언젠가는 간단하게라도 읽어야지라고 했던 논문들을 설을 맞아 간단하게라도 정리해본다.
paper link: https://arxiv.org/pdf/2308.10149.pdf
Abstract
LLM은 기본적으로 대규모 학습 데이터를 통해 학습을 하는 통계기반의 모델이기 때문에, 대규모 학습 데이터가 어떻게 구성되어 있느냐에 따라 편향성을 나타낼 수 있다. 따라서 만약, 사전학습 모델이 이미 편향성을 가진 모델이라면, downstream task를 위해 Fine tuning한 모델도 편향성을 나타낼 수 있는 것이다.
그리고 이러한 것들은 LLM을 사용하는데 있어서 좋지 않은 잠재성을 가지게 된다. 본 논문에서는 fairness LLM에 관련된 연구들을 보여주고, 평가는 어떻게 하는지, 또 debiasing method는 무엇이 있는지 소개한다.
기본적으로 본 논문에서 설명하는 bias는 2가지가 있는 것으로 보인다.
- intrinsic bias
- extrinsic bias
그렇다면 각각의 bias는 어떤 개념을 내포하는 것일까?
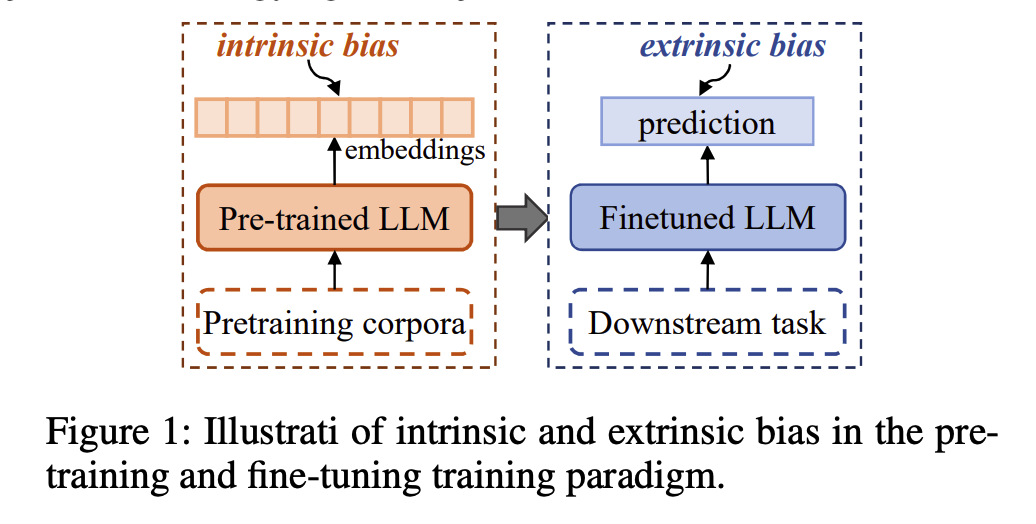
위 그림에서 파악할 수 있듯이,
intrinsic bias는 사전학습 모델에서 나타날 수 있는 bias이다. 사전학습을 할 때에는 BERT 계열의 Encoder계열 모델은 결국 핵심 목표는 특정 토근을 잘 임베딩하여 vector represantation을 잘 나타내는 것이다. 주변 문맥을 잘 파악하여 토큰의 임베딩이 되어야 하는 것이고, 만약 사전학습 데이터의 품질이 안 좋거나, 편향되어 있다면, 이러한 임베딩 또한 편향된다는 의미이다.
extrinsic bias는 사전학습 모델을 바탕으로 최종적으로 우리가 하고자 하는 downstream task에서 prediction과 같은 것들을 할 때 잘못된, 편향적인 prediction을 하는 것이다.
여기서 생각해야 할 것은 우리는 그렇다면 사전학습을 진행을 할 때, 기본적으로 편향되지 않은 사전학습 모델을 만들고자 노력해야 한다. 그렇다면 편향되지 않은 사전학습 모델을 만들고자 한다면, 현재 우리가 통상적으로 구축하는 사전학습 모델은 통계 기반의 모델이기 때문에, 편향되지 않은 데이터를 구축하는 것이 핵심이다. 또한 사전학습 모델을 구축을 했다면, 이러한 모델을 어떻게 잘 evaluation할 수 있을지에 대한 고민을 해봐야 한다.
downstream task를 위한 모델 학습을 할 때도 마찬가지이다.
본 논문에서는 그러한 evaluation 평가 방법과 debiasing method를 설명할 것이다.
자세한 것은 직접 이러한 모델을 만들 때 참고를 하면 좋을 것이다.
그리고 이러한 것들을 어떠한 방법론으로 할지에 대한 본 논문의 연구 구조도이다.
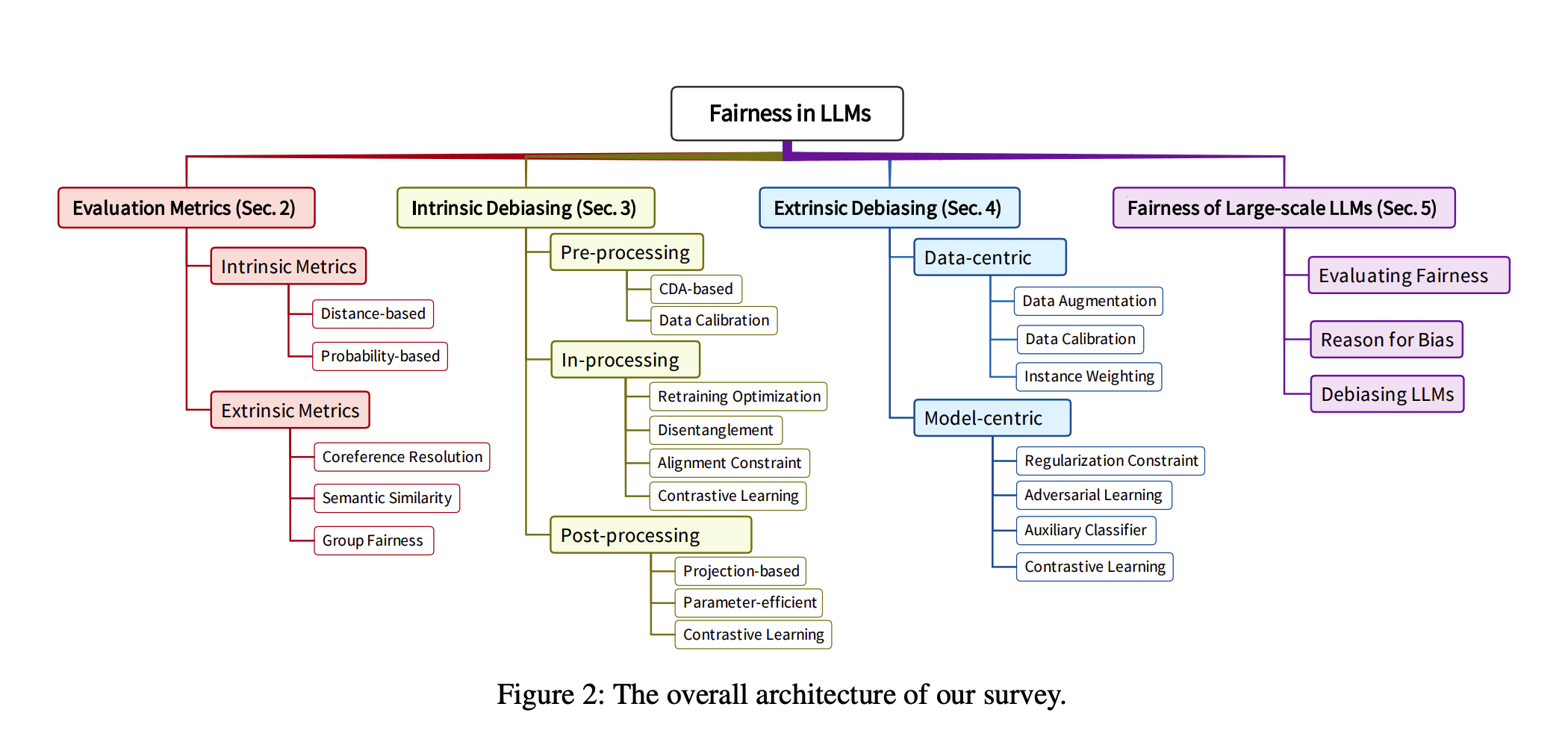
- 사전학습을 할 때, 평가방식이나 debiasing method를 어떠한 것을 쓸지 고민이 된다면, intrinsic에 관련된 것들을 찾아보는 것이 좋을 것이다.
- 파인튜닝을 할 때, 평가방식이나 debiasing method를 어떠한 것을 쓸지 고민이 된다면, extrinsic에 관련된 것들을 찾아보는 것이 좋을 것이다.
일단 나는 주로 pretraining보다는 sft를 하기 때문에, extrinsic debiasing에 대해서 먼저 알아봐야 할 것 같다.
Extrinsic Debiasing
- 이 개념은 downstream task에서 어떤 input이 들어와도 일관된 output을 내고자 하기 위한 방법론이다.
- 예를 들어, 기성세대가 LLM을 사용해도, MZ세대가 LLM을 사용해도 그 계층에 편향된 답변을 하는 것이 아닌 일관된 답변을 하기 위한 방법론이다.
- 큰 범주로는 다음과 같은 방법론이 존재한다.
Data-centric DebiasingModel-centric Debiasing
Data-centric Debiasing
- 본 방법론은 데이터 자체의 결함을 찾는 것으로, 라벨이 불균형하다거나, 잘못된 정보가 포함되어 있다거나, distributional difference가 존재하는 것이다. distributional difference는 어떤 의미인지 차차 알아가봐야 할 것 같다.
Data Augmentation
- 가장 간단하게 불균형한 라벨을 맞춰주는 방법론이다. 특정 클래스로 분류될 만한 클래스만 존재한다면 다른 클래스로 분류될 만한 클래스들도 추가해서 비율을 맞춰주는 방식이다.
Data Calibration
- 데이터 교정이라고도 불린다. 데이터 퀄리티를 높이기 위해, 여러 가지 방법론이 나왔다.
- 기계 번역 분야에서 나온 방법론으로는 성별 편향을 막기 위해서, 대명사를 '그' 또는 '그녀' 이런 식으로 적절하게 분배될 수 있도록 번역 데이터셋을 구성하는 것이다.
- 조금 더 구체적으로 예를 들면, 다음과 같은 케이스가 있을 수 있다.
공장노동자는 오늘도 일을 한다. 그는 아침을 먹고 일과를 시작한다.- 위와 같은 데이터를 항상 '그'로 하게 되면, '공장노동자'는 남성 중심이다라고 모델이 생각하게 되지만, 적절히 '그녀'와 섞어서 사용하게 되면 모델이 편향적이지 않게 되는 것이다.
- 이런 식으로 데이터 편향을 calibration을 통해 정제해주는 것이다.
