[DeepSeek LLM Review] DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
아직 이직이 끝나지 않았지만, 한숨을 돌리며 다시금 제대로 정리하고 싶었던 DeepSeek LLM부터 순차적으로 정리하고자 한다.
이직을 준비하면서 이때까지 내가 고민하지 못했던, 그리고 더 깊게 고민해야 했던 부분들을 정리하면서 한 단계 더 성장하고자 한다.
또한 비록 아직 이루지 못했지만, 언젠가는 LLM 또는 혁신적인 기술의 코어를 만드는데 기여하는 그 날을 고대하며, 이 글을 작성한다.
Summary
Abstract에는 대표적인 키워드들이 몇 개가 있다.
- Scaling Laws
- consists of 2T tokens
- SFT and DPO on DeepSeek LLM Base Models
- DeepSeek LLM 67B surpassed LLaMA-2 70B especially in the domains of code, mathematics, and reasoning
- evaluations
이 때부터 code(DeepSeek-coder)와 mathematics(DeepSeek-Math), reasoning(DeepSeek-R1)를 염두에 두고 있었던 게 아닌가 싶다.
그렇다면 위를 바탕으로 각각 어떻게 연구를 했는지 한 번 알아보면 좋을 것 같다.
Scaling Laws
이 paper에서는 Scaling Laws에 대해서 다시 한번 정의하려고 한다. 그렇다면 이 질문이 먼저 나온다.
왜 Scaling Laws가 모델을 학습하는데 중요할까?
사실 아주 간단하게 생각한다면 'Pretraining할 때 그냥 단순히 토큰을 많이 때려 박으면 성능이 올라가는 것 아닌가? 어차피 next token prediction이고, 통계적으로 더 많이 학습하면 되는 것 아닌가?'라는 생각을 했다.
그렇지만 우리는 Compute Budget이 한정적이다. 아무리 큰 기업이고, 아무리 GPU 보유량이 많다 해도, Compute Budget은 무한하지 않고, 그렇다면 특정 모델의 사이즈에 맞는 가장 효율적인 데이터양을 찾아야 한다.(물론 데이터를 잘 정제하여 noise도 제거해야 한다.)
그렇기에 본 논문에서도 그렇고, 2가지 선행 연구를 고려한다.
- Scaling Laws for Neural Language Models(OpenAI)
- Training Compute-Optimal Large Language Models(DeepMind)
그런데 본 논문에서는 위 두 논문은 한계가 있다는 점을 들며, 새로운 Scaling Law를 제시한다.
그렇다면 위의 논문들은 어떤 결과를 도출해냈을까?
-
Kaplan Scaling Law
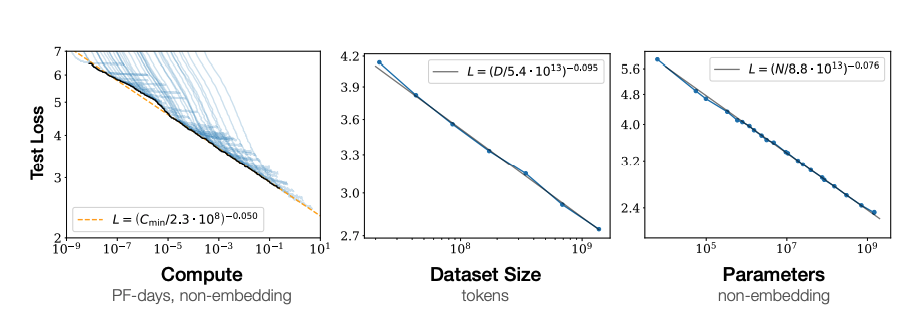
- 모델의 성능은 compute Budget , model scale , data scale 에 따라 결정된다는 것을 제시한다.
-
Chinchilla Scaling Law
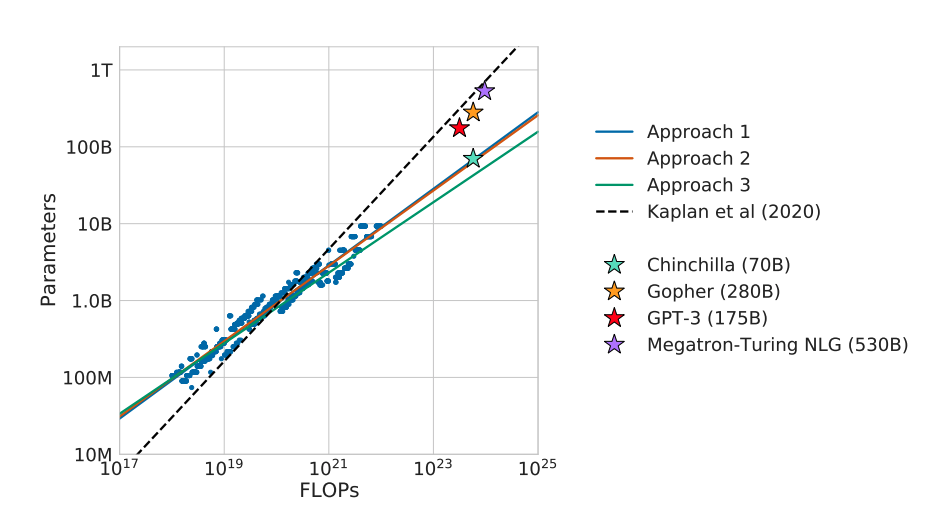
- 그리고 Compute Budget은 결국 고정되어 있을테니 이에 따라 최적의 model scale과 data scale이 존재한다.
- Chinchilla Scaling Law에서는 70B의 모델을 학습하는데 1.4T 정도의 토큰이 필요하다고 말한다.
자세한 부분은 논문을 참고.
empirical하게 실험을 했으며, Llama나 이런 모델에서도 pretrain을 할 때, 실제로 Chinchilla Scaling Law등을 참고해서 token을 태운 것으로 알고 있다.
그런데 왜 DeepSeek LLM에서는 새로운 Scaling Law를 제시하는가?
1. 일단 다른 연산량(모델 크기나 데이터 크기에 따라 연산량이 다를 수 있음.) 내에서 hyperparameter 세팅을 어떻게 해야하는지 제시하지 않았다고 한다. 사실 디테일한 performance를 내기 위해서는 batch size, learning rate 이러한 것들이 중요한데 말이다.
2. 그리고 Compute Budget을 더 정확히 계산하기 위해서 Data scale과 Model scale사이의 식을 수정하고자 한다.
그래서 Contribution은 다음과 같다.
1. Hyperparameter에 대한 Scaling Law
2. 모델 파라미터 크기를 토큰당 FLOPs로 계산. -> 조금 더 정확한 optimal model/data scaling-up
3. 사전학습 데이터의 퀄리티에 따른 optimal model/data scaling-up
그렇다면 이제부터 하나하나 알아보자.
Scaling Laws for Hyperparameters
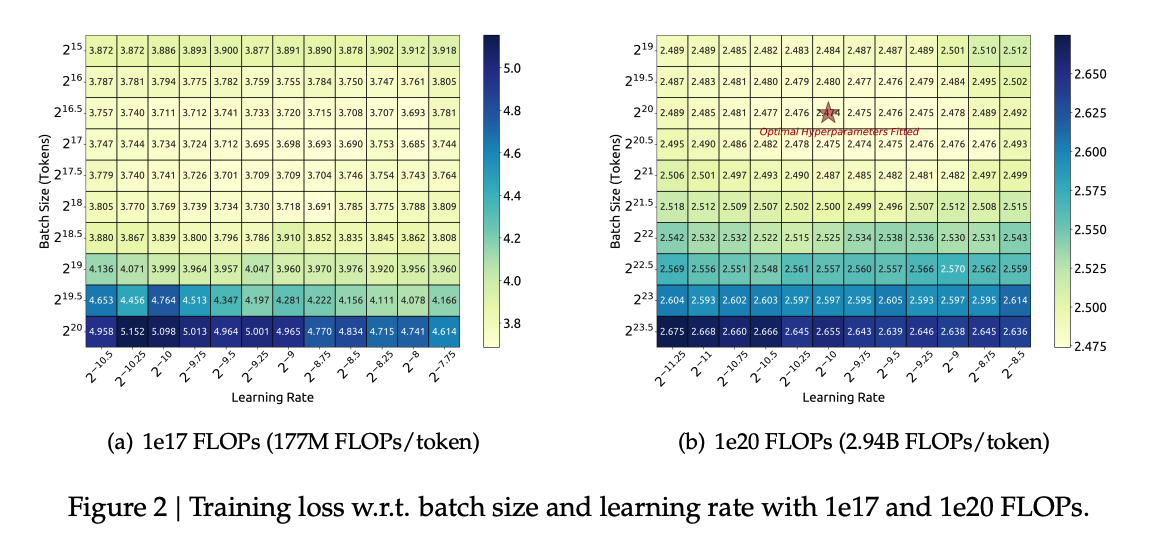
- small-scale experiments로 해봤을 때 꽤나 넓은 분포로 near-optimal 한 것을 볼 수 있음.
- 그리고 나서 1e17 ~ 2e19까지 본 논문에서 나온 Multi-step lr scheduler를 바탕으로 batch size, lr, compute budget에 따라 다양한 모델 학습을 해 봄.
- 그 결과, 다음과 같은 특징을 찾음.
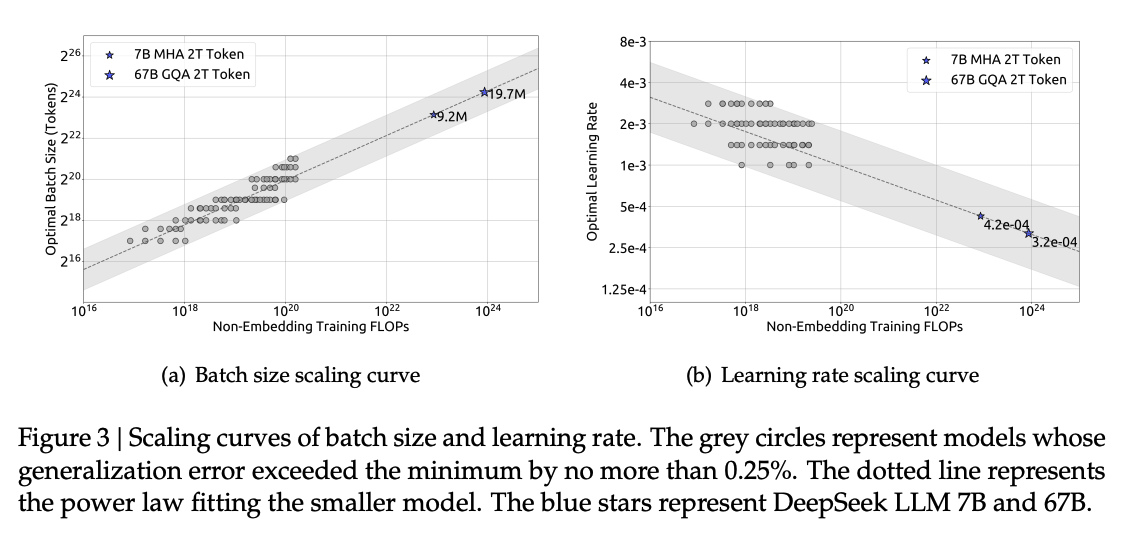
- Optimal한 성능에 도달하기 위해서 Compute Budget이 오를수록, Batch Size가 커짐.
- Optimal한 성능에 도달하기 위해서 Compute Budget이 오를수록, Learning Rate가 작아짐.
- 그래서 다음과 같은 식에 도달함.

- 이걸 바탕으로 7B와 67B를 학습할 때 Batch size와 LR을 설정한 것으로 보임.
- 따라서 우리는 여기서 작은 모델을 가지고 Batch size와 LR을 설정하여 여러 가지 ablation을 한 뒤, near-optimal을 찾아서 큰 모델에 적용해보면 되지 않을까라는 생각을 해본다.
Estimating Optimal Model and Data Scaling
그렇다면 이번에는 최적의 데이터 스케일과 모델의 관계는 어떻게 될까?
- Kaplan과 Chinchilla의 Scaling Laws에서는 대략 의 값을 도출해냄.
- Kaplan Scaling Laws에서의
- non-embedding parameters -> 마지막 vocab 출력 레이어를 제외한 파라미터수
- Chinchilla Scaling Laws에서의
- complete parameters -> 마지막 vocab 출력 레이어를 포함한 파라미터수
그러나 DeepSeek LLM에서는 이것이 정확한 Flops를 위한 계산인가? 라는 의문을 던졌다. 도대체 attention 계산이 많은 것을 차지하는데 이것은 어디간 것인가? 라는 의문을 시작으로 non-embedding FLOPs / token M이라는 개념을 제시했다.
그리고 이것은 그것을 비교한 식이다.
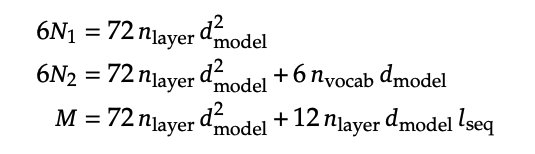
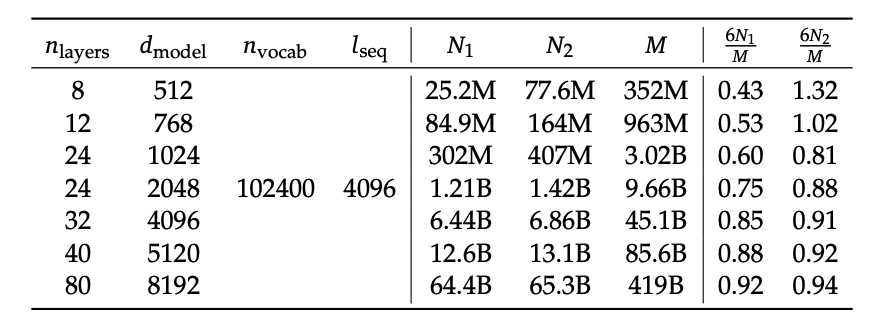
그리고 위 표는 (Kaplan), (Chinchilla), (DeepSeek)으로 계산했을 때의 수치 차이다. 작은 모델에서 더 큰 수치 차이를 볼 수 있고, 이는 Data Scaling을 얼마나 해야 할 지 정할 때 큰 오차로 다가올 수 있음을 말한다.
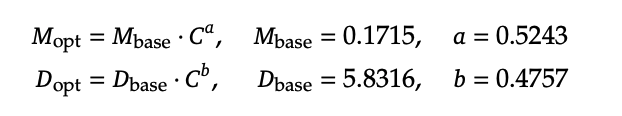
위 식을 바탕으로 내가 주어진 Compute Budget이 어느 정도라면 이에 맞는 모델 사이즈와 데이터 크기를 정할 수 있다고 한다.
Scaling Laws with Different Data
마지막으로 이번에는 데이터의 퀄리티에 따른 Scaling Law는 어떻게 될까? 이다.
DeepSeek LLM 연구진은 데이터를 계속 추가적으로 정제하면서 데이터 구성이 바뀌는데 이에 따라 Scaling Laws도 바뀐다는 것을 발견했다.
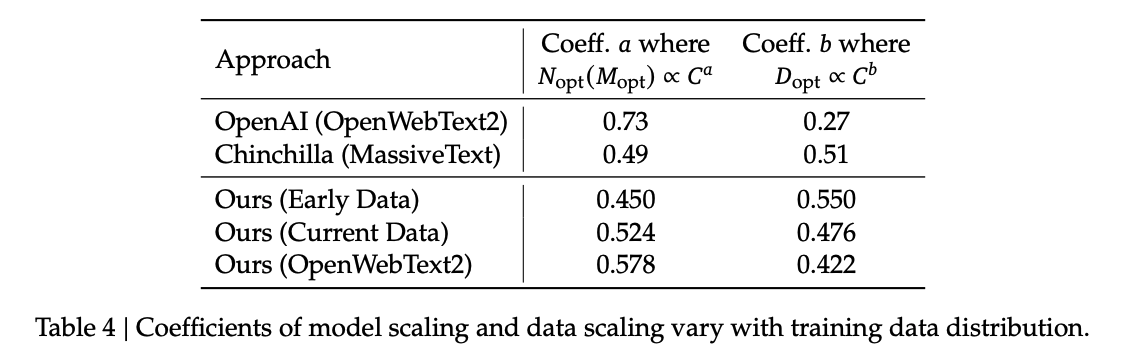
- Early Data는 그냥 수집한 데이터로 추정됨.(거의 raw data 수준 아닌가 생각됨.)
- Current Data는 Early Data보다는 data quality가 더 높다고 말함.
- OpenWebText2는 Current Data보다도 data quality가 더 높다고 말함.
- 위 표를 보게 되면, 더 정제를 잘할수록 data quality가 높을수록 모델 스케일에 더 많은 비중을 둘 수 있음을 알 수 있음.
Data(2T tokens)
다음은 학습용 데이터를 어떻게 수집하고 정제했는가이다. 모델을 최적화하기 위해서는 다양한 학습 데이터를 수집해야 하고, 또 효율적으로 학습을 하기 위해서는 정제가 필요하다.
보통 데이터를 수집할 때 2가지를 고민해야 한다.
- richness
- diversity
위 2가지를 어떻게 확보할 것인지에 대한 많은 고민을 해야 한다. 그렇다면 DeepSeek 연구진들은 어떤 paper들을 참고하고 본인들만의 방법을 새롭게 정의했는가를 본다면,
- RedPajama: an Open Dataset for Training Large Language Models(Together AI, Stanford Univ, Chicago Univ, Eleuther AI... etc)
- The Pile: An 800GB Dataset of Diverse Text for Language Modeling(Eleuther AI)
- The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only(The Falcon LLM Team)
- LLaMA: Open and Efficient Foundation Language Models(Meta)
를 참고했다고 한다.
Deduplication
Deduplication을 조금 더 공격적으로 수행했다고 한다. 일반적으로는 dump 별로 deduplication을 수행을 하는데, 과연 이게 제대로 정제가 될까? 라는 의문에서 시작하지 않았을까 생각된다.

- 위 표를 보게 되면 단순히 dump별로 정제하는 것보다, entire dump를 가지고 정제를 했을 때 4배나 많은 데이터가 정제됐음을 볼 수 있다.
Filtering
필터링은 다음과 같은 방식으로 진행되었다.
- linguistic과 semantic 관점에서 평가하였다.(어떻게 했는지 자세한 내용은 나오지 않는다.)
- 그리고 data imbalance를 맞추기 위해 underrepresented domain에 관련된 데이터를 remixing했다고 한다.
Tokenization
토크나이저는 다음과 같이 만들었다고 한다.
- BBPE tokenizer를 활용했다고 한다.
- 또한 Pre-tokenization에서 new lines + Chinese-Japanese-Korean Symbol이 합쳐지는 문제를 피하고자 하였다.
- number는 개별로 tokenizing 했다고 한다.
사실 Data는 크게 특별한 부분은 없어 보인다.
Comments
Alignment나 이러한 부분들은 특별한 부분이 없어서 Scaling Laws나 Data 부분에만 집중을 했다. 이를 바탕으로 우리는 모델을 학습할 때 data scaling과 model scaling에 대해서 고민해볼 수 있지 않을까라는 생각을 한다.
또 스터디를 하면서 다른 분들의 평을 보고는 하는데 아직까지는 나는 그 정도로 생각이 나아가지는 못하는 것 같다.
