[DeepSeek-R1 리뷰] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning(GRPO Part)
이전 설명에 이어서 DeepSeek-R1 한 번 분해해보자.
그렇다면 이제부터 본격적으로 R1 모델을 분해해보자.
DeepSeek-R1-Zero
핵심부터 한 번 더 짚고 넘어가자.
DeepSeek-R1-Zero 모델은 SFT 없이, RL만으로 성능을 높힌 모델이다. 그리고 그 RL은 GRPO라고 하는 알고리즘이다.
Group Relative Policy Optimization(GRPO)
Why was GRPO created?
PPO를 개선하기 위해서 GRPO라는 방법론을 생각해냈다.
그렇다면 PPO의 어떤 부분을 개선해야할까?
- PPO는 기본적으로 4개의 모델이 필요하다.
- policy model
- reference model
- reward model
- critic model
- 각각의 용도를 생각해본다면,
- policy model은 dialogue가 주어진다면 어떤 token(action)을 생성해야 할 지에 대해 결정하는 모델이다.
- reference model은 토큰 별로 reward를 줄 때 정책이 급변하는 것을 막기 위해 KL penalty를 주기 위한 용도의 모델이다.(아래의 식 참고)
- reward model은 위의 식에서 reward를 주기 위해 쓰이기도 하고, advantage에서 Q function을 계산하기 위해서 쓰이는 reward를 계산하기 위해서 사용되기도 한다.
- critic model은 advantage function에서 value function을 계산하기 위해서 사용된다.
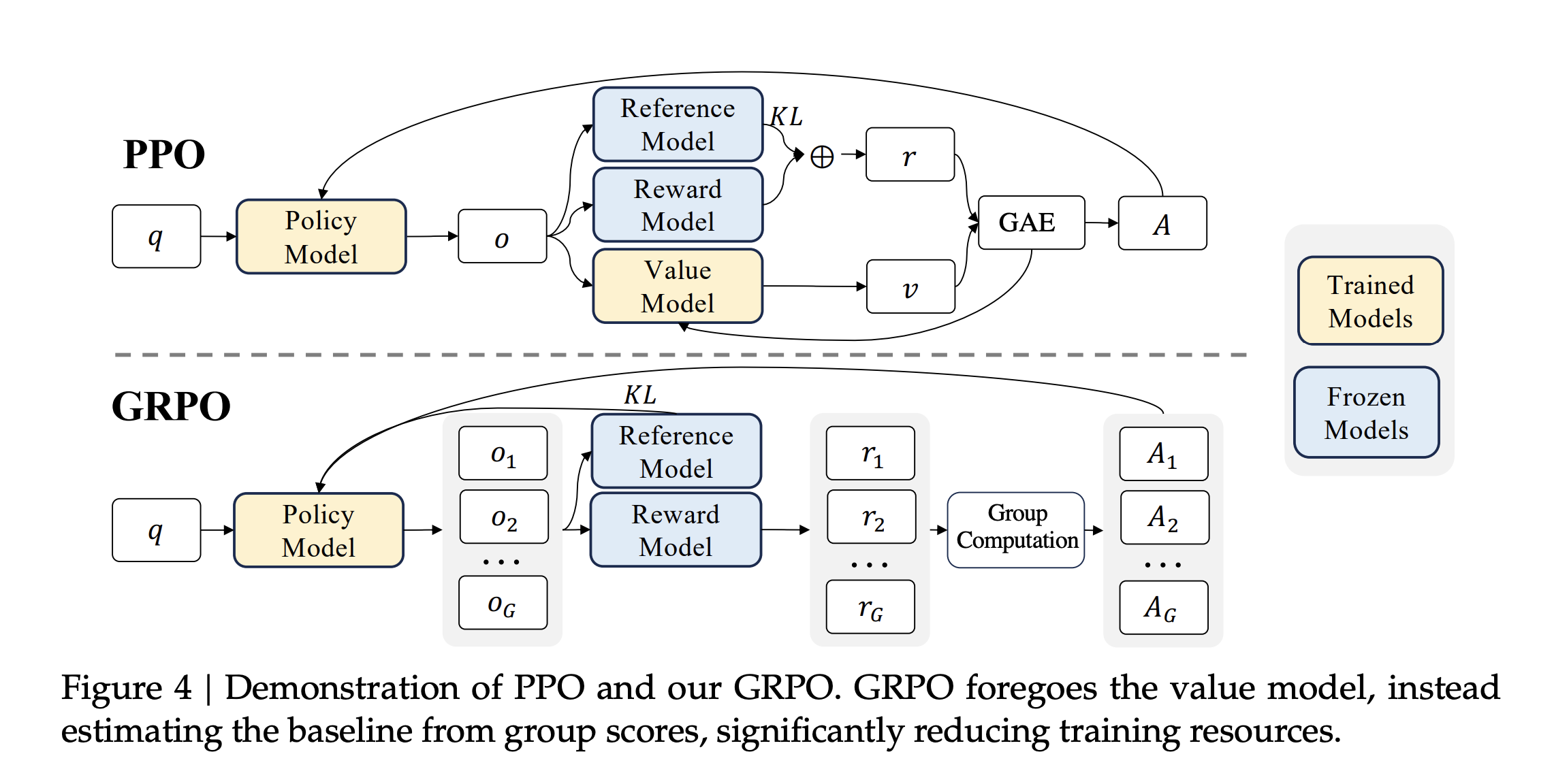
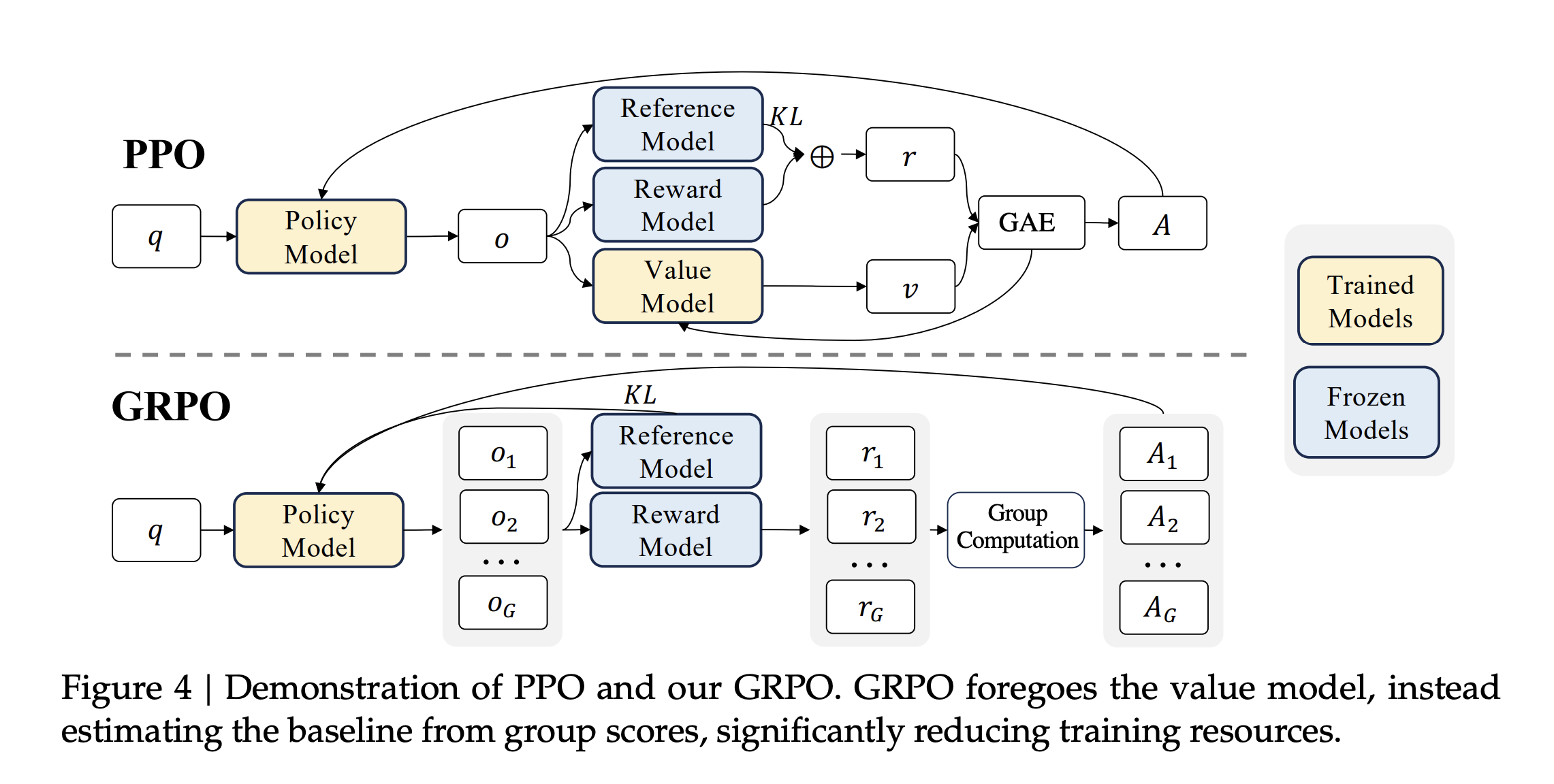
일단 GRPO의 결론부터 말하고자 한다면 위의 그림에서도 알 수 있듯이 Value Model(Critic Model)을 제거하는 RL 프레임워크다.
PPO를 활용한 RL 프레임워크에서는 이미 너무나도 많은 memory와 computing power가 필요한데, policy model의 사이즈에 버금가는 critic 모델까지 활용해서 매 토큰마다 advantage를 계산한다고 하면 쉽지 않을 것이다.
그럼 원래 PPO는 어떻게 되어 있을까?
-
PPO 알고리즘을 통해 최적화해야 하는 것은 policy다.
-
그러므로 gradient ascent 알고리즘을 통해 를 최적화하는 을 찾아야 한다. 그리고 그에 대한 식은 다음과 같다.
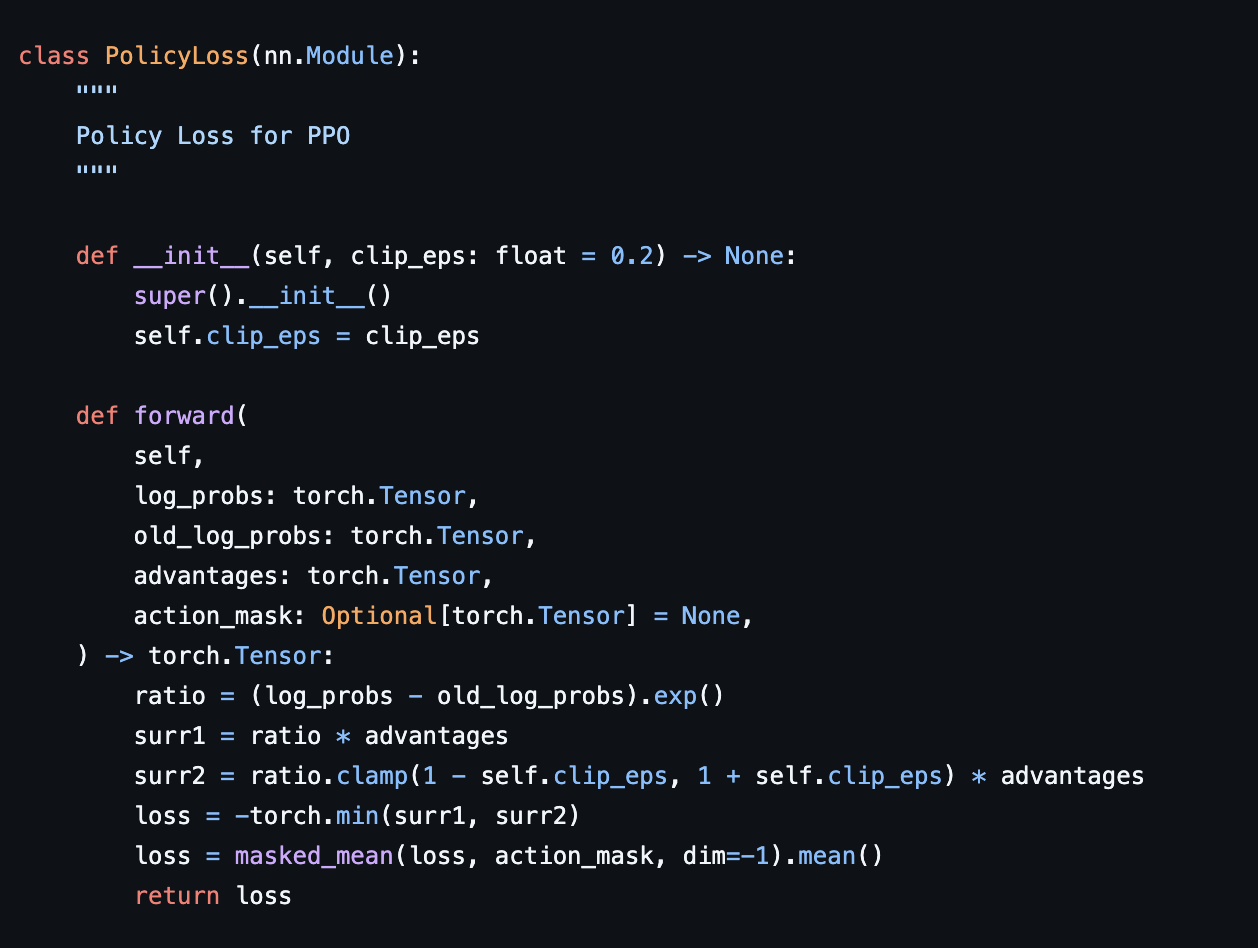
- 기본적으로 일반적인 SFT처럼
gradient descent방식으로 학습하지 않는다. gradient descent는 loss를 최소화해야 하는데, 위의 식은gradient ascent로 값을 최대화해야 한다.- 그런데
torch의loss.backward를 사용하기 위해서는 값을 반대로 뒤바꿔줘야 한다. - 아래의 그림에 확인할 수 있다.
- 그리고 가 일반적으로 잘 알고 있는
Advantage function이다. Advantage function을 구하기 위해서는Critic model이 필요한 것이다.
그런데 GRPO방식은 Critic model을 제거한다고 했고, 그러면 다음과 같은 의문점이 생긴다.
그럼 Advantage function의 값을 어떻게 구하지?
Figure 4를 보게 되면 하나의 query에 대해서 여러 개의 response를 생성하는 것을 알 수 있다. 이를 통해 각 응답에 대해 reward model을 활용하여 보상을 주고, 이의 평균을 보상에서 빼주는 것이다. 이를 통해 Advantage를 구한다. Advantage의 의미는 행동에 대한 평가라고 하였다. 그러므로 좋은 보상을 받았으면, 평균보다 좋은 보상일 것이고, 그러므로 Advantage가 양수일 것이다. 이를 통해 좋은 보상을 받은 행동을 더 할 수 있도록 학습을 하는 것이다.(이는 PPO의 목적과 동일하다.)
- 위 식을 간단히만 보자면,
- 을 곱하는 이유는 각각의 response에 대해 업데이트를 할 때 하나의 응답의 결과를 너무 많이 반영하는 것을 방지하기 위해 정규화하는 과정이라고 생각하면 된다.
그리고 또 한 가지 생각해봐야 할 점은 실제 reward를 받는 시점은 에피소드가 끝난(문장 생성이 끝난) 시점에서 reward를 받는다. 그러나 critic model을 학습하기 위해서는 매 시점 에 대해서 reward값을 계산을 해야 한다.(아래 식 참고)
Memory랑 computing power는 많이 필요한데, 실제로 critic model이 필요한 reward는 문장 생성의 마지막에만 주어진다. 이렇게 맞지 않다 보니 이를 대체하고자 하는 RL 프레임워크가 아닌가 싶다.
References
