Abstract
- LLM은 2 단계로 학습이 진행됨.
raw text를 활용한 unsupervised pretraining.-> general한 목적을 가진 representation을 학습하기 위해. 즉, 우리의 자연어를 어느 상황에서나 잘 표현되는 벡터로 표현하기 위한 학습이라 볼 수 있다.large scale의 instruction tuning 또는 RL(reinforcement learning).-> 주어진 end task에 더 잘 align 될 수 있도록, 그리고 user preference에 맞도록 fine tuning하는 것이다.
- 본 논문은 이 두 단계의 중요성을 확인하기 위해 LIMA를 학습한다.
- LIMA란 LLAMA 65B과 같은 base model에 1000개의 퀄리티 있고, 잘 선정된 prompt와 그에 따른 response로 학습된 것이다.
- RLHF나 기타 다른 방법을 활용하여 loss를 따로 학습하는 것이 아닌, 학습 방식은 기본적인 supervised loss로 학습한다.
- 1000개 정도로 작은 데이터로 학습을 진행하는데, 이 학습 데이터에는 여행 계획을 짜는 등의 복잡한 쿼리(input)도 포함된다.
- 이러한 방식으로 강화학습 방식으로 학습된 GPT-4, Bard, DaVinci003과 비슷한 성능을 낸다.
- 이러한 연구 결과는 pretraining 당시에 대부분의 지식을 LLM이 습득하고, 제한된 Instruction tuning 데이터만이 높은 퀄리티의 출력을 내기 위해 필요하다는 것을 시사한다.
Instruction
- 여러 가지의 alingment를 하기 위한 여러 가지 연구가 있었음. (instruction tuning, RLHF 등등)
- 그러나 뭐 이런 논문들은 compute cost가 너무 많이 들고, ChatGPT 수준의 성능을 달성하기 위해서는 특성화된 data가 필요했음.
- 하지만, 잘 pretrained된 모델만 있으면, 1000개의 잘 선정된 데이터만 있으면 이런 성능 달성이 가능함.
- 1000개의 데이터동안 LLM은 유저와 대화하는 포맷만 학습을 하면 되는 것이다.
- 이러한 실험을 하기 위해서는 잘 선정된, 그리고 실제 유저의 프롬프트같은 형식과 high quality의 답변으로 구성된 1000개의 샘플이 필요하다.
데이터셋 구성 개요
-
그렇다면 이러한 데이터는 어디서 구했을까? 다양성을 위해 그리고 퀄리티를 위해,
Stack Exchange나wikiHow와 같은 곳에서 데이터를 샘플링했다. 이렇게 750개를 모았다. -
그렇다면 나머지 250개는? 직접 작성했다.
-
이렇게 데이터를 모으면서 중요한 점이 있다. 다양성은 유지하면서, 스타일과 포맷을 모델이 학습할 수 있는 일관성이 있는 데이터를 모아야 하는 것이다.
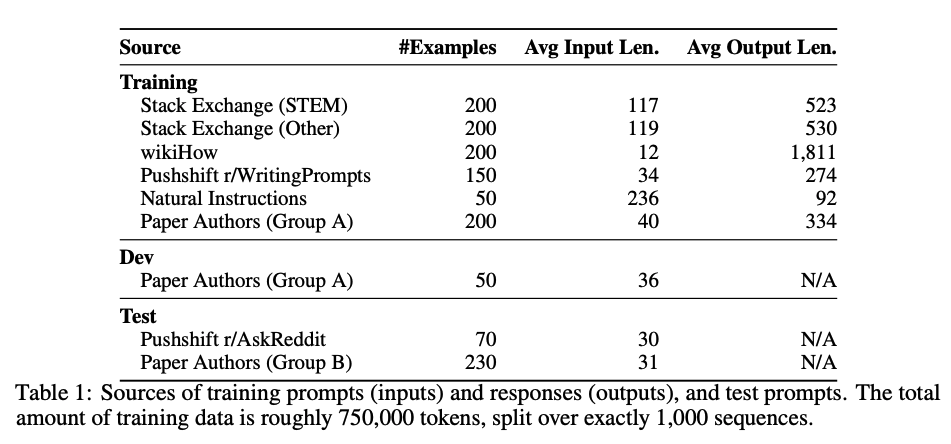
-
또한 ablation study는 데이터 품질의 상승 없이(다양성에 대한 상승 없이) 단순히 양만 증가시키는 것은 성능을 떨어뜨리는 것을 보여준다.
Alignment Data
- 본 논문의 중심가설은 다음과 같다.
- 대부분의 지식은 pretraining동안 다 학습했다.
- alignment를 하는 동안은 단순히 유저와 상호작용하는 포맷에 대한 distribution만 학습하는 것이다.
- 이러한 가설을 검증하기 위해 본 저자는 1000개의 프롬프트와 답변을 수집했다.
- output 형태는 서로서로 일관성이 있으나, input은 다양하다.
- 목표는 helpful한 AI 어시스턴트를 만드는 것이다.
Community Questions & Answers
Stack Exchange와wikiHow의 데이터는 컨셉과 적절해서 자동 샘플링으로 수집했다.- 하지만,
Reddit에서 수집한 데이터는 유머적인 답변도 있고, 적절하지 않은 답변이 있어서 수동으로 샘플링했다.
Manually Authored Examples
- 데이터의 다양성을 더 증폭시키기 위해 다음과 같은 방법을 활용했다.
- 실제로 데이터 만드는 사람들에게, 그들만의 관심분야에 대한 prompt나 그들의 친구들의 관심분야에 대한 prompt를 작성하게 하였고, 문제가 있는 prompt를 걸러낸뒤 퀄리티 있는 데이터로 활용했다.
- 또한 퀄리티 있는 답변을 작성하기 위해, 직접 prompt에 답변을 하는 방식으로 데이터를 구성했다.
- helpful한 AI 어시스턴트를 만들기 위해, 일정한 톤으로 답변했고, 많은 프롬프트들에 대한 답변이 chain of thought(또는 let's think step-by-step)와 같은 방식으로 prompt에 있는 지식을 활용한 방식으로 답변을 하도록 구성됐다.
- 이러한 방식은 사실 많은 노동이 들어간다. 그래서 양으로, 또는 automatic한 방법으로 하고자 한 연구도 있다.
- 예시
- Unnatural instructions: Tuning language models with (almost) no human labor
- Self-instruct: Aligning language model with self generated instructions
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality
- Stanford alpaca: An instruction-following llama model.
- Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision
Training LIMA
- 학습 방식
- base model: LLaMa 65B
- 데이터셋: 1000개의 alingment용 데이터셋
- user와 assistant를 구별하기 위해 각 발화의 끝에 EOT(end-of-turn) token 추가
- EOT 토큰의 역할은 생성 중단 역할을 함.
- EOS 토큰과의 의미 중복을 피하기 위해 사용함.
- 15 epoch
- AdamW optimizer 사용( = 0.9, = 0.95, wd = 0.1, warmup steps 없이, lr = 1e-5로 시작해서 1e-6까지 선형적으로 떨어지게 설정.)
- batch size는 32
- max sequence length는 2K
- 드롭아웃은 residual connection 위에서 적용.
- 드롭아웃은 bottom layer부터 last layer까지 0.0부터 0.3까지 선형적으로 증가하게 적용함.
- perplexity는 생성 퀄리티와 연관이 별로 없어서, 수동적으로 직접 체크포인트를 dev set에 테스트하여 선정.

매일 매일 한 걸음씩 나아가고자 합니다.