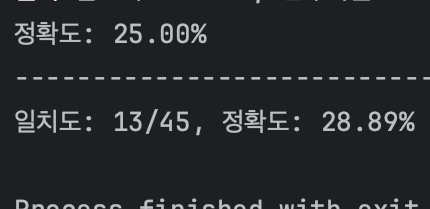
전처리를 하니 정확도가 75% -> 28%가 되는 기이한 현상...
서론
약 5개월간의 대장정이었던 캡스톤이 마침내 끝났다. '이게 될까?'라는 주제로 시작했던 프로젝트가, 서로 으쌰으쌰 하면서 각자 맡은 분야에서 최선을 다하니 '이게 되네!'라는 말로 마무리했던 아주 멋진 경험이었다. Spring에 감각이 생기고, Kubernetes로 인프라 및 CI/CD 까지 구축해서, 좀 더 스케일이 큰 배포까지 해본, 하고 싶은 건 다 할 수 있었던 경험이었다.
그러나, 본격적으로 프로젝트를 한 것은 처음이기에 많이 서툴렀다. 그리고 직접 구현하면서 꽤 많은 문제점은 해결되었지만, 아직 해결하지 못 한채로 남아있는 수수께끼들이 있다. 백엔드부터 시작해서 CI/CD, OCR, 그리고 인프라까지, 더 성장하기 위해서는 반드시 풀어야 할 의문점에 대해 나열해보려고 한다. 시험이 끝나고 한번 연구해볼 생각이다.
백엔드 (Spring)
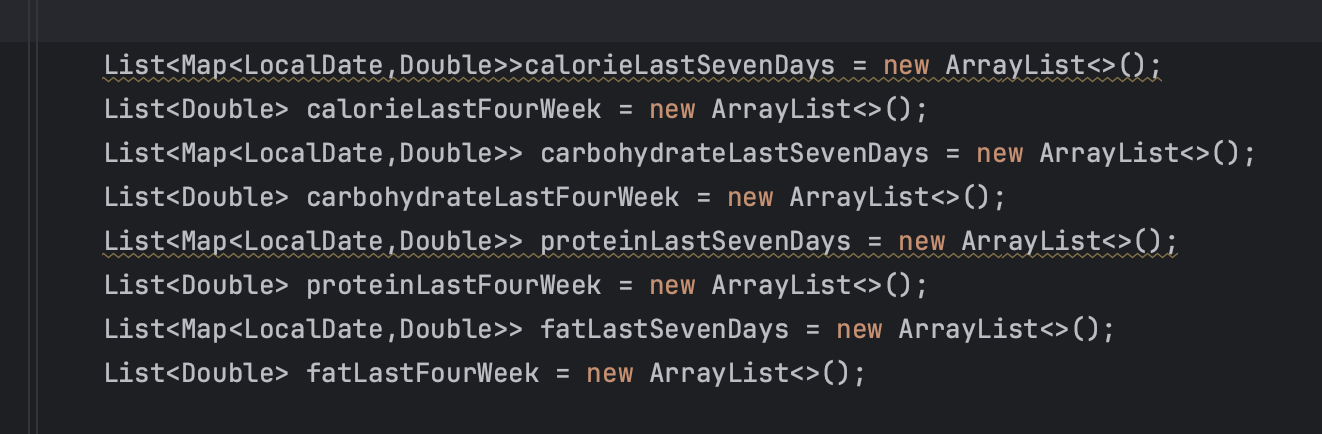
- 그래프 데이터를 그려낼 때, 영양성분 관련 누적 데이터를 저장하기 위해 8개의 ArrrayList (한 달 칼탄단지, 1주 칼탄단지)를 선언했는데, 보기에도 비효율적인 것 같은데 어떻게 개선할까?
- 생성 Dto로 객체를 생성하고자 할 때, 팩토리 메서드를 사용하는데 만일 엔티티 속성이 추가되면 객체 생성 메소드를 사용하는 모든 메소드의 파라미터를 모조리 바꿔야 했다. 더 나은 방안은?
FavoriteFood favoriteFood = FavoriteFood.createFavoriteFood(createFavoriteFoodDto.getName(), user, food, createFavoriteFoodDto.getBaseNutrition());- 객체를 Dto로 반환할 때, 파라미터 길이가 지나치게 길다. 다른 Dto 패턴은 없을까?
@Transactional(readOnly = true)
public List<ResponseFoodDto> getFoodListByDate(Long userId, LocalDate date){
return foodList.stream()
.map(food ->
ResponseFoodDto.of(food.getId(),
food.getUser().getId(),
food.getName(),
food.getBaseNutrition(),
food.isFavorite(),
food.getAddedTime().getHour(),
food.getAddedTime().getMinute()
))
.collect(Collectors.toList());
}-
객체를 업데이트 할 시, 객체에 직접 접근하는 update 메서드를 통해 값을 업데이트 했는데, 직접 객체에 접근하는 방법보다 더 개선할 방안은?
-
update, delete의 반환 타입은 void가 맞을까?
// 업데이트 반환값이 void다.
@Transactional
public void updateFood(UpdateFoodDto updateFoodDto, LocalDate date) {
...
}
// 삭제 반환값이 void다.
@Transactional
public void deleteFood(Long foodId, Long userId, LocalDate date) {
...
}- food와 favoritefood는 현재 1:다로 맺어져 있고, favoriteFood는 FK로 food와 연관관계에 있다. 이때 favoriteFood가 생성될 시, food와의 연관관계를 직접적으로 명시하는 food.setFavoriteFood() 메소드가 있다. 이 방법은 적절한 방법일까?
@Transactional
public Long saveFavoriteFood(CreateFavoriteFoodDto createFavoriteFoodDto) {
...
// Food와의 연관관계를 명시적으로 설정해준다.
food.setFavoriteFood(favoriteFood);
foodRepository.save(food);
...
}- Redis를 이용한 캐시 사용시 직렬화, 역직렬화 문제로 인해 예외가 다소 발생했다. 원인과 그 이유는?
2023-11-16 11:02:27.807 ERROR 1 --- [nio-8080-exec-9] o.a.c.c.C.[.[.[/].[dispatcherServlet]
: Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception
[Request processing failed; nested exception is org.springframework.data
.redis.serializer.SerializationException: Could not read JSON: Cannot
construct instance of `com.diareat.diareat.user.dto.response.ResponseRankUserDto
(no Creators, like default constructor, exist): cannot deserialize from Object
value (no delegate- or property-based Creator)
- 하위 객체인 favoriteFood에 변경사항이 있을 때마다 상위 객체인 Food의 메서드를 일일이 불러와 명시적으로 연관관계를 변경시켜줘야 했다. 과연 올바른 방안일까?
@Transactional
public void updateFavoriteFood(UpdateFavoriteFoodDto updateFavoriteFoodDto) {
...
// 연관관계가 있는 Food에 명시적으로 FavoriteFood의 속성을 바꿔준다.
food.updateFavoriteFood(updateFavoriteFoodDto.getName(), updateFavoriteFoodDto.getBaseNutrition());
...
}
@Transactional
public void deleteFavoriteFood(Long favoriteFoodId, Long userId) {
...
//모든 FavoriteFood 마다, 1:다 관계에 있는 Food와의 연관관계를 끊는다.
favoriteFood.getFoods().forEach(food -> food.setFavoriteFood(null));
...
}- 한달간의 영양성분을 4주단위로 묶기 위해 1주 단위로 총 4번 반복문을 실행하고, 그 반복문 안에서 또 반복문을 돌려 Map<LocalDate, BaseNutrition> 의 LocalDate가 해당 날짜에 있는지 확인하고 추가했다. 좀 더 효율적인 방안은?
@Transactional(readOnly = true)
public ResponseAnalysisDto getAnalysisOfUser(Long userId, int year, int month, int day){
...
// 한 달 전부터 시작해서 현재 날짜에 도달할 때까지 한 주 씩 더하여 반복문 실행
for (LocalDate date = currentDate.minusWeeks(3).with(DayOfWeek.MONDAY); date.isBefore(currentDate); date = date.plusWeeks(1)){
...
// 반복문 안의 한 주의 시작 (월요일)에서 하루 씩 더하여 반복문 실행
for (LocalDate inner_date = date; inner_date.isBefore(date.plusWeeks(1)); inner_date = inner_date.plusDays(1)){
// 칼, 탄, 단, 지의 영양소 합하기
...
}
// 안 쪽 반복문에서 합한 영양소를 배열에 추가하는 로직
...
}
...
}
- 애플리케이션 레이어 수준에서 연관관계를 설정하는 것이 아닌, 데이터베이스 영역에서 연관관계를 설정하고 참조하는 또 다른 방식이 있지 않을까? (on, join 등 …)
// Food와의 연관관계를 명시적으로 설정해준다.
food.setFavoriteFood(favoriteFood);- ResponseFoodDto와 ResponseSimpleFoodDto가 있다. 둘 다 음식에 관련된 응답 dto인데 불필요하게 dto를 사용하고 있지 않았을까?
public class ResponseSimpleFoodDto {} // Best 3 and Worst 3에 사용될 객체
public class ResponseFoodDto {} // 식습관 그래프나, 단순 음식 정보 반환 때 사용된 객체
-
api를 공인 도메인에 노출시키는 것은 위험하다. 실제 기업에서는 이를 보완하기 위해 어떤 방법을 사용할까?
-
회원가입 api와 로그인 api를 통해 임시의 JWT 토큰만 얻으면 모든 api에 접근할 수 있다. 좀 더 보안성 좋은 방법은 무엇일까?
-
Transactional을 사용해 테스트 코드를 작성하는 방법과, Mockito를 사용해 테스트 코드를 작성하는 방법 두 가지가 있었다. 이 둘은 각각 언제 사용해야 빛을 발할까?
OCR
- 이미지 전처리를 시도했는데 오히려 OCR 정확도가 떨어진 이유는 무엇일까?

- OCR 추론 요청을 할 때, 한번에 두개의 요청이 들어오면 순차적으로 처리를 하고, 그 다음 요청에 처리를 하기 때문에 훨씬 오래 걸렸다. 병렬적으로 처리하는 방법은 없을까?
- 파이썬의 event loop 방식으로 멀티 스레드 방식을 사용했더니 훨씬 느려졌다. 그 이유는?
from concurrent.futures import ProcessPoolExecutor
import asyncio
executor = ProcessPoolExecutor(max_workers=10)
async def run_in_executor(func, *args):
loop = asyncio.get_event_loop()
result = await loop.run_in_executor(executor, func, *args)
return result
# FastAPI에서 영양성분표를 파싱하기 위해 multipart로 이미지 받아옴
@app.post("/parse_nutrients", status_code=201)
async def read_item(file: UploadFile = File(...)):
contents = await file.read()
nparr = np.frombuffer(contents, np.uint8)
#multipart 값을 이미지로 변환
image = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
#멀티 스레딩 방식으로 이미지 처리
result = await run_in_executor(nutrition_run, image)
-
멀티 프로세스로 진행했더니 복수 요청에 대해 어느 정도 잘 처리했다. 그러나 CUDA out of memory 오류가 계속해서 발생하여, 어쩔 수 없이 싱글 프로세스로 진행했다. 이 이유는? 그리고 해결방안은?
-
멀티 프로세스, 멀티 스레드 방식을 파이썬에서는 어떻게 적절하게 적용할까?
-
OCR 추론의 경우 어떤 방식으로 해야 복수 개의 요청에 대해 효과적으로 처리할 수 있을까?
-
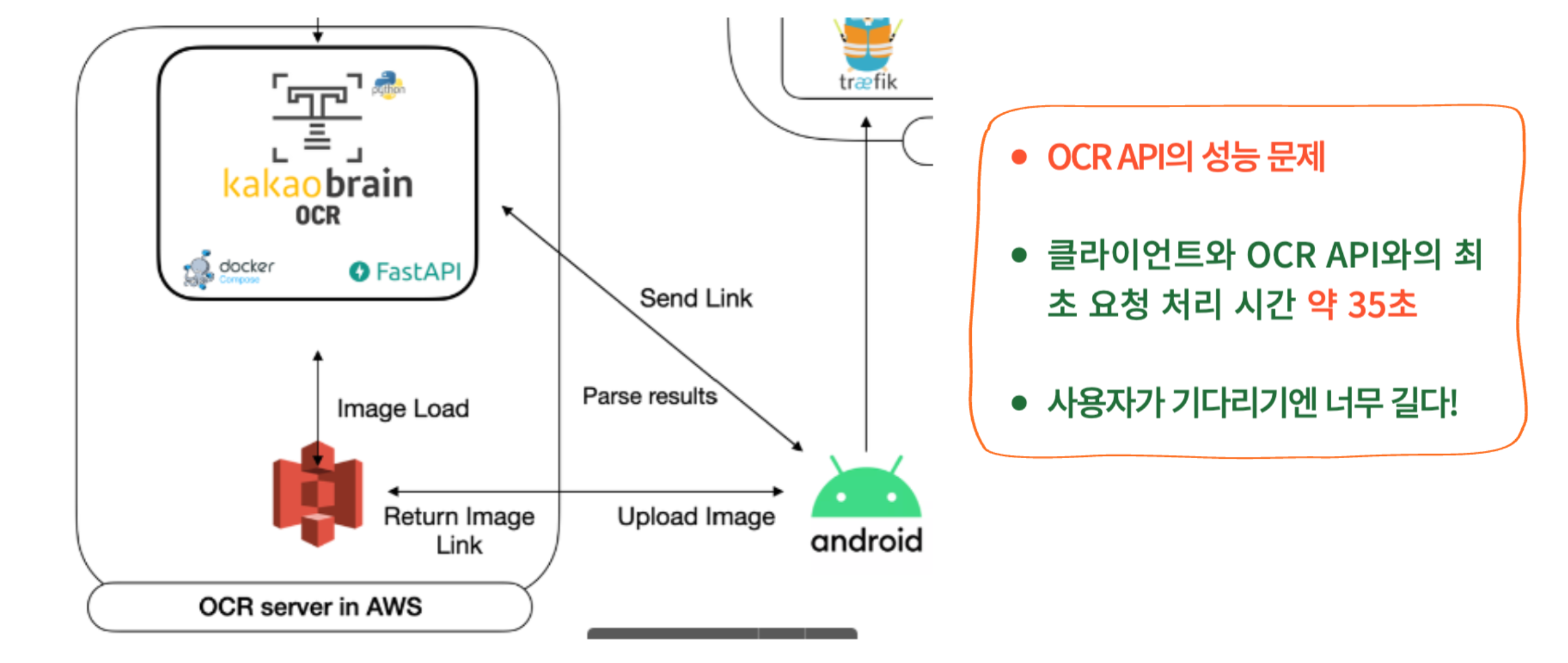
FastAPI를 사용할 때 S3 이미지를 다운 받고 처리했더니 지나치게 느렸다. 그래서 Multipart 방식으로 직접 이미지를 다운받았다. 뭔가 잘못된 방식이었을 것 같은데, 해결방안은?
-
Multipart 방식과 S3 방식의 장단점은 무엇일까?
CI/CD, 인프라 (Kubernetes)
- 처음으로 아키텍처를 설계해보았다. 더 보완해야 할 점은 무엇일까?
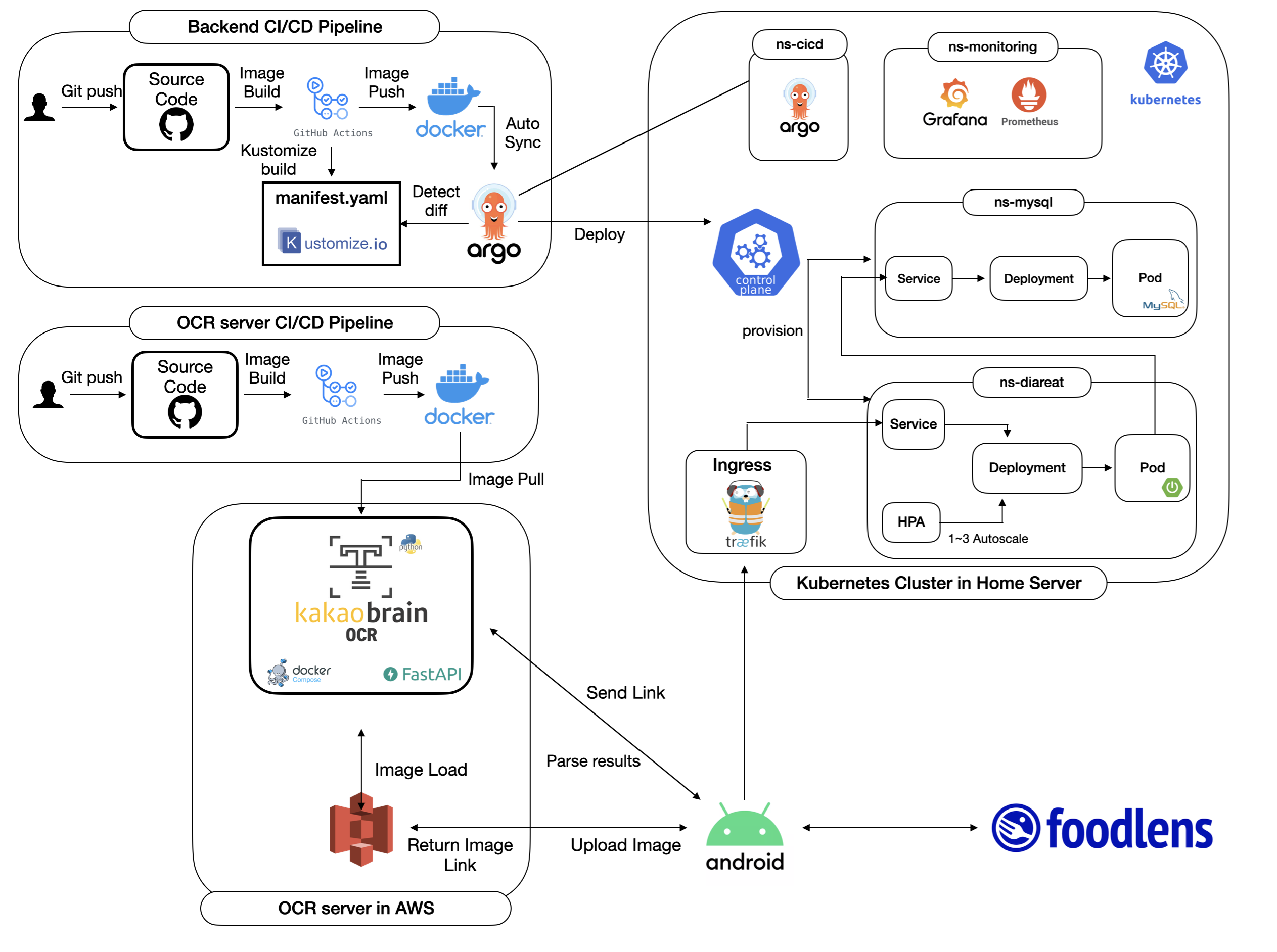
-
Kubernetes는 과연 트레이드 오프가 없는 방안이었을까? Nginx & EC2 배포에 비해 Kubernetes 배포가 갖는 이점과 트레이드 오프는? (Traefik, Nginx)
-
자꾸만 완돌이가 죽어, 불안한 마음에 실제 LINC 사업단 경진대회에서는 EC2, RDS로 진행했다. 완돌이는 왜 자꾸 죽었을까? DHCP 오류였을까?
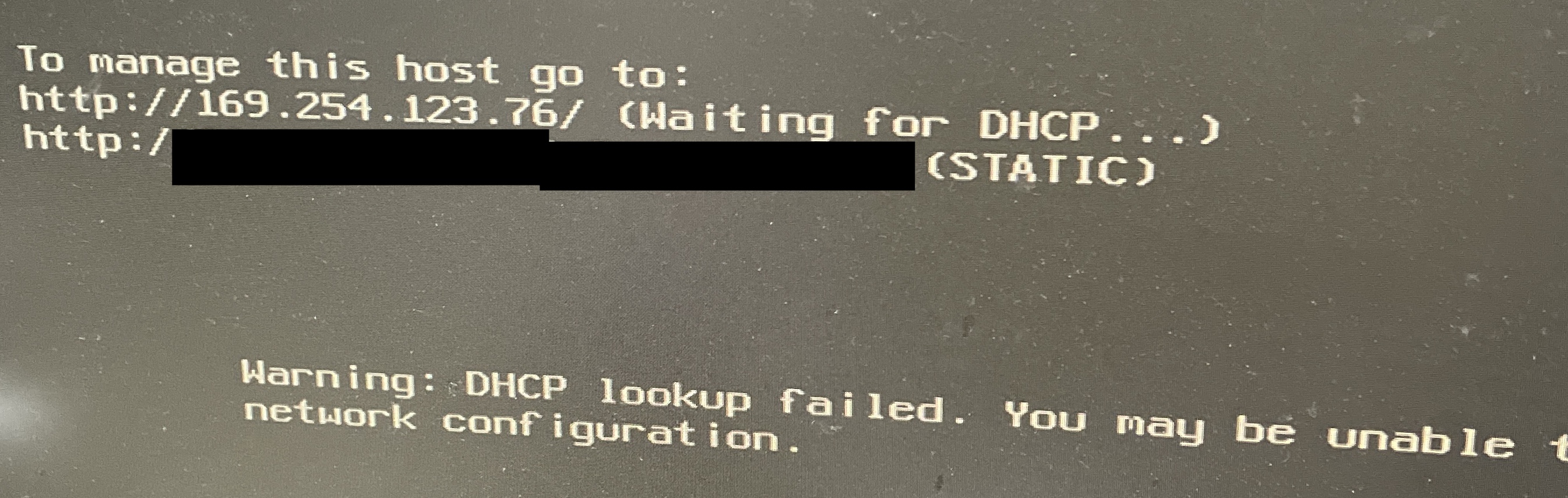
-
대다수의 기업들이 데이터베이스를 온프레미스 환경이 아닌 RDS와 같은 DB 전용 환경을 굳이 쓰는 이유는?
-
서버를 컨테이너화 시키는 것은 과연 배포단계에서의 Silver Bullet이라고 불릴 수 있을까? 서버 내에서 직접 코드를 실행하는 것과, 컨테이너로 실행하는 것의 장단점은 무엇일까?
-
파드 교체 과정에서 트래픽 정상 수신 여부를 확인하기 위해 readinessProbe를 사용했다. livenessProbe와 같이 사용하면 어떤 점에서 더 이점이 있을까?
-
Kubernetes를 적극 사용하는 기업의 경우도 Kustomization을 사용할까? 내가 구축한 Kubernetes 기반 CI/CD 파이프라인과 기업의 파이프라인에는 어떤 차이점이 있을까?
캡스톤 링크
Diareat, 사각지대 없는 식습관 관리를 위해!
https://github.com/CAUSOLDOUTMEN
혹시 보시면서 해결 방안이 있다고 생각되시면, 자유롭게 댓글 달아주시면 정말로 감사드리겠습니다.
