ChatGPT를 시작으로 대규모 언어 모델이 쏟아지고 있는 현재 상황에서 LLM을 주어진 task에 맞춰서 잘 활용하기 위해서는 여러 분야를 공부해야 한다. 아래는 공부해야 할 키워드들에 대한 정리이다.
Aligning For LLMs
How to collect data
- Instructions From Human
- NLP BenchMarks
- PromptSource
- SuperNaturalInstruction
- FLAN
- Unnatural Instructions
- OIG
- Hand-crafted Instructions
- Dolly-v2
- OpenAssistant
- COIG
- ShareGPT
- NLP BenchMarks
- Instruction From Strong LLMs
- Self-Instruct
- Improving Input Quality
- Self-Instruction
- Lamini-lm
- Baize
- AttrPrompt
- WizardLM
- WizardCoder
- Unnatural Instructions
- Phi-1
- Improving Output Quality
- CoT
- Orca
- Improving Input Quality
- Multi-Turn Instructions
- Baize
- CAMEL
- SelFee
- UltraLLaMA
- Vicuna
- Multilingual Instructions
- Phoenix
- BayLing
- BactrianX
- Self-Instruct
- Instruction Data Management
- Instruction Implications
- TULU
- FLACUNA
- Data-Constrained LM
- BELLE
- Instruction Quantity
- IFS
- LIMA
- Instruction Mining
- Alpagasus
- Instruction Implications
How to train
- Online Human Alignment
- RLHF(Reinforcement Learning from Human Feedback)
- RAFT(Reward rAnked FineTuning for Generative Foundation Model Alignment)
- Offline Human Alignment
- Rank-based Training
- DPO(Direct Preference Optimization)
- PRO(Preference Ranking Optimization for Human Alignment)
- RRHF(Rank Responses to Align Language Models with Human Feedback without tears)
- SLiC
- Language-based Training
- Conditional Behavior Cloning
- CoH(Chain of Hindsight Aligns Language Models with Feedback)
- Stable Alignment
- SelFee
- SecondThoughts
- Rank-based Training
- Parameter-Efficient Training(a.k.a PEFT)
- Prefix Tuning
- Prompt Tuning
- LoRA(Low Rank Adaptation of Large Language Models)
- AdaLoRA(Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning)
How to evaluate
- Evaluation Benchmarks
- Closed-set Benchmarks
- Open-set Benchmarks
- Evaluation Paradigms
- Human-based Evaluation
- LLMs-based Evaluation
etc
- continual learning of LLMs
- quantization of LLMs
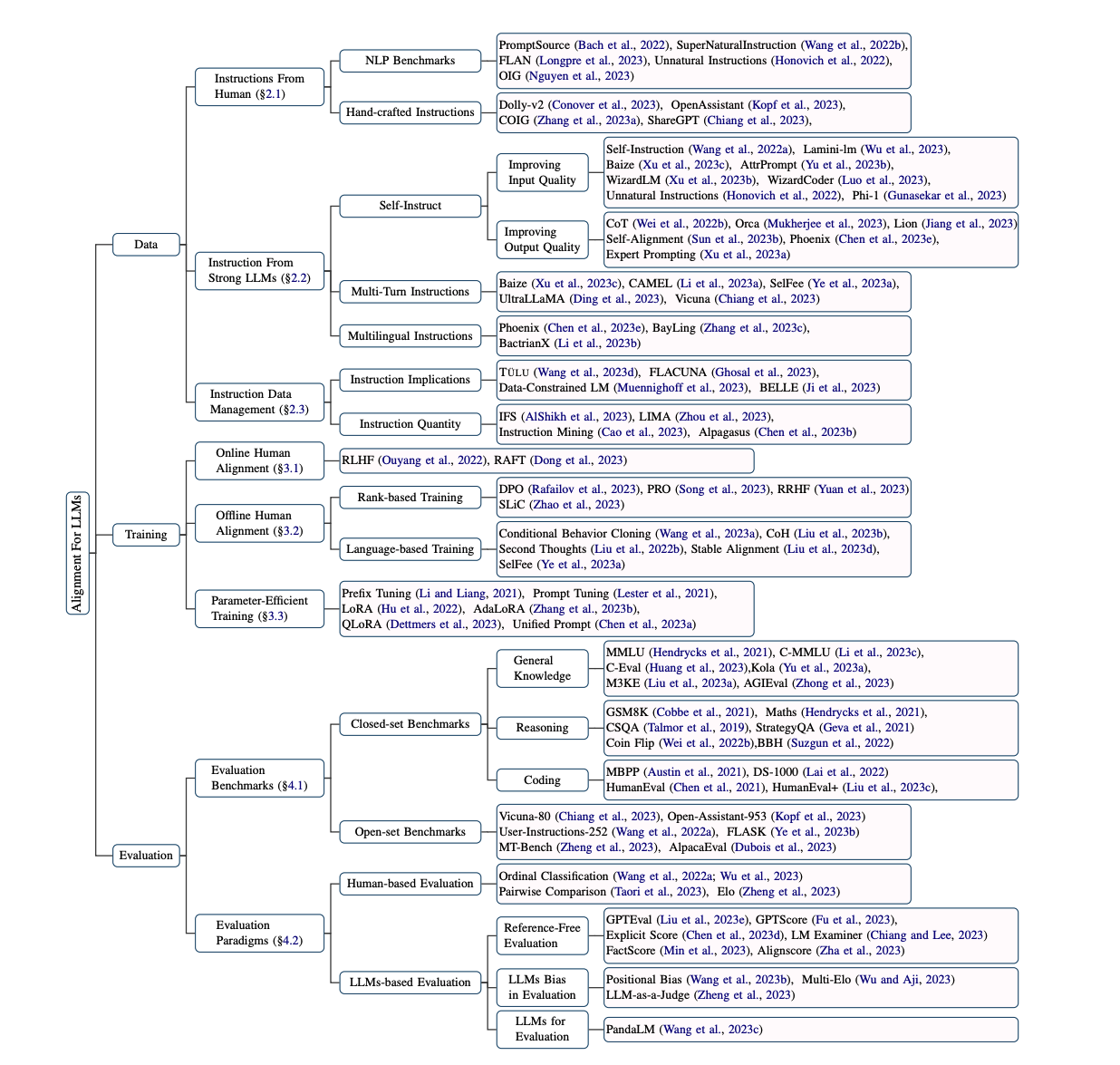
reference: https://arxiv.org/pdf/2307.12966v1.pdf

매일 매일 한 걸음씩 나아가고자 합니다.