LLM에 대한 alignment를 잘하기 위해서는 퀄리티가 좋은 데이터가 반드시 필요하다. 여기서 생각해볼 점은 좋은 퀄리티를 가진 데이터란 무엇인가이다. 이 점은 두고 두고 고민해야 한다. 우리가 직면한 문제에서 적절하며, 좋은 퀄리티를 가진 데이터가 무엇일지 고민해야 한다. 다음은 여러 가지 데이터를 좋은 퀄리티를 얻을 수 있는 대표적인 방법론들이다.
Instructions from Human
- 일단 간단하게는 기존에 존재하는 human-annotated NLP benchmark가 있음.
- i.e.) AI HUB 데이터 등등
- 뿐만 아니라, 직접 비용을 들여가며 사람을 고용해서 라벨링하는 방법이 있음.
NLP Benchmarks
- 기존에 존재하는 NLP Benchmarks를 natural language instruction 형태로 바꾸는 방식이 존재한다.
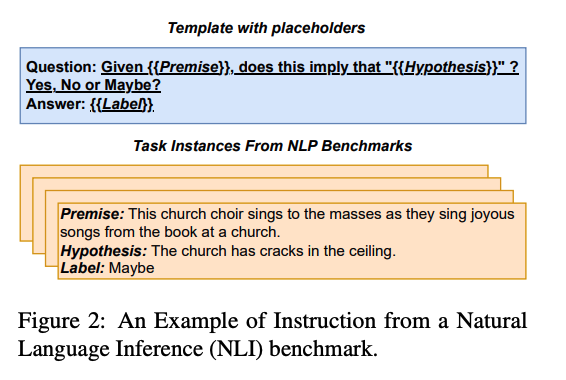
- 위의 예시의 benchmarks에서 natural language instruction 형태로 바꾸는 방법을 보여준다.
- 기존에는 자리 구분자 표시가 존재하는 형태였지만, LLM이 잘 이해할 수 있는 형태로 변형하여 instruction을 준다.
- 이러한 benchmark들은 상당한 양의 diverse하고, heterogeneous한 데이터셋들을 포함하고 있다.
Hand-crafted Instructions
- NLP 벤치마크를 활용해서 instruction 데이터셋을 구성하는 것은 꽤나 효과적임.
- 그러나, 많은 NLP 데이터셋들이 아주 협소한 분야로 치우쳐져 있음. 즉, 범위가 너무 좁음.
- 그래서, real world에는 적합하지 않다는 게 단점.
- 특정 분야의 문제만 풀 것이라면 NLP 벤치마크가 괜찮지만, wide한 범위의 문제를 풀기에는 어렵다는 단점이 있음.
- 이러한 문제점을 해결하기 위해 Databricks와 같은 회사들은 그들의 직원들로부터 직접 수작업으로 15000개의 natural한 데이터셋을 수집함.
- 수집하는 과정에서 외부의 웹브라우저에서의 정보도, chatGPT와 같은 LLM을 활용하지도 않았음.
- 또는 다음과 같은 방법을 쓸 수도 있다.
- ShareGPT - 사람들이 GPT를 사용하여 instruction을 한 것들을 모아놓은 곳이다. 여기서 human-written instructions을 얻을 수 있을 뿐만 아니라, high qualitydml GPT 답변도 얻을 수 있다.
- Stack Overflow도 중요한 소스가 될 수 있다.
- Stack Overflow와 같이 유명한 온라인 QA Websites를 활용할 수 있다. 국내 한정 네이버 지식인 또는 아하 QnA 등등
Instructions From Strong LLMs
-
데이터셋을 모으는 자동화 방법에는 closed-source LLMs(e.g. ChatGPT/GPT4)들을 이용하는 방법도 있다.
-
적절한 prompt를 제공함으로써, 다양하고 high quality의 데이터셋을 얻을 수 있다.
-
아래는 전반적인 self-instruct 방식의 데이터 생성 방법론이다.
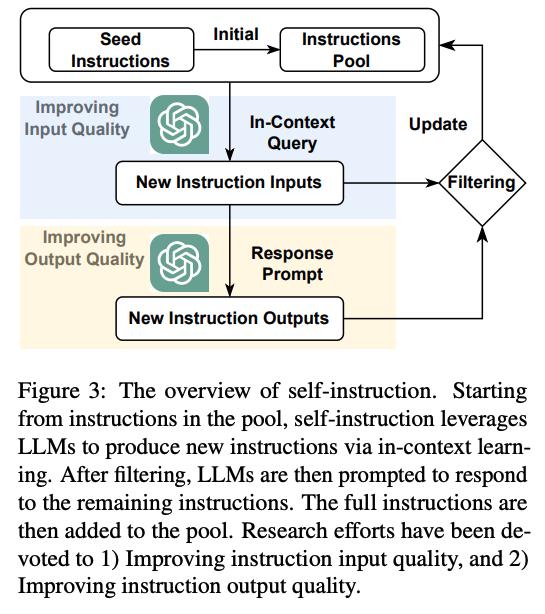
-
데이터 pool에 존재하는 instruction들로부터 시작해서, self-instruction이 LLM들을 활용해서 새로운 instruction을 in-context learning(prompting) 방식으로 생성해낸다.(self-instruction에 대해서는 이후에 추가적으로 설명).
-
이 중에서 quality가 낮은 instruction들을 정제한 뒤, 다시 in-context learning 방식으로 다시 instruction에 대한 output을 생성한다.
-
이렇게 생성된 output 중에 quality가 낮은 것들을 정제한 뒤, full instruction set을 구축하여, instruction 데이터 풀에 넣어준다.
-
여기서 중요한 점은 instruction input quality와 instruction output quality를 어떻게 높여줄지이다.
Self-Instruction
- Self-Instruct는 연구자들 사이에서 instruction 데이터셋을 모으는데 human resource가 너무 많이 들어가다 보니 어떻게 하면 자동화하여 데이터셋을 모을까해서 나온 방법론이다.
- ChatGPT와 같은 LLM을 활용하여 잘 prompting을 한다면 large-scale instruction들을 생성해낼 수 있다.
- 또한 diverse한 topic과 task를 커버할 수 있다.
- 심지어 연구자들은 이러한 ChatGPT로 생성한 insruction을 활용하여 fine tuning했을 때가 NLP benchmark를 활용하여 fine tuning했을 때보다 더 성능 측면에서 나은 점도 발견했다.
- 우리가 잘 알고 있는 Alpaca도 이러한 방식을 차용한 것이다.
- 그리고 상단한 연구에 따라 instruction의 다양성, 품질, 복잡성 등의 측면에서 더 정교해질 것이다.
