[DeepSeek-R1 리뷰] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning(Main Part)
최근에 보지 못했던 좀 핫한, 그리고 최신 트렌드를 좇기 위한 리뷰를 해보고자 한다.
o1 모델과 달리 어떤 독특한 특징이 있는지, 그리고 어떤 기술들을 활용했는지, 어떤 인사이트를 얻을 수 있을지 조금 분석을 해봐야할 것 같다.
Abstract
- DeepSeek-R1-Zero
- DeepSeek-R1
DeepSeek-R1-Zero는 supervised fine-tuning(SFT)없이 대규모의 RL만 한 모델이다. 그런데 이 모델은 poor readability와 language mixing 문제가 있었다고 한다.(SFT를 안 하게 되면 가독성 있게 생성하는 능력과 다국어 능력이 떨어지는가?는 알아봐야 할 것 같다. 일단은 SFT를 하게 되면 가독성 있게 생성하는 능력이 더 좋고, 다국어 능력도 더 좋은가 보다.)
어쨌든 이러한 부족한 점을 개선한 게 DeepSeek-R1 모델이고, RL을 하기 전에 multi-stage training과 cold-start data를 포함시켰다고 한다.
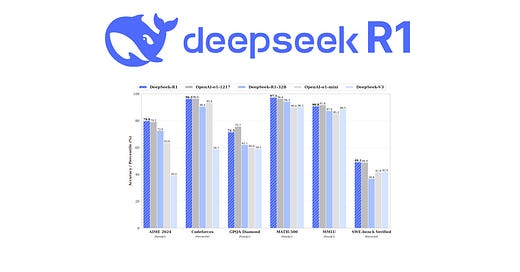
결과부터 말하자면, OpenAI-o1-1217을 reasoning task들에서 이겼다고 한다. 또 뭐 여러 가지 조합 및 distillation model을 만들었다고 하니 알아봐야겠다. 그리고 어떻게 만들었길래 무슨 숨은 기술이 있는지 알아봐야겠다.
- multi-stage training이 뭘까?
- cold-start data는 뭘까?
Illustration of DeepSeek-R1 training pipeline
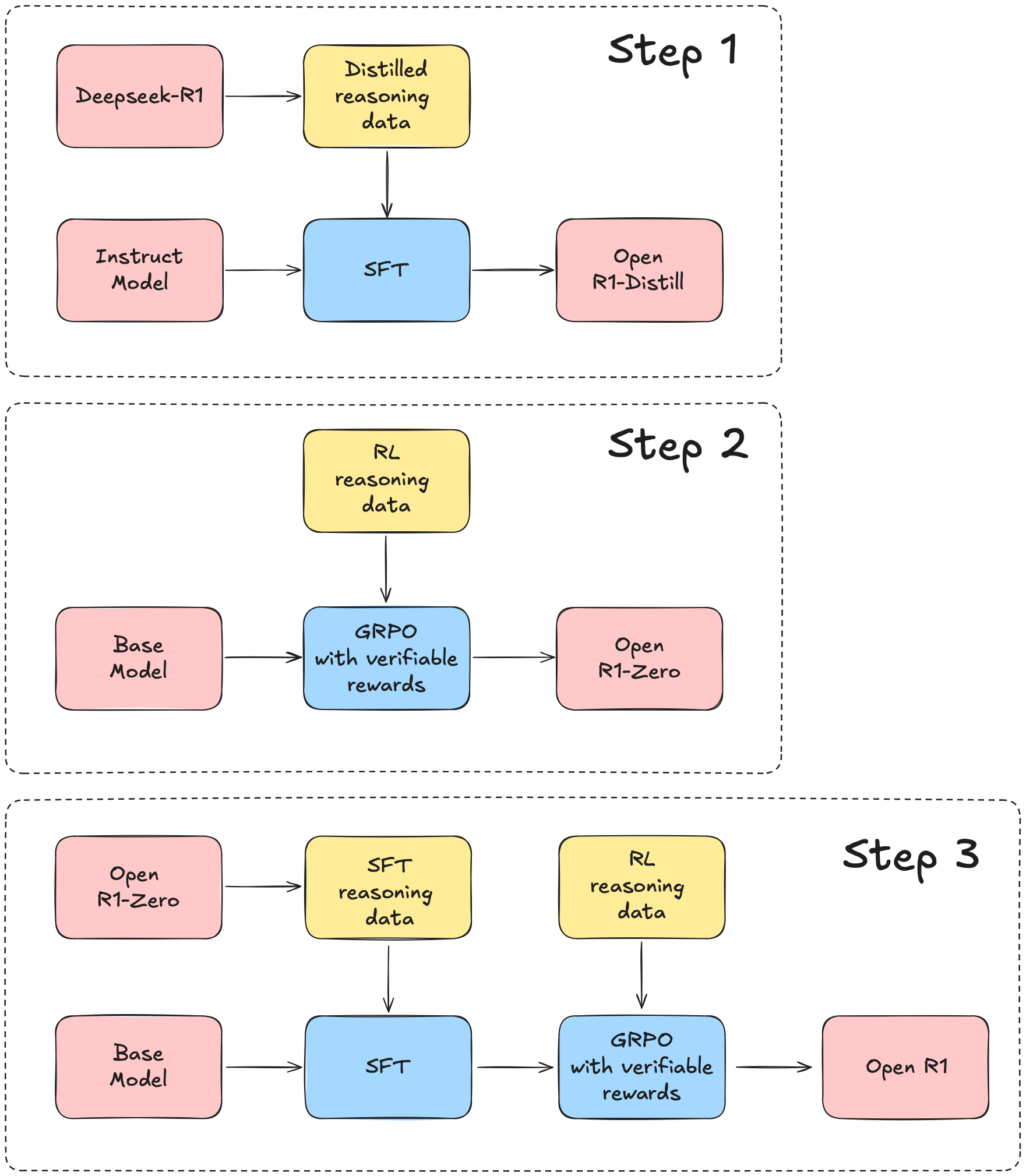
일단 글이 길 수도 있으니 간략하게 어떤 건지 알아보기 위한 사람들을 위해 Huggingface에서 opensource로 내놓은 Open-R1의 내용을 차용한다.
- Open-R1[1] 라이브러리는 DPO, ORPO 등의 방법론들이 나왔을 때 간단하게 DPO를 활용하여 자체 모델을 구축하게 만들어줬던 trl 라이브러리처럼 r1 모델을 자체적으로 만들 때 도움이 되는 라이브러리이다.
학습 파이프라인은 다음과 같이 구성된다.(모델을 만드는 순서가 1,2,3 순은 아니다. 본인이 만들고 싶은 자체 모델이 있을 때 그 step에 맞는 라이브러리를 활용하는 것이다.)
- Step 1: technical report에서 등장한 DeepSeek-R1-Distill-Qwen-7B 또는 DeepSeek-R1-Distill-Llama-8B 이런 모델들을 만드는 방법. DeepSeek-R1 모델을 활용하여 추출된 high-quality 데이터들을 활용해서 distilling한 모델들이다.
- Step 2: DeepSeek-V3-base[2] 모델을 활용해서 만든 모델. 물론 Open-R1은 DeepSeek-V3-base만을 써야하는 것은 아닌 것 같다. 결론은 이 스텝을 통해서 DeepSeek-R1-Zero와 같은 모델을 만들 수 있고, 그러한 모델을 만들 수 있는 것이니 여기에는 SFT가 포함되어 있지 않다. 단순히 RL만 포함되어 있다.
- DeepSeek-V3 Architecture
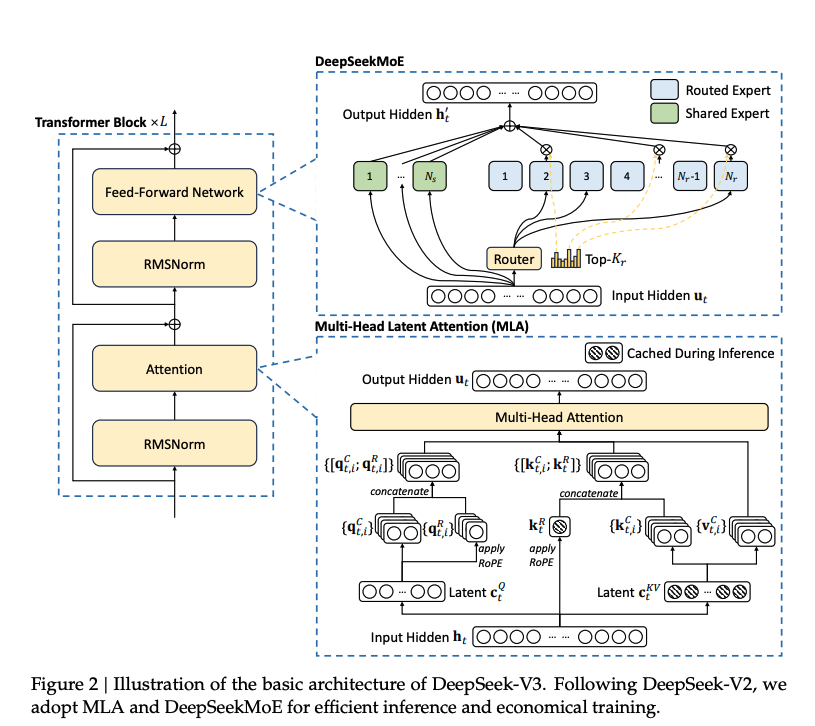
- DeepSeek-V3 Architecture
- Step 3: base 모델(DeepSeek-V3-base와 같은 모델)에서 R1-Zero가 아닌 R1모델로 가는 학습 파이프라인을 도식화해놓은 형태이다. 여기서는 SFT를 거친다.
그렇다면 이러한 형태들을 보고 나면 다음과 같은 질문들이 생긴다.
- Distilled reasoning data는 뭐지?
- RL reasoning data는 뭐지?
- GRPO는 또 뭘까?
이 3가지를 이해해야 R1 모델을 어떻게 만드는지 제대로 이해를 할 수 있을 것이라고 생각한다.
Introduction
그렇다면 이 모델은 왜 나오게 됐을까? 사실 계속 트렌드를 좇던 사람은 이 글이 필요가 없을 수도 있다. 그러나 나는 최근에는 안 좇고 있었으니 연구 배경에 대해서 알아볼 필요가 있을 것 같다.
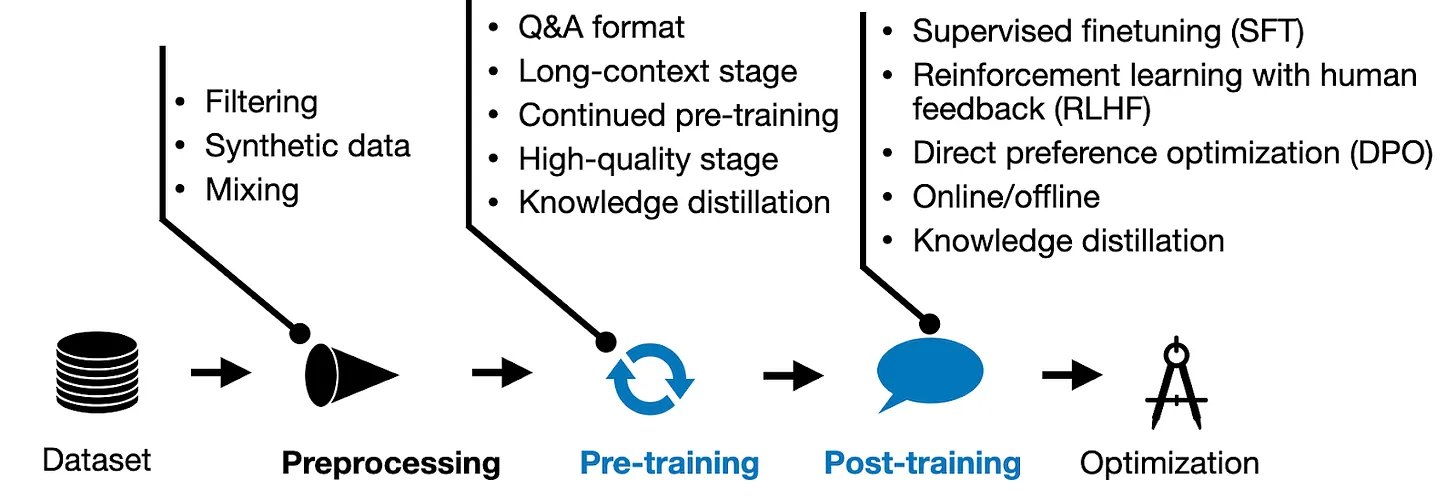
기본적인 학습 파이프라인은 위의 그림과 같이 구성이 된다. 일반적으로 우리가 알고 있는 Qwen2-7B라든지, Llama3-8B라든지 이러한 모델들이 Pre-training 단계까지 거친 모델들이다. 그리고 이들의 Check Point를 base로 하여, Instruction Tuning을 한다든지, Human Preference를 입히기 위해, DPO 또는 RLHF를 한다든지의 Post-Training의 단계를 거치게 된다. 그리하여 나온 모델들이 Qwen2-7B-Instruct 또는 Llama3-8B-Instruct와 같은 모델들이다. 그리고 또 다른 방식으로 학습한 OpenAI의 o1 같은 모델들이다.
- 그렇다면 이 o1이라는 모델은 어떤 특징을 띄는가?
일단 핵심만 말해본다면, 다음과 같은 특징을 띈다.
- 단순히 model의 size를 키워서 성능을 높인 모델이 아니라, inference를 할 시에 scaling, 즉, 추론에 computing power를 더 활용해서(CoT의 길이를 더 길게 했다고 함. 자세한 것은 찾아봐야 할 듯.) 성능을 높였다고 함.[4]
- 그래서 그 근원이 뭘까?를 생각하면서, process-based reward model, reinforcement learning 과 같은 방식, Monte Carlo Tree Search, Beam Search등 여러 탐색 알고리즘 등으로 research들이 이루어졌는데 o1의 성능에는 미치지 못했다고 함.
그래서 R1을 통해서 reasoning 능력을 높이고자 한다고 한다. 그리고 pure한 RL 방법론을 활용해서 R1을 만들고자 했다고 한다.
그리고 앞서 나왔던 cold-start data와 multi-stage training pipeline을 통해서 이를 이룰 수 있었다고 한다.
사실 나도 읽다가 보니 모르는 부분이 너무 많은 것 같지만 그래도 한 번 읽어보고 정리해보고자 한다.
- reasoning-oriented RL이 뭐지?
- RL 프로세스 중에 수렴(convergence)을 한다는 것은 어떤 것인가?
- 그리고 이 수렴한 checkpoint로부터 다시 rejection sampling을 통해 SFT 데이터를 만든 다는 것은 어떤 의미인지?
정말 정리해야 할 부분이 많은 것으로 생각된다.
Conclusion
그렇다면 이 모델을 개발함으로써 얻었던 결론은 어떻게 될까?
- pure RL approach(GRPO인 것 같음.)만 사용해도 충분히 promising하고, 더 나아가서 cold-start data를 사용과 함께 iterative한 RL tuning을 하면 o1과 비슷한 성능을 내는 모델을 만들 수 있다.
- 이러한 R1 모델 가지고 distillation만 해도 충분히 promising하고, 현재 off-the-shelf 모델들보다 나은 성능을 보여주는 것으로 보임.
그러나 한계도 몇 가지 보여줌. 커뮤니티에서도 나오는 말이지만
- General Capability -> DeepSeek-V3에 비해 일반적인, 범용적인 task에서는 성능이 떨어짐을 보여줌. Reasoning task는 잘함.
- Language Mixing -> 한국어가 잘 안 됨. 영어랑 중국어만 잘 될 것 같음. 다른 Instruction Model들은 분명히 한국어를 충분히 잘했는데 이건 약간 애매한 느낌. 왜 그럴까? 궁금하긴 하다.
- Prompt Engineering
- Software Engineering Tasks
더 자세한 건 다음 편에 알아보자...
References
