[DeepSeek-Coder Review] DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
다음은 DeepSeek Coder이다. 물론 내가 코딩을 잘하는 Pretrained model을 만들 일이 있을지, 또 이러한 모델을 사용할 일이 있을지는 잘 모르겠지만, 그래도 대표적인 모델들에 대해서 읽다 보면 insight가 있지 않을까 싶어 읽어본다.
Summary
이번에도 Abstract에서 대표적인 키워드들을 한 번 뽑아보자.
- 2T tokens
- pre-trained on a high quality project level code corpus
- fill-in-the-blank task with 16K window
- surpasses Codex and GPT-3.5
등등이 있는 것으로 보인다. 그렇다면 이제 본격적으로 살펴보면서 각각의 개념들, 그리고 실험 결과들의 타당성 등에 따져보면서 한 번 보자.
Data Collection(2T tokens) & High-Quality project-level code corpus
일단 전체 학습 데이터의 87%를 차지하는 코드데이터를 어떻게 모았는지부터 한 번 살펴보자.
사전학습 데이터를 모을 때 기본적으로 중요한 건 학습 효율적으로 데이터를 모으고, high-quality 데이터를 모아야 한다는 것이다.
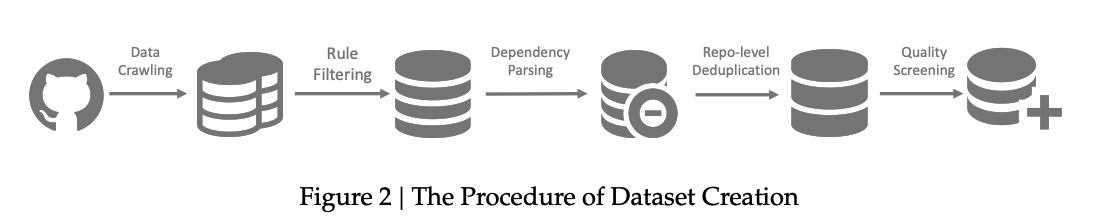
기본적인 파이프라인은 위와 같이 전개된다.
1. Data Crawling
2. Rule-based Filtering
3. Dependency Parsing
4. Repo-level deduplication
5. Quality Screening
Data Crawling and Filtering
그렇다면 가장 먼저 일단 코드 데이터를 수집하고 정제해야 한다.(보통 통상 raw dataset을 수집하게 되면 중복 데이터도 많고, 쓸모 없는 데이터도 많으니까....)
그래서 일단 모은다. 그리고 Filter한다.
- Github에서 2023년 2월 이전에 만들어진 코드들을 모두 모음.
- 그럼 이걸 어떻게 정제할 것인가?는 StarCoder를 참조하여, 그 방식으로 정제함.(StarCoder는 여러 사람들이 heuristic하게 visual inspection 방식으로 정제를 진행. 자세한 것은 StarCoder 참고)
결국 우리의 목적은 양질의 데이터를 모으는 것인데, 이걸 어떻게 정제할지를 StarCoder와 같은 선행 연구 논문을 보고 정제할 수 있다. 그렇다면 여기서 드는 생각은 평균 line 길이 100자 미만과 같은 heuristic한 부분은 어떻게 정할 수 있지?라는 생각이 드는데, 현실적으로 stratified random sampling을 한 다음에 결정하지 않았을까라는 생각이 든다.
사전학습 데이터는 정말 크기가 큰 사전학습 데이터고, 첫 필터링으로 최소한의 데이터를 거르는 방식으로 진행했을 것인데, 그에 따라 랜덤 샘플링을 통해 노이즈와 평균 line 길이의 관계를 보고, 이에 따라 noise가 가장 많이 제거되는 비율을 분포표를 보고 결정하지 않았을까라는 생각이 든다.
Dependency Parsing
- DeepSeek Coder의 본인들이 말하는 것은 Application level의 코딩 assistant를 만들고자 함.
- 그런데 기존에는 단독 파일로만 학습을 하니, project level로 잘 작동을 안 함.
- 그렇다면 Left to Right 방식인 LLM에 학습하려면? -> Topological Sort를 해서 dependency가 존재하는 것끼리 sequence를 정해줘야 하지 않을까? 라는 생각을 하게 됨.
그렇다면 이걸 어떻게 하면 될까?
예를 들어 우리가 다음과 같은 구조의 Repo가 있다고 가정하자.
evals/
├── evaluator.py # → import prompts.py, utils.py
├── utils/
│ └── utils.py
└── prompts/
├── prompts.py # → import templates.py
└── templates.py그렇다면 학습할 때 넣어야 하는 방식은 templates.py -> prompts.py -> utils.py -> evaluator.py 순서의 sequence가 되어야 file 간에 dependency를 학습하게 되지 않을까라는 생각을 함. 그리고 이렇게 학습 데이터를 구성함.
그에 대한 자세한 pseudo code이다.

Repo-Level Deduplication
크게 특별한 점은 없다. 기존의 LLM들이 거쳐왔던 과정으로 near deduplication을 수행했다.
조금 특이한 점이라면, 기존에 Coding을 위한 LLM들은 file 기반으로 deduplication을 했다고 하는데, 이렇게 되면 repo 내에서 필수한 파일들이 날아가서 구조가 깨지는 일들이 있어서, Repo Level로 dedup을 했다고 한다.
그런데 의문이 드는 점은 충분히 다들 생각할 수 있을 것 같은데, 왜 이전 논문에서는 하지 않았는지 잘 모르겠다.
Fill-in-the-blank task
- 참조논문
이 논문에서 조금 볼만한 점은 2 Step으로 학습했고, 이 과정에서 처음에는 Next Token Prediction 그리고, 그 다음에는 Fill-in-the-Middle 방식으로 학습을 했다는 점이다.
물론 FIM 방식이라고 해서 Objective function이 바뀐 것은 아니다.
FIM 방식은 다음과 같다.
- PSM(Prefix-Suffix-Middle)
- SPM(Suffix-Prefix-Middle)
그리고 FIM의 효과를 알아보기 위해서 HumanEval-FIM benchmark를 활용했다고 하는데, HumanEval-FIM benchmark는 다음과 같다. HumanEval Benchmark는 OpenAI에서 발표한 Code Generation 능력을 평가하기 위한 벤치마크로 여기서 FIM benchmark는 다음과 같다.
- HumanEval에서 특정 single line 부분을 random하게 가린다. 그리고 그 부분을 다시 복구시키도록 하는 task다.
그리고 CodeGen2.5에서는 MSP(Masked Span Prediction)이 FIM 성능을 올리는데 더 효과적이라고 하여 그 부분도 비교군에 넣었다고 한다.
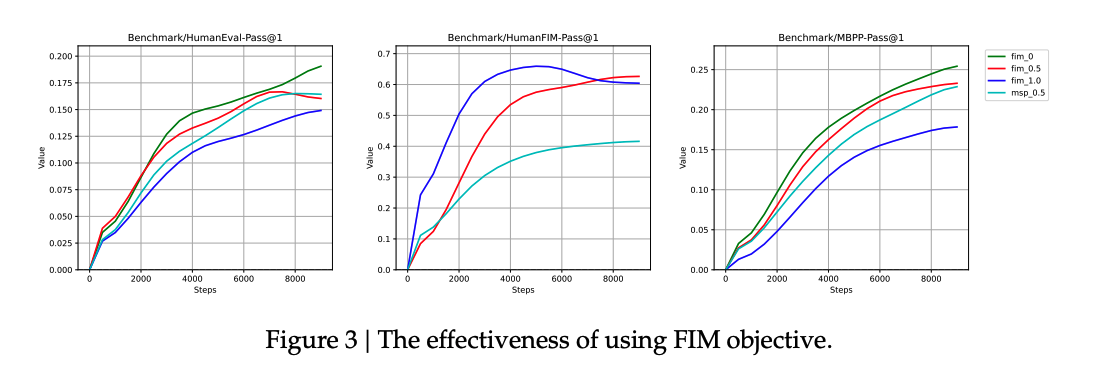
위의 결과를 보게 되면 아무래도 FIM task에 특화되어 있으므로 HumanEvalFIM에 대해서는 확실히 PSM 방식이 좋음을 알 수 있다.
그러나 이것만으로 모델의 성능을 판단할 수는 없으므로 HumanEval-Pass@1과 MBPP-Pass@1의 성능을 보게 되면 fim 0.5가 fim 1.0에 비해 조금 더 안정적으로 성능이 수렴함을 알 수 있다.
-> MSP(Masked Span Prediction)란?
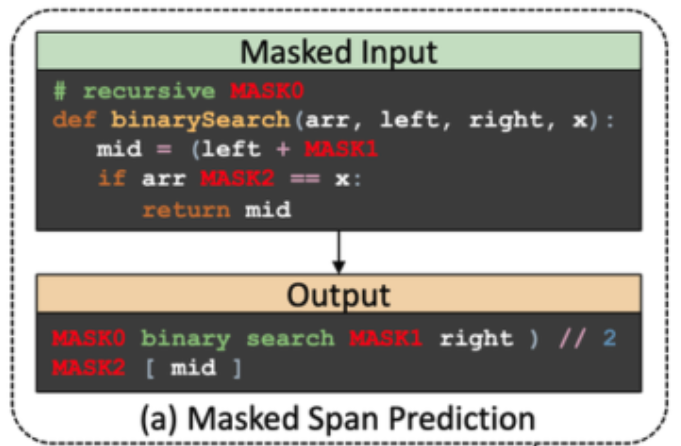
자세한 사항은 T5나 CodeT5를 참고하면 알 수 있다.
