서버로 이전할 수 있다. 하드웨어에 직접 설치가 된 하이퍼바이저이므로 가능한 특징이기도 하다.
-
RAM 동적할당: 만일 물리적 서버의 총 RAM이 8GB이면, A 가상머신에 6GB, B 가상머신에 5GB를 할당할 수 있다. RAM을 정적으로 분할해서 할당하는 것이 아닌, 동적으로 할당을 하기 때문에 가상머신들이 사용하는 RAM의 총량이 실제 물리서버의 RAM 총량을 넘을 수 있다.
Host Hypervisor (제 2형)
보통 가상 머신이라고 할 때 가장 먼저 머릿속으로 떠오르는 것이 VMware이나 Virual Box이다. 이것들이 바로 제 2형 하이퍼바이저다.
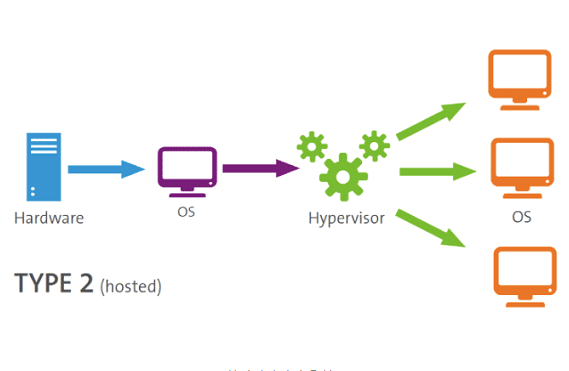
우리가 Virtual Box나 VMWare을 설치할 때는 보통 운영체제 (Windows, Mac OS 등...) 차원에서 설치할 것이다. 이때 딸려오는 하이퍼바이저 역시 운영체제에 설치된다.
제 1형 하이퍼바이저와 가장 큰 차이를 보이는 것이 바로 이처럼 "하드웨어"에 설치되느냐, "소프트웨어에 설치되느냐" 이 차이다. 운영체제 또한 시스템 자원을 관리하는 일종의 "소프트웨어"이기 때문에, 하이퍼바이저가 설치되는 차원이 다르다.
그럼 소프트웨어에 설치된 하이퍼바이저는 어떤 장점을 보일까?
- 콘솔의 불필요: 하드웨어에 설치되어 있어서 별도의 관리 콘솔이 필요한 제 1형 하이퍼바이저와는 다르게, 운영체제에 직접 설치되어 있기 때문에 관리 콘솔이 불필요 하다.
그러나 단점은 매우 명확하다.
- 동적 할당의 불가능: 하드웨어 차원에서 직접 리소스를 할당하는 것이 아닌, 운영체제 차원에서 리소스를 할당하기 때문에 RAM의 동적 할당이 불가능하다. 즉, 호스트 머신의 RAM이 8GB라면, 가상머신들의 RAM 할당량의 총량은 8GB를 넘어설 수 없다.
컨테이너의 등장
제 1형 하이퍼바이저든, 제 2형 하이퍼바이저든 모두 호스트 머신의 하드웨어 리소를 가상화하여 분할한다는 점은 모두 동일하다. 즉, 가상 머신에서는 실제 하드웨어를 쓰는 것 마냥 전체 리소스를 가상화한다.
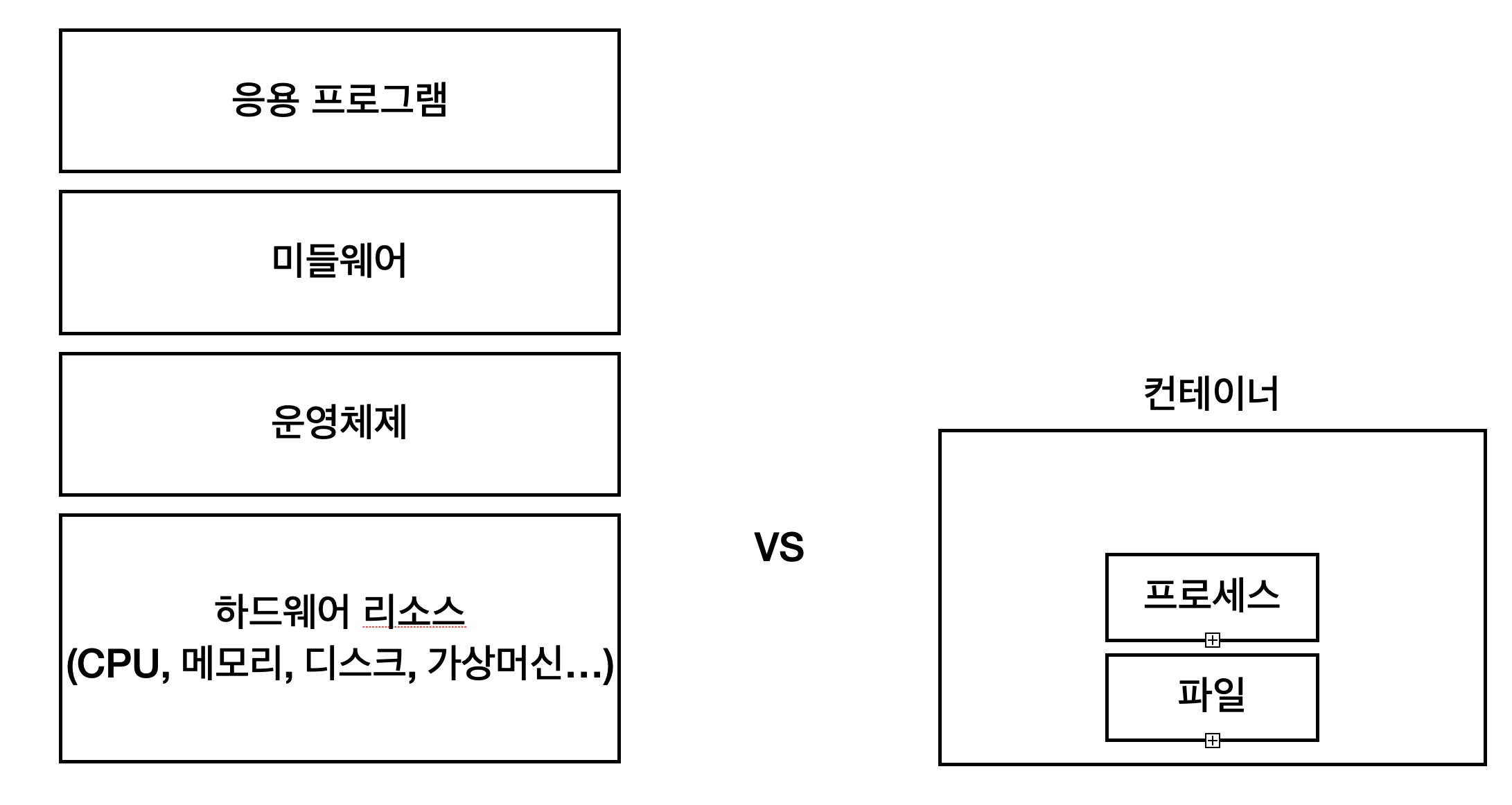 그러나 하이퍼바이저를 통한 가상화 방법은 위 처럼 하드웨어 리소스 뿐만 아니라, Guest OS, 미들웨어와 응용 프로그램까지 모조리 다 가상화를 해야 하므로 오버헤드가 굉장히 심각하다.
그러나 하이퍼바이저를 통한 가상화 방법은 위 처럼 하드웨어 리소스 뿐만 아니라, Guest OS, 미들웨어와 응용 프로그램까지 모조리 다 가상화를 해야 하므로 오버헤드가 굉장히 심각하다.
애초에 가상화된 운영체제는 자신이 사용하고 있는 리소스들을, 별도의 하드웨어로 인식하기 때문에 쌩판 다른 머신이라고 생각하면 된다. 즉, 머신 안에 새로운 머신을 새로 생성한 수준이라고 생각하면 된다.
반면, 컨테이너는 어떨까?
컨테이너는 조금 다르다. 가장 큰 차이점은 하이퍼바이저가 없다는 것에서 시작된다. 즉, 호스트 머신의 리소스를 가상 머신에 대신 할당하는 중계자가 없다는 의미다.
그렇다면 하드웨어 리소스까지 가상화를 하지 않는다는 것이면, 어디까지 가상화를 한다는 것일까? 위 사진처럼, 컨테이너는 프로세스 수준까지만 격리를 한다. 즉, 격리된 공간에는 호스트 머신의 하드웨어 리소스가 포함이 되지 않는다. 따라서 컨테이너는 가상 머신을 통한 가상화보다 훨씬 적은 오버헤드를 유발한다.
그런데, 솔직히 이정도는 컨테이너라는 용어를 한번이라도 들었으면 모두 다 알 법한 내용이다. 어떤 식으로 격리를 하는지 알아야, 왜 오버헤드가 적게 발생하면서도 가상머신과 거의 비슷한 수준으로 격리된 환경을 제공할 수 있는지 알 수 있다.
컨테이너는 어떻게 격리를 할까?
격리 기술: Namespace
첫번째 컨테이너 격리 기술은 Namespace를 활용한 격리다. 앞에서 말한 가상 머신 방법은 호스트 머신 위에, 새로운 가상 머신을 만들고 하드웨어 리소스나 파일 시스템 등, 구동에 필요한 모든 리소스를 할당했다. 즉, 운영체제 자체를 통째로 위에 올려 그 안에서 독립된 환경을 제공한다.
반면, 컨테이너는 가상 머신을 새로 만드는 대신, Namespace를 통해 리소스들을 분리한다.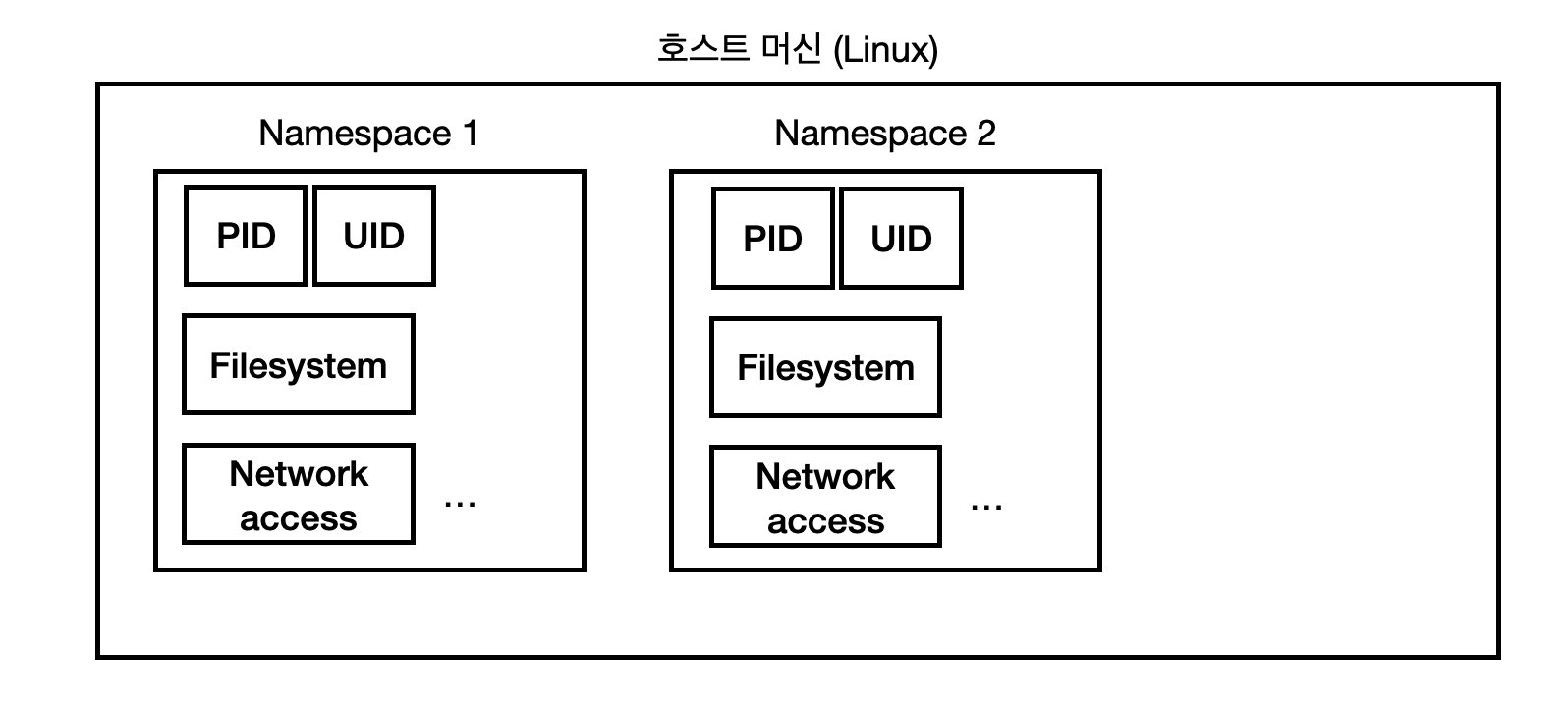 쉽게 말하면, 새로운 공간을 그 위에 얹는 것이 아닌, 이미 있는 호스트 머신 내에서 PID 나 네트워크 액세스 등의 리소스의 권한을 분리시킴으로써 외부의 접근을 제한한다고 생각하면 된다.
쉽게 말하면, 새로운 공간을 그 위에 얹는 것이 아닌, 이미 있는 호스트 머신 내에서 PID 나 네트워크 액세스 등의 리소스의 권한을 분리시킴으로써 외부의 접근을 제한한다고 생각하면 된다.
즉, 가상 머신의 격리 기술은 "하드웨어 차원"에서 격리시킨다면, 컨테이너는 "소프트웨어 차원(운영체제)"에서 격리하는 것이다.
Namespace Isolation
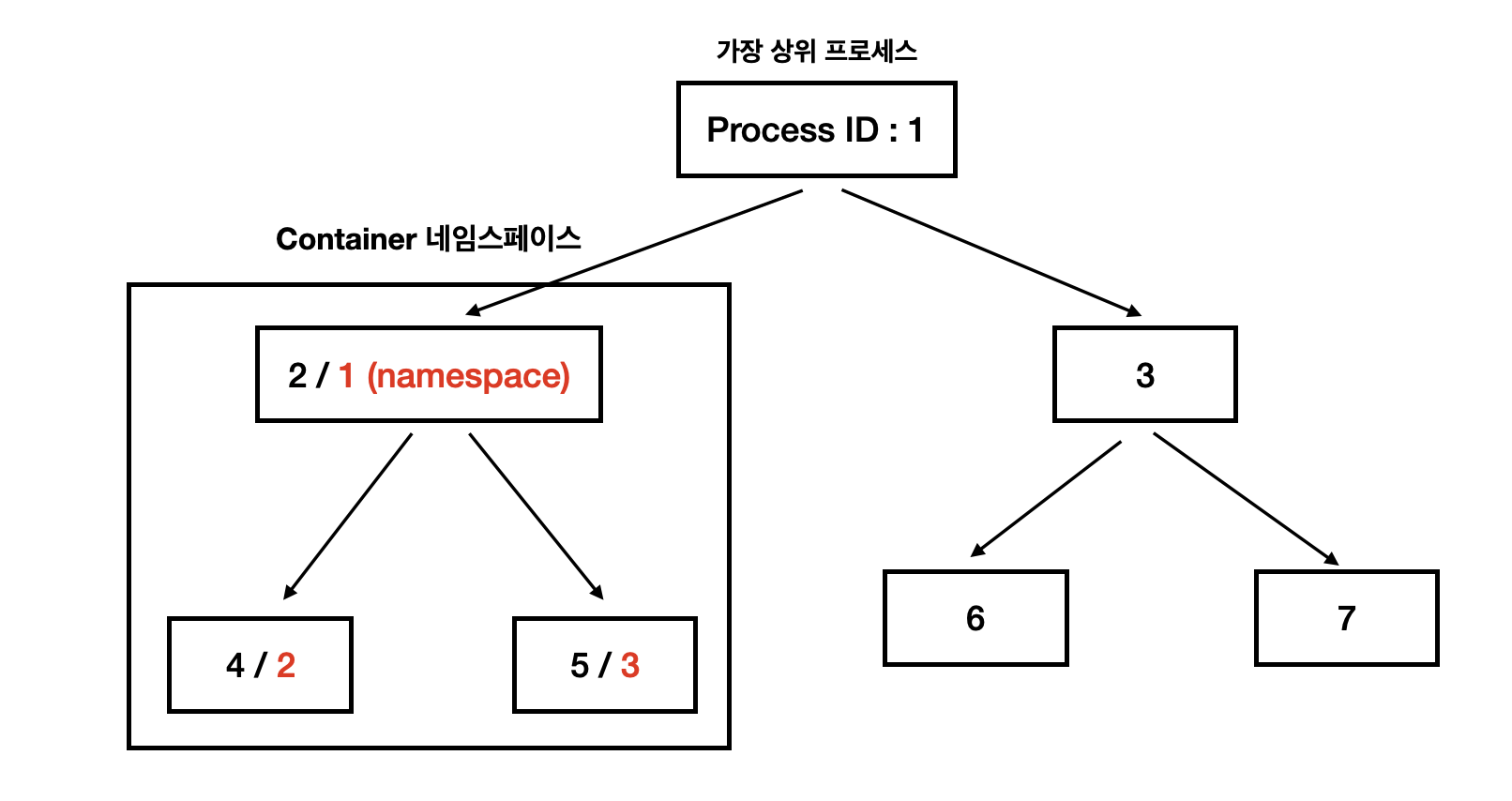 리눅스의 프로세스들은 기본적으로 Process Tree의 원리대로 실행된다.
리눅스의 프로세스들은 기본적으로 Process Tree의 원리대로 실행된다.
모든 리눅스 시스템은 부팅 시, PID가 1인 가장 상위 프로세스가 실행되며, 이 프로세스로부터 하위 프로세스들이 실행된다. 상위 프로세스는 하위 프로세스에 접근할 수 있지만, 하위 프로세스는 상위 프로세스에 접근을 할 수 없다.
즉, 우리가 Linux CLI 를 통해 Docker 명령어를 입력하면 컨테이너에 접근할 수 있지만, 다른 프로그램은 하위 프로세스이므로 컨테이너에 접근을 할 수 없다는 의미다.
컨테이너 네임스페이스로 격리된다면, 리눅스 부팅시 PID=1인 프로세스가 실행되는 것과 같이 컨테이너 실행 시 PID=1인 최상위 프로세스가 실행되고, 이 프로세스로부터 하위 프로세스들이 생성되지만, 사실 실제로는 PID=1이 아닌 그저 리눅스 최상위 프로세스의 하위 프로세스인 셈이다.
완돌이를 통해 확인해보자.
현재 완돌이에는 Kubernetes 클러스터 안에 Redis 파드가 있다. ps -ef으로 프로세스(PID)와 부모 프로세스(PPID) 로그를 확인해보자.

UID PID PPID C STIME TTY TIME CMD
root 42276 1 0 Dec05 ? 00:00:23 /usr/bin/containerd-shim-runc-v2 -namespace moby -id 0561d0fb3cad5bf672d14b4363c8ec53018a0
root 42375 1 0 Dec05 ? 00:00:23 /usr/bin/containerd-shim-runc-v2 -namespace moby -id 966c35bdfddf24fc1a37c7558c704125672cb
lxd 42419 42276 0 Dec05 ? 00:09:20 redis-server *:6379다음과 같이 최상위 프로세스 (PID = 1) 에서 moby 라는 이름의 Namespace를 생성하는 프로세스 (PID = 42276)이 생성되고, 그 프로세스에서 하위 프로세스 (PID = 42419)가 생성되어 redis-server를 생성하는 것을 확인할 수 있다.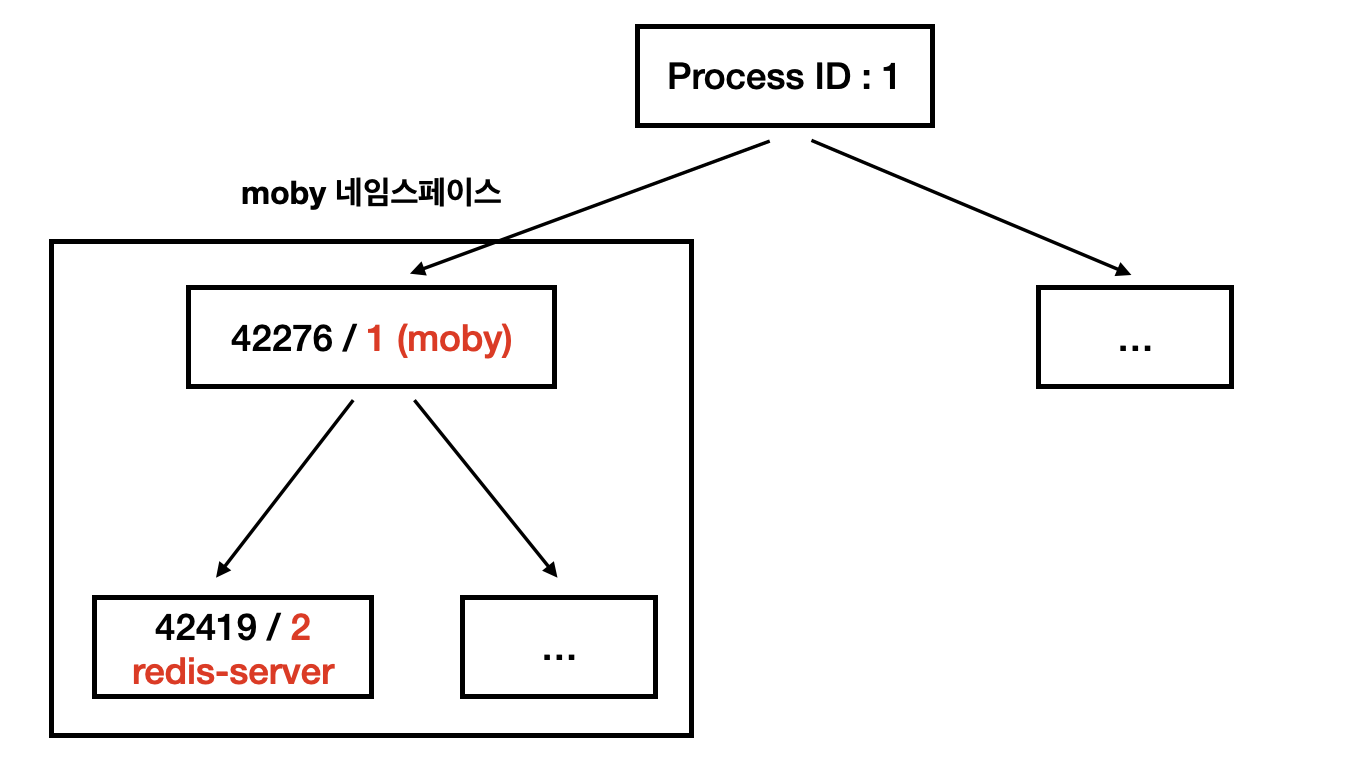
그럼 격리가 되어있는지 확인해보자.
sudo nsenter --target 42419 --mount --uts --ipc --net --pid다음과 같이 redis-server의 PID를 입력하고, 이 프로세스의 다양한 네임스페이스에 들어가보자

sudo nsenter --target 42419 --mount --uts --ipc --net --pid
root@reddis-db-54f4b586bb-c59k7:/# ls
bin boot data dev etc home lib lib32 lib64 libx32 media mnt opt proc root run sbin srv sys tmp usr var놀랍게도, docker exec -it ~~~를 했을 때랑 동일한 결과가 나온다. 즉, 네임스페이스를 통해 격리된 환경에 접속했다는 뜻이다!
리눅스에는 다음과 같이 6가지의 Namespace를 지원한다.
| 네임스페이스 | 설명 |
|---|---|
| Mnt (파일시스템 마운트) | 각 네임스페이스별로 독립적인 읽기, 쓰기 등의 파일시스템을 마운트하고 해제할 수 있다. |
| Pid (프로세스) | 독립적으로 프로세스들을 할당할 수 있다. |
| Net (네트워크) | 각 네임스페이스 별 고유의 네트워크 리소스, 이를 테면 라우팅 테이블, 포트 번호, IP 주소 등을 독립적으로 관리한다. |
| Ipc (SystemV IPC) | Inter process communication의 줄임말로, 프로세스 간 통신에 필요한 공유 메모리, 세마포어, 메시지 큐등을 독립적으로 관리한다. |
| Uts (hostname) | 독립적으로 호스트 네임을 관리한다. |
| user (UID) | 독립적인 사용자를 할당한다. |
딱 보면 이 6가지를 통해서 가상 머신과 비슷한 수준의 환경을 조성할 것처럼 보이지 않는가? 파일시스템과, 네트워크, 프로세스 간 통신, 사용자 등, 가상 환경을 실행할 수 있는 조건들을 갖췄다. 그럼 이 중, 파일시스템 마운트를 우리 완돌이에게 한번 확인해보겠다.
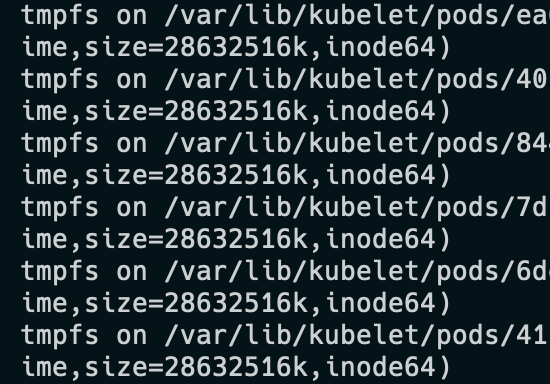
사진을 보면 무수히 많은 tmpfs, 즉 Temp File System 이 Mount 되어있는 것을 볼 수 있고, 경로를 보면 Kubernetes의 Pod 쪽에 Mount가 된 것을 볼 수 있다. 기본적으로 pod가 생성될 때, 컨테이너의 임시 volume 인 emptyDir 볼륨을 생성하는데, 격리된 환경의 볼륨을 생성하기 위해 저렇게 Temp File System을 마운트하는 것을 볼 수 있다.
그러나 결정적으로 한 가지는 빠져있는데, 바로 커널이다. '운영체제 = 커널' 이라고 부를 정도로, 커널은 I/O와 메모리 관리, Interrupt 등 핵심 기능들을 담당한다. 가상 머신은 운영체제도 가상화 하므로, 커널 또한 가상화를 한다. 그러나 컨테이너는 커널을 가상화하지 않는다. 그럼, 어떻게 커널의 기능을 사용할까?
격리 기술: Cgroups
컨테이너는 운영체제의 커널을 가상화 하는 대신, 호스트 OS의 커널을 이용한다. 이 때, cgroups, 곧 Control Group를 사용한다.
Cgroups는 리눅스 커널의 기능 중 일종으로, 다음과 같은 리소스를 제어하게 할 수 있다.
- 메모리
- CPU
- I/O
- 네트워크
- device 노드 (/dev/)
Docker와 같은 컨테이너 런타임은 이런 리눅스의 Cgroups를 응용해서 리소스 자원을 할당 또는 제어한다. 보통 LXC, LibContainer, runC 등의 기술을 사용하여 격리를 하는데 이는 리눅스 커널의 cgroups, namespaces를 응용한 것이다.
Kubernetes로 구축된 완돌이에서도 확인해봤는데, 조금 다르게 나왔다.

일단 추정해보면 Kubernetes에서 Best-effort 속성으로 리소스를 할당해주는 cgroup이 있는 것 같은데, 이건 나중에 한번 조사할 것이다.
그래서 GPU를 왜 못 쓰는 것인가?
자 그럼 처음으로 돌아가보자. 왜 Docker 컨테이너는 GPU를 사용하지 못하는 것일까? 이제 답을 할 수 있다.
namespace로 인한 프로세스 격리로 인해 GPU 드라이버에 접근을 하지 못하기 때문이다.
모든 컴퓨터는 GPU를 사용하기 위해서는 일명 GPU Driver를 필요로 한다. 즉, GPU 리소스에 접근하기 위한 일종의 소프트웨어인데, 이 소프트웨어는 결국 또 하나의 Process다. 결국 또 다른 방법이 필요하다.
NVIDIA CUDA
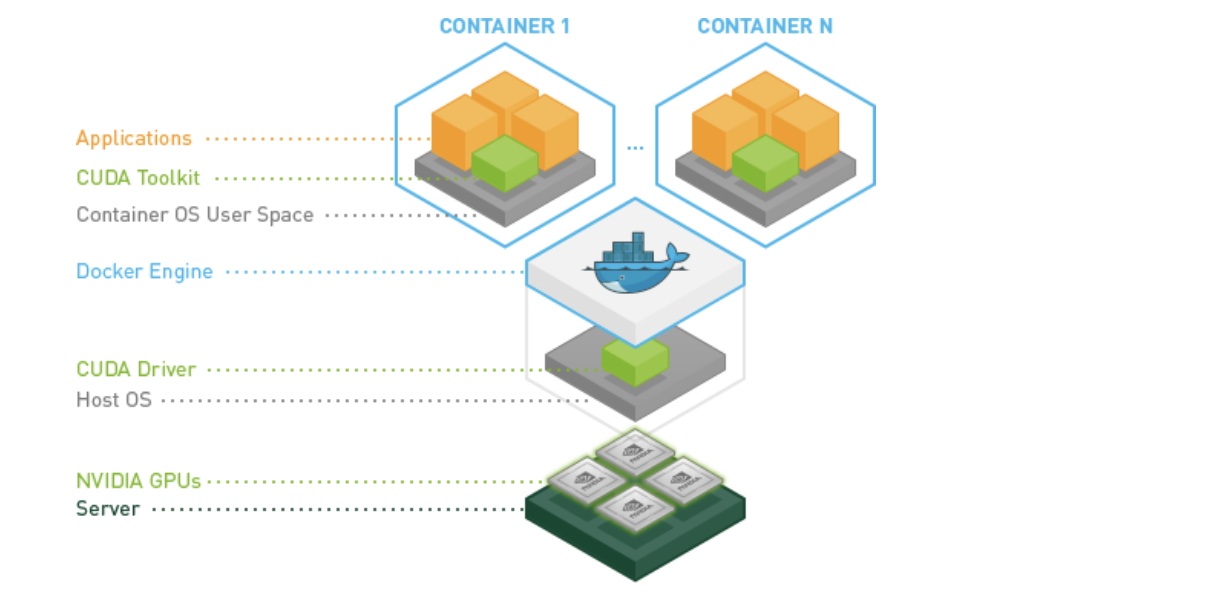 내가 사용한 방법은 Nvidia CUDA Toolkit을 사용하는 것이었다. 동작은 다음과 같다.
내가 사용한 방법은 Nvidia CUDA Toolkit을 사용하는 것이었다. 동작은 다음과 같다.
- GPU 리소스를 포함하는 서버 환경에서, CUDA Driver을 통해 GPU 리소스에 접근한다.
- Docker 런타임을 Nvidia로 사용함으로써 CUDA Driver까지 포함하여 격리를 시킨다.
- 격리된 환경에서 애플리케이션은 CUDA Toolkit을 사용해 GPU 리소스에 접근한다.
즉, 격리된 namespace에 Nvidia CUDA Driver까지 포함시켜 가상화를 하면, GPU 리소스를 사용할 수 있는 것이다!
다음과 같은 방식으로 우선 Nvidia 드라이버를 설치해보자.
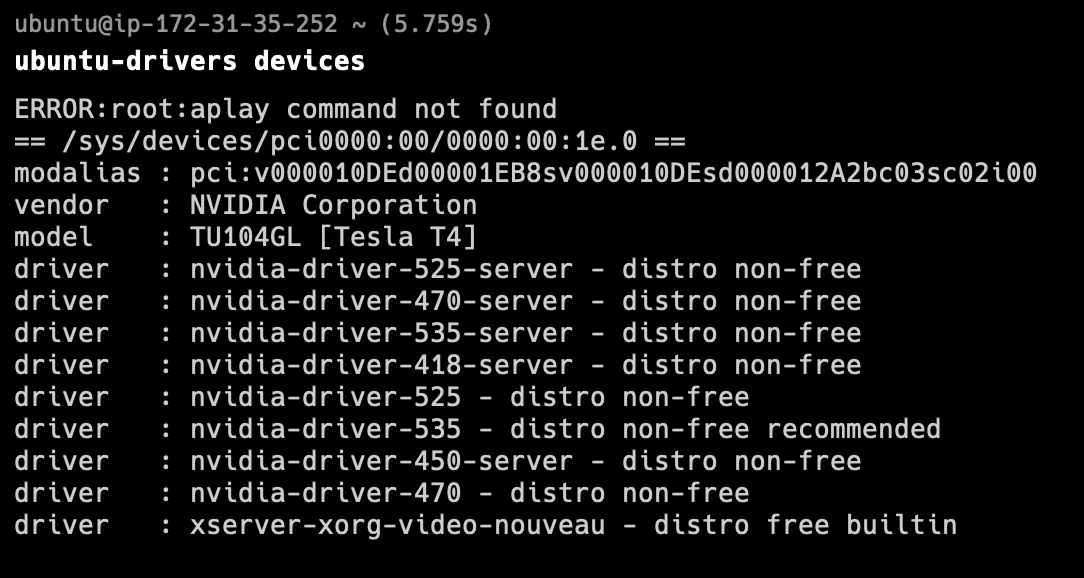 이런 식으로 자신의 gpu 성능에 따라 추천되는 gpu가 다르다. 나는 nvidia-driver-535를 추천했으므로, 저 드라이버를 설치하자.
이런 식으로 자신의 gpu 성능에 따라 추천되는 gpu가 다르다. 나는 nvidia-driver-535를 추천했으므로, 저 드라이버를 설치하자.
$ sudo apt-get update
$ sudo apt-get install nvidia-driver-535그 후, 제대로 GPU 리소스에 접근할 수 있는지 확인을 해보면 다음과 같이 나온다.
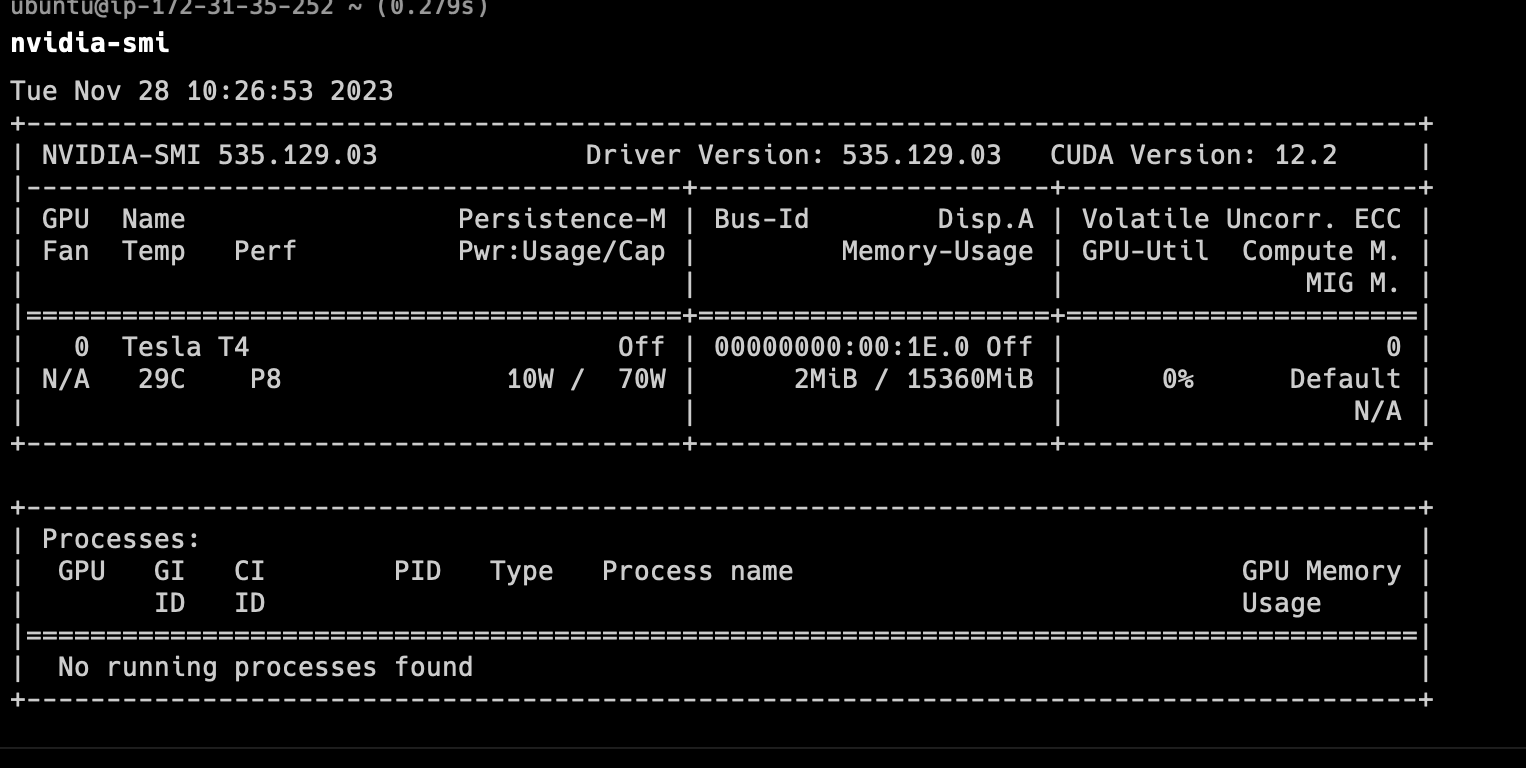 그러나, 아까 말했듯 Driver를 설치해도 결국
그러나, 아까 말했듯 Driver를 설치해도 결국 namespace 격리로 인해 이 Driver에 설치를 할 수 없게 된다. 따라서, 컨테이너 런타임을 Nvidia로 실행하여 이 Driver에 접근이 가능하도록 해야 한다. 런타임을 Nvidia로 설정하고, 컨테이너 안에서 GPU 리소스에 접근할 수 있는지 확인해보자.
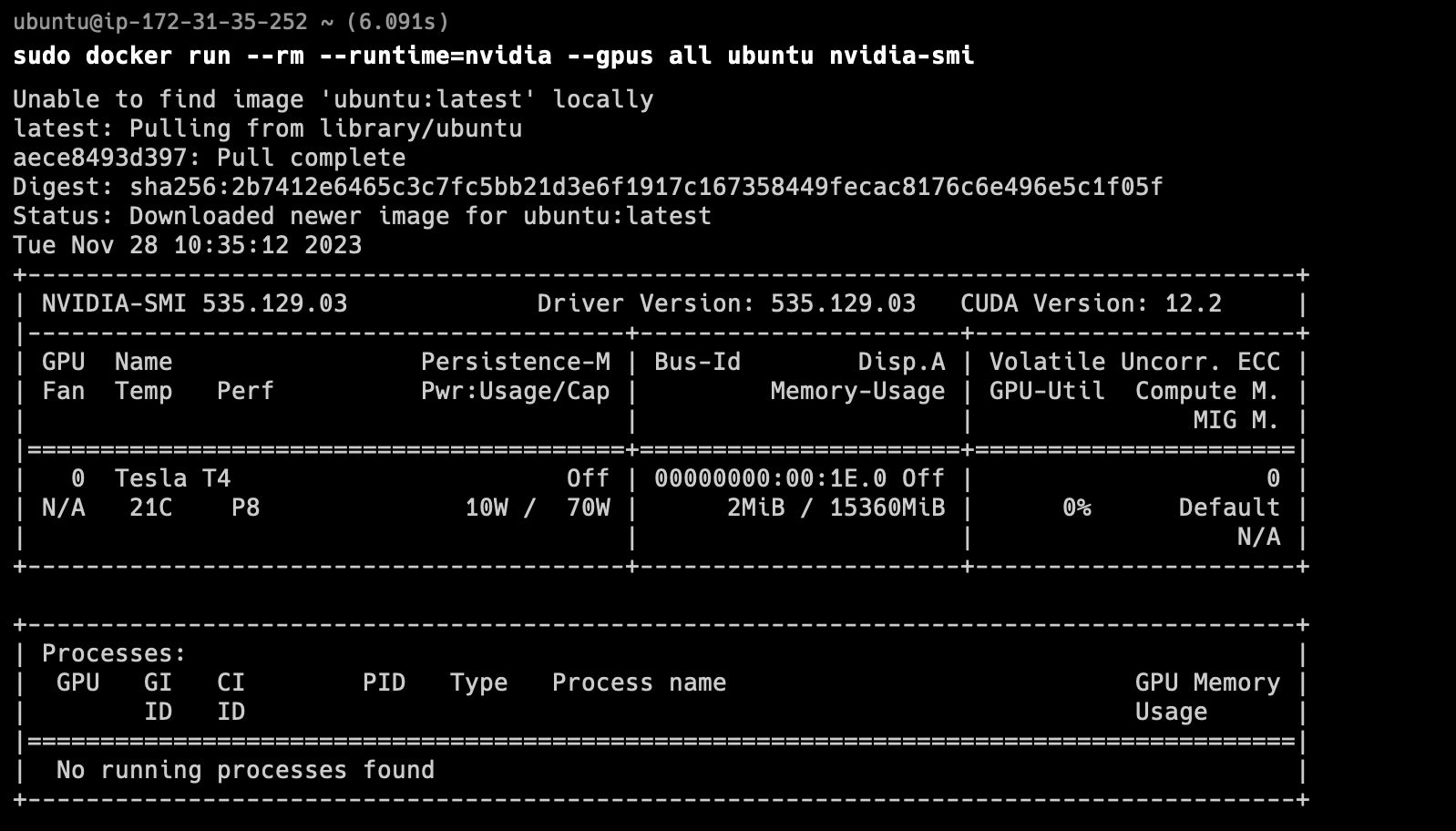 컨테이너 안에서도 드라이버에 접근이 가능한 것을 확인할 수 있다!!!!
컨테이너 안에서도 드라이버에 접근이 가능한 것을 확인할 수 있다!!!!
결론
GPU 하나 못 써서 불평하다가, 이 참에 왜 컨테이너에서는 GPU를 못쓰는지 알아보기 위해 컨테이너의 격리 기술을 조사해봤다. 어렴풋이 "컨테이너는 격리를 하기 위해 사용하는 것이다" 라고만 알고 있었는데, 어떻게 격리를 하는지는 몰랐었다.
Namespace를 통해 프로세스나 파일 시스템 등을 통해 격리를 시키고, Cgroups를 통해 커널 사용을 할당하거나 제한을 함으로써, 굳이 운영체제를 한번 더 올리지 않고 내부에서 분할하는 방식으로 훨씬 더 작은 오버헤드를 유발하는 격리 수준을 이룬다.
이 때문에 GPU 드라이버 프로세스에 접근을 못하기 때문에, 런타임 설정 등의 추가 조치가 필요하고, 그 후에 GPU 리소스에 접근이 가능한 것이다.

If you want to learn more about GPU sharing solutions, you can learn about the HAMi project, which is currently a CNCF sandbox project.