LLM은 기본적으로 사전학습된 데이터와 SFT가 된 데이터를 통해 next token prediction을 한다. 이러한 부분에서 최신 정보를 매번 학습하기가 어렵고, 또 추가 정보를 학습하기에는 많은 컴퓨팅 자원이 필요하기 때문에, RAG(Retrieval Augmented Generation)이라는 기법이 나오게 되었다. 이러한 부분을 고려하며 다음 논문을 읽어본다.
Abstract
- 기존의
RALM(Retrieval-Augmented Language Modeling)방식은 LM의 아키텍쳐를 변경하여 구현하려고 함. - 그러나 이러한 방식은 실제 서비스로 배포할 때 복잡함을 보여줌.
- 따라서 본 논문에서는 간단한 방식으로
In-Context RALM이라는 방식을 제시함. In-Context RALM이란 LM 아키텍처를 유지하고, LM을 학습하는 것 없이 LM의In-Context Learning의 능력을 끌어내오는 방식을 취한 개념.
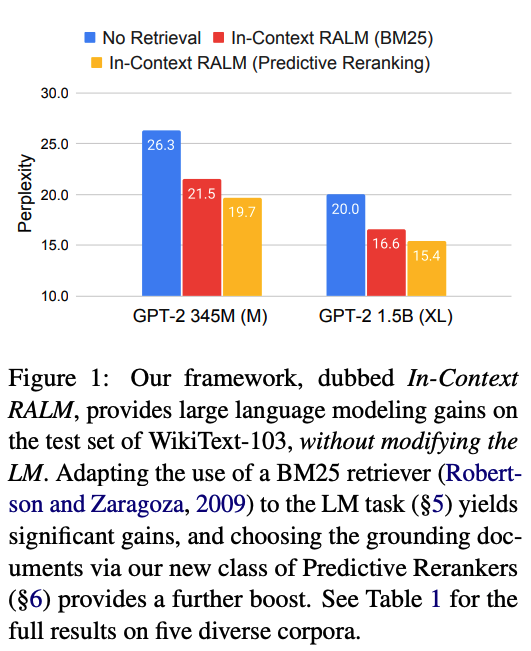
- 위 사진은 retrieval을 하지 않았을 때, retrieval을 단순히 했을 때, 그리고 retrieval과 ranking을 동시에 했을 때의
perplexity를 보여준다. - retrieval + ranking이
perplexity가 가장 낮은 것으로 보아 가장 안정적이다.

- 그리고 위 사진은
In-Context RALM의 파이프라인 구조다. - Retrieval document를 단순히 Input의 앞단에 붙이는 구조이다.
Our Framework
In-Context RALM
- 기본적으로 LM은 next token을 예측하는 방식이다. 그리고 수식은 다음과 같다.
RALMs(Retrieval Augmented language models는 외부의 corpus 를 단순히 input의 앞단에 붙인 것이다. 따라서 식은 다음과 같이 된다.- 이전에 retrieved document 기반으로 LM generation을 했던 방법은 논문을 참고하면 좋을 것 같다.
- 그러나 여기서는 아주 간단한 방법으로 구현했다.
- 그래서 최종적인 RALM의 수식은 다음과 같다.
- 는 string a와 b를 합친것을 의미한다.
- 따라서
retrieval된 document + prompt를 통해next token을 예측하는 것이다.
RALM Design Choices
- 다음은 디테일한 사항이다.
- Retrieval Stride
- 매 스텝마다 검색을 하여 retrieval된 document기반으로 생성을 하게 된다면, 게산 비용이 엄청나게 들 것임.
- 따라서
stride라는 방법을 취해서, 일정 stride마다 검색을 하게 하는 방식이다. - 그러므로 수식은 다음과 같다.
- 로 retrieval을 stride길이로 몇 번이나 수행할지에 대한 값이다.
- stride를 작게 하여 자주 retrieval하는 것이 성능 면에서는 우수함.
- 그러나 그렇게 되면 계산 비용이 너무 커지므로, 큰 stride를 통해서 하는 것이 좋음.
- 큰 stride로 해도 vanilla LM에 비해 성능이 매우 좋기 때문에 tradeoff관계로 생각할 수 있음.
- Retrieval Query Length
- 생성을 할 때, retrieval document + prompt를 통해 진행한다고 했었다.
- 그러나 retrieval query가 너무 길면, 정보들이 희석되고 따라서 적절한 길이의 retrieval query가 필요함.
- 따라서
retrieval query length를 로 제한하고, 마지막 토큰만을 prompt 앞에 붙인다. - 그러므로 수식은 다음과 같다.
- 이다.
- 수식을 해석하자면 j번째의 retrieval마다 stride s만큼 생성하는데, 이 때 검색 쿼리는 l로 제한해서 생성을 한다는 것이다.
- 만약 검색 쿼리가 '[2, 0, 2, 4, 년, 카타르, 아시, 안, 컵, 우승, 팀, 은, 어디, 야, ?]'라고 하고, l = 10 이라고 하면, '카타르 아시안컵 우승팀은 어디야?'가 검색 쿼리가 되고, 이에 따라
retrieval 정보 + 검색 쿼리에 의해 s만큼 생성하다가 s이후에 검색 쿼리를 교체하는 것이다.
- 은 성능이 좋지 않다고 한다.
Experiments Details
Datasets
- Language Modeling
- WikiText-103
- The Pile
- Real-News
- Open-Domain Question Answering
- Natural Questions
Models
- GPT 계열 모델
Retrievers
- sparse retriever(word-based) -
BM25 - dense retriever(neural network) -
BERT-base,Contriever,Spider
Reranking
Roberta-base로 초기화.- BM25로 top-k document를 복원하기 위해 reranker를 학습함.
- Predictive Reranking이라고 부름.
- LM이 next token을 생성할 때 어떤 문서가 가장 적합한지를 결정하기 위한 것이라, predictive라고 불린다.
- Roberta를 기반으로 한 모델로 에 적합한 document가 어떠한 것일지, prob로 나타내는 분류모델이다.
- 이 prob에 따라 top k document를 결정한다.

매일 매일 한 걸음씩 나아가고자 합니다.